深入了解Java字串
一:先簡單說下有關類加載
??在進入正文之前,我先講一下Java的一個特性優勢,那就是Java的類是動態加載的,無論是反射還是new出來的物件,都是需要通過類加載器進行按需動態加載的,這個類加載是通過一種機制——雙親委派機制(先交給上層的類加載器進行載入,如果可以的話回傳加載結果,否則再自己進行嘗試加載),部分原始碼如下:
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
@Override
protected Class<?> loadClass(String cn, boolean resolve)
throws ClassNotFoundException
{
// for compatibility reasons, say where restricted package list has
// been updated to list API packages in the unnamed module.
SecurityManager sm = System.getSecurityManager();//系統安全機制(策略)管理
if (sm != null) {
int i = cn.lastIndexOf('.');
if (i != -1) {
sm.checkPackageAccess(cn.substring(0, i));
}
}
return super.loadClass(cn, resolve);//交給上層類加載器進行加載
}
public static SecurityManager getSecurityManager() {
if (allowSecurityManager()) {
return security;
} else {
return null;
}
}
//判斷是否是允許安全管理的
private static boolean allowSecurityManager() {
return (allowSecurityManager != NEVER);
}
二:正文
??字串是程式中最常用到的資料型別之一(可以說是非常重要的一種資料型別),Java中可以通過String、StringBuilder、StringBuffer這三種創建字串的類物件來進行字串的創建,它們各有各的優缺點,
2.1 字串拼接程式比較String、StringBuffer、StringBuilder的拼接性能
??最開始我們先通過一段程式來了解這三者在拼接字串方面的效率:
public class Test1 {
public static void main(String[] args) {
createString();
createStringBuffer();
createStringBuilder();
}
public static void createString(){
long start= System.currentTimeMillis();
String string="0";
for(int i=1;i<100000;i++){
string+=i;
}
long end=System.currentTimeMillis();
System.out.println("String append 100000 data cost:"+(end-start)+"millis");
}
public static void createStringBuffer(){
long start= System.currentTimeMillis();
StringBuffer stringBuffer=new StringBuffer("0");
for(int i=1;i<10000000;i++){
stringBuffer.append("a"+i);
}
long end=System.currentTimeMillis();
System.out.println("StringBuffer append 10000000 data cost:"+(end-start)+"millis");
}
public static void createStringBuilder(){
long start= System.currentTimeMillis();
StringBuilder stringBuilder=new StringBuilder("0");
for(int i=1;i<10000000;i++){
stringBuilder.append("b"+i);
}
long end=System.currentTimeMillis();
System.out.println("StringBuilder append 10000000 data cost:"+(end-start)+"millis");
}
}
代碼運行結果如下:

??顯而易見,三者在拼接字串方面的效率:StringBuilder>StringBuffer>String
接下來我們來通過原始碼增進對著三者的認識,
2.2 關于String(結構、原始碼)
我們先來介紹下String相關內容:
2.2.1 String的結構
首先我們來看下String相關的UML圖:
我們現來看下String繼承了哪些介面:

簡單的對這五個介面進行闡述:
- 介面CharSequence:是java.lang包下的一個介面,此介面對多種不同的對char訪問的統一介面,向String、StringBuffer、StringBuilder都是CharSequence的實作類,CharSequence類和String類都可以定義字串,但是String定義的字串只能讀,CharSequence定義的字串是可讀可寫的;對于抽象類或者介面來說不可以直接使用new的方式創建物件,但是可以直接給它賦值:
CharSequence test = "test"; - 介面ConstantDesc和介面Constable一起講:
??JDK12在java.base模塊新增了java.lang.constant包,包中定義了一系列基于值的符號參考型別,它們能夠描述每種加載常量,
??Constable表示一個型別是Constable,Constable型別是可以在JVMS4.4中描述的Java類檔案的常量池中標識的常量,并且其實體可以名義上將自己的描述為ConstantDesc,一些常量型別在常量池中具有本地表示形式:String、Integer、Long、Float、Double、Class、MethodType、MethodHandle,型別String、Integer、Long、Float和Double充當其自己的名義描述符;Class、MethodType和MethodHandle具有對應的名義描述符ClassDesc,MethodTypeDesc和MethodHandlerDesc,
??ConstanrDesc:在JVMS4.4中定義的可加載常量值的名義描述符,名義描述符中的類名稱(如類檔案的常量池中的類別名稱)必須相對特定的類加載器進行解釋,該類加載器不是名義描述符的一部分, - 介面Comparable:實作compareTo方法進行字串比較
- 介面Serializable:序列化標識,表示該字串可以進行序列化和反序列化;
String類有哪些Field:(下文原始碼處有做簡述)
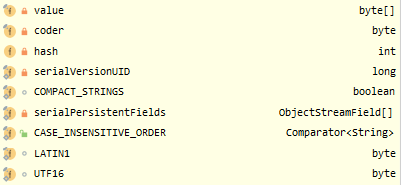
String的構造器有這些:
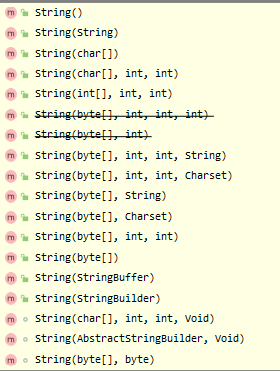
可見,字串String跟位元組陣列byte[]、字符陣列char[]是密切相關的,
2.2.2 String的部分Field及Constructor
String部分原始碼:
//注意:String被關鍵字final修飾
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence,
Constable, ConstantDesc {
@Native static final byte LATIN1 = 0;//是ISO-8859-1的別名
@Native static final byte UTF16 = 1;
@Stable
