文章目錄
- 前言
- 一、合并與分割
- 1.張量合并
- 2.張量分割
- 二、數學運算
- 1.張量的四則運算
- 2.張量的冪指運算
- 3.張量的近似運算
- 4.裁剪
- 三、合并與分割
- 1.范數
- 2.序號索引
- 1.未指定索引軸時
- 2.指定索引軸時
- 3.保持維度
- 3.保留前K個值(TOP-K)
- 4.邏輯關系( > < = !=)
- 四、where與gather
- 1.where 條件賦值
- 2.gather
- 總結
前言
補充一些常用的張量操作,
一、合并與分割
1.張量合并
torch.cat([a,b],dim = c) 用于合并張量,但是要保證張量的資料維度可以合并不會出錯(即在要合并的軸 資料維度可以不一樣,但是其他的軸資料要保持維度相同),
a,b :指要合并的資料,c 表示要合并的所在軸,
代碼如下:
import torch
a = torch.rand(4,3,28,28)
b = torch.rand(6,3,28,28)
#除0軸資料維度可以不一樣(4和6),1,2,3軸資料維度都相同故可以合并
c = torch.cat([a,b],dim = 0)
#除1軸資料維度可以不同也可以相同(3,3);1軸據維度不同(4,6);
# 2,3軸資料維度都相同故不可以合并,列印出錯
# d = torch.cat([a,b],dim = 1)
print(c.shape)
# print(d.shape)

torch.stack([a,b],dim = c) 會在dim指定軸之前增加新的維度,但在指定軸的資料維度比==.cat()== 要求更嚴格同樣必須一致,
代碼如下:
import torch
a = torch.rand(4,3,28,28)
b = torch.rand(6,3,28,28)
#除0軸資料維度必須保持相同(4和6 不同 會出錯),1,2,3軸資料維度都相同否則會無法合并報錯
c = torch.stack([a,b],dim = 0)
print(c.shape)
輸出結果:

代碼如下:
import torch
a = torch.rand(6,3,28,28)
b = torch.rand(6,3,28,28)
#除0軸資料維度必須保持相同(6和6),1,2,3軸資料維度都相同否則會無法合并報錯
c = torch.stack([a,b],dim = 0)
print(c.shape)
輸出結果:

2.張量分割
.split(a,dim = b) 將張量按照a的指定長度在b軸上進行拆分,
.chunk(a,dim = b) 將張量拆分成a個數量在b軸上進行拆分,
代碼如下:
import torch
a = torch.rand(6,3,28,28)
print(a.shape)
#split以長度進行拆分,3是指長度,每n個進行一個拆分,要有接受資料要保持對應
b,c,d =a.split(2,dim=0)
print(b.shape,c.shape,d.shape)
b,c = a.split(3,dim=0)
print(b.shape,c.shape)
print("********************************************************************")
#chunk,是拆分成指定的n個
b,c = a.chunk(2,dim = 0)
print(b.shape,c.shape)
b,c,d =a.chunk(3,dim=0)
print(b.shape,c.shape,d.shape)
輸出結果:

