本文將從以下方面結合原始碼進行分析:自動擴容、初始化與懶加載、哈希計算、位運算(默認采用JDK1.8), 自動擴容 擴容操作發生在putVal最后部分,在增加元素后才判斷是否需要擴容,如果超過閾值,會自動擴容,
 這里擴容都是<<1翻倍進行擴容的,
這里擴容都是<<1翻倍進行擴容的,
 擴容時節點陣列進行資料轉移的三種情況:
擴容時節點陣列進行資料轉移的三種情況:
- 節點的元素無后繼節點:

- 節點為樹節點:
 因為capacity變化后,hash&(cap-1)可能得到不同結果,原有的紅黑樹變成高低位兩個紅黑樹,低位紅黑樹下標位置和舊陣列相同,高位紅黑樹下標位置在舊陣列的基礎上+oldCap,因為hash&(2*cap-1)結果等于hash&(cap-1)或者hash&(cap-1)+cap,
因為capacity變化后,hash&(cap-1)可能得到不同結果,原有的紅黑樹變成高低位兩個紅黑樹,低位紅黑樹下標位置和舊陣列相同,高位紅黑樹下標位置在舊陣列的基礎上+oldCap,因為hash&(2*cap-1)結果等于hash&(cap-1)或者hash&(cap-1)+cap,
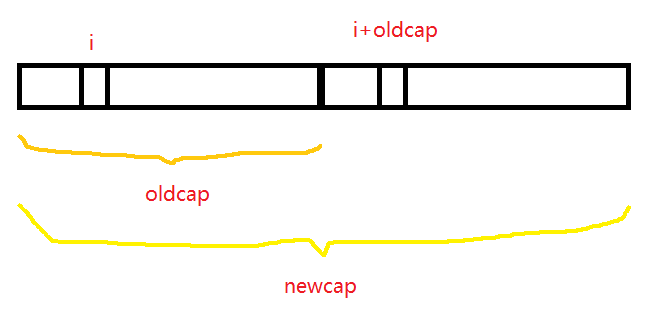 紅黑樹擴容時遍歷原有鏈表,然后根據新的hash值重新分為低位鏈表和高位鏈表,
若所有元素都在低位鏈表或高位鏈表,則不需要重新樹化,直接將鏈表頭節點插入陣列對應位置;
若低位鏈表或高位鏈表的數量<7,則深拷貝低位或高位樹節點鏈表得到普通節點新鏈表(低位或高位樹節點鏈表含有樹的偏序關系,拷貝得到的普通節點鏈表只有鏈表的偏序關系),并將新鏈表頭節點插入陣列對應位置,
具體原始碼分析如下:
紅黑樹擴容時遍歷原有鏈表,然后根據新的hash值重新分為低位鏈表和高位鏈表,
若所有元素都在低位鏈表或高位鏈表,則不需要重新樹化,直接將鏈表頭節點插入陣列對應位置;
若低位鏈表或高位鏈表的數量<7,則深拷貝低位或高位樹節點鏈表得到普通節點新鏈表(低位或高位樹節點鏈表含有樹的偏序關系,拷貝得到的普通節點鏈表只有鏈表的偏序關系),并將新鏈表頭節點插入陣列對應位置,
具體原始碼分析如下:
1 final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
2 // 獲取自身樹節點
3 TreeNode<K,V> b = this;
4 // Relink into lo and hi lists, preserving order
5 // 低位鏈表的頭尾節點
6 TreeNode<K,V> loHead = null, loTail = null;
7 // 高位鏈表的頭尾節點
8 TreeNode<K,V> hiHead = null, hiTail = null;
9 // 低位鏈表節點數量、高位鏈表節點數量
10 int lc = 0, hc = 0;
11 for (TreeNode<K,V> e = b, next; e != null; e = next) {
12 next = (TreeNode<K,V>)e.next;
13 // 這步操作不是多余的,在e為低位或高位鏈表最終尾節點時起到賦空作用
14 e.next = null;
15 // 如果仍然在原位置,則加入低位鏈表
16 if ((e.hash & bit) == 0) {
17 if ((e.prev = loTail) == null)
18 loHead = e;
19 else
20 loTail.next = e;
21 loTail = e;
22 ++lc;//低位鏈表數量+1
23 }
24 else {
25 // 如果是在新的位置(原索引值+oldcap),加入高位鏈表
26 if ((e.prev = hiTail) == null)
27 hiHead = e;
28 else
29 hiTail.next = e;
30 hiTail = e;
31 ++hc;// 高位鏈表數量+1
32 }
33 }
34 // 低位鏈表不為空
35 if (loHead != null) {
36 // 低位鏈表數量不超過6,則深拷貝低位樹節點鏈表得到普通節點新鏈表,并將新鏈表頭部放入陣列
37 if (lc <= UNTREEIFY_THRESHOLD)
38 tab[index] = loHead.untreeify(map);
39 else {
40 tab[index] = loHead;
41 // 如果高位鏈表為空,說明全部元素都在低位鏈表中,因為原鏈表已經是樹化的了,所以不用再轉為紅黑樹
42 if (hiHead != null) // (else is already treeified)
43 loHead.treeify(tab);
44 }
45 }
46 // 高位鏈表不為空