private final byte[] value;//傳入的字串值,被final修飾
private final byte coder;//用于對位元組進行編碼的識別符號,被final修飾
private int hash; // Default to 0,字串的快取hash
private static final long serialVersionUID = -6849794470754667710L;//序列化ID
static final boolean COMPACT_STRINGS;//是否壓縮字串,如果字串壓縮被禁用,則位元組總是用UTF16編碼,對于具有多個可能實作路徑的方法,當壓縮被禁用,只采用一個代碼路徑,
//壓縮字串==true=>if(coder==LATIN1){,,,}
//壓縮字串==false=>if(false){,,,}
/*
這個欄位的實際值由JVM注入,靜電
初始化塊用于在此處設定值以進行通信
這個靜態的final欄位不是靜態可折疊的
在vm初始化期間避免任何可能的回圈依賴
*/
static {
COMPACT_STRINGS = true;
}
//ObjectStreamField是Serializable類的Seriablizable欄位的描述,ObjectStreamFields的陣列用于宣告一個類的Serializable欄位
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
public String(byte bytes[], int offset, int length, String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
checkBoundsOffCount(offset, length, bytes.length);//檢查長度是否在bytes[]陣列的范圍內
StringCoding.Result ret =
StringCoding.decode(charsetName, bytes, offset, length);//使用對應的編碼方式進行解碼,若編碼方式為null,則用默認的ISO-8859-1
this.value = ret.value;
this.coder = ret.coder;
}
public String(StringBuffer buffer) {
this(buffer.toString());//后面講到StringBuffer會補充
}
public String(char value[], int offset, int count) {
this(value, offset, count, rangeCheck(value, offset, count));
}
public String(StringBuilder builder) {
this(builder, null);
}
@HotSpotIntrinsicCandidate //被該注解標注的,在HotSpot中都有一套高效地實作,該高效實作基于CPU指令,運行時,HotSpot維護的高效實作會替代JDK的原始碼實作,從而獲得更高效的效率
public String(String original) {
this.value = original.value;
this.coder = original.coder;
this.hash = original.hash;
}
}
2.2.3 通過一段程式來閱讀關于String的常用方法的源代碼
下面通過一段程式來閱讀查看String中的常用方法的原始碼:
public class Test1 {
public static void main(String[] args) throws Exception {
//注意,在ASCII編碼中一個中文字符占倆位元組
String s1 = "沈爍華";
String s2 = "沈爍華";
String s3 = "沈爍華" + "聊編程" + "沈爍華";
String s4 = "聊編程" + new String("的小華");
String s5 = "I love programming 打住";
char[] c = new char[3];
s3.getChars(0, 3, c, 0);
for (char c1 : c) {
System.out.print(c1 + ",");//沈,爍,華
}
System.out.println();
byte[] b = s1.getBytes("GBK");
for (byte t : b) {
System.out.print(t + ",");//-55,-14,-53,-72,-69,-86
}
System.out.println();
System.out.println(s1.length());//3
System.out.println(s1.charAt(0));//沈
System.out.println(s1.equals(s2));//true
System.out.println(s1.contentEquals(new StringBuilder("沈爍華")));//true
System.out.println(s1.contentEquals(new StringBuffer("沈爍華")));//true
System.out.println(s3.hashCode());
System.out.println(s2.indexOf("華"));//2,因為是從前開始找
System.out.println(s3.lastIndexOf("爍"));//7,因為是從后開始找
for (String s : s5.split(" ", 3)) {
System.out.print(s + ",");//I,love,programming 打住, 3是限制陣列的長度,所以后面的programming 打住沒有按空格分隔開
}
System.out.println();
System.out.println(String.valueOf(new char[]{'a', 'b'}, 0, 1));
System.out.println(s3.toCharArray());
s1.intern();
}
}
方法原始碼如下:
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) {
//檢查是都越界問題
checkBoundsBeginEnd(srcBegin, srcEnd, length());
checkBoundsOffCount(dstBegin, srcEnd - srcBegin, dst.length);
if (isLatin1()) {//是否是IOS編碼
StringLatin1.getChars(value, srcBegin, srcEnd, dst, dstBegin);
} else {
StringUTF16.getChars(value, srcBegin, srcEnd, dst, dstBegin);
}
}
//這個是StringLatin1類中的
public static void getChars(byte[] value, int srcBegin, int srcEnd, char dst[], int dstBegin) {
inflate(value, srcBegin, dst, dstBegin, srcEnd - srcBegin);
}
// inflatedCopy byte[] -> char[]
@HotSpotIntrinsicCandidate
public static void inflate(byte[] src, int srcOff, char[] dst, int dstOff, int len) {
for (int i = 0; i < len; i++) {
dst[dstOff++] = (char)(src[srcOff++] & 0xff);//遍歷復制,注意這里進行了與運算,0xff表示一個十六進制數FF,也就是十進制的255(1111 1111)
}
}
/