二、數學運算
1.張量的四則運算
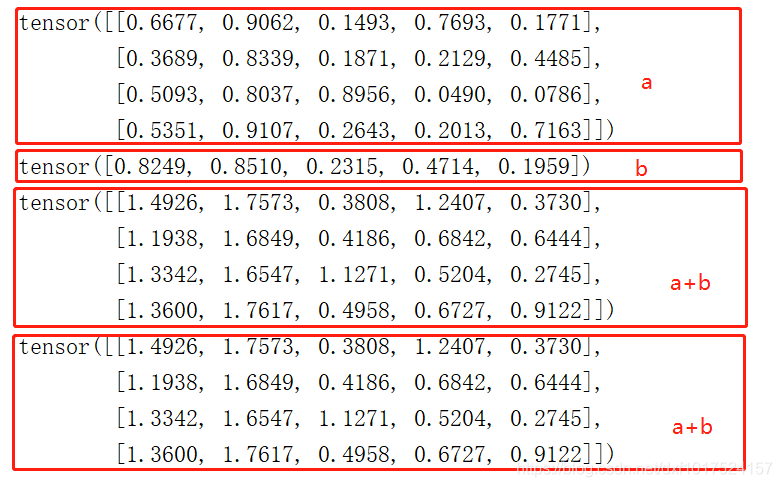
加法:若相加資料的維度不同,符合廣播機制的會廣播后再相加,
+號 可以使用加號進行相加,
torch.add() 也可以呼叫add方式相加,
代碼如下:
import torch
a = torch.rand(4,5)
b = torch.rand(5)
print(a)
print(b)
#因為b的維度不夠所有且符合廣播機制,torch會將b廣播成與a相同然后相加
#加法具有兩種實作形式,一種是+號,另一種是呼叫add方式
print(a+b)
print(torch.add(a,b))
輸出結果:
減法
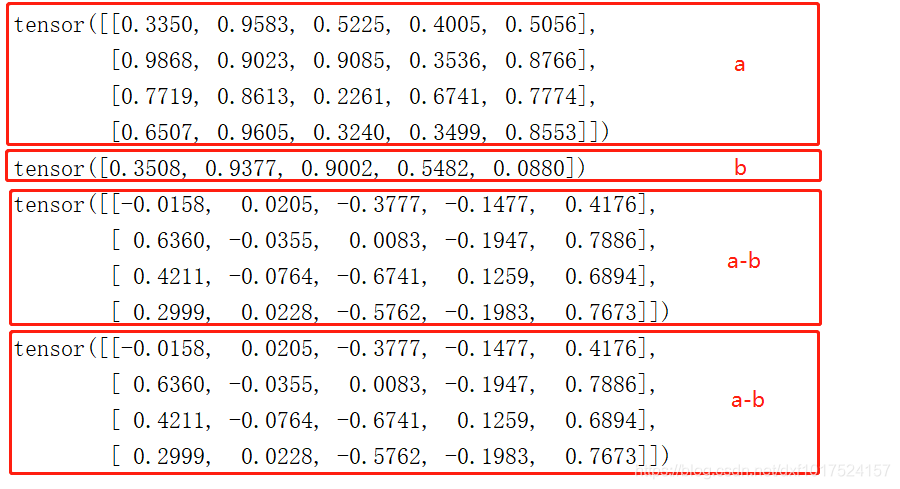
-號 可以使用多載運算子減號進行相減,
torch.sub() 也可以呼叫sub(減法:subtraction)方式相減,
代碼如下:
import torch
a = torch.rand(4,5)
b = torch.rand(5)
print(a)
print(b)
print(a-b)
print(torch.sub(a,b))
輸出結果:
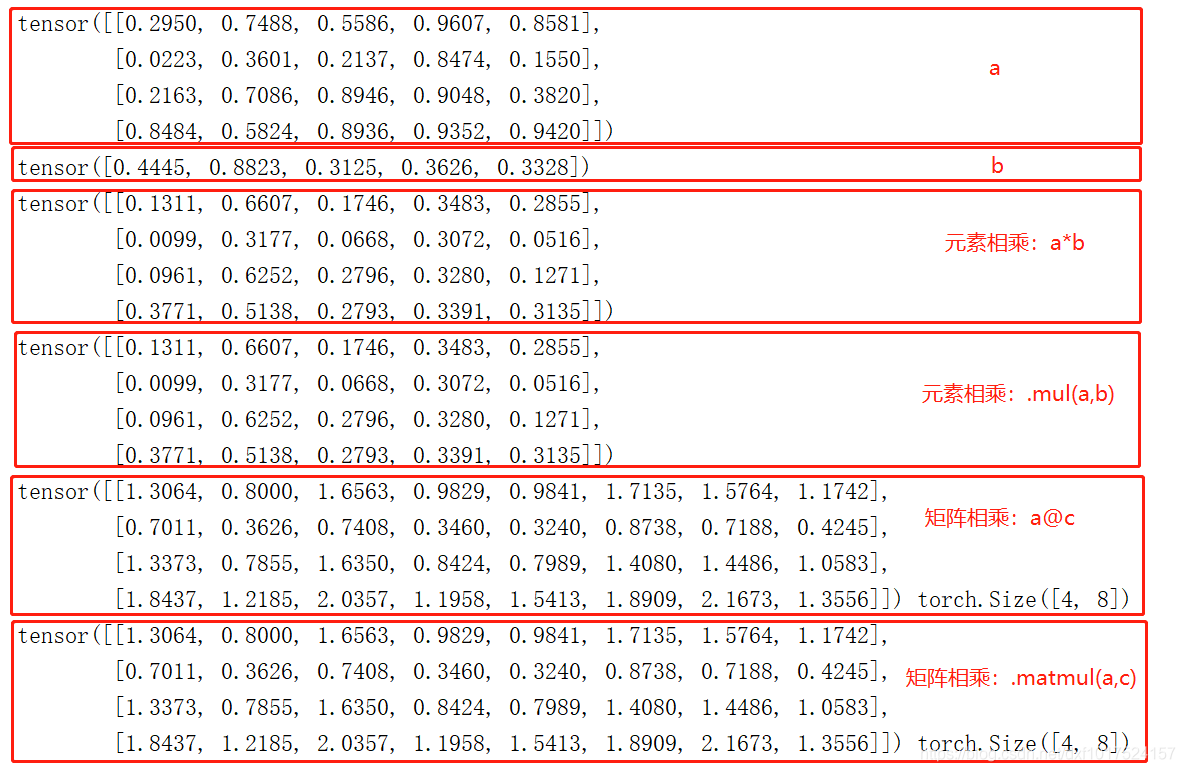
乘法:乘法分為元素相乘(即對應位置的元素想乘)和矩陣乘法,
元素相乘:
*號 :可以使用多載運算子星號進行對應元素相乘,
torch.mul() :也可以呼叫mul(乘法:multiply)方法相乘,
矩陣乘法:需滿足矩陣的運算規則,如A的列數(4行5列),等于C的行數(5行8列)得到新的維度(4行8列)
.mm(a,c)號 :僅適用于2D張量矩陣(不推薦),
@ :多載運算子符號號進行矩陣相乘,
torch.matmul() :也可以呼叫.matmul()方法進行矩陣相乘,(在3D、4D等多維張量矩陣乘法中,只計算最后兩個軸,如(1,2,3,4)@(1,2,4,5)=(1,2,3,5))
