目前碩士搬磚,老師給了個任務,下載700篇相關文獻,并且把每篇文獻按照 *年份-期刊名稱-文章題目* 格式來重命名,未處理之前如圖:
處理完成之后如圖:

對于700篇的文獻整理,每一篇要依次點開,尋找對應 “年份 期刊名稱 文章題目” ;這個作業量顯然是災難, 且重復操作沒有營養,想寫一個程式自動完成,
第一步:獲取每一篇文獻的相關資訊,若用程式直接讀取pdf檔案,尋找資訊是相當困難的,因為我的這700篇文獻中“年份 期刊名稱 文章題目”出現位置極不規律,可以說一篇一個樣,隨便貼兩張圖:


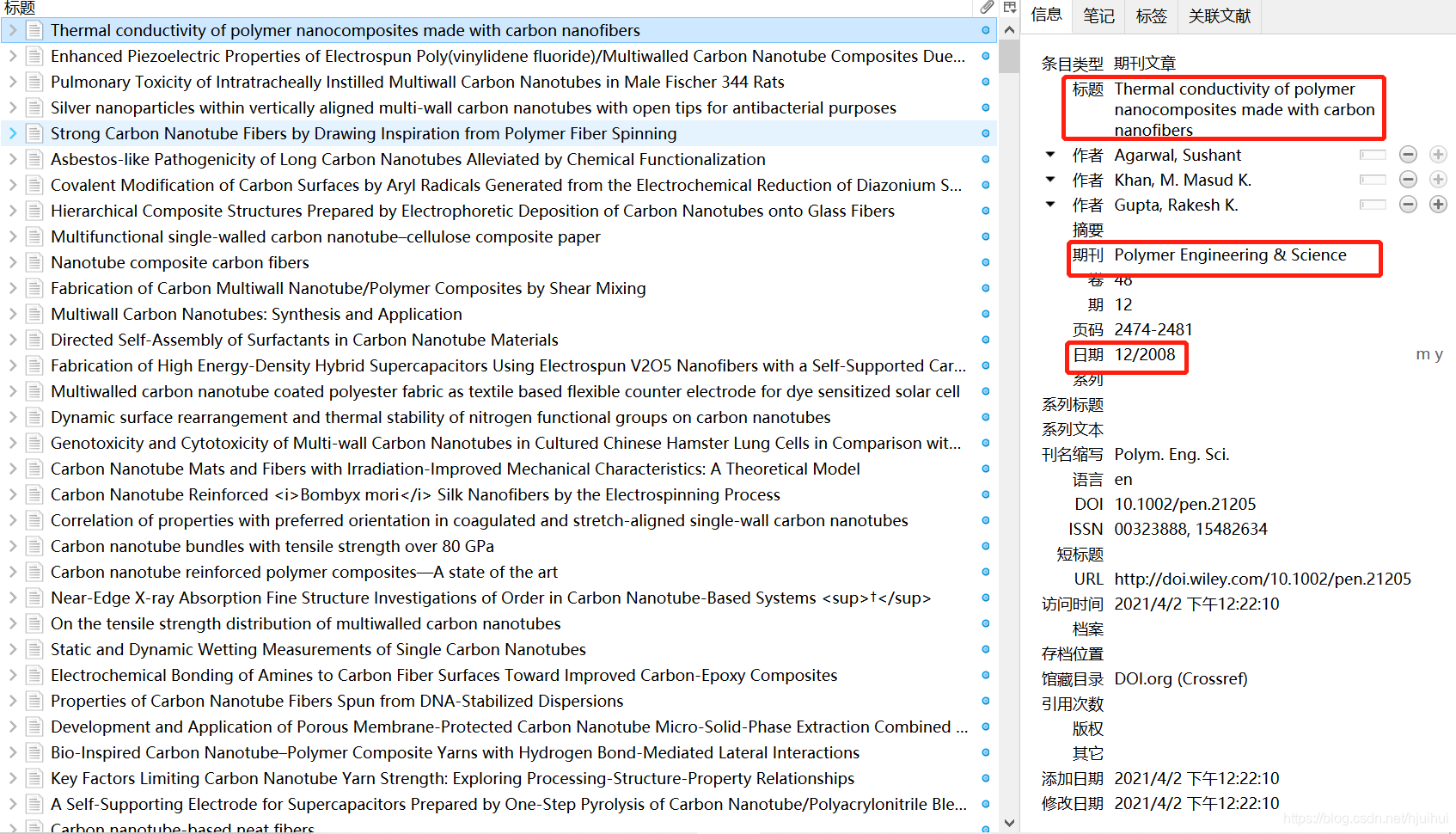
可以看出,*“年份 期刊名稱 文章題目”*出現很不一樣,無法通過一種固定的方法獲取,在“哥們”的幫助之下,獲得了一個神奇的軟體:Zotero,下載鏈接(https://www.zotero.org/download/),把文章匯入之后可以自動獲得一系列資訊,如圖:
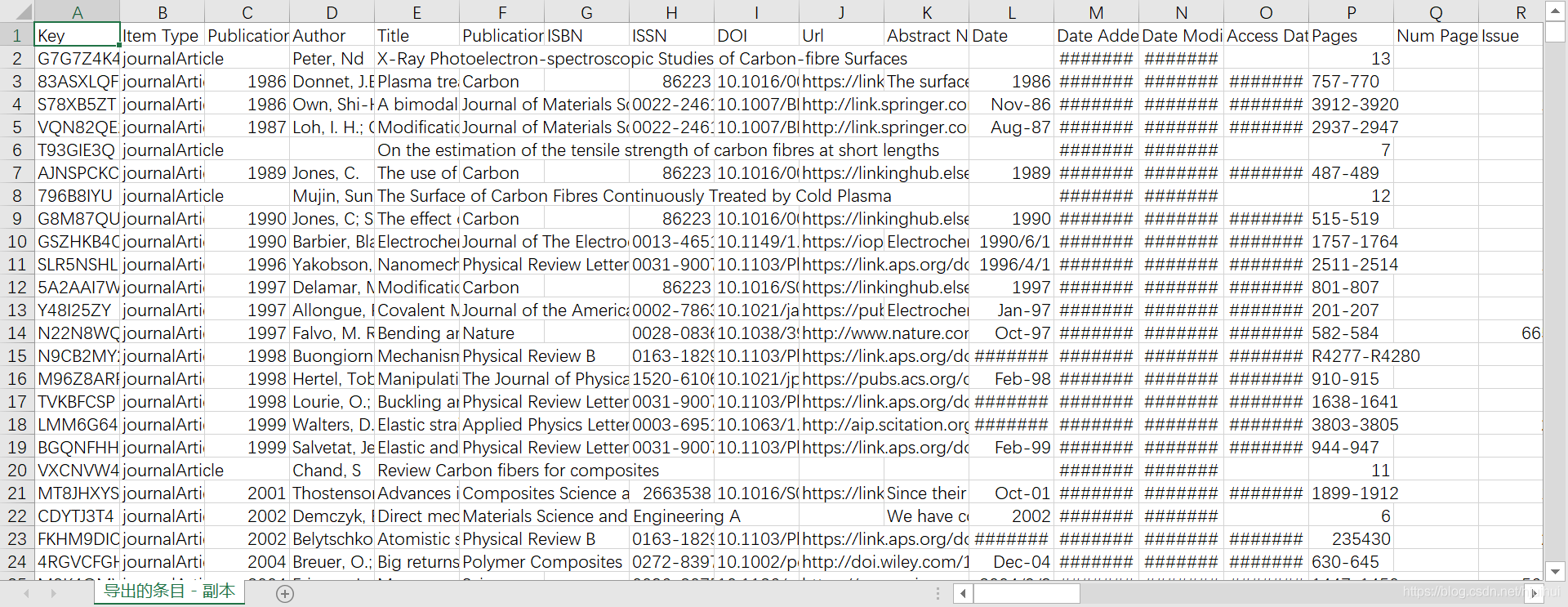
通過匯入的操作,可以獲得每一篇的相關資訊,此軟體可以將這些資訊輸出為.csv檔案,如圖:
第二步:從這里選擇需要的資訊,然后再通過python代碼,就可以批量命名啦,源程式直接上:
import os,csv
path = "C:/Users/e2164\Desktop/2"+"/" #文獻檔案所在位置
new_name = csv.reader(open(r'C:\Users\e2164\Desktop\wenxin.csv', encoding='utf-8')) #匯出的excel檔案所在位置
New=[]