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, coder(), value);//呼叫StringCode按照指定字符集進行比那嗎
}
public int length() {
return value.length >> coder();//右移多少位
}
byte coder() {
return COMPACT_STRINGS ? coder : UTF16;//UTF16的值是1
}
///
public char charAt(int index) {
if (isLatin1()) {
return StringLatin1.charAt(value, index);
} else {
return StringUTF16.charAt(value, index);
}
}
//這是StringLatin1類(IOS編碼)中的charAt
public static char charAt(byte[] value, int index) {
if (index < 0 || index >= value.length) {
throw new StringIndexOutOfBoundsException(index);
}
return (char)(value[index] & 0xff);
}
//
public boolean equals(Object anObject) {
if (this == anObject) {//判斷是否是自己
return true;
}
if (anObject instanceof String) {
String aString = (String)anObject;
if (coder() == aString.coder()) {//判斷編碼是否一致
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}
@HotSpotIntrinsicCandidate
public static boolean equals(byte[] value, byte[] other) {
//通過遍歷來查看是否相同
if (value.length == other.length) {
for (int i = 0; i < value.length; i++) {
if (value[i] != other[i]) {
return false;
}
}
return true;
}
return false;
}
public boolean contentEquals(CharSequence cs) {
// Argument is a StringBuffer, StringBuilder
if (cs instanceof AbstractStringBuilder) {
if (cs instanceof StringBuffer) {
synchronized(cs) {//注意,這里加了悲觀鎖
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
} else {
return nonSyncContentEquals((AbstractStringBuilder)cs);
}
}
// Argument is a String
if (cs instanceof String) {
return equals(cs);
}
// Argument is a generic CharSequence
int n = cs.length();
if (n != length()) {
return false;
}
byte[] val = this.value;
if (isLatin1()) {
for (int i = 0; i < n; i++) {
if ((val[i] & 0xff) != cs.charAt(i)) {
return false;
}
}
} else {
if (!StringUTF16.contentEquals(val, cs, n)) {
return false;
}
}
return true;
}
private boolean nonSyncContentEquals(AbstractStringBuilder sb) {
int len = length();
if (len != sb.length()) {
return false;
}
byte v1[] = value;
byte v2[] = sb.getValue();
if (coder() == sb.getCoder()) {
int n = v1.length;
for (int i = 0; i < n; i++) {
if (v1[i] != v2[i]) {
return false;
}
}
} else {
if (!isLatin1()) { // utf16 str and latin1 abs can never be "equal"
return false;
}
return StringUTF16.contentEquals(v1, v2, len);
}
return true;
}
/
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)
: StringUTF16.hashCode(value);
}
return h;
}
//StringUTF16的hashCode
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;//長度折半
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);//哈希公式計算出唯一hash值,避免哈希沖突
}
return h;
}
//
public int indexOf(String str) {
if (coder() == str.coder()) {
return isLatin1() ? StringLatin1.indexOf(value, str.value)
: StringUTF16.indexOf(value, str.value);
}
if (coder() == LATIN1) { // str.coder == UTF16,編碼不一致
return -1;
}
return StringUTF16.indexOfLatin1(value, str.value);
}
public static int indexOfLatin1Unsafe(byte[] src, int srcCount, byte[] tgt, int tgtCount, int fromIndex) {
//這里補充講一下Java中的斷言assert關鍵字:assert主要用來保證程式的正確性,通常在程式開發和測驗時使用,為了提高程式運行的效率,在軟體發布后,斷言是默認關閉的
assert fromIndex >= 0;
assert tgtCount > 0;
assert tgtCount <= tgt.length;
assert srcCount >= tgtCount;
char first = (char)(tgt[0] & 0xff);//位元組轉為字符
int max = (srcCount - tgtCount);
//從指定起點開始往后找
for (int i = fromIndex; i <= max; i++) {
// Look for first character.
if (getChar(src, i) != first) {
while (++i <= max && getChar(src, i) != first);
}
// Found first character, now look at the rest of v2
if (i <= max) {
int j = i + 1;
int end = j + tgtCount - 1;
for (int k = 1;
j < end && getChar(src, j) == (tgt[k] & 0xff);
j++, k++);
if (j == end) {
// Found whole string.
