文章目錄
- pandas資料可視化
- 線形圖
- 條形圖
- 堆積條形圖
- 水平條形圖
- 直方圖
- 箱型圖
- 區域圖
- 散點圖
- 餅狀圖
- plotly資料可視化
- 激活backend:
- Plotly backend簡介
- if Jupyter
- 資料集選取
- 開始繪圖
- 散點圖
- 條形輝度圖
- 散點分類圖
- 資料推薦
pandas資料可視化
其實,pandas作圖是個什么效果大家心里應該有數,不然也不會有那么多其他的庫來作圖,或者說,pandas本身是一個做資料分析的庫,作圖的話,可能并不是它的本職作業,
但是呢,既然人家有,那我就放一下,
不急,文章后面會有比較好的pandas可視化工具,
(如果性子急的朋友可以從目錄直接跳轉到下面的第二個大板塊兒)
線形圖
import pandas as pd
import numpy as np
s = Series( np. random. randn( 10). cumsum(), index= np. arange( 0, 100, 10))
s. plot()
條形圖
df = pd.DataFrame(np.random.rand(10,4),columns=['a','b','c','d')
df.plot.bar()
堆積條形圖
傳遞stacked = True :
df = pd.DataFrame(np.random.rand(10,4),columns=['a','b','c','d')
df.plot.bar(stacked=True)
水平條形圖
要獲得水平條形圖,請使用 barh 方法:
df = pd.DataFrame(np.random.rand(10,4),columns=['a','b','c','d')
df.plot.barh(stacked=True)
直方圖
df = pd.DataFrame({'a':np.random.randn(1000)+1,'b':np.random.randn(1000),'c':
np.random.randn(1000) - 1}, columns=['a', 'b', 'c'])
df.plot.hist(bins=20)
箱型圖
df = pd.DataFrame(np.random.rand(10, 5), columns=['A', 'B', 'C', 'D', 'E'])
df.plot.box()
區域圖
df = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df.plot.area()
散點圖
df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd'])
df.plot.scatter(x='a', y='b')
餅狀圖
df = pd.DataFrame(3 * np.random.rand(4), index=['a', 'b', 'c', 'd'], columns=['x'])
df.plot.pie(subplots=True)
plotly資料可視化
pandas現在可以使用Plotly、Bokeh作為可視化的backend,直接實作互動性操作,無需再單獨使用可視化包了,
激活backend:
pd.options.plotting.backend = 'plotly'
可以填在上面的有:
Plotly
Holoviews
Matplotlib
Pandas_bokeh
Hyplot
Plotly backend簡介
Plotly是基于Javascript版本的庫寫出來的,因此生成的Web可視化圖表,可以顯示為HTML檔案或嵌入基于Python的Web應用程式中,
使用Plotly可以畫出很多媲美Tableau的高質量圖:
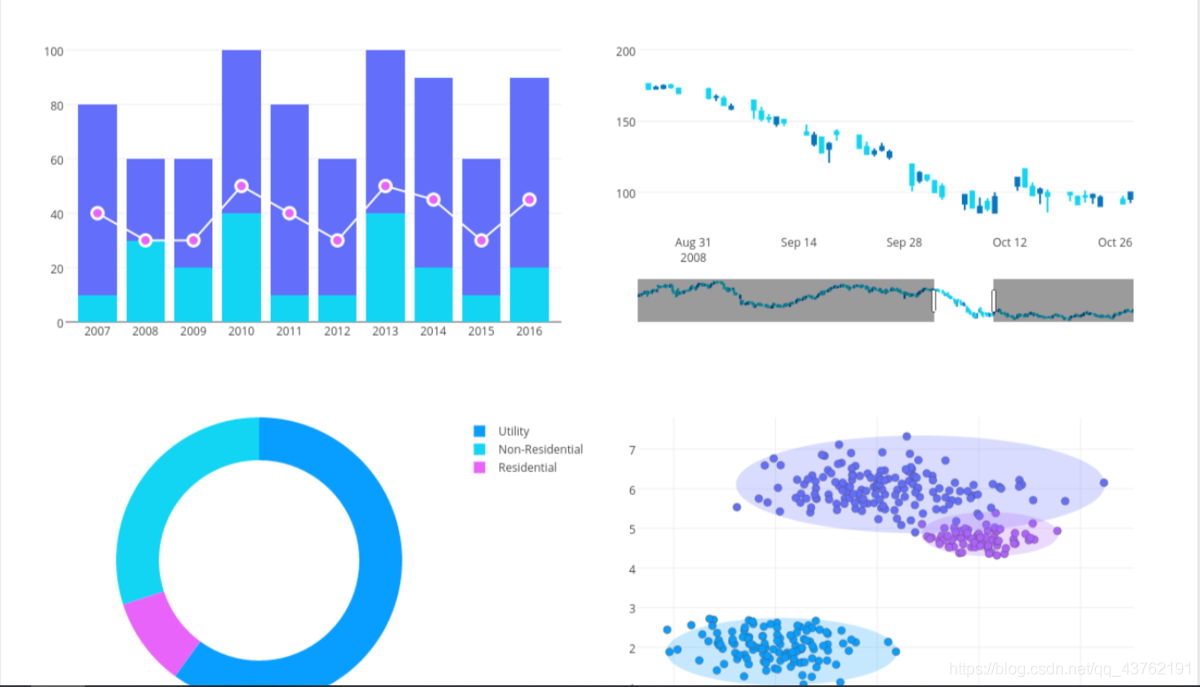
此前一直是苦于pyecharm的模板不夠多,前端不熟的小伙伴,這可是一個好東西哦!!!
