文章目錄
- 前言
- 一、python正則運算式的應用領域有哪些?
- 1、概念
- 2、作用
- 二、python中正則運算式re模塊的使用
- 1、re模塊常用的函式表格及概念
- 2、引入re庫
- 三、re代碼實體展示
- 總結
前言
一、python正則運算式的應用領域有哪些?
1、概念
-
正則運算式是對字串操作的一種邏輯公式,就是用事先定義好的一些特定字符、及這
些特定字符的組合,組成一個“規則字串”,這個“規則字串”用來表達對字串的一
種過濾邏輯(可以用來做檢索,截取或者替換操作), -
正則表述式用于搜索、替換和決議字串,正則運算式遵循一定的語法規則,使用非常
靈活,功能強大,使用正則運算式撰寫一些邏輯驗證非常方便,例如電子郵件地址格式的驗
證, -
正則運算式是對字串(包括普通字符(例如,a 到z 之間的字母)和特殊字符)操作
的一種邏輯公式,就是用事先定義好的一些特定字符、及這些特定字符的組合,組成一個“規
則字串”,這個“規則字串”用來表達對字串的一種過濾邏輯,正則運算式是一種文
本模式,模式描述在搜索文本時要匹配一個或多個字串,
2、作用
- 給定的字串是否符合正則運算式的過濾邏輯(稱作“匹配”),
- 可以通過正則運算式,從字串中獲取我們想要的特定部分,
- 還可以對目標字串進行替換操作,
二、python中正則運算式re模塊的使用
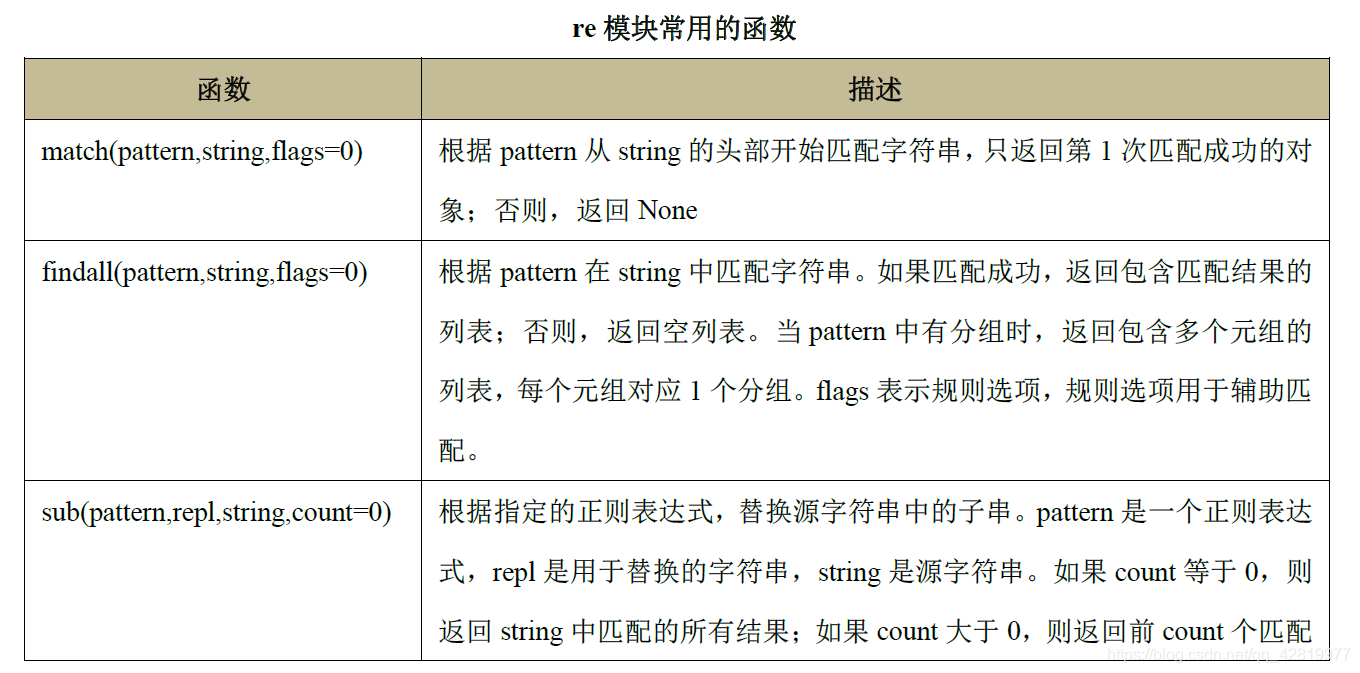
- Python 語言通過標準庫中的re 模塊支持正則運算式,re 模塊提供了一些根據正則表達
式進行查找、替換、分隔字串的函式,這些函式使用一個正則運算式作為第一個引數,re
模塊常用的函式如下表所示,
1、re模塊常用的函式表格及概念
- match 方法
- re.match 嘗試從字串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,
match()就回傳None,語法格式如下:
import re
re.match(pattern, string, flags=0)

- 匹配字串是正則運算式中最常用的一類應用,也就是設定一個文本模式,然后判斷另
外一個字串是否符合這個文本模式,
如果文本模式只是一個普通的字串,那么待匹配的字串和文本模式字串在完全相
等的情況下,match 方法會認為匹配成功,如果匹配成功,則match 方法回傳匹配的物件,
然后可以呼叫物件中的group 方法獲取匹配成功的字串,如果文本模式就是一個普通的字