return i;
}
}
}
return -1;
}
//從后往前查跟從前往后查是類似的
public static int lastIndexOfLatin1(byte[] src, int srcCount,
byte[] tgt, int tgtCount, int fromIndex) {
assert fromIndex >= 0;
assert tgtCount > 0;
assert tgtCount <= tgt.length;
int min = tgtCount - 1;
int i = min + fromIndex;
int strLastIndex = tgtCount - 1;
char strLastChar = (char)(tgt[strLastIndex] & 0xff);
checkIndex(i, src);
startSearchForLastChar://斷言
while (true) {
while (i >= min && getChar(src, i) != strLastChar) {
i--;
}
if (i < min) {
return -1;
}
int j = i - 1;
int start = j - strLastIndex;
int k = strLastIndex - 1;
while (j > start) {
if (getChar(src, j--) != (tgt[k--] & 0xff)) {
i--;
continue startSearchForLastChar;
}
}
return start + 1;
}
}
//
//正則運算式進行匹配切分,當然也要考慮到limit對陣列的限制
public String[] split(String regex, int limit) {
/* fastpath if the regex is a
(1)one-char String and this character is not one of the
RegEx's meta characters ".$|()[{^?*+\\", or
(2)two-char String and the first char is the backslash and
the second is not the ascii digit or ascii letter.
*/
char ch = 0;
if (((regex.length() == 1 &&
".$|()[{^?*+\\".indexOf(ch = regex.charAt(0)) == -1) ||
(regex.length() == 2 &&
regex.charAt(0) == '\\' &&
(((ch = regex.charAt(1))-'0')|('9'-ch)) < 0 &&
((ch-'a')|('z'-ch)) < 0 &&
((ch-'A')|('Z'-ch)) < 0)) &&
(ch < Character.MIN_HIGH_SURROGATE ||
ch > Character.MAX_LOW_SURROGATE))
{
int off = 0;
int next = 0;
boolean limited = limit > 0;
ArrayList<String> list = new ArrayList<>();
while ((next = indexOf(ch, off)) != -1) {
if (!limited || list.size() < limit - 1) {
list.add(substring(off, next));//采用substring方法進行切分
off = next + 1;
} else { // last one
//assert (list.size() == limit - 1);
int last = length();
list.add(substring(off, last));
off = last;
break;
}
}
// If no match was found, return this
if (off == 0)
return new String[]{this};
// Add remaining segment
if (!limited || list.size() < limit)
list.add(substring(off, length()));
// Construct result
int resultSize = list.size();
if (limit == 0) {
while (resultSize > 0 && list.get(resultSize - 1).isEmpty()) {
resultSize--;
}
}
String[] result = new String[resultSize];
return list.subList(0, resultSize).toArray(result);
}
return Pattern.compile(regex).split(this, limit);
}
//
public static String valueOf(char data[], int offset, int count) {
return new String(data, offset, count);
}
//
public char[] toCharArray() {
return isLatin1() ? StringLatin1.toChars(value)
: StringUTF16.toChars(value);
}
public static char[] toChars(byte[] value) {
char[] dst = new char[value.length];//進行陣列復制
inflate(value, 0, dst, 0, value.length);
return dst;
}
2.3 關于StringBuffer
2.3.1 StringBuffer的結構
StringBuffer
同樣的,StringBuffer我們也從其UML圖開始:
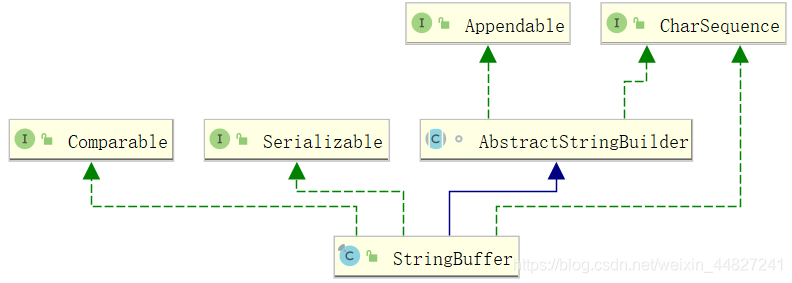
對StringBuffer的繼承的介面和抽象介面進行補充說明:
- 介面Appendable:能夠被追加char序列和值的物件,如果某個類的實體打算接收來自Formatter的格式,必須實作Appendable
- 抽象類AbstractStringBuilder:是StringBuffer、StringBuilder的直接父類,定義了很多方法的默認實作,
StringBuffer的成員變數如下(成員變數注釋寫在下面原始碼處):
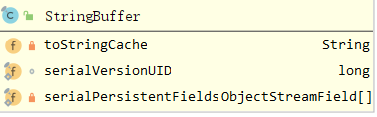
由于StringBuffer繼承了AbstractStringBuilder,所以StringBuffer也繼承了AbstractStringBuilder的成員變數:
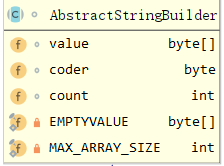
成員變數會在下面的原始碼出進行注釋說明
StringBuffer的構造器有如下:
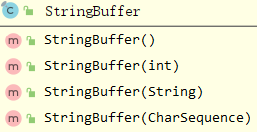
2.3.2 StringBuffer的部分Field和Constructor
先針對部分成員變數和部分構造器進行原始碼分析:
//注意這里final關鍵字修飾
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, Comparable<StringBuffer>, CharSequence
{