for i in new_name: #獲取表格想要資訊,我這里選擇的是 “年份 期刊名稱 文章題目“
name=i[0]+'-'+i[1]+'-'+i[2] #這是把這些資訊整合在一起
New.append(name)
print('匯入完成')
# 獲取該目錄下所有檔案,存入串列中
f = os.listdir(path)
print(len(f))
print(f[0])
n = 0
i = 0
j = 1
for i in f:
# 設定舊檔案名(就是路徑+檔案名)
oldname = f[n]
# 設定新檔案名
newname = New[n]+'.pdf'
# 用os模塊中的rename方法對檔案改名
try:
os.rename(path+oldname, path+newname)
print(oldname, '======>', newname) #命名成功的
except:
os.rename(path + oldname, path + 'error'+str(j)+'.pdf')
print(j)
j += 1 #命名失敗的
n += 1
注意:
1、有些文獻的題目中含有“/ \ < > * ? : ”,這樣的字符是不允許出現的,所以在表格中把這些符號預先替換掉,從而大大提高成功率,
2、excel檔案中的文獻排列順序要和文獻檔案順序排列一致,否則出現“張冠李戴”,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/272488.html
標籤:python
上一篇:基于Pythion的Selenium自動化測驗(一)搭建環境、常用Webdriver API
下一篇:Python概述