文章目錄
- 基于邏輯回歸的分類預測
- 一、邏輯回歸函式介紹
- 二、matplotlib和seaborn庫
- 1.特征與標簽組合的散點可視化
- 2.箱形圖
- 3.三個特征下的三維散點圖
- 三、利用邏輯回歸模型在二分類上進行訓練和預測
基于邏輯回歸的分類預測
邏輯回歸是機器學習中十分經典的一個演算法之一,他是一個分類方法,主要運用于二分類,雖然它比不上現在很火的深度學習,但是這些傳統的演算法仍然有著它獨特的優勢:模型簡單和模型可行性高,在本次的學習中,我學習到了如何呼叫sklearn庫來對鳶尾花iris進行簡單的邏輯回歸分類,包括二分類和三分類;還有matplolib中一些我還沒用過的函式以及新的畫圖庫seaborn,
一、邏輯回歸函式介紹
邏輯回歸運用Logistic函式(或稱為Sigmoid函式),函式如下: l o g i ( z ) = 1 1 + e ? x logi(z) = \frac{1}{1+e^{-x}} logi(z)=1+e?x1?我們可以使用python的matplotlib庫來將這個函式列印出來:
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-5,5,0.01)
y = 1/(1+np.exp(-x))
plt.plot(x,y)
plt.xlabel(‘z’)
plt.ylabel(‘y’)
plt.grid()
plt.show()
運行的結果如下:
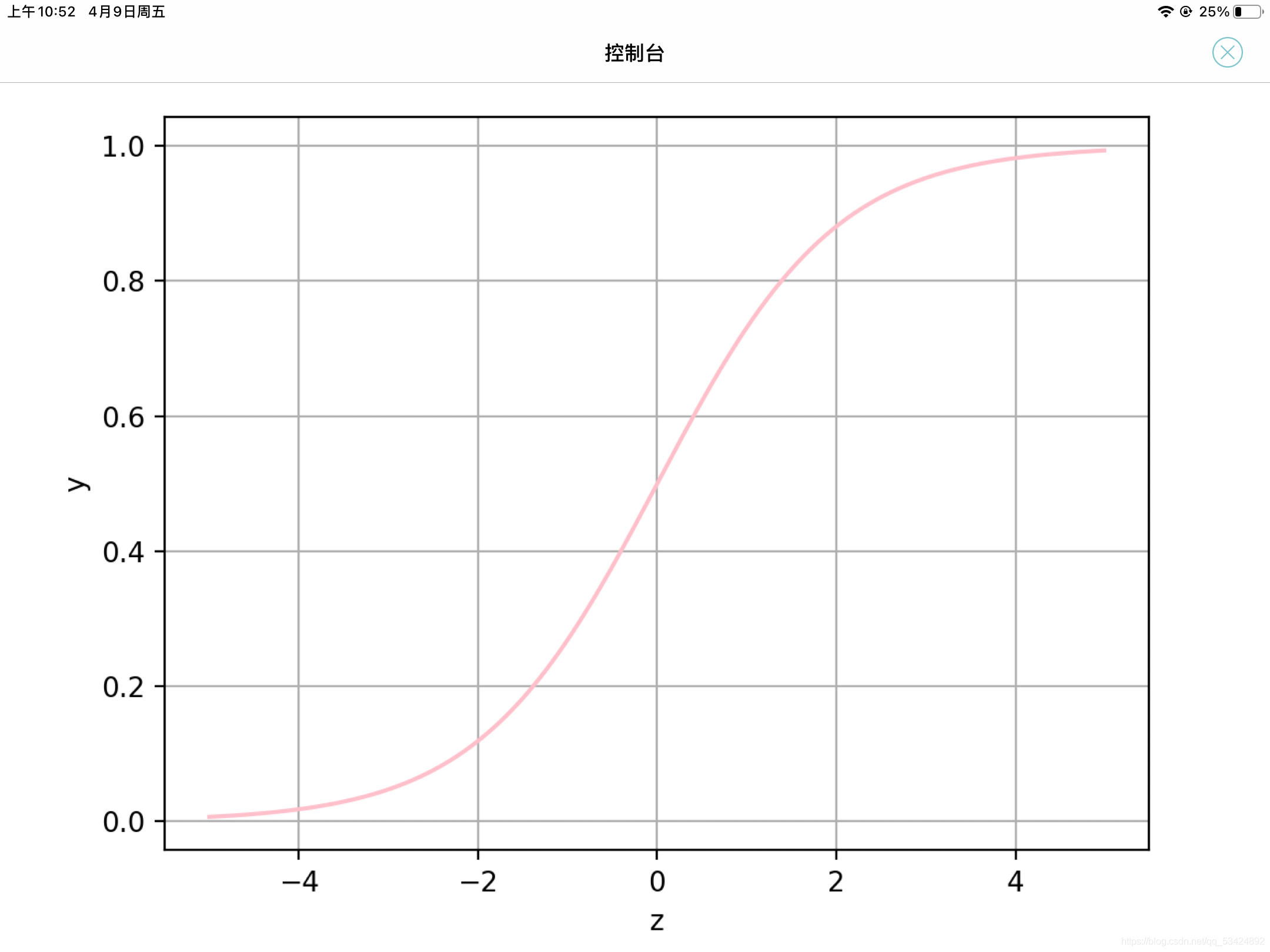
其中回歸基本方程為 z = w 0 + ∑ i N x i w i z = w_0 + \sum_{i}^{N}{x_iw_i} z=w0?+i∑N?xi?wi?邏輯回歸常用于二分類問題,而對于二分類問題來說,型別只有兩個,所以 p ( y = 1 ∣ x , θ ) = 1 ? p ( y = 0 ∣ x , θ ) p(y=1|x,θ)=1-p(y=0|x,θ) p(y=1∣x,θ)=1?p(y=0∣x,θ),而邏輯回歸的原理其實就是構建了一個決策邊界:對于函式 y = 1 1 + e ? x y=\frac{1}{1+e^{-x}} y=1+e?x1?,當 y > = 0 y>=0 y>=0時, z > = 0.5 z>=0.5 z>=0.5;當 y < 0 y<0 y<0時, z < 0.5 z<0.5 z<0.5,其中對應的y值就是對于型別1的概率預測值,對于多分類,就是將多個二分類的邏輯回歸組合,
二、matplotlib和seaborn庫
1.特征與標簽組合的散點可視化
首先我們要將特征和標簽的資訊合并:
iris_all = iris_features.cppy()#進行淺拷貝,防止修改原始資料
iris_all[‘target’] = iris_target
sns.pairplot(data=iris_all,diag_kind=‘hist’,hue=‘target’)
plt.show()
經過查詢資料得知,pairplot()里面的引數很多,但是常用的卻不多,比如在這個例子里面,diag_kind就是設定對角圖樣式的一個引數,除了上例的hist,還有一個叫kde的引數,其他還有很多,這里放一個鏈接可以直接跳轉過去查看:pairplot函式詳解
在hue這個引數的作用下,就會以型別為分類變數進行畫圖,之后就會得到四個特征下每個類別的眾多散點圖,
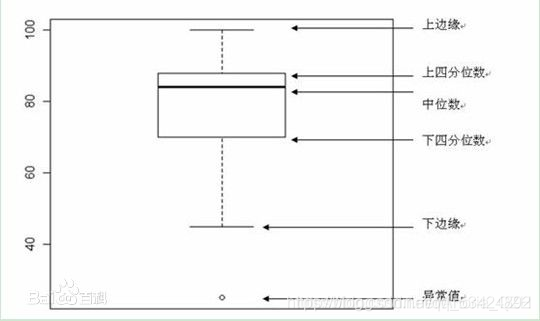
2.箱形圖
箱形圖最大的優點就是不受例外值的影響(例外值也稱為離群值),可以以一種相對穩定的方式描述資料的離散分布情況,
對于一個箱形圖,具有六個資料節點,如下圖:
因為資料集當中有四個特征,所以我們需要使用一個簡單的for回圈來將每一個特征的每一個類別的值畫出來,
for col in iris_features.columns():
sns.boxplot(x=‘target’,y=col,data=iris_all,saturation=0.5,palette=‘pastel’)
plt.title(col)
plt.show()
3.三個特征下的三維散點圖
選取其前三個特征繪制三維散點圖
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(10,8))
ax = fig.add_subplot(111, projection='3d')