private transient String toStringCache;//回傳上次最后一次修改的整個字串的快取
static final long serialVersionUID = 3388685877147921107L;
//------AbstractStringBuilder的成員變數-------------------------------------
byte coder;//編碼標識
int count;//當前字串的長度
private static final byte[] EMPTYVALUE = new byte[0];//初始模式是空的位元組陣列
@HotSpotIntrinsicCandidate
public StringBuffer(String str) {
super(str.length() + 16);//在原有字串長度上進行擴充16的長度
append(str);
}
AbstractStringBuilder(int capacity) {//呼叫父類AbstractStringBuilder的構造器
if (COMPACT_STRINGS) {
value = new byte[capacity];
coder = LATIN1;
} else {
value = StringUTF16.newBytesFor(capacity);
coder = UTF16;
}
}
@Override
@HotSpotIntrinsicCandidate
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
public AbstractStringBuilder append(String str) {
if (str == null) {
return appendNull();
}
int len = str.length();
ensureCapacityInternal(count + len);
putStringAt(count, str);//把str放在count位置后面
count += len;//更新字串長度,注意這里要區分容量和長度的區別
return this;
}
private final void putStringAt(int index, String str) {
if (getCoder() != str.coder()) {
inflate();
}
str.getBytes(value, index, coder);
}
/
@HotSpotIntrinsicCandidate
public StringBuffer() {//空字符
super(16);
}
/
@HotSpotIntrinsicCandidate
public StringBuffer(int capacity) {
super(capacity);//指定字串長度
}
2.3.3 通過一段程式來閱讀關于StringBuffer的常用方法的源代碼
下面通過一段簡單的程式來對StringBuffer的幾個常用的方法進行原始碼決議
public class Test1 {
public static void main(String[] args) throws Exception {
StringBuffer sb = new StringBuffer("a");
StringBuffer sb1=new StringBuffer();
sb.append("bbbbbbbbbbbbbbbb");
System.out.println(sb.toString());
System.out.println(sb.compareTo(sb1));
System.out.println(sb.substring(0,2));
System.out.println(sb.equals("a"));
System.out.println(sb.hashCode());
}
}
@Override
@HotSpotIntrinsicCandidate
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
public AbstractStringBuilder append(String str) {
if (str == null) {
return appendNull();
}
int len = str.length();
ensureCapacityInternal(count + len);
putStringAt(count, str);
count += len;
return this;
}
private void ensureCapacityInternal(int minimumCapacity) {
// overflow-conscious code
int oldCapacity = value.length >> coder;
if (minimumCapacity - oldCapacity > 0) {//若不夠存,則創建一個新的出來
value = Arrays.copyOf(value,
newCapacity(minimumCapacity) << coder);//復制出一個新的,更大容量的byte陣列
}
}
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = value.length >> coder;
int newCapacity = (oldCapacity << 1) + 2;//容量翻倍再加2
if (newCapacity - minCapacity < 0) {
newCapacity = minCapacity;
}
int SAFE_BOUND = MAX_ARRAY_SIZE >> coder;//保證不超過安全界限
return (newCapacity <= 0 || SAFE_BOUND - newCapacity < 0)
? hugeCapacity(minCapacity)//安全界限進行變化
: newCapacity;
}
private final void putStringAt(int index, String str) {
if (getCoder() != str.coder()) {//編碼方式是否一致,不一致的話就進行一致性編碼
inflate();
}
str.getBytes(value, index, coder);//復制位元組陣列
}
@Override
@HotSpotIntrinsicCandidate
public synchronized String toString() {
if (toStringCache == null) {
return toStringCache =
isLatin1() ? StringLatin1.newString(value, 0, count)
: StringUTF16.newString(value, 0, count);
}
return new String(toStringCache);
}
@Override
public synchronized int compareTo(StringBuffer another) {
return super.compareTo(another);
}
int compareTo(AbstractStringBuilder another) {
if (this == another) {
return 0;
}
byte val1[] = value;
byte val2[] = another.value;
int count1 = this.count;
int count2 = another.count;
