?? 盡人事,聽天命,博主東南大學碩士在讀,熱愛健身和籃球,樂于分享技術相關的所見所得,關注公眾號 @ 飛天小牛肉,第一時間獲取文章更新,成長的路上我們一起進步
?? 本文已收錄于 「CS-Wiki」Gitee 官方推薦專案,現已累計 1.5k+ star,致力打造完善的后端知識體系,在技術的路上少走彎路,歡迎各位小伙伴前來交流學習
?? 如果各位小伙伴春招秋招沒有拿得出手的專案的話,可以參考我寫的一個專案「開源社區系統 Echo」Gitee 官方推薦專案,目前已累計 600+ star,基于 SpringBoot + MyBatis + MySQL + Redis + Kafka + Elasticsearch + Spring Security + ... 并提供詳細的開發檔案和配套教程,公眾號后臺回復 Echo 可以獲取配套教程,目前尚在更新中
本來準備這篇文章一口氣寫完 Hashtable 和 ConcurrentHashMap 的,后來發現 Hashtable 就已經很多了,考慮各位的閱讀體驗,所以 ConcurrentHashMap 就放在下篇文章吧,
OK,繼續上篇文章 HashMap 這套八股,不得背個十來遍? 最后提出的問題來講:
1. 如何保證 HashMap 執行緒安全?
一般有三種方式來代替原生的執行緒不安全的 HashMap:
1)使用 java.util.Collections 類的 synchronizedMap 方法包裝一下 HashMap,得到執行緒安全的 HashMap,其原理就是對所有的修改操作都加上 synchronized,方法如下:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m)
2)使用執行緒安全的 Hashtable 類代替,該類在對資料操作的時候都會上鎖,也就是加上 synchronized
3)使用執行緒安全的 ConcurrentHashMap 類代替,該類在 JDK 1.7 和 JDK 1.8 的底層原理有所不同,JDK 1.7 采用陣列 + 鏈表存盤資料,使用分段鎖 Segment 保證執行緒安全;JDK 1.8 采用陣列 + 鏈表/紅黑樹存盤資料,使用 CAS + synchronized 保證執行緒安全,