47 if (hiHead != null) {
48 // 高位鏈表數量不超過6,則深拷貝樹節點高位鏈表得到普通節點新鏈表,并將新鏈表頭部放入陣列
49 if (hc <= UNTREEIFY_THRESHOLD)
50 tab[index + bit] = hiHead.untreeify(map);
51 else {
52 tab[index + bit] = hiHead;
53 // 如果低位鏈表為空,說明全部元素都在高位鏈表中,因為原鏈表已經是樹化的了,所以不用再轉為紅黑樹
54 if (loHead != null)
55 hiHead.treeify(tab);
56 }
57 }
58 }
- 節點為鏈表節點:
1 // case3:節點為鏈表節點,進行鏈表的賦值操作
2 else { // preserve order
3 // 低位Node鏈表頭節點和尾節點
4 Node<K,V> loHead = null, loTail = null;
5 // 高位Node鏈表頭節點和尾節點
6 Node<K,V> hiHead = null, hiTail = null;
7 Node<K,V> next;
8 // 遍歷原鏈表,拆分成低位鏈表和高位鏈表
9 do {
10 next = e.next;
11 // 如果是在原位置,則加入低位鏈表
12 if ((e.hash & oldCap) == 0) {
13 if (loTail == null)
14 loHead = e;
15 else
16 loTail.next = e;
17 loTail = e;
18 }
19 else {
20 // 如果不在原位置,加入高位鏈表
21 if (hiTail == null)
22 hiHead = e;
23 else
24 hiTail.next = e;
25 hiTail = e;
26 }
27 } while ((e = next) != null);
28 // 如果低位鏈表不為空
29 if (loTail != null) {
30 // 尾部節點賦空并將頭部節點放入陣列指定位置
31 loTail.next = null;
32 newTab[j] = loHead;
33 }
34 // 如果高位鏈表不為空
35 if (hiTail != null) {
36 // 尾部節點賦空并將頭部節點放入陣列指定位置
37 hiTail.next = null;
38 newTab[j + oldCap] = hiHead;
39 }
40 }
在jdk1.8之前,hashmap在多執行緒環境中使用會出現死鏈問題,如果有多個執行緒同時進行擴容操作,一個執行緒拿到鏈表頭節點和后繼節點時掛起,另一個執行緒執行完擴容操作,會使得這兩個節點互相依賴,出現死鏈,導致第一個執行緒不能退出回圈,CPU使用率飆升,
jdk1.8將原來的頭插法改為了尾插法,同時復制鏈表時不再是遍歷一個節點就插入,而是使用高低位鏈表,待遍歷完所有節點后,再將高低位鏈表放入新陣列對應位置,
但是仍然不建議在多執行緒環境下使用,仍然會有資料缺失和資料重復等等問題,
初始化與懶加載 hashmap節點陣列的定義和初始化不會在建構式中完成,而是在首次執行put()操作時才完成的,
1 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 2 boolean evict) { 3 Node<K,V>[] tab; Node<K,V> p; int n, i; 4 // 如果節點陣列未初始化或為空,則進行初始化操作 5 if ((tab = table) == null || (n = tab.length) == 0) 6 n = (tab = resize()).length;resize()中會設定默認的初始化容量DEFAULT_INITIAL_CAPACITY為16,擴容的閾值為0.75*16 = 12,即哈希桶陣列中元素達到12個便進行擴容操作, 最后創建容量為16的Node陣列,并賦值給成員變數哈希桶table,即完成了HashMap的初始化操作,
1 final Node<K,V>[] resize() { 2 // 獲取原有table 3 Node<K,V>[] oldTab = table; 4 int oldCap = (oldTab == null) ? 0 : oldTab.length; 5 int oldThr = threshold; 6 // 新容量、新閾值 7 int newCap, newThr = 0; 8 ...................... 9 else { // zero initial threshold signifies using defaults 10 // 原容量和閾值都<=0,則用默認值初始化,默認容量16,負載因子0.75,對應的是hashmap沒帶引數初始化, 11 newCap = DEFAULT_INITIAL_CAPACITY; 12 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); 13 }
