本人前段時間需要用到粒子群優化演算法來求取全域最優解,這個問題用PySwarms來解決,奈何沒有搜索到什么中文檔案講解使用方法,只能抱著英文檔案慢慢啃了QAQ,所以這里把個人見解寫了下來,希望能和有需求的朋友交流,
這里將主要決議Inverse Kinematics Problem這個官方例子,以及從中學到如何使用GlobalBestPSO,
PySwarms的使用:GlobalBestPSO例子決議
- Inverse Kinematics Problem(運動學逆問題)
- 問題背景
- 準備作業
- 運行演算法
- GlobalBestPSO的使用
- 引數(這里只講常用的引數)
- 方法
- optimize引數
- objective_func怎么寫
- optimize回傳值
- 總結
Inverse Kinematics Problem(運動學逆問題)
問題官網網站如下(此問題所有代碼均來自官網):https://pyswarms.readthedocs.io/en/latest/examples/usecases/inverse_kinematics.html
問題背景
逆運動學是機器人技術中最具挑戰性的問題之一,IK坐標難以計算且多解,所以特別困難,現在可以為3自由度機械手找到簡單的解決方案,但是嘗試解決6自由度甚至更多自由度的問題可能會出現富有挑戰性的代數問題,
在此例中,我們將使用具有5個旋轉關節和1個棱柱關節的6自由度斯坦福機械臂,這些關節的活動范圍如下所示:
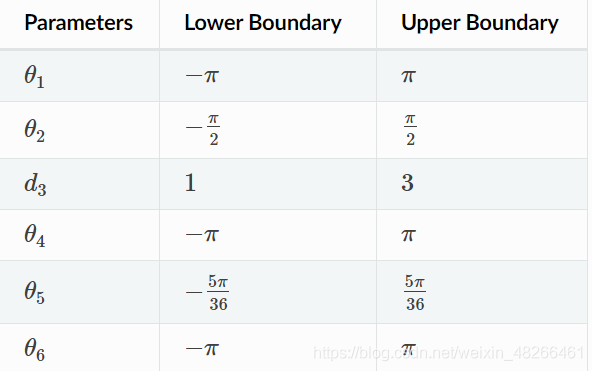
現在,如果給定了末端位置(在本例中為xyz坐標),則需要找到具有上表約束的最佳引數,這些條件足以將這個問題視為優化問題,我們將引數向量X定義如下:
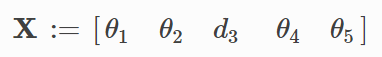
對于末端位置,我們將目標向量T定義為:
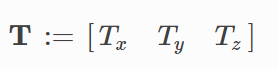
下面就開始解決具體問題吧!
原文后續就開始大致講解粒子群優化演算法的原理,不明白的朋友可以看這篇博客,講解得很清楚,
最優化演算法之粒子群演算法(PSO)
有關粒子群優化演算法的原理這里就不再贅述了,
準備作業
首先匯入相關包:
# Import modules
import numpy as np
# Import PySwarms
import pyswarms as ps
我們以點[?2,2,3]作為目標,希望該點為最佳機械手姿勢,首先定義一個函式來獲取從當前位置到目標位置的距離(可以看出此距離函式就是求兩位置間的歐氏距離):
def distance(query, target):
x_dist = (target[0] - query[0])**2
y_dist = (target[1] - query[1])**2
z_dist = (target[2] - query[2])**2
dist = np.sqrt(x_dist + y_dist + z_dist)
return dist
我們將使用此距離函式來計算代價,顯然距離越遠,距離代價就越高,
下面開始設定演算法需要的引數:
swarm_size = 20
dim = 6 # Dimension of X
epsilon = 1.0
options = {'c1': 1.5, 'c2':1.5, 'w':0.5}
constraints = (np.array([-np.pi , -np.pi/2 , 1 , -np.pi , -5*np.pi/36 , -np.pi]),
np.array([np.pi , np.pi/2 , 3 , np.pi , 5*np.pi/36 , np.pi]))
d1 = d2 = d3 = d4 = d5 = d6 = 3
swarm_size為粒子個數;dim為待求引數的維度;epsilon后續也沒有用到,我也不太明白放在這里的用意,如有大佬告知,不勝感激;options為重要的引數串列,c1為粒子的個體認知系數,c2為群體系數系數,w為慣性因子;constraints為待求引數取值限制;d1~d6為關節長度,均取3,(有關API引數的含義和注意事項后面會詳細介紹)
為了獲得當前位置,我們需要計算每個關節的旋轉和平移矩陣,為此,這里我們使用Denvait-Hartenberg引數,我們定義了一個計算這些矩陣的函式,該函式使用旋轉角度和棱柱形關節的延伸量d作為輸入(不用擔心不明白這是啥引數矩陣,不用明白,只需要知道輸入一些引數回傳一個矩陣就好):
def getTransformMatrix(theta, d, a, alpha):
T = np.array([[np.cos(theta) , -np.sin(theta)*np.cos(alpha) , np.sin(theta)*np.sin(alpha) , a*np.cos(theta)],
[np.sin(theta) , np.cos(theta)*np.cos(alpha) , -np.cos(theta)*np.sin(alpha) , a*np.sin(theta)],
[0 , np.sin(alpha) , np.cos(alpha) , d ],
[0 , 0 , 0 , 1 ]
])
return T
現在我們可以計算變換矩陣以獲得末端的位置,為此,我們創建了另一個函式,該函式將向量X與關節變數作為輸入(同樣不需要知道怎么算的,只需要知道輸入和輸出是什么就好):
def get_end_tip_position(params):
# Create the transformation matrices for the respective joints
t_00 = np.array([[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]])
t_01 = getTransformMatrix(params[0] , d2 , 0 , -np.pi/2)
t_12 = getTransformMatrix(params[1] , d2 , 0 , -np.pi/2)
t_23 = getTransformMatrix(0 , params[2] , 0 , -np.pi/2)
t_34 = getTransformMatrix(params[3] , d4 , 0 , -np.pi/2)
t_45 = getTransformMatrix(params[4] , 0 , 0 , np.pi/2)
t_56 = getTransformMatrix(params[5] , d6 ,0 , 0)
# Get the overall transformation matrix
end_tip_m = t_00.dot(t_01).dot(t_12).dot(t_23).dot(t_34).dot(t_45).dot(t_56)
# The coordinates of the end tip are the 3 upper entries in the 4th column
pos = np.array([end_tip_m[0,3],end_tip_m[1,3],end_tip_m[2,3]])
return pos
為了運行演算法,我們需要準備的最后一件事就是我們要優化的函式,我們只需要計算每個群體粒子的位置與目標點之間的距離即可(這里就是運用到前面定義的函式get_end_tip_position進行計算X[i]的末端位置,再運用distance函式計算此位置與目標點之間的距離,回傳這個距離陣列):
def opt_func(X):
n_particles = X.shape[0] # number of particles
target = np.array([-2,2,3])
dist = [distance(get_end_tip_position(X[i]), target) for i in range(n_particles)]
return np.array(dist)
運行演算法
經過上述準備,我們終于可以開始實作演算法了!