不過前兩者的執行緒并發度并不高,容易發生大規模阻塞,所以一般使用的都是 ConcurrentHashMap,他的性能和效率明顯高于前兩者,
2. synchronizedMap 具體是怎么實作執行緒安全的?
這個問題應該很容易被大家漏掉吧,面經中也確實不常出現,也沒啥好問的,不過為了保證知識的完整性,這里還是解釋一下吧,
一般我們會這樣使用 synchronizedMap 方法來創建一個執行緒安全的 Map:
Map m = Collections.synchronizedMap(new HashMap(...));
Collections 中的這個靜態方法 synchronizedMap 其實是創建了一個內部類的物件,這個內部類就是 SynchronizedMap,在其內部維護了一個普通的 Map 物件以及互斥鎖 mutex,如下圖所示:
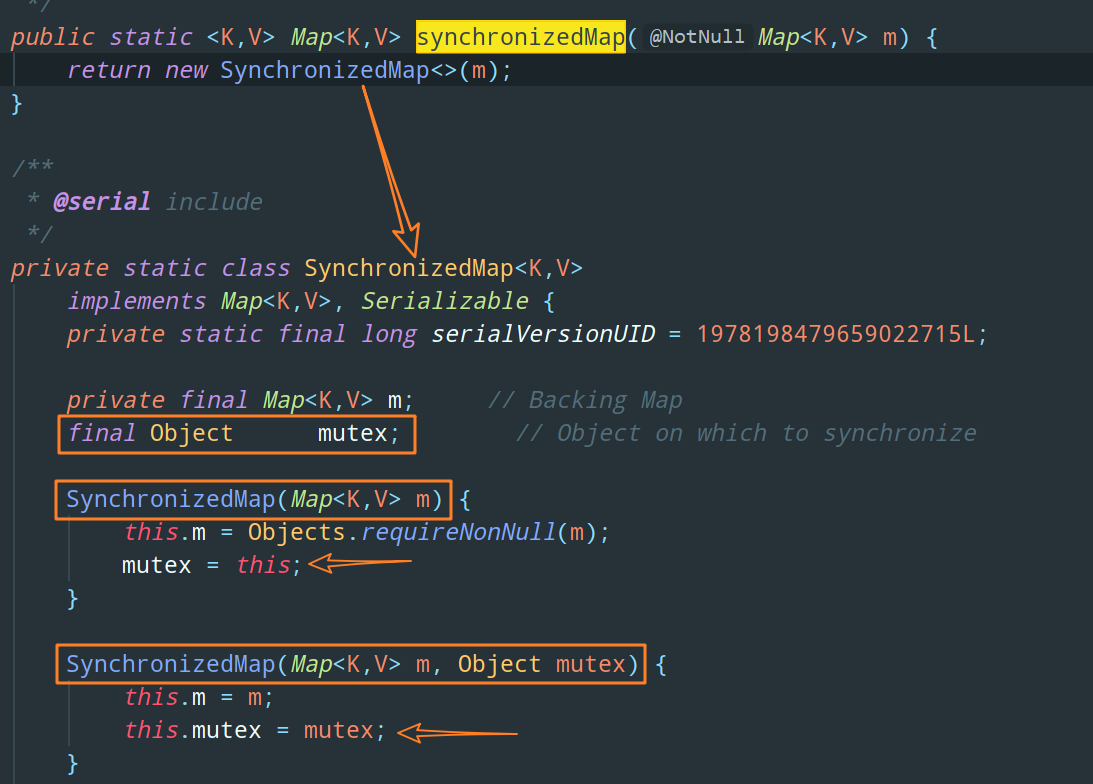
可以看到 SynchronizedMap 有兩個建構式,如果你傳入了互斥鎖 mutex 引數,就使用我們自己傳入的互斥鎖,如果沒有傳入,則將互斥鎖賦值為 this,也就是將呼叫了該建構式的物件作為互斥鎖,即我們上面所說的 Map,
創建出 SynchronizedMap 物件之后,通過原始碼可以看到對于這個物件的所有操作全部都是上了悲觀鎖 synchronized 的:
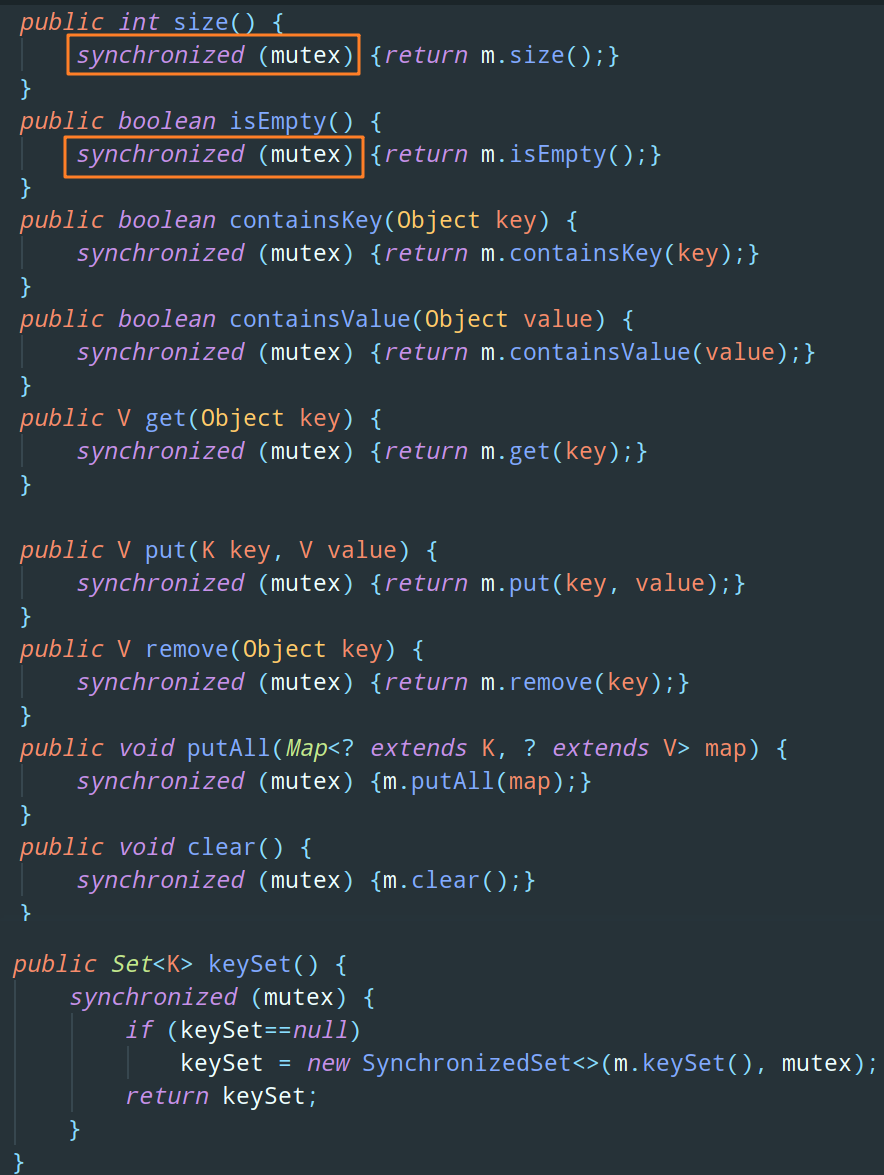
由于多個執行緒都共享同一把互斥鎖,導致同一時刻只能有一個執行緒進行讀寫操作,而其他執行緒只能等待,所以雖然它支持高并發,但是并發度太低,多執行緒情況下性能比較低下,
而且,大多數情況下,業務場景都是讀多寫少,多個執行緒之間的讀操作本身其實并不沖突,所以SynchronizedMap 極大的限制了讀的性能,
所以多執行緒并發場景我們很少使用 SynchronizedMap ,
3. 那 Hashtable 呢?