哈希計算 null的hash值為0,計算key的hash值時先獲取key的32位hashCode,然后將hashcode&(hashcode>>>16),等效于高16位不變,高16位與低16位作異或,結果為新的低16位,將高16位與低16位進行異或的操作稱之為擾動函式,目的是將高位的特征融入到低位之中,降低哈希沖突的概率,
1 static final int hash(Object key) { 2 int h; 3 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 4 }ConcurrentHashMap中經過擾亂函式處理之后,需要與HASH_BITS做與運算,HASH_BITS為0x7ffffff,即只有最高位為0,這樣運算的結果使hashCode永遠為正數,在ConcurrentHashMap中,預定義了幾個特殊節點的hashCode,如:MOVED、TREEBIN、RESERVED,它們的hashCode均定義為負值,因此,將普通節點的hashCode限定為正數,也就是為了防止與這些特殊節點的hashCode產生沖突,
1 static final int MOVED = -1; // hash for forwarding nodes 2 static final int TREEBIN = -2; // hash for roots of trees 3 static final int RESERVED = -3; // hash for transient reservations 4 static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash 5 static final int spread(int h) { 6 return (h ^ (h >>> 16)) & HASH_BITS; 7 }哈希沖突 如有多個key計算得到的hashCode相同,就會產生hash沖突,jdk1.8的hashmap使用了鏈表法和紅黑樹去處理hash沖突, 當出現hash沖突時,將新插入的節點通過尾插法插入到鏈表的尾部,當鏈表的長度超過8且陣列的capacity>=64則將鏈表轉為紅黑樹,
1 // 如果鏈表的數量超過了8,且陣列cap大小>=64則轉為紅黑樹 2 // 如果鏈表數量超過了8,但陣列cap大小<64則resize()擴容 3 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 4 treeifyBin(tab, hash); 5 6 final void treeifyBin(Node<K,V>[] tab, int hash) { 7 int n, index; Node<K,V> e; 8 // 如果陣列長度沒達到64就擴容 9 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) 10 resize();
位運算 計算陣列大小的方法,給定一個輸出值,找到大于等于給定值的最小的2^n,
1 static final int tableSizeFor(int cap) { 2 int n = cap - 1; 3 n |= n >>> 1; 4 n |= n >>> 2; 5 n |= n >>> 4; 6 n |= n >>> 8; 7 n |= n >>> 16; 8 return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; 9 }這里是實作了找>=cap的最小2^n,cap為int型別,長度32位, 對于一個正數,找大于該數的最小的2^n,都可以采用這種方式,將n最高位后面全部置為1,然后加1,因為位運算非常快速,這種方法比找到最高位然后構造新的數要更快, 至于陣列大小設定為2^n,是為了提高陣列的空間利用率,計算索引的方法是hash&(cap-1),當cap為2^n,cap-1為00001111(忽略前置0)的形式,這樣得到的索引位置為[0,cap-1],每一個位置都由機會,如果cap不為2^n,比如15,那么cap-1為00001110,計算得到的索引只有0,2,4,6,8,10,12,14這些位置,空間利用率只有50%,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/270595.html
標籤:Java
上一篇:一文簡述JAVA內部類和例外