符串,那么group 方法回傳的就是文本模式字串本身,

-
其中,匹配符“[]”可以指定一個范圍,例如:“[ok]”將匹配包含“o”或“k”的字
符,同時“[]”可以與\w、\s、\d 等標記等價,例如,[0-9a-zA-Z]等價于\w,[^0-9] 等價于\D, -
如果要匹配電話號碼,需要形如“\d\d\d\d\d\d\d\d\d\d\d”這樣的正則運算式,其中表現
了11 次“\d”,表達方式煩瑣,而且某些地區的電話號碼是8 位數字,區號也有可能是3
位或4 位數字,因此這個正則運算式就不能滿足要求了,正則運算式作為一門小型的語言,
還提供了對運算式的一部分進行重復處理的功能,例如,“*”可以對正則運算式的某個部
分重復匹配多次,這種匹配符號稱為限定符,下表列出了正則運算式中常用的限定符,
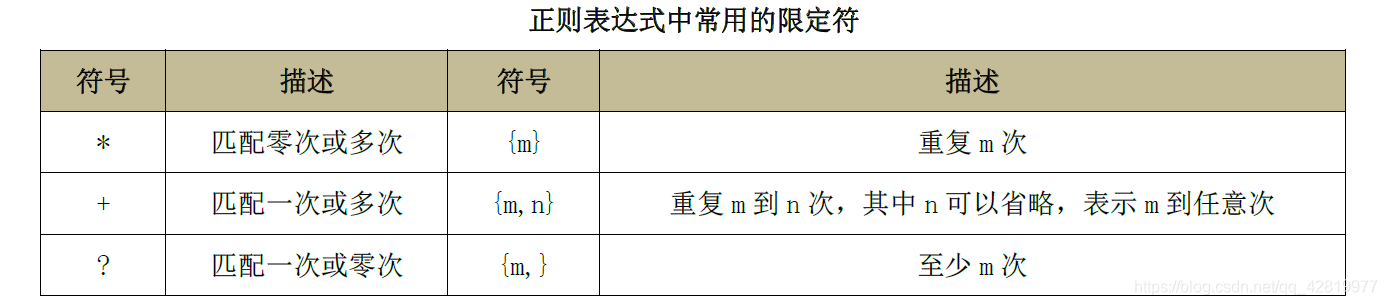
-
利用{}可以控制符號重復的次數,
-
原生字串
在大多數編程語言相同,正則運算式里使用“\”作為轉義字符,這就可以能造成反斜
杠困擾, -
假如你需要匹配文本中的字符“\”,那么使用編程語言表示的正則運算式里將需要4
個反斜杠:前面兩個和后兩個分別用于在編程語言里轉義成反斜杠,轉換成兩個反
斜杠后再在正則運算式里轉義成一個反斜杠,Python 里的原生字串很好地解決了這個問
題,使用Python 的 “r” 前綴,例如匹配一個數字的“\d”可以寫成r“\d”,有了原生字串,
再也不用擔心是不是漏寫了反斜杠,寫出來的運算式也更直觀,


注意:^與[^m]中的“^”的含義并不相同,后者“^”表示“除了….”的意思
- search() 方法:
search 在一個字串中搜索滿足文本模式的字串,語法格式如下:
re.search(pattern, string, flags=0)

-
match 與search 的區別
re.match 只匹配字串的開始,如果字串開始不符合正則運算式,
則匹配失敗,函式回傳None;
而re.search 匹配整個字串,直到找到一個匹配, -
匹配多個字串
search 方法搜索一個字串,要想搜索多個字串,如搜索aa、bb 和cc,最簡單的方
法是在文本模式字串中使用擇一匹配符號(|),擇一匹配符號和邏輯或類似,只要滿足
任何一個,就算匹配成功, -
分組
如果一個模式字串中有用一對圓括號括起來的部分,那么這部分就會作為一組,可以