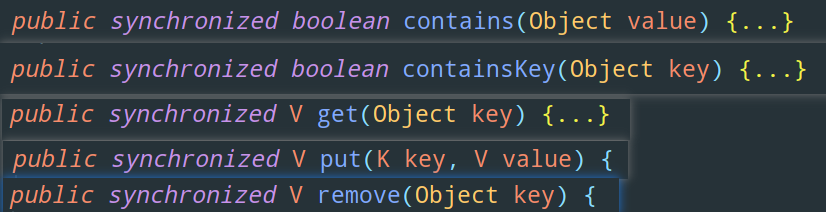
和 SynchronizedMap 一樣,Hashtable 也是非常粗暴的給每個方法都加上了悲觀鎖 synchronized,我們隨便找幾個方法看看:
4. 除了這個之外 Hashtable 和 HashMap 還有什么不同之處嗎?
Hashtable 是不允許 key 或 value 為 null 的,HashMap 的 key 和 value 都可以為 null !!!
先解釋一下 Hashtable 不支持 null key 和 null value 的原理:
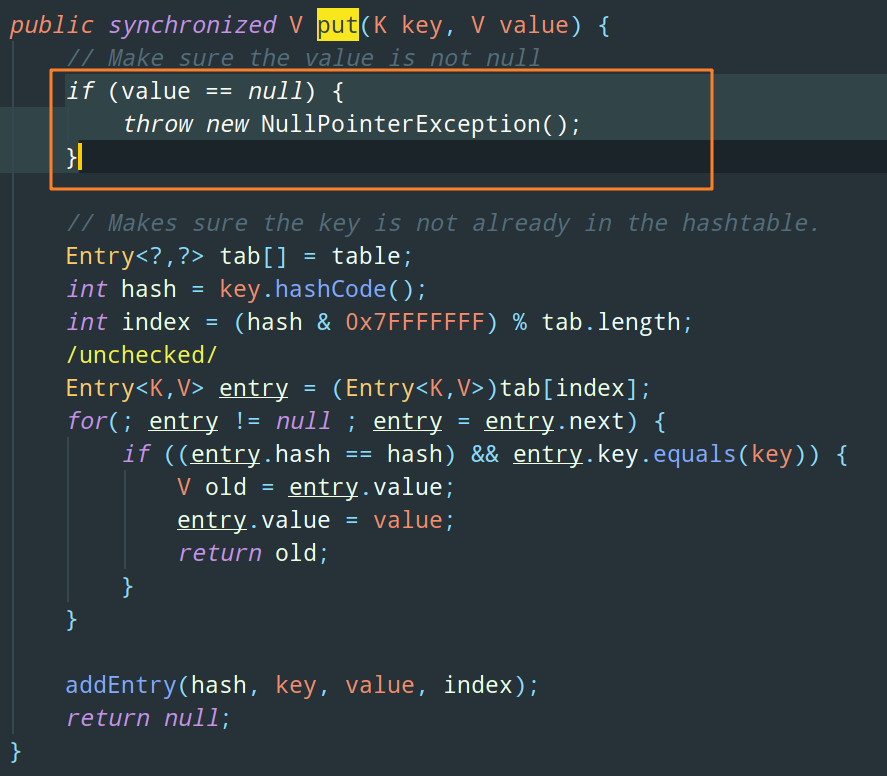
如果我們 put 了一個 value 為 null 進入 Map,Hashtable 會直接拋空指標例外:
2)如果我們 put 了一個 key 為 null 進入 Map,當程式執行到下圖框出來的那行代碼時就會拋出空指標例外,因為 key 為 null,我們拿了一個 null 值去呼叫方法:
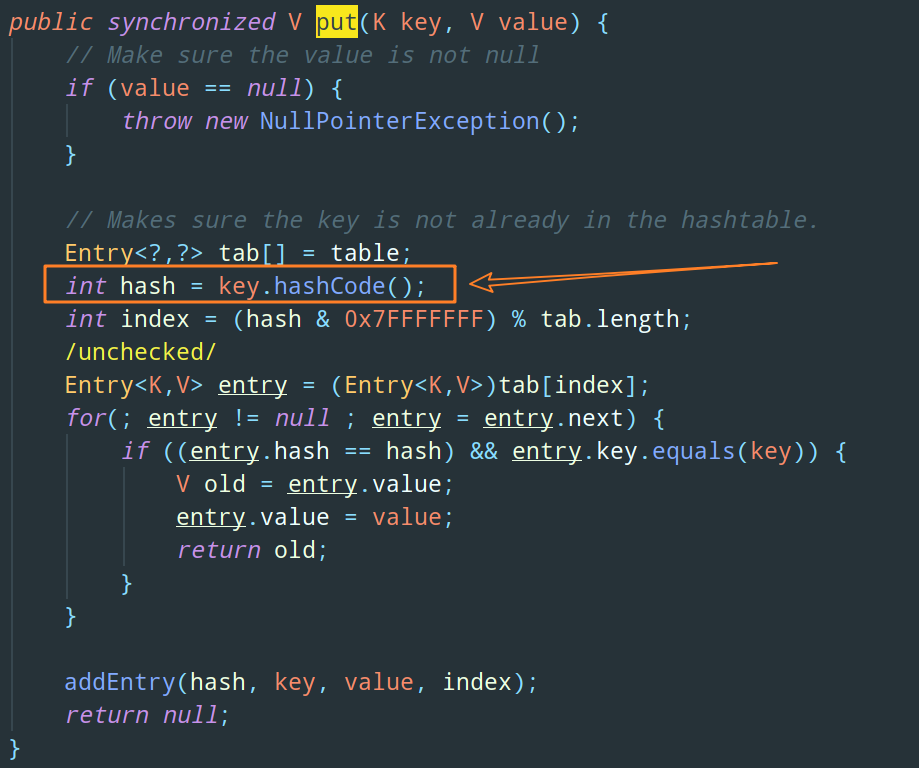
OK,講完了 Hashtable,再來解釋一下 HashMap 支持 null key 和 null value 的原理:
1)HashMap 相比 Hashtable 做了一個特殊的處理,如果我們 put 進來的 key 是 null,HashMap 在計算這個 key 的 hash 值時,會直接回傳 0:
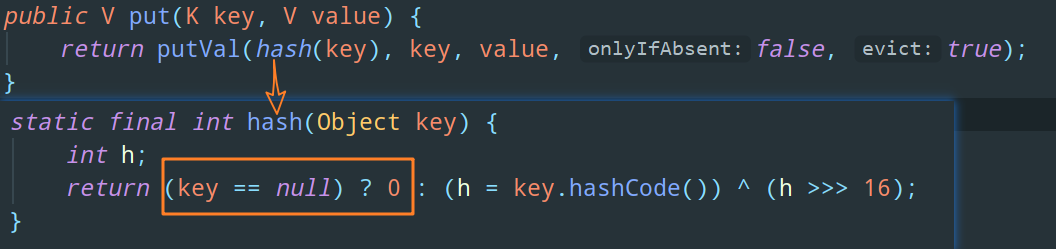