if (coder == another.coder) {
return isLatin1() ? StringLatin1.compareTo(val1, val2, count1, count2)
: StringUTF16.compareTo(val1, val2, count1, count2);
}
return isLatin1() ? StringLatin1.compareToUTF16(val1, val2, count1, count2)
: StringUTF16.compareToLatin1(val1, val2, count1, count2);
}
@Override
public synchronized String substring(int start, int end) {
return super.substring(start, end);
}
public String substring(int start, int end) {
checkRangeSIOOBE(start, end, count);//檢查是否指定的范圍有效
if (isLatin1()) {
return StringLatin1.newString(value, start, end - start);
}
return StringUTF16.newString(value, start, end - start);
}
public boolean equals(Object obj) {
return (this == obj);
}
@HotSpotIntrinsicCandidate
public native int hashCode();//注意,這里的hashCode被native關鍵字修飾(就是我們常聽到的JNI[Java Native Interface]),被native修飾的代表其是由C語言實作的,呼叫C的API
//以下是PrintStream類的
public void println(int x) {
synchronized (this) {
print(x);
newLine();
}
}
public void print(int i) {
write(String.valueOf(i));
}
private void write(String s) {
try {
synchronized (this) {
ensureOpen();
textOut.write(s);
textOut.flushBuffer();
charOut.flushBuffer();
if (autoFlush && (s.indexOf('\n') >= 0))
out.flush();
}
}
catch (InterruptedIOException x) {
Thread.currentThread().interrupt();
}
catch (IOException x) {
trouble = true;
}
}
private void newLine() {
try {
synchronized (this) {
ensureOpen();
textOut.newLine();
textOut.flushBuffer();
charOut.flushBuffer();
if (autoFlush)
out.flush();
}
}
catch (InterruptedIOException x) {
Thread.currentThread().interrupt();
}
catch (IOException x) {
trouble = true;
}
}
2.4 關于StringBuilder(不細講)
下面的StringBuilder就不展開詳細講了,因為StringBuffer和StringBuilder幾乎是一樣的,主要不同是StringBuffer的成員方法都加上了悲觀鎖synchronized,保證執行緒安全,而StringBuilder沒有加,直接上一副StringBuilder的UML圖:
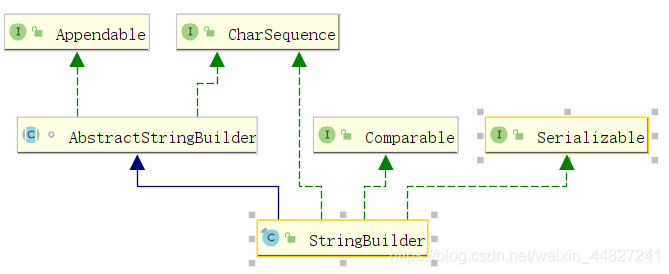
以上是單純針對String、StrignBuffer、StringBuilder的JDK原始碼進行分析,下面真正的干貨來啦!!!
三 干貨!!!
我將其總結為要點:
- 字串拼接效率:StringBuilder>StrignBuffer>String
- String、StringBuilder、StringBuffer這三者都是被final關鍵字修飾,所以三者都是不能被繼承的
- 三者的使用場景分別是:
- String使用場景:在不需要經常修改字串的時候進行使用,
- StringBuilder使用場景:在非多執行緒并發的場景下且經常需要修改字串的時候進行使用,
- StringBuffer適用場景:在多執行緒并發的場景下(存在執行緒安全隱患)且經常需要修改字串的時候進行使用,
- String不是基本資料型別,因為String被final修飾,在Java中有八大基本資料型別:byte(整型單位元組)、boolean(布爾單位元組)、short(整型雙位元組)、char(雙位元組)、int(四位元組)、float(四位元組)、long(八位元組)、double(八位元組)
- 如何看方法中定義的區域變數是否是執行緒安全的:看是否是資料共享的(有無被static修飾)、是否是在多執行緒應用場景中
來看段代碼:
public class Test1 {
public static void main(String[] args) throws Exception {
StringBuilder sb1=new StringBuilder("a");
StringBuilder sb2=new StringBuilder("a");
Thread t1=new Thread(new Runnable() {
@Override
public void run() {
for(int i=0;i<5;i++){
test(sb1);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
Thread t2=new Thread(new Runnable() {
@Override
public void run() {
for(int i=0;i<10;i++){
test(sb2);
}
}
});
t1.start();
t2.start();
Thread.sleep(100000);
System.out.println(sb1.toString());
System.out.println(sb2.toString());
}
//執行緒可能不安全,倘若有倆執行緒同時呼叫進入,進行操作,這時由于sb是一個參考傳遞,而且static用的是同一份,這時雙方的執行速度不同對導致最終的結果有所偏差
public static void test(StringBuilder sb){
sb.append("沈爍華");
sb.append("聊編程");
}
//執行緒可能是不安全的,與test道理類似
public static StringBuilder test2(StringBuilder sb){
sb.append("沈爍華");
sb.append("聊編程");
return sb;
}
//執行緒安全,因為其回傳的是String型別,gen形參StringBuilder sb無關
public static String test3(StringBuilder sb){
sb.append("沈爍華");
sb.append("聊編程");
return sb.toString();
}
}
看下結果你就知道了:

-