通過group 方法的引數獲取指定的組匹配的字串,當然,如果模式字串中沒有任何用圓
括號括起來的部分,那么就不會對待匹配的字串進行分組,
- 使用分組要了解如下幾點:
□ 只有圓括號括起來的部分才算一組,如果模式字串中既有圓括號括起來的部分,
也有沒有被圓括號括起來的部分,那么只會將被圓括號括起來的部分算作一組,其
它的部分忽略,
□ 用group 方法獲取指定組的值時,組從1 開始,也就是說,group(1)獲取第1 組的
值,group(2)獲取第2 組的值,以此類推,
□ groups 方法用于獲取所有組的值,以元組形式回傳,所以除了使用group(1)獲取第
1 組的值外,還可以使用groups()[0]獲取第1 組的值,獲取第2 組以及其它組的值
的方式類似,
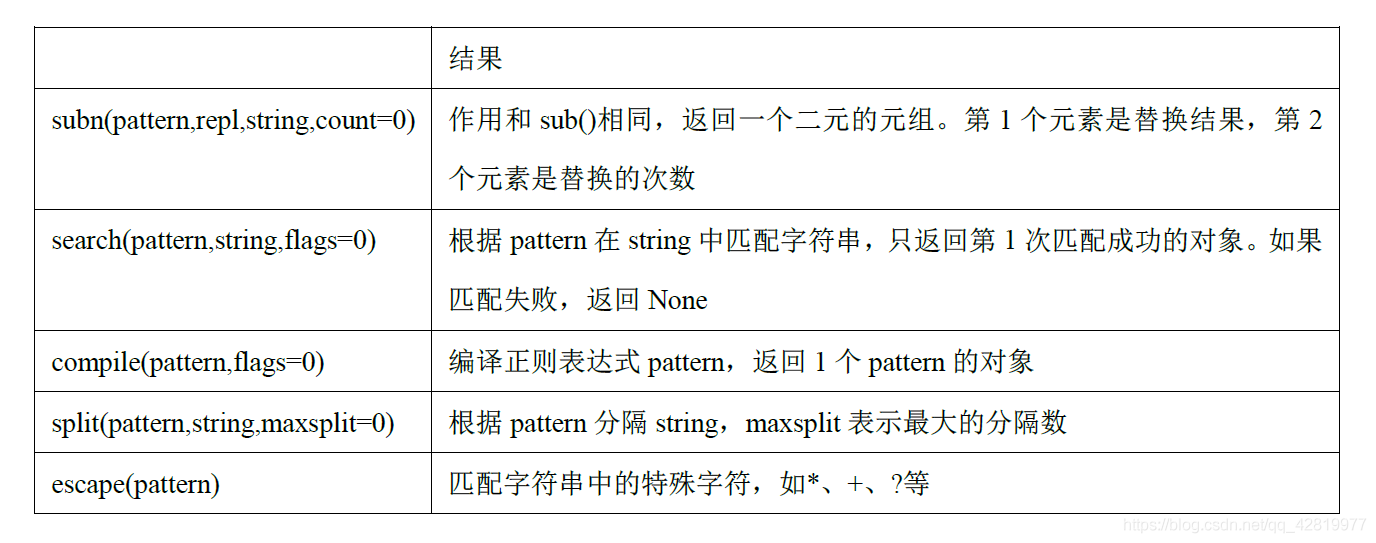
- re 模塊中其他常用的函式
- sub 和subn 搜索與替換
sub 函式和subn 函式用于實作搜索和替換功能,這兩個函式的功能幾乎完全相同,都是
將某個字串中所有匹配正則運算式的部分替換成其他字串,用來替換的部分可能是一個
字串,也可以是一個函式,該函式回傳一個用來替換的字串,sub 函式回傳替換后的結
果,subn 函式回傳一個元組,元組的第1 個元素是替換后的結果,第2 個元素是替換的總
數,語法格式如下:
re.sub(pattern, repl, string, count=0, flags=0)

- compile 函式
compile 函式用于編譯正則運算式,生成一個正則運算式( Pattern )物件,供match()
和search() 這兩個函式使用,語法格式為:
re.compile(pattern[, flags])

- findall 函式
在字串中找到正則運算式所匹配的所有子串,并回傳一個串列,如果沒有找到匹配的,
則回傳空串列,語法格式如下:
findall(pattern, string, flags=0)

注意:match 和search 是匹配一次findall 匹配所有
-
finditer 函式
和findall 類似,在字串中找到正則運算式所匹配的所有子串,并把它們作為一個迭
代器回傳, -
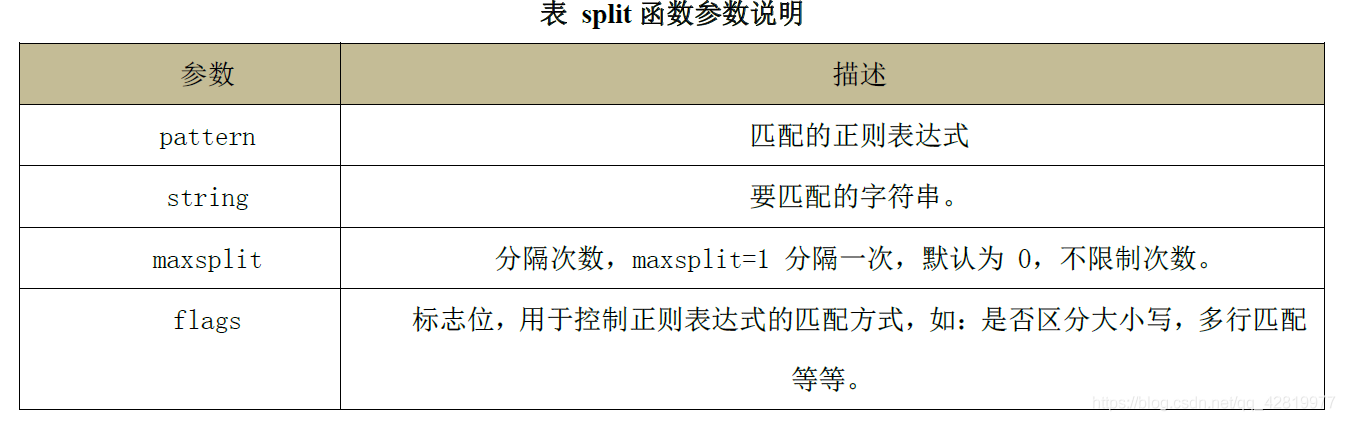
split 函式
split 函式用于根據正則運算式分隔字串,也就是說,將字串與模式匹配的子字串
都作為分隔符來分隔這個字串,split 函式回傳一個串列形式的分隔結果,每一個串列元素