也就是說 HashMap 中 key為 null 的鍵值對的 hash 為 0,因此一個 HashMap 物件中只會存盤一個 key 為 null 的鍵值對,因為它們的 hash 值都相同,
2)如果我們 put 進來的 value 是 null,由于 HashMap 的 put 方法不會對 value 是否為 null 進行校驗,因此一個 HashMap 物件可以存盤多個 value 為 null 的鍵值對:
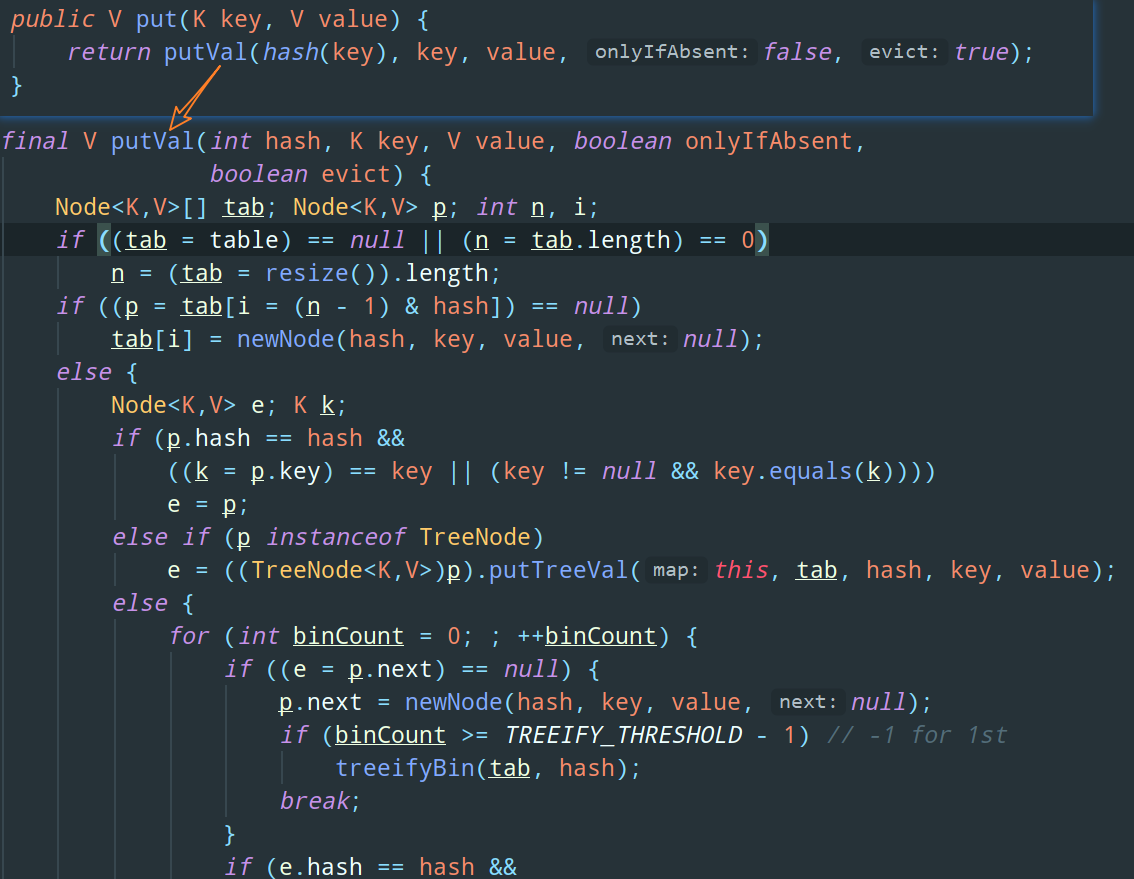
不過,這里有個小坑需要注意,我們來看看 HashMap 的 get 方法:

如果 Map 中沒有查詢到這個 key 的鍵值對,那么 get 方法就會回傳 null 物件,但是我們上面剛剛說了,HashMap 里面可以存在多個 value 為 null 的鍵值對,也就是說,通過 get(key) 方法回傳的結果為 null 有兩種可能:
HashMap中不存在這個 key 對應的鍵值對HashMap中這個 key 對應的 value 為 null
因此,一般來說我們不能使用 get 方法來判斷 HashMap 中是否存在某個 key,而應該使用 containsKey 方法,
5. 那到底為什么 Hashtable 不允許 key 和 value 為 null 呢?為什么這么設計呢?
不止是 Hashtable 不允許 key 為 null 或者 value 為 null,ConcurrentHashMap 也是不允許的,作為支持并發的容器,如果它們像 HashMap 一樣,允許 null key 和 null value 的話,在多執行緒環境下會出現問題,
