寫在前面:大家好!我是【AI 菌】,一枚愛彈吉他的程式員,我
熱愛AI、熱愛分享、熱愛開源! 這博客是我對學習的一點總結與記錄,如果您也對深度學習、機器視覺、演算法、Python、C++感興趣,可以關注我的動態,我們一起學習,一起進步~
我的博客地址為:【AI 菌】的博客
我的Github專案地址是:【AI 菌】的Github
文章目錄
- 一、回歸問題
- 二、問題描述
- 三、模型搭建與訓練
- (1) 資料準備及可視化
- (2) 計算梯度、更新權值
- (3) 設定初始值
- (4) 迭代訓練指定次數
- 四、實驗結果與預測
- (1) 訓練前后損失對比
- (2) 可視化擬合結果
- (3) 輸入任意x,預測y值
一、回歸問題
回歸問題在生活中是很常見的,比如股價的走勢預測、天氣預報中溫度和濕度等的預測、交通流量的預測等,對于預測值是連續的實數范圍,或者屬于某一段連續的實數區間的問題稱為回歸問題,回歸問題是一種連續值預測問題,
特別地,如果使用線性模型去逼近真實模型,那么我們把這一類方法叫做線性回歸(Linear Regression,簡稱 LR),線性回歸是回歸問題中的一種具體的實作,
二、問題描述
我們有一個資料集,這個資料集中包含100個已知點(x, y),我們希望,建立一個數學模型,對于任意的新輸入x,該模型都能輸出一個近似于真實值的結果,
如果我們換一個角度來看待這個問題,它其實可以理解為一組連續值的預測問題,給定資料集𝔻,我們需要從𝔻中學習到資料的真實模型,從而預測未見過的樣本的輸出值,
在假定模型的型別后,學習程序就變成了搜索模型引數的問題,比如我們假設神經元為線性模型,那么訓練程序即為搜索線性模型的𝒘和𝑏引數的程序,訓練完成后,利用學到的模型,對于任意的新輸入𝒙,我們就可以使用學習模型輸出值作為真實值的近似,
為了使模型盡可能地簡單,我們假定該線性模型為一次函式 y = wx + b
三、模型搭建與訓練
完整代碼已經上傳我的Github倉庫,歡迎star:https://github.com/Keyird/TensorFlow2-for-beginner
(1) 資料準備及可視化
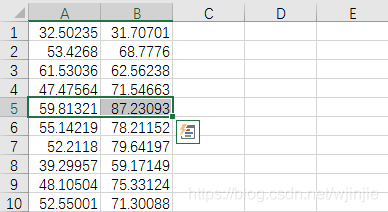
本次資料集一共包含100個坐標點(x, y),在data.csv檔案中直接給出,部分資料如下所示:
使用函式genfromtxt()可直接讀取data.csv檔案中的資料,并轉換成numpy陣列格式,做法如下:
points = np.genfromtxt("data.csv", delimiter=",")
為了更直觀地感受,下面使用matplotlib對這些點進行可視化:
plt.scatter(points[:, 0], points[:, 1])
x = np.arange(0, 100)
y = w * x + b
plt.xlabel('x')
plt.ylabel('y')
plt.show()
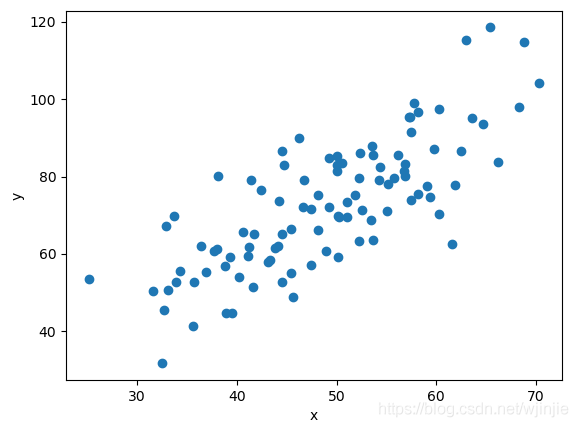
這100個點的分布如下圖所示:
(2) 計算梯度、更新權值
在計算梯度前,我們需要先確定損失函式,本次實驗我們采用簡單的平方和誤差作為損失函式:
l o s s = ∑ i ( w x i + b ? y i ) 2 loss=\sum_i(wx_i +b -y_i)^2 loss=∑i?(wxi?+b?yi?)2
根據梯度下降法,可以推知權值w、b的更新公式:
w ′ = w ? l r ? σ l o s s σ w w^{'} = w-lr * \frac{\sigma loss}{\sigma w} w′=w?lr?σwσloss?
b ′ = b ? l r ? σ l o s s σ b b^{'} = b-lr * \frac{\sigma loss}{\sigma b} b′=b?lr?σbσloss?,其中 l r lr lr 為學習率
對引數w、b分別求偏倒可得:
σ l o s s σ w = 2 ∑ ( w x i + b ? y i ) x i \frac{\sigma loss}{\sigma w}=2\sum(wx_i +b -y_i)x_i σwσloss?=2∑(wxi?+b?yi?)xi?
σ l o s s σ b = 2 ∑ ( w x i + b ? y i ) \frac{\sigma loss}{\sigma b}=2\sum(wx_i +b -y_i) σbσloss?=2∑(wxi?+b?yi?)