代碼如下:
import torch
a = torch.rand(4,5)
b = torch.rand(5)
c = torch.rand(5,8)
print(a)
print(b)
#各對應元素相乘
print(a*b)
print(torch.mul(a,b))
#矩陣乘法:torch.mm(僅適用于2D矩陣相乘,不推薦);@符號多載的矩陣乘號;.matmul()函式等三種方法
#矩陣乘法要滿足矩陣的運算規則:即A的列數(4行5列),等于的行數C(5行8列)得到新的維度(4行8列)
d = a@c
e = torch.matmul(a,c)
print(d,d.shape)
print(e,e.shape)
輸出結果:
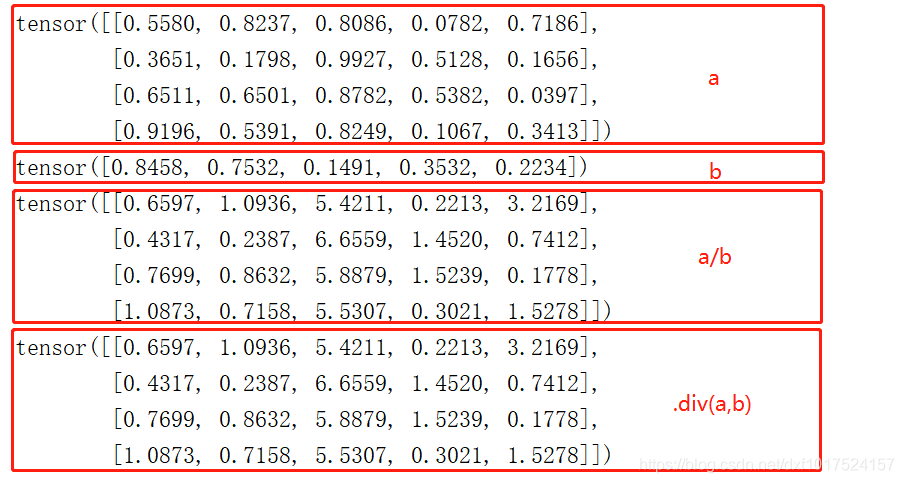
除法:
/號 :可以使用多載運算子 / 號進行對應元素相除,
torch.div() :也可以呼叫div(除法:divide)方法相除,
代碼如下:
import torch
a = torch.rand(4,5)
b = torch.rand(5)
print(a)
print(b)
#各對應元素相除
print(a/b)
print(torch.div(a,b))
輸出結果:
2.張量的冪指運算
.pow(a) :計算x的a次方,也可以使用兩個星號來代替 **(),
.sqrt() :開平方根,同樣可以使用 **(0.5)
.rsqrt() :開平方根后的倒數,
代碼如下:
import torch
a = torch.full((3,3),4)
#平方
b = a.pow(2)
#3次方
c = a**(3)
#開平方根
d = a.sqrt()
e = a.pow(0.5)
#平方根的倒數
f = a.rsqrt()
print(a)
print(b)
print(c)
print(d)
print(e)
print(f)
輸出結果:

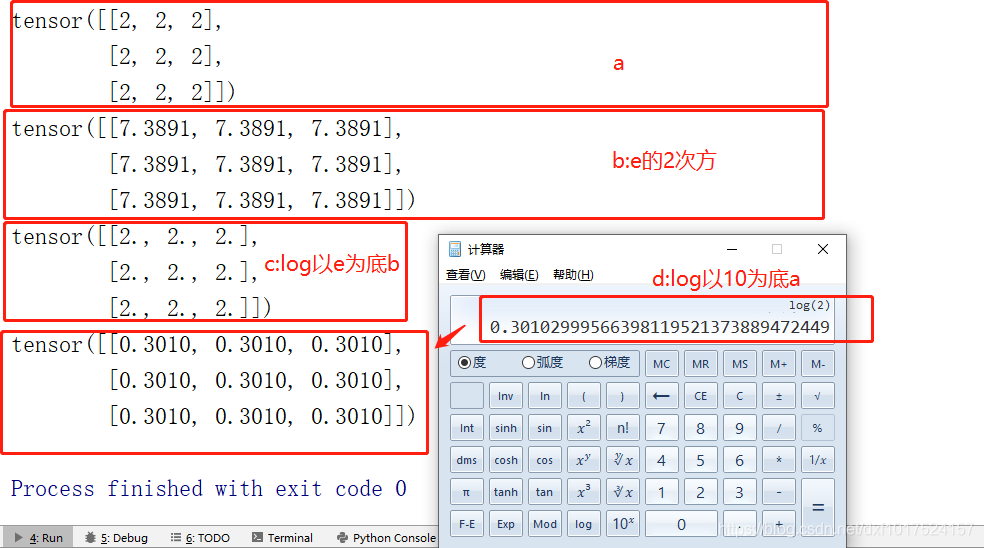
.exp(a) :計算以e的a次方,
.log(a) :計算以e為底log(a),
.rsqrt() :計算以10為底log(a),
代碼如下:
import torch
a = torch.full((3,3),2)
#對a每個數均進行e的指定次方
b = torch.exp(a)
# log默認以2為底
c = torch.log(b)
#log 函式以10為底
d = torch.log10(a)
print(a)
print(b)
print(c)
print(d)
輸出結果:
3.張量的近似運算
.floor() :向下取整,
.ceil(a) :向上取整,
.trunc() :截取整數部分,
.frac() :截取小數部分,
.round() :對小數部分進行四舍五入,
代碼如下:
import torch
a = torch.tensor(5.64)
#向下取整
print(a.floor())
#向上取整
print(a.ceil())
#截取整數部分
print(a.trunc())
#截取小數部分
print(a.frac())
#對小鼠部分進行四舍五入
print(a.round())
輸出結果:

4.裁剪
.clamp(a,b) :將資料裁剪到 a 到 b 之間,(常用于對梯度裁剪,防止梯度爆炸的情況出現)
代碼如下:
import torch
a = torch.rand(3,3)*20
print(a)
print(a.min())
print(a.median())
print(a.max())
#將資料裁剪到 5-15之間,小于5的以5代替,大于15的以15代替
b = a.clamp(5,15)
print(b)
輸出結果:

三、合并與分割
1.范數
1范數 :所有資料絕對值之和,
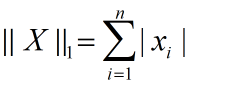
2范數 :所有資料的平方和開根號,
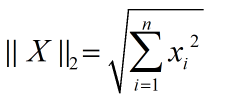
p范數 :所有資料的p次方和開p根號,
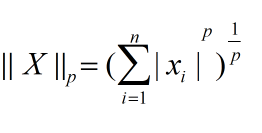
1范數和2范數,未指定軸分析 :即對所有的數的絕對值求和,以及開根號,
代碼如下:
a = torch.full([8],1.)
b = torch.full((2,4),1.)
c = torch.full((2,3,4),1.)
print(a)
print(b)
print(c)
# 1范數:所有資料的絕對值之和 , 2范數平方和開根號
print(a.norm(1),b.norm(1),c.norm(1))
print(a.norm(2),b.norm(2),c.norm(2))
輸出結果:

1范數和2范數,以c為例在指定軸分析 :C為3D張量分別再0,1,2三個指定軸求1范數,分析資料的計算,
0軸:c的形狀為(2,3,4),在0軸分析,如果未設定軸保留=truse,則1 范數形狀應為(3,4)

1軸:c的形狀為(2,3,4),在1軸分析,如果未設定軸保留=truse,則1 范數形狀應為(2,4),可以理解對在垂直方向相加,

2軸:c的形狀為(2,3,4),在2軸分析,如果未設定軸保留=truse,則1 范數形狀應為(2,3),可以理解對在水平方向相加,

代碼如下:
import torch
c = torch.full((2,3,4),1.)
print(c)
#在指定的軸求范數
#0軸
print(c.norm(1,dim=0))
print(c.norm(2,dim=0))
#1軸
print(c.norm(1,dim=1))
print(c.norm(2,dim=1))
#2軸
print(c.norm(1,dim=2))
print(c.norm(2,dim=2))
2.序號索引
.min() :獲取張量資料中的最小值,
.max() :獲取張量資料中的最大值,
1.未指定索引軸時
pytorch采用的是將整個張量打平和1D張量,根據最大值和最小值獲取位置索引,
.argmin() :獲取打平后張量資料中的最小值索引,
.argmax() :獲取打平后張量資料中的最大值索引,
2.指定索引軸時
代碼如下:
import torch
a = torch.arange(24).view(2,3,4).float()
print(a)
#列印張量的最大值和最小值
print(a.min(),a.max())
#列印張量最大值,最小值對應的索引,無引數指定時默認flatten
print(a.argmin(),a.argmax())
#若不想打平,則需要指定軸
#0軸可以理解未垂直方向取索引
print(a.argmin(dim=0))
print(a.argmax(dim=0))
#1軸可以理解為水平方向取索引
print(a.argmin(dim=1))
print(a.argmax(dim=1))
#1軸可以理解為水平方向取索引
print(a.argmin(dim=2))
print(a.argmax(dim=2))
0軸:a的形狀為(2,3,4),在0軸索引分析,是對應位置索引,索引值形狀未(3,4),