假設它們允許 null key 和 null value,我們來看看會出現什么問題:當你通過 get(key) 獲取到對應的 value 時,如果回傳的結果是 null 時,你無法判斷這個 key 是否真的存在,為此,我們需要呼叫 containsKey 方法來判斷這個 key 到底是 value = https://www.cnblogs.com/cswiki/archive/2021/04/01/null 還是它根本就不存在,如果 containsKey 方法回傳的結果是 true,OK,那我們就可以呼叫 map.get(key) 獲取 value,
上面這段邏輯對于單執行緒的 HashMap 當然沒有任何問題,在單執行緒中,當我們得到的 value 是 null 的時候,可以用 map.containsKey(key) 方法來區分二義性,
但是!由于 Hashtable 和 ConcurrentHashMap 是支持多執行緒的容器,在呼叫 map.get(key) 的這個時候 map 物件可能已經不同了,
我們假設此時某個執行緒 A 呼叫了 map.get(key) 方法,它回傳為 value = https://www.cnblogs.com/cswiki/archive/2021/04/01/null 的真實情況就是因為這個 key 不能存在,當然,執行緒 A 還是會按部就班的繼續用 map.containsKey(key),我們期望的結果是回傳 false,
但是,在執行緒 A 呼叫 map.get(key) 方法之后,map.containsKey 方法之前,另一個執行緒 B 執行了 map.put(key,null) 的操作,那么執行緒 A 呼叫的 map.containsKey 方法回傳的就是 true 了,這就與我們的假設的真實情況不符合了,