if Jupyter
如果是在Jupyterlab中使用Plotly,那還需要執行幾個額外的安裝步驟來顯示可視化效果,
首先,安裝IPywidgets,
pip install jupyterlab "ipywidgets>=7.5"
然后運行此命令以安裝Plotly擴展,
jupyter labextension install jupyterlab-plotly@4.8.1
好,我用的是pyechart
資料集選取
資料集來源
這個資料也是Scikit-learn中的樣本資料,所以也可以使用以下代碼將其直接匯入,
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_openml
pd.options.plotting.backend = 'plotly'
X,y = fetch_openml("wine", version=1, as_frame=True, return_X_y=True)
data = pd.concat([X,y], axis=1)
print(data.head().T)
0 1 2 3 4
Alcohol 14.23 13.2 13.16 14.37 13.24
Malic_acid 1.71 1.78 2.36 1.95 2.59
Ash 2.43 2.14 2.67 2.5 2.87
Alcalinity_of_ash 15.6 11.2 18.6 16.8 21.0
Magnesium 127.0 100.0 101.0 113.0 118.0
Total_phenols 2.8 2.65 2.8 3.85 2.8
Flavanoids 3.06 2.76 3.24 3.49 2.69
Nonflavanoid_phenols 0.28 0.26 0.3 0.24 0.39
Proanthocyanins 2.29 1.28 2.81 2.18 1.82
Color_intensity 5.64 4.38 5.68 7.8 4.32
Hue 1.04 1.05 1.03 0.86 1.04
OD280%2FOD315_of_diluted_wines 3.92 3.4 3.17 3.45 2.93
Proline 1065.0 1050.0 1185.0 1480.0 735.0
class 1 1 1 1 1
該資料集是葡萄酒相關的,包含葡萄酒型別的許多功能和相應的標簽,
開始繪圖
散點圖
繪圖方式與正常使用Pandas內置的繪圖操作幾乎相同,只是現在以豐富的Plotly顯示可視化效果,
fig = data[['Alcohol', 'Proline']].plot.scatter(y='Alcohol', x='Proline')
fig.show()
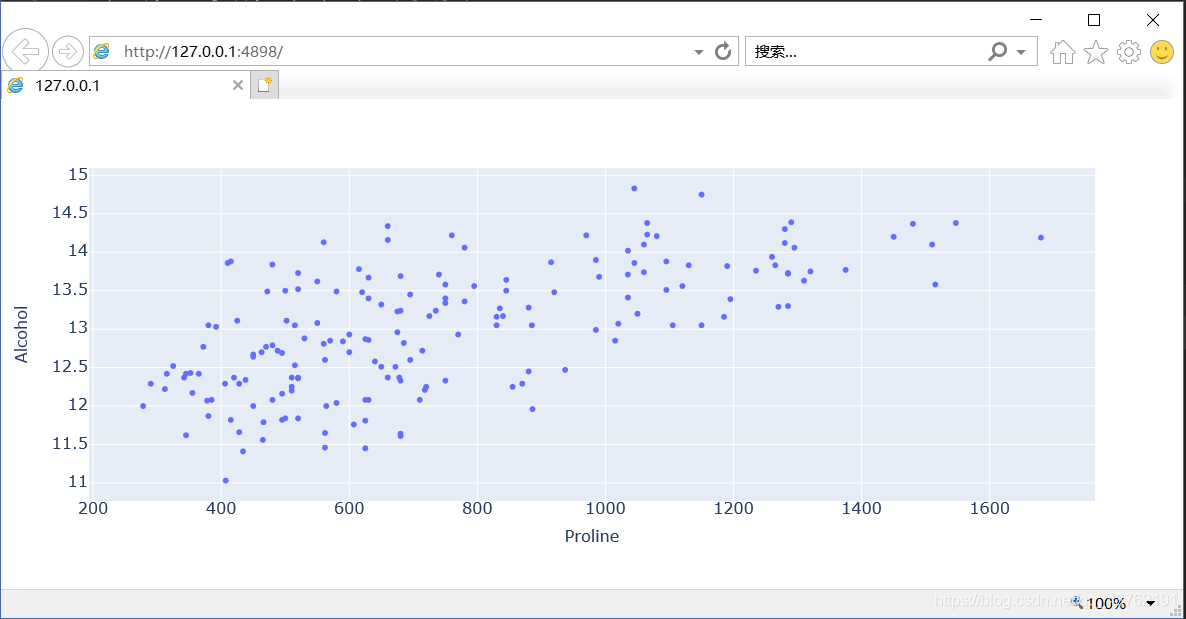
放大縮小,矢量圖,你懂得,
條形輝度圖