關于String.intern():當程式中有大量的字串操作是,使用該方法就是將字串或字串的參考地址放入字串常量池中(前提是字串常量池中沒有該字串),下次需要的話直接從字串常量池中取,就不用再去創建,省去創建很多重復字串,節省記憶體空間,GC是可以回收StringTable的,這樣做加快了系統運行效率,
下圖是虛擬機jdk8中的執行緒共享區簡圖:
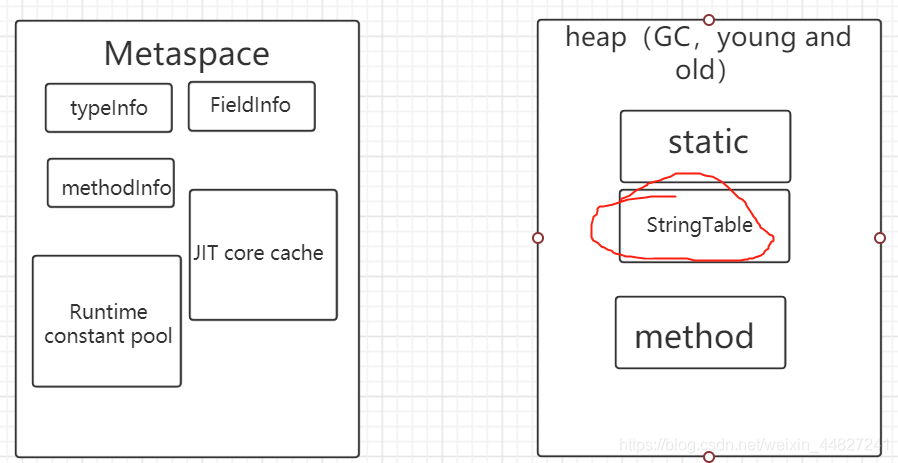
-
jdk版本更新迭代很快,之所以把字串常量池放在堆空間中,是因為heap是gc的主戰場,這樣可以提高字串的回收效率,提升空間利用率,降低OOM的風險,
-
StringTable內部是Hashtable(執行緒安全),不同jdk版本有不同的默認長度,當池內的數量接近最大可容納的數量時,就會造成哈希沖突,根據不同的應用場景,我們可以手動設定其大小:-XX:StringTableSize=N來設定
-
字串拼接操作:
- 常量與常量之間進行字串拼接結果是放在常量池中的,其原理是編譯器優化;
- 相同的字串在常量池中只存放一份 ,
- 只要其中有一個是變數,結果就是在堆中,其拼接原理是使用了StringBuilder,但如果拼接左右兩邊都是被final修飾的常量參考或常量,其原理就不是StringBuilder了
- 如果拼接結果呼叫intern(),則主動將常量池中沒有的字串物件放入池中,并回傳此物件的地址,
public class Test1 {
public static void main(String[] args) throws Exception {
String s1 = "java";//相當于拼接""進入常量池
String s2 = "python";//相當于拼接""進入常量池
String s3 = "javapython";//相當于拼接""進入常量池
String s4 = "java" + "python";//拼接進入常量池
String s5 = s1 + "python";//相當于new出一個StringBuilder,指向的是地址參考
String s6 = "java" + s2;//相當于new出一個StringBuilder,指向的是地址參考
String s7 = s1 + s2;//相當于new出一個StringBuilder,指向的是地址參考
System.out.println(s3==s4);//true
System.out.println(s3==s5);//false
System.out.println(s3==s6);//false
System.out.println(s3==s7);//false
System.out.println(s5==s6);//false
System.out.println(s5==s7);//false
System.out.println(s6==s7);//false
String s8 = s6.intern();//看常量池中是否存在,如果存在回傳地址,若不存在,將其放入并回傳池中地址
System.out.println(s3 == s8);//true
System.out.println(s6 == s8);//false 池中的地址和StringBuilder堆中的地址是不一樣的
System.out.println("===================");
final String s9 = "java";//常量
String s10 = s9 + "python";//常量參考+常量
System.out.println(s10==s8);//true
System.out.println(s10==s7);//false
}
}
- 在可以指定容量的類構造器中,能盡量指定容量就指定容量,因為如果后面使用默認容量不夠的話,就會去進行擴容,擴容操作是需要一定開銷的,例如StringBuilder、StringBuffer,二者的默認容量是16;
- 如果需要經常使用字串拼接的就用StringBuiilder或StringBuffer,不要用String,因為String拼接程序會生成大量的String和StringBuilder物件,在GC時會消耗額外大量時間
- 重頭戲來了!!!判斷下面的代碼創建了幾個物件:(注:只單純看該陳述句)
java String s=new String("a")+new String("b");
我想還是先方法答案再放位元組碼:
上述問題共創建了6個物件:
“a”和“b”為兩個常量物件,
new String()算上兩個,
因為左右兩邊有變數,所以底層是使用StringBuilder去append,這部分外加上一個,
最后一個是StringBuilder.toString()轉為String物件
放位元組碼:
Last modified 2021年4月10日; size 1075 bytes
MD5 checksum 877740f339941987f066b1ba1d115504
Compiled from "Test1.java"
public class com.hua.demo.string.Test1
minor version: 0
major version: 55
flags: (0x0021) ACC_PUBLIC, ACC_SUPER
this_class: #7 // com/hua/demo/string/Test1
super_class: #8 // java/lang/Object
interfaces: 0, fields: 0, methods: 2, attributes: 3
Constant pool:
#1 = Methodref #8.#27 // java/lang/Object."<init>":()V
#2 = Class #28 // java/lang/String
#3 = String #29 // a
#4 = Methodref #2.#30 // java/lang/String."<init>":(Ljava/lang/String;)V
#5 = String #31 // b
#6 = InvokeDynamic #0:#35 // #0:makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
#7 = Class #36 // com/hua/demo/string/Test1
#8 = Class #37 // java/lang/Object
#9 = Utf8 <init>
#10 = Utf8 ()V
#11 = Utf8 Code
#12 = Utf8 LineNumberTable
#13 = Utf8 LocalVariableTable
#14 = Utf8 this
#15 = Utf8 Lcom/hua/demo/string/Test1;
#16 = Utf8 main
#17 = Utf8 ([Ljava/lang/String;)V
#18 = Utf8 args
#19 = Utf8 [Ljava/lang/String;
#20 = Utf8 s
#21 = Utf8 Ljava/lang/String;
#22 = Utf8 Exceptions
#23 = Class #38 // java/lang/Exception
#24 = Utf8 MethodParameters
#25 = Utf8 SourceFile
#26 = Utf8 Test1.java
#27 = NameAndType #9:#10 // "<init>":()V
#28 = Utf8 java/lang/String
#29 = Utf8 a
#30 = NameAndType #9:#39 // "<init>":(Ljava/lang/String;)V