所以,出于并發安全性的考慮,Hashtable 和 ConcurrentHashMap 不允許 key 和 value 為 null,
6. Hashtable 和 HashMap 的不同點說完了嗎?
除了 Hashtable 不允許 null key 和 null value 而 HashMap 允許以外,它倆還有以下幾點不同:
1)初始化容量不同:HashMap 的初始容量為 16,Hashtable 初始容量為 11,兩者的負載因子默認都是 0.75;
2)擴容機制不同:當現有容量大于總容量 * 負載因子時,HashMap 擴容規則為當前容量翻倍,Hashtable 擴容規則為當前容量翻倍 + 1;
3)迭代器不同:首先,Hashtable 和 HashMap 有一個相同的迭代器 Iterator,用法:
Iterator iterator = map.keySet().iterator();
HashMap 的 Iterator 是 快速失敗 fail-fast 的,那自然 Hashtable 的 Iterator 也是 fail-fast 的,Hashtable 是 fail-fast 機制這點很明確,JDK 1.8 的官方檔案就是這么寫的:

但是!!!Hashtable 還有另外一個迭代器 Enumeration,這個迭代器是 失敗安全 fail-safe 的,網路上很多博客提到 Hashtable 就說它是 fail-safe 的,這是不正確的、是存在歧義的!
7. 介紹下 fail-safe 和 fail-fast 機制
fail-safe 和 fail-fast 是一種思想,一種機制,屬于系統設計范疇,并非 Java 集合所特有,各位如果熟悉 Dubbo 的話,一定記得 Dubbo 的集群容錯策略中也有這倆,
當然,這兩種機制在 Java 集合和 Dubbo 中的具體表現肯定是不一樣的,本文我們就只說在 Java 集合中,這兩種機制的具體表現,
1)快速失敗 fail-fast:一種快速發現系統故障的機制,一旦發生例外,立即停止當前的操作,并上報給上層的系統來處理這些故障,
舉一個最簡單的 fail-fast 的例子:
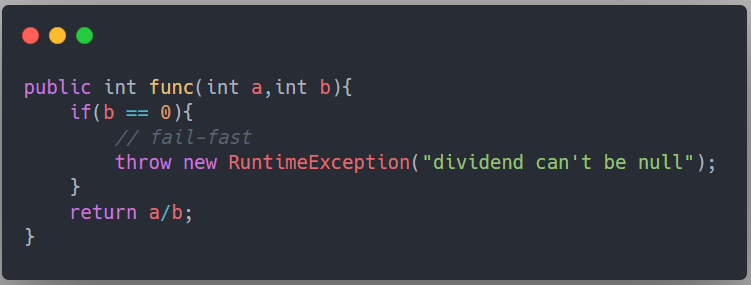
這樣做的好處就是可以預先識別出一些錯誤情況,一方面可以避免執行復雜的其他代碼,另外一方面,這種例外情況被識別之后也可以針對性的做一些單獨處理,
java.util 包下的集合類都是 fail-fast 的,比如 HashMap 和 HashTable,官方檔案是這樣解釋 fail-fast 的:
The iterators returned by all of this class's "collection view methods" are fail-fast: if the map is structurally modified at any time after the iterator is created, in any way except through the iterator's own
removemethod, the iterator will throw aConcurrentModificationException. Thus, in the face of concurrent modification, the iterator fails quickly and cleanly, rather than risking arbitrary, non-deterministic behavior at an undetermined time in the future.