注:由于偏導符號不會打,所以以上式子中的偏導符號均由 σ \sigma σ符號代替,
在訓練程序中,一次輸入100組資料,計算平均梯度,對當前輪的引數w、b進行更新:
def step_gradient(b_current, w_current, points, learningRate):
# 初始化w,b
b_gradient = 0
w_gradient = 0
N = float(len(points))
# 計算100個點的平均梯度
for i in range(0, len(points)):
x = points[i, 0]
y = points[i, 1]
# grad_b = 2(wx+b-y)
b_gradient += (2/N) * ((w_current * x + b_current) - y)
# grad_w = 2(wx+b-y)*x
w_gradient += (2/N) * x * ((w_current * x + b_current) - y)
# 更新權值w,b
new_b = b_current - (learningRate * b_gradient)
new_w = w_current - (learningRate * w_gradient)
# 回傳更新后的w,b
return [new_b, new_w]
(3) 設定初始值
learning_rate = 0.0001 # 設定學習率
initial_b = 0 # 初始化b
initial_w = 0 # 初始化w
num_iterations = 1000 # 設定迭代次數
(4) 迭代訓練指定次數
以initial_b, initial_w為初始權值,learning_rate為學習率,迭代訓練num_iterations次
def gradient_descent_runner(points, starting_b, starting_w, learning_rate, num_iterations):
b = starting_b
w = starting_w
# 迭代num_iterations次
for i in range(num_iterations):
b, w = step_gradient(b, w, np.array(points), learning_rate)
return [b, w]
# 以learning_rate為學習率,迭代訓練num_iterations次
[b, w] = gradient_descent_runner(points, initial_b, initial_w, learning_rate, num_iterations)
四、實驗結果與預測
(1) 訓練前后損失對比
將100組資料的平均損失作為損失進行計算,
def compute_error_for_line_given_points(b, w, points):
totalError = 0
for i in range(0, len(points)):
x = points[i, 0] # 獲取點的橫坐標,等價于points[i][0]
y = points[i, 1] # 獲取點的縱坐標,等價于points[i][1]
# 累計平方和誤差損失
totalError += (y - (w * x + b)) ** 2
# 平均損失
return totalError / float(len(points))
分別計算訓練前和訓練后的平均損失,來進行比較:
print("訓練開始: b = {0}, w = {1}, error = {2}"
.format(initial_b, initial_w,compute_error_for_line_given_points(initial_b, initial_w, points)))
print("Running...")
[b, w] = gradient_descent_runner(points, initial_b, initial_w, learning_rate, num_iterations)
print("訓練 {0} 輪后: b = {1}, w = {2}, error = {3}".
format(num_iterations, b, w,compute_error_for_line_given_points(b, w, points)))
輸出對比:

從輸出結果結果可以看出,迭代完1000次后,平均損失降低了很多,所以可見模型是朝著好的方向在訓練,
(2) 可視化擬合結果
通過matplotlib繪制擬合結果:
plt.scatter(points[:, 0], points[:, 1])
x = np.arange(0, 100)
y = w * x + b
plt.xlabel('x')
plt.ylabel('y')
plt.title("y = wx + b")
plt.plot(x, y, color='r', linewidth=2.5)
plt.show()
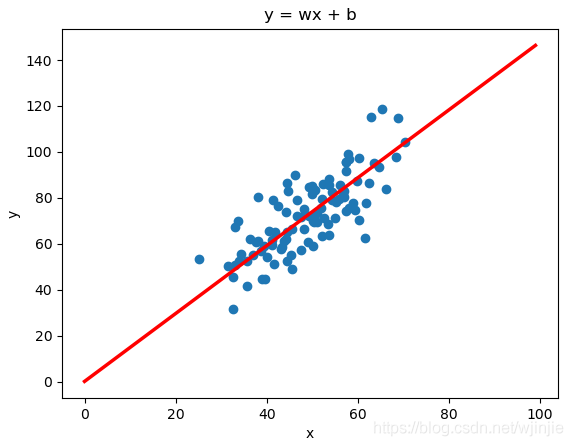
直線擬合結果如下:
(3) 輸入任意x,預測y值
通過1000次迭代訓練,我們已經得到了優化后的w,b,即直線,因此當我們任意輸入一個新的x,可以根據擬合好的直線y=1.4777x+0.0889,得到預測值y,
# 任意輸入一個x,預測y
print("請任意輸入一個x:")
x = eval(input())
print("y={:.3f}".format(w*x+b))
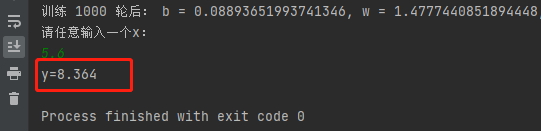
如下圖所示,當我們隨便輸入一個x=5.6,經過線性回歸,預測得到y=8.364,
本教程所有代碼會逐漸上傳github倉庫:https://github.com/Keyird/TensorFlow2-for-beginner
如果對你有幫助的話,歡迎star收藏~
由于水平有限,博客中難免會有一些錯誤,有紕漏之處懇請各位大佬不吝賜教!

推薦文章
- TensorFlow2 入門指南 | 01深度學習快速入門
- TF2.0深度學習實戰(一):分類問題之手寫數字識別
- 【C++21天養成計劃】不聊學習只談干貨(Day1)
- 【人生苦短,我學 Python】序言——不學點Python你就out了?
最好的關系是互相成就,各位的「三連」就是【AI 菌】創作的最大動力,我們下期見!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/274706.html
標籤:python
下一篇:java小程式:控制臺字符影片