我們可以結合Pandas的groupby函式創建一個條形圖,總結各類之間Hue的均值差異,
fig = data[['Hue','class']].groupby(['class']).mean().plot.bar()
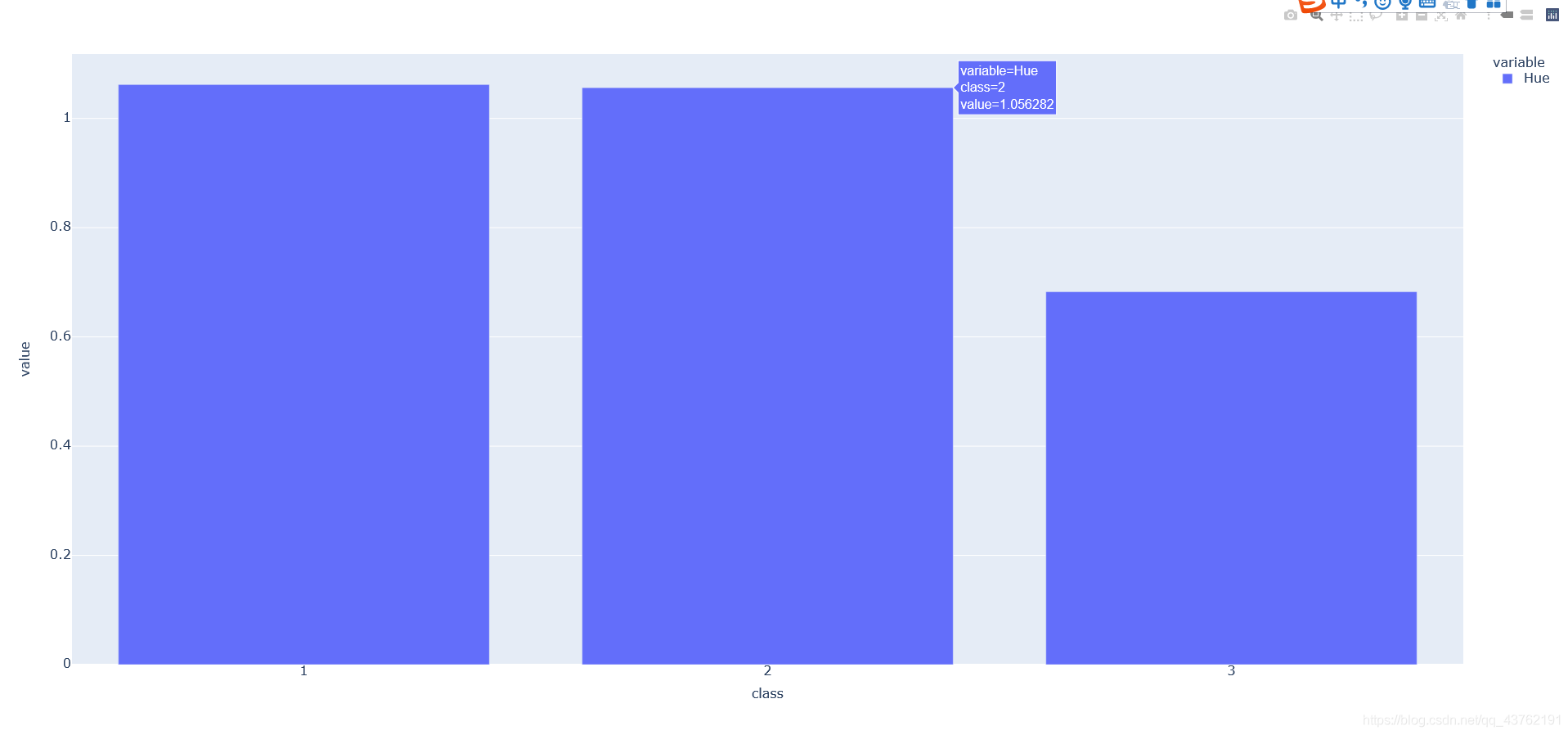
散點分類圖
將class添加到我們剛才創建的散點圖中,通過Plotly可以輕松地為每個類應用不同的顏色,以便直觀地看到分類,
fig = data[['Hue', 'Proline', 'class']].plot.scatter(x='Hue', y='Proline', color='class', title='Proline and Hue by wine class')
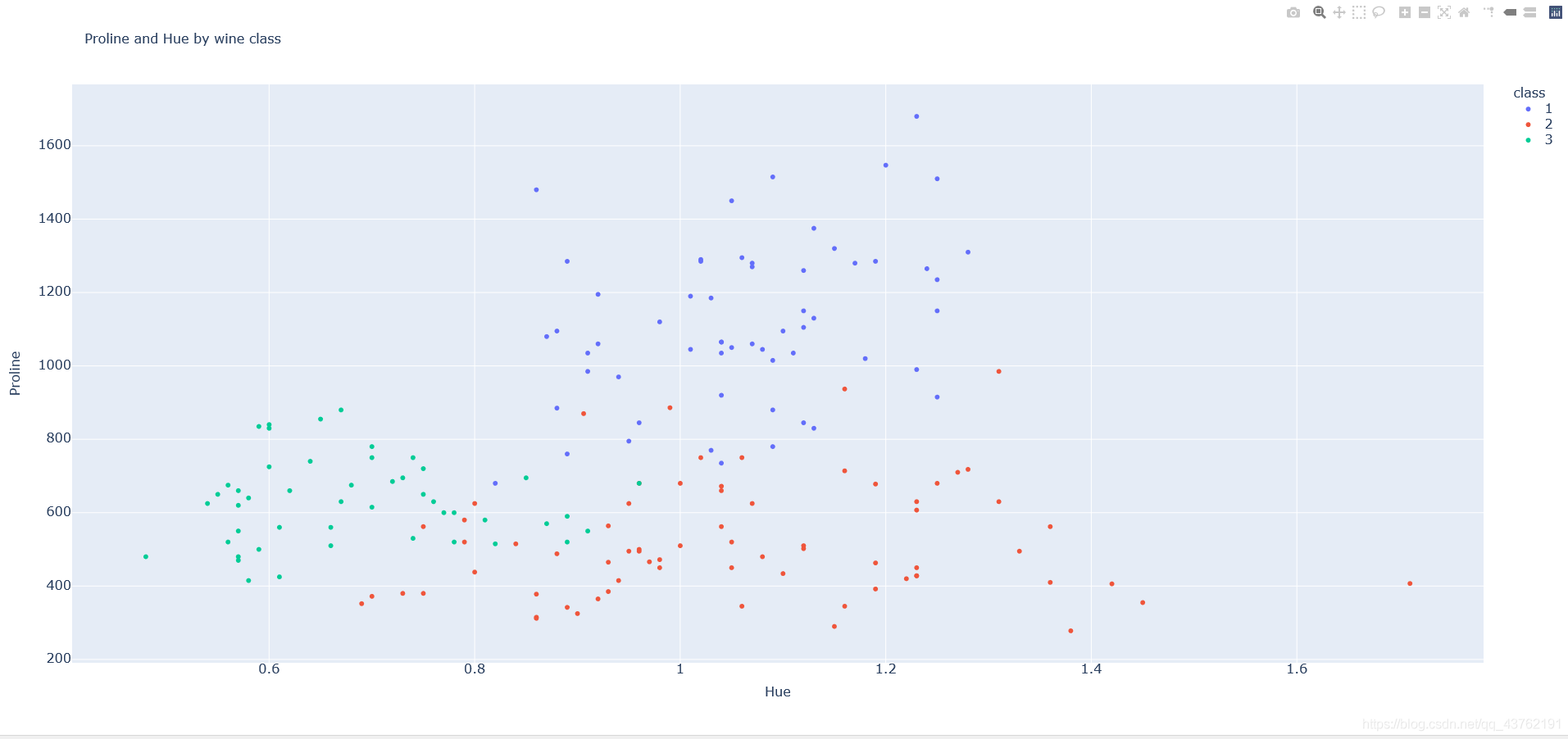
資料推薦
這里示例就放這些,比較簡單一些,
這里不建議大家去看各種網文,質量都參差不齊的,直接去看官方檔案,
Python Figure Reference: Single-Page
Plotly Python Open Source Graphing Library Fundamentals
推一篇還不錯的博文:可視化神器Plotly(5)—引數詳解


轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/274408.html
標籤:python
上一篇:Python筆記