大體意思就是說當 Iterator 這個迭代器被創建后,除了迭代器本身的方法 remove 可以改變集合的結構外,其他的因素如若改變了集合的結構,都將會拋出 ConcurrentModificationException 例外,
所謂結構上的改變,集合中元素的插入和洗掉就是結構上的改變,但是對集合中修改某個元素并不是結構上的改變,我們以 Hashtable 來演示下 fail-fast 機制拋出例外的實體:
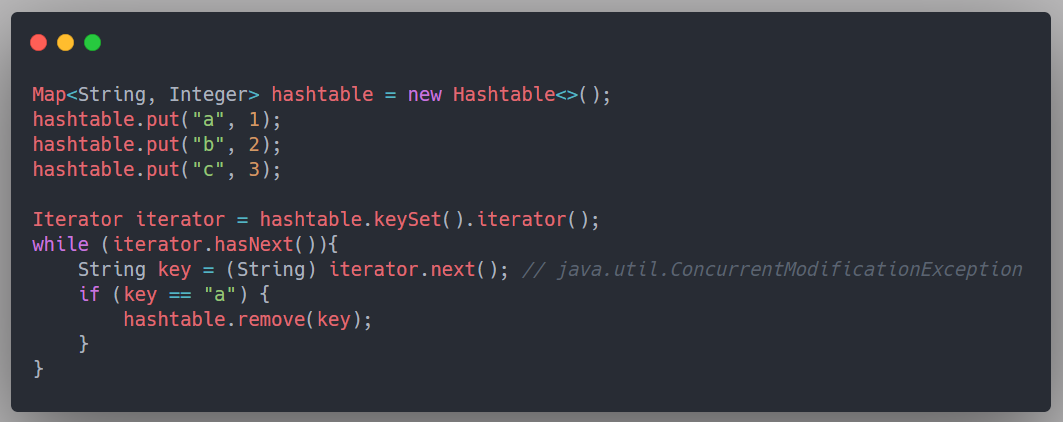
分析下這段代碼:第一次回圈遍歷的時候,我們洗掉了集合 key = "a" 的元素,集合的結構被改變了,所以第二次遍歷迭代器的時候,就會拋出例外,
另外,這里多提一嘴,使用 for-each 增強回圈也會拋出例外,for-each 本質上依賴了 Iterator,
OK,我們接著往下看官方檔案:
Note that the fail-fast behavior of an iterator cannot be guaranteed as it is, generally speaking, impossible to make any hard guarantees in the presence of unsynchronized concurrent modification. Fail-fast iterators throw
ConcurrentModificationExceptionon a best-effort basis. Therefore, it would be wrong to write a program that depended on this exception for its correctness: the fail-fast behavior of iterators should be used only to detect bugs.
意思就是說:迭代器的 fail-fast 行為是不一定能夠得到 100% 得到保證的,但是 fail-fast 迭代器會做出最大的努力來拋出 ConcurrentModificationException,因此,程式員撰寫依賴于此例外的程式的做法是不正確的,迭代器的 fail-fast 行為應該僅用于檢測程式中的 Bug,
2)失敗安全 fail-safe:在故障發生之后會維持系統繼續運行,
顧名思義,和 fail-fast 恰恰相反,當我們對集合的結構做出改變的時候,fail-safe 機制不會拋出例外,
java.util.concurrent 包下的容器都是 fail-safe 的,比如 ConcurrentHashMap,可以在多執行緒下并發使用,并發修改,同時也可以在 for-each 增強回圈中進行 add/remove,
不過有個例外,那就是 java.util.Hashtable,上面我們說到 Hashtable 還有另外一個迭代器 Enumeration,這個迭代器是 fail-safe 的,