iris_all_class0 = iris_all[iris_all['target']==0].values#選取類別為0的特征
iris_all_class1 = iris_all[iris_all['target']==1].values#選取類別為1的特征
iris_all_class2 = iris_all[iris_all['target']==2].values#選取類別為3的特征
# 'setosa'(0), 'versicolor'(1), 'virginica'(2)
ax.scatter(iris_all_class0[:,0], iris_all_class0[:,1], iris_all_class0[:,2],label='setosa')
ax.scatter(iris_all_class1[:,0], iris_all_class1[:,1], iris_all_class1[:,2],label='versicolor')
ax.scatter(iris_all_class2[:,0], iris_all_class2[:,1], iris_all_class2[:,2],label='virginica')
plt.legend()
plt.show()
三、利用邏輯回歸模型在二分類上進行訓練和預測
我們將資料集劃分為訓練集和測驗集,在訓練集上進行模型訓練,在測驗集上對模型性能進行驗證,
from sklearn.model_selection import train_test_split #這個函式是用來劃分訓練集和測驗集的
#因為是二分類,所以我們只需要匯入兩個類別0和1
iris_features_part = iris_features.iloc[:100]#一個類別是有50個樣本,所以我們可以直接取前100個作為資料集
iris_target_part = iris_target[:100]
#測驗集為20%,訓練集為80%
x_train,x_text,y_train,y_text = train_test_split(iris_features_part, iris_target_part, test_size = 0.2, random_state = 2020)
#test_size是測驗集的大小,如果是小數,則是代表其比例;如果是整數,則是代表取樣本數
#random_state確保每一次的訓練集都是相同的
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(random_state=0,solver='lbfgs')
clf.fit(x_train,y_train)#進行訓練集模型訓練
## 查看其對應的w
print('the weight of Logistic Regression:',clf.coef_)
## 查看其對應的w0
print('the intercept(w0) of Logistic Regression:',clf.intercept_)
#在訓練集和測驗集上分布利用訓練好的模型進行預測
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
而在課程中,對于模型訓練結果的評估更是讓人嘆為觀止(俺只是一個小白)
from sklearn import metrics
## 利用accuracy(準確度)【預測正確的樣本數目占總預測樣本數目的比例】評估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩陣 (預測值和真實值的各類情況統計矩陣)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用熱力圖對于結果進行可視化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')#熱力圖(又是一個我沒聽說過的東西)
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
在iris鳶尾花這個資料集當中,原本就有著三個類別,所以只需要將開頭只匯入兩個類的代碼刪去就可以完成對三個類的邏輯回歸預測,值得一提的是,因為邏輯回歸模型是概率預測模型,所以我們可以用clf.predict_proba()來列印測驗集的概率,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/274410.html
標籤:python