我們已經可以從網上爬取資料了,現在我們來看看如何對資料決議
文章目錄
- 1. xpath 的介紹
- 優點:
- 安裝lxml庫
- XML的樹形結構:
- 選取節點的運算式舉例:
- 2. 爬取起點小說網
- 在瀏覽器中獲取書名和作者測驗
- 使用xpath獲取起點小說網的資料
1. xpath 的介紹
xpath是一門在XML檔案中查找資訊的語言
優點:
- 可以在xml中找資訊
- 支持HTML的查找
- 可以通過元素和屬性進行導航
但是Xpath需要依賴xml的庫,所以我們需要去安裝lxml的庫,
安裝lxml庫
我們先要安裝lxml的庫,直接在pycharm里安裝即可:
XML的樹形結構:
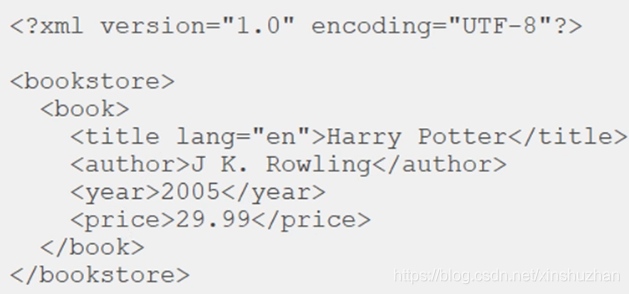
根元素-元素-屬性-文本
使用XPath選取節點:
- nodename: 選取此節點的所有節點
- /從根節點選擇
- // 從匹配選擇的當前節點選擇檔案中的節點,而不考慮他們的位置
- . 選擇當前節點
- … 選擇當前節點的父節點(此處是兩個點,瀏覽器默認顯示3個…)
- /text() 獲取當前路徑下的文本內容
- /@xxx 提取當前路徑下標簽的屬性值
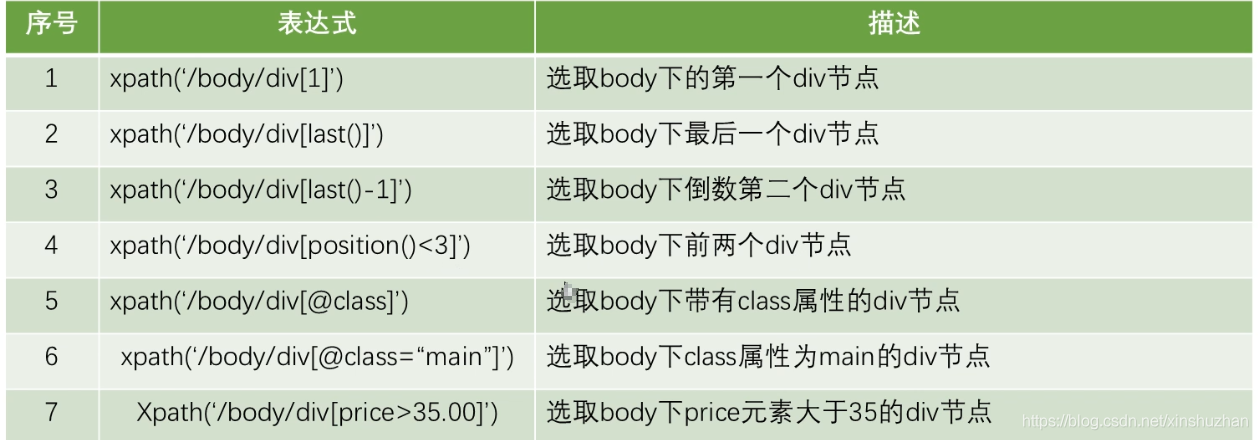
選取節點的運算式舉例:
2. 爬取起點小說網
在瀏覽器中獲取書名和作者測驗
在谷歌里安裝一個xpath的插件:

在html中查找book-mid-info:
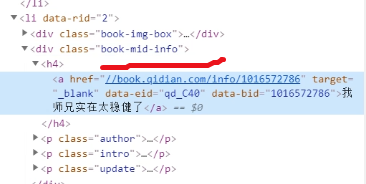
我們要獲取小說的名稱:
也就是 //div[@class=‘book-mid-info’]/h4/a/txt()

再加一個獲取作者:

使用xpath獲取起點小說網的資料
# 作者:互聯網老辛
# 開發時間:2021/4/8/0008 8:24
import requests
from lxml import etree
url="https://www.qidian.com/rank/yuepiao"
headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
#發送請求
resp=requests.get(url,headers)
e=etree.HTML(resp.text) #型別轉換,把str轉變為class 'lxml.etree._ELement
print(type(e))
names=e.xpath('//div[@class="book-mid-info"]/h4/a/text()')
authors=e.xpath('//p[@class="author"]/a[1]/text()')
print(names)
print(authors)
#名稱和作者對應
for name,authors in zip(names,authors):
print(name,":",authors)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/274072.html
標籤:python
上一篇:python英雄聯盟萬圖視頻制作