HashTable 中有一個 keys 方法可以回傳 Enumeration 迭代器:
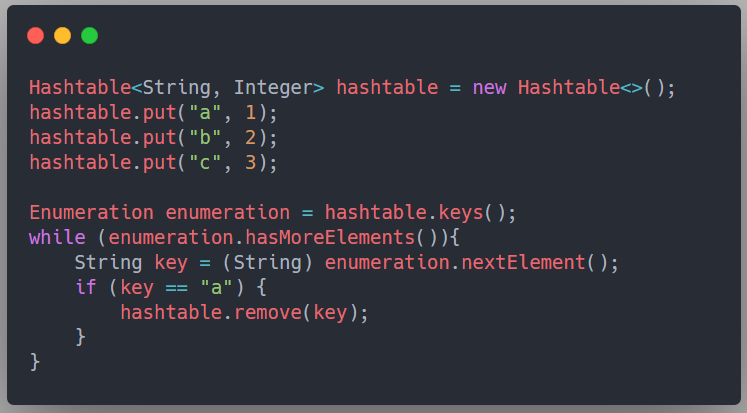
至于為什么 fail-safe 不會拋出例外呢,這是因為,當集合的結構被改變的時候,fail-safe 機制會復制一份原集合的資料,然后在復制的那份資料上進行遍歷,因此,雖然 fail-safe 不會拋出例外,但存在以下缺點:
- 不能保證遍歷的是最新內容,也就是說迭代器遍歷的是開始遍歷那一刻拿到的集合拷貝,在遍歷期間原集合發生的修改迭代器是不知道的;
- 復制時需要額外的空間和時間上的開銷,
8. 講講 fail-fast 的原理是什么
從原始碼我們可以發現,迭代器在執行 next() 等方法的時候,都會呼叫 checkForComodification 這個方法,查看 modCount 和 expectedModCount 是否相等,如果不相等則拋出例外終止遍歷,如果相等就回傳遍歷,
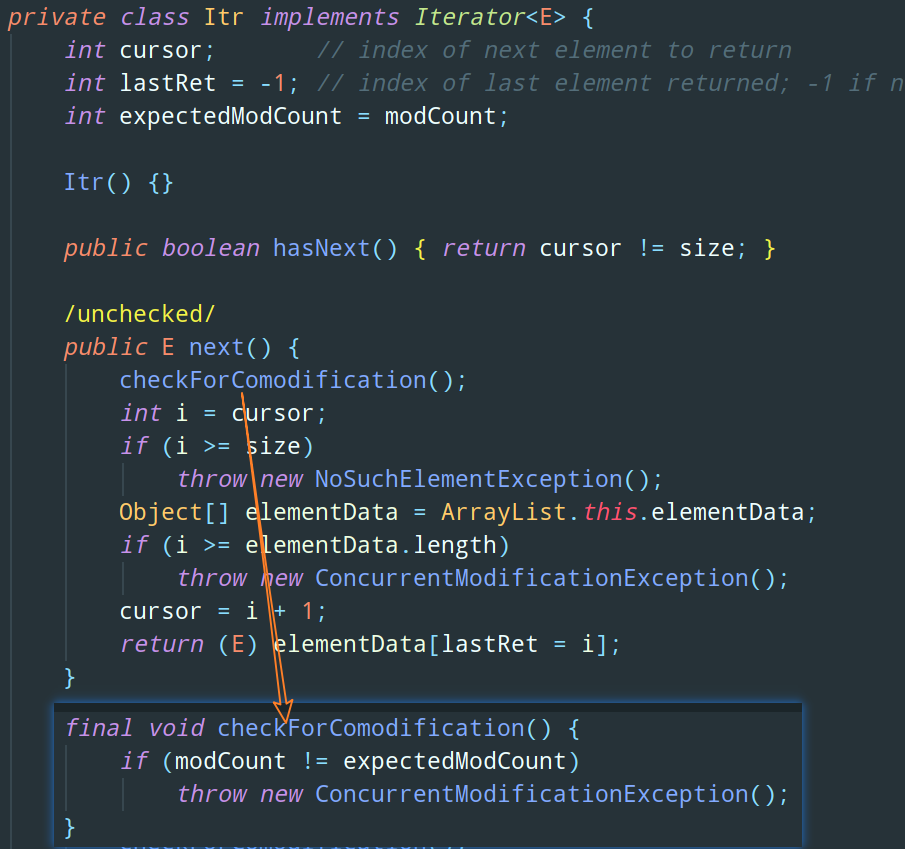
expectedModcount 這個值在物件被創建的時候就被賦予了一個固定的值即 modCount,也就是說 expectedModcount 是不變的,但是 modCount 在我們對集合的元素的個數做出改變(洗掉、插入)的時候會被改變(修改操作不會),那如果在迭代器下次遍歷元素的時候,發現 modCount 這個值發生了改變,那么走到這個判斷陳述句時就會拋出例外,
?? 關注公眾號 | 飛天小牛肉,即時獲取更新
- 博主東南大學碩士在讀,利用課余時間運營一個公眾號『 飛天小牛肉 』,2020/12/29 日開通,專注分享計算機基礎(資料結構 + 演算法 + 計算機網路 + 資料庫 + 作業系統 + Linux)、Java 基礎和面試指南的相關原創技術好文,本公眾號的目的就是讓大家可以快速掌握重點知識,有的放矢,希望大家多多支持哦,和小牛肉一起成長 ??
- 并推薦個人維護的開源教程類專案: CS-Wiki(Gitee 推薦專案,現已累計 1.5k+ star), 致力打造完善的后端知識體系,在技術的路上少走彎路,歡迎各位小伙伴前來交流學習 ~ ??
- 如果各位小伙伴春招秋招沒有拿得出手的專案的話,可以參考我寫的一個專案「開源社區系統 Echo」Gitee 官方推薦專案,目前已累計 600+ star,基于 SpringBoot + MyBatis + MySQL + Redis + Kafka + Elasticsearch + Spring Security + ... 并提供詳細的開發檔案和配套教程,公眾號后臺回復 Echo 可以獲取配套教程,目前尚在更新中,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/270646.html
標籤:其他