# Call an instance of PSO
optimizer = ps.single.GlobalBestPSO(n_particles=swarm_size,
dimensions=dim,
options=options,
bounds=constraints)
# Perform optimization
cost, joint_vars = optimizer.optimize(opt_func, iters=1000)
很簡單的樣子!?(并沒有,自己寫待優化函式的時候呢QAQ)代入上面說的引數實體化一個全域最優器物件,再呼叫其優化方法便可以得到我們上面設定的代價值和待求引數值,
print(get_end_tip_position(joint_vars))
[-2.09012905 2.07694604 3.01641479]
再查看我們求取的引數值計算得到的末端坐標,幾乎就是我們的目標坐標值,成功啦!
下面開始最關鍵的使用部分啦!
GlobalBestPSO的使用
我舉上面的官網例子其實也是因為我就是看那個例子學會的,下面就開始介紹GlobalBestPSO的使用方法吧!
引數(這里只講常用的引數)
- n_particles :int,粒子群中的粒子數,一般取 20–40,如果是比較難的問題或者特定類別的問題,粒子數可以取到100 - 200,
- dimensions:int,待求取引數的維度,
- options:dict,引數c1,c2,w的設定,
使用帶有關鍵字{‘c1’, ‘c2’, ‘w’}的字典 ,這里再重復一遍各關鍵字的含義:c1為粒子的個體認知系數,c2為群體系數系數,w為慣性因子,
c1和c2取值通常相等,且常取值為2,當然取值0-4也有,
w較大時全域搜索能力強,較小時區域搜索能力強, - bounds:numpy.ndarray,待求引數的取值范圍,
兩行的ndarray,第一行為待求引數的最小值,第二行為最大值,很重要的一點是,列的大小要和輸入的引數維度匹配,并且還要注意每一個引數范圍的對齊,不要錯位了, - init_pos:numpy.ndarray,初始位置的設定,
不設定的話,粒子初始位置則是隨機的,
方法
其實我認為最重要的是這個方法里待優化方程的寫法QAQ,下面就開始了!
optimize引數
- objective_func :callable,求取最優解的方程,
objective_func怎么寫
說實話API檔案并沒有明確給出這個函式怎么寫:)
這里我們以一個簡單的二元二次為例,來看這個函式到底怎么寫,
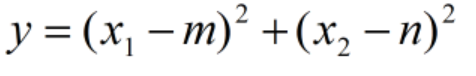
顯然取全域最優也就是方程取最小值,此時x1=m,x2=n,
最最重要的一點就是待求引數要放在第一個,可以取名x,y等等等等,后面引數放多少都可以(當然夸張了),其實就是類似于可變引數函式的引數規則,第一個引數是我們現在需要求的引數,所以自然不能傳遞值,其余引數就必須要有確定的值,
還有一點也是需要特別注意的是:放在第一個位置的引數在多維時,在使用第i個引數時,需要采用 x[: ,i] 這樣的形式,否則會出錯,
明確完這兩點之后就可以開始寫函式了:
import pyswarms as ps
swarm_size = 20
dim = 2 # Dimension of paramater vetcor X
options = {'c1': 0.5, 'c2': 0.3, 'w': 0.9}
optimizer = ps.single.GlobalBestPSO(n_particles=swarm_size,
dimensions=dim,
options=options)
def func(x,m=2,n=2):
f = (x[:,0]-m)**2+(x[:,1]-n)**2
return f
cost, pos = optimizer.optimize(func,iters=1000,m=3,n=1)
運行結果如下:

- iters:int,迭代次數,這個引數可以根據待解決問題的大小來選擇,
- kwargs :dict,上述方程的輸入引數,也可以在后面按引數名傳遞引數值,
optimize回傳值
全域最小代價和全域最優位置,
總結
只要設定了合適的PSO優化演算法引數,寫好了待優化函式,理論上就能運用GlobalBestPSO求得全域最小代價和全域最優位置,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/272499.html
標籤:python
下一篇:java筆記--IO流