#31 = Utf8 b
#32 = Utf8 BootstrapMethods
#33 = MethodHandle 6:#40 // REF_invokeStatic java/lang/invoke/StringConcatFactory.makeConcatWithConstants:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/String;[Ljava/lang/Object;)Ljava/lang/invoke/CallSite;
#34 = String #41 // \u0001\u0001
#35 = NameAndType #42:#43 // makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
#36 = Utf8 com/hua/demo/string/Test1
#37 = Utf8 java/lang/Object
#38 = Utf8 java/lang/Exception
#39 = Utf8 (Ljava/lang/String;)V
#40 = Methodref #44.#45 // java/lang/invoke/StringConcatFactory.makeConcatWithConstants:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/String;[Ljava/lang/Object;)Ljava/lang/invoke/CallSite;
#41 = Utf8 \u0001\u0001
#42 = Utf8 makeConcatWithConstants
#43 = Utf8 (Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
#44 = Class #46 // java/lang/invoke/StringConcatFactory
#45 = NameAndType #42:#50 // makeConcatWithConstants:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/String;[Ljava/lang/Object;)Ljava/lang/invoke/CallSite;
#46 = Utf8 java/lang/invoke/StringConcatFactory
#47 = Class #52 // java/lang/invoke/MethodHandles$Lookup
#48 = Utf8 Lookup
#49 = Utf8 InnerClasses
#50 = Utf8 (Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/String;[Ljava/lang/Object;)Ljava/lang/invoke/CallSite;
#51 = Class #53 // java/lang/invoke/MethodHandles
#52 = Utf8 java/lang/invoke/MethodHandles$Lookup
#53 = Utf8 java/lang/invoke/MethodHandles
{
public com.hua.demo.string.Test1();
descriptor: ()V
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 14: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/hua/demo/string/Test1;
public static void main(java.lang.String[]) throws java.lang.Exception;
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=4, locals=2, args_size=1
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String a
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: new #2 // class java/lang/String
12: dup
13: ldc #5 // String b
15: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
18: invokedynamic #6, 0 // InvokeDynamic #0:makeConcatWithConstants:(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
23: astore_1
24: return
LineNumberTable:
line 21: 0
line 22: 24
LocalVariableTable:
Start Length Slot Name Signature
0 25 0 args [Ljava/lang/String;
24 1 1 s Ljava/lang/String;
Exceptions:
throws java.lang.Exception
MethodParameters:
Name Flags
args
}
SourceFile: "Test1.java"
InnerClasses:
public static final #48= #47 of #51; // Lookup=class java/lang/invoke/MethodHandles$Lookup of class java/lang/invoke/MethodHandles
BootstrapMethods:
0: #33 REF_invokeStatic java/lang/invoke/StringConcatFactory.makeConcatWithConstants:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/String;[Ljava/lang/Object;)Ljava/lang/invoke/CallSite;
Method arguments:
#34 \u0001\u0001
再例如java String s="a"+"b"+"c";//編譯器將其優化,等同于直接"abc"就只有一個
但如果寫法是:
public class Test1 {
public static void main(String[] args) throws Exception {
//String s="a"+"b"+"c";//編譯器將其優化,等同于直接"abc"
String a1="a";
String b1="b";
String c1="c";
String s=a1+b1+c1;
}
}
String[] args不算的話,就是4個,
結束語
??本人目前仍處于Java學習階段,今后會繼續寫一些關于底層原始碼的文章,以上內容是本人翻閱原始碼以及之前自己接觸過的相關重點內容做出的總結,如有不對之處歡迎指正,需要補充的可以私我或者在評論區說下,也歡迎小伙伴們進行技術交流,共同成長,喜歡的小伙伴可以點贊加關注,感謝!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/275144.html
標籤:java
上一篇:一維陣列中重復元素的去除
下一篇:設計模式:行為型-訪問者模式