都是分隔的子字串,語法格式如下:
re.split(pattern, string[, maxsplit=0, flags=0])
- 貪婪模式和非貪婪
貪婪模式指Python 里數量詞默認是貪婪的,總是嘗試匹配盡可能多的字符,非貪婪模
式與貪婪相反,總是嘗試匹配盡可能少的字符,可以使用"*","?","+","{m,n}"后面加上?,使
貪婪變成非貪婪
2、引入re庫
import re
三、re代碼實體展示
- 01match方法的使用
import re
s='hello python'
pattern='hello'
o=re.match(pattern,s)
print(o)
print(dir(o))
print(o.group()) #回傳匹配的字串
print(o.span())
print(o.start())
print('flags引數的使用')
s='hello python'
pattern='Hello'
o=re.match(pattern,s,flags=re.I)
print(o)
print(o.group())
- 02常用字符的使用
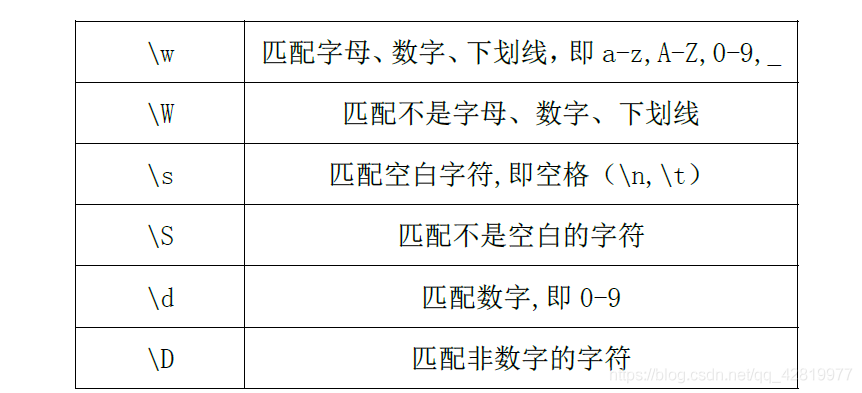
'''
. 匹配任意一個字符(除了\n)
[] 匹配串列中的字符
\w 匹配字母、數字、下劃線,即a-z,A-Z,0-9,_
\W 匹配不是字母、數字、下劃線
\s 匹配空白字符,即空格(\n,\t)
\S 匹配不是空白的字符
\d 匹配數字,即0-9
\D 匹配非數字的字符
'''
import re
print('--------.的使用--------')
s='a'
s='A'
s='8'
s='_'
s='\n'
pattern='.'
o=re.match(pattern,s)
print(o)
print('---------\d的使用------------')
s='0'
s='5'
s='9'
s='a'
pattern='\d'
o=re.match(pattern,s)
print(o)
print('---------\D的使用------------')
s='0'
# s='5'
s='9'
s='a'
pattern='\D'
o=re.match(pattern,s)
print(o)
print('--------\s的使用-----------')
s=' '
s='\n'
s='\t'