1軸:a的形狀為(2,3,4),在1軸索引分析,可以理解為豎向(垂直)取索引,索引值形狀未(2,4),

2軸:a的形狀為(2,3,4),在2軸索引分析,可以理解為橫向(水平)取索引,索引值形狀未(2,3),

3.保持維度
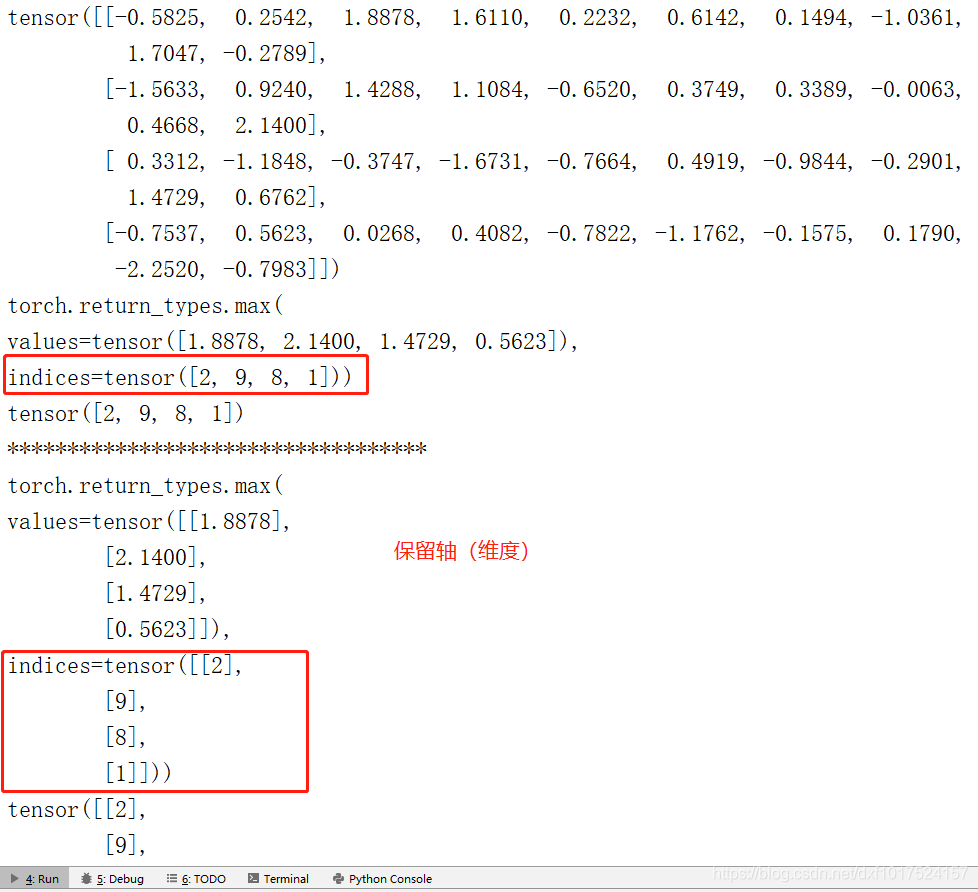
keepdim :對指定的軸取索引時,如果保持軸數不變需要使用 keepdim 保持,
代碼如下:
import torch
a = torch.randn(4,10)
print(a)
#列印在1軸最大值及對應索引
print(a.max(dim=1))
#列印索引
print(a.argmax(dim =1))
print("***********************************")
#列印在1軸最大值及對應索引,保留軸
print(a.max(dim=1,keepdim = True))
#列印索引
print(a.argmax(dim =1,keepdim = True))
輸出結果:
3.保留前K個值(TOP-K)
在分類問題中,由于各種原因,可能會出現,分類的某一問題概率值并不高,為了更準確的分類,我們會需要保留的大的前K個概率,進一步判斷藥分類的類別,
.topk(a) :保留前a個概率值,
.kthvalue(a) :需要注意的是保留第a個小的,并且只能設定為小,
代碼如下:
import torch
a = torch.randn(2,8)
print(a)
#largest 默認為True取最大的前k個,False取最小的前k個
#取最大的前3個及對應的索引號
print(a.topk(3,dim=1))
#取最小的前3個及對應的索引號
print(a.topk(3,dim=1,largest = False))
#取第k個小的值,只能取小
print(a.kthvalue(1,dim=1))
輸出結果:

4.邏輯關系( > < = !=)
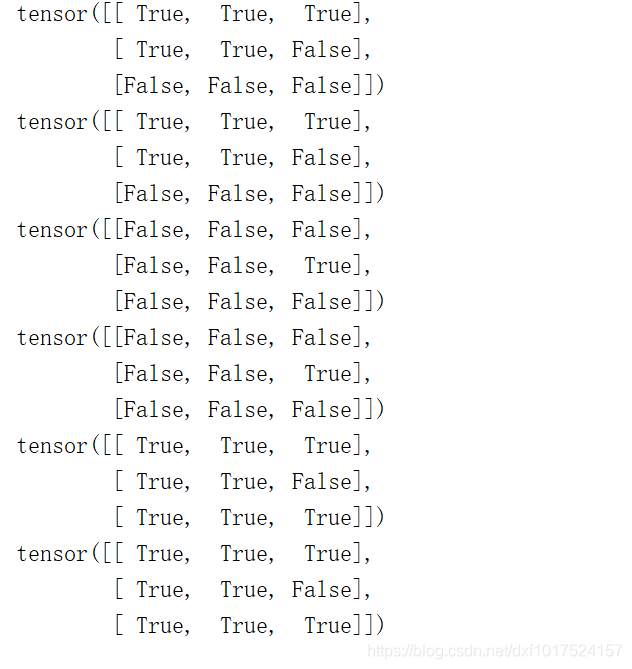
大于:可以直接用多載運算子 > 或者==.gt()== 大于(great)比較,
小于:可以直接用多載運算子 < 或者==.lt()== 小于比較,
等于:可以直接用多載運算子 == 或者 .eq() 等于(equal),
不等于:可以直接用多載運算子 != 或者 .not_equal() ,
代碼如下:
import torch
a = torch.arange(9).view(3,3)
print(a)
#大于
print(a>5)
print(torch.gt(a,5))
#小于
print(a<5)
print(torch.lt(a,5))
#等于
print(a == 5)
print(torch.eq(a,5))
#不等于
print(a != 5)
print(torch.not_equal(a,5))
輸出結果:

四、where與gather
1.where 條件賦值
.where(condition , x, y ) :如果滿足條件,會將x中對應元素賦值給輸出,不滿足則將y對應數值賦給輸出,
代碼如下:
import torch
condation = torch.randn(3,3)
print(condation)
x = torch.full((3,3),0.)
print(x)
y = torch.full((3,3),1.)
print(y)
#where 用法
print(torch.where(condation>0.5,x,y))
輸出結果:

2.gather
.gather(input , dim, index,out =None) :將資料索引映射到所需要的位置,
代碼如下:
import torch
#資料
data = torch.randn(3,6)
print(input)
#索引 在輸入的資料中在1軸上去前2個最大值及索引
indexz_data = data.topk(2,dim=1)
print(indexz_data)
idx = indexz_data.indices
#將資料索引映射到另一個位置 [50 - 56]
label = torch.arange(6) + 50
print(label)
#使用gathe進行對應查找
print(torch.gather(label.expand(3,6),dim=1,index = idx))
輸出結果:

總結
本節,承上對Pytorch中常用的一些方法進行補充和解釋,敬請小伙伴們批評指正,學習討論,覺得有價值,勞駕動動食指,點個贊哈,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/272885.html
標籤:python