s='_'
pattern='\s'
o=re.match(pattern,s)
print(o)
print('--------\S的使用-----------')
s=' '
s='\n'
s='\t'
s='_'
pattern='\S'
o=re.match(pattern,s)
print(o)
print('---------\w的使用------------')
s='z'
s='A'
s='8'
s='_'
s='#'
pattern='\w'
o=re.match(pattern,s)
print(o)
print('---------\W的使用------------')
s='z'
# s='A'
s='8'
s='_'
s='#'
s='+'
pattern='\W'
o=re.match(pattern,s)
print(o)
print('---------[]的使用----------')
pattern='[2468]'
s='2'
s='3'
s='4'
s='6'
# s='8'
o=re.match(pattern,s)
print(o)
- 03匹配手機號碼
import re
# pattern='\d\d\d\d\d\d\d\d\d\d\d'
pattern='1[35789]\d\d\d\d\d\d\d\d\d'
s='13456788765'
o=re.match(pattern,s)
print(o)
#電話號碼 區號-座機號 010-3762266 0342-8776262
- 04重復數量符號
'''
* :0次或多次
?:0次或1次
+:至少1次
{m}:重復m次
{m,n}:重復m到n次
{m}:至少重復m次
'''
import re
print('--------*的使用------------')
pattern='\d*'
s='123qwe'
s='123456qwe'
s='qwe'
o=re.match(pattern,s)
print(o)
print('--------+的使用------------')
pattern='\d+'
# s='123qwe'
# s='1qwe'
# s='123456qwe'
s='qwe'
o=re.match(pattern,s)
print(o)
print('--------?的使用------------')
pattern='\d?'
s='123qwe'
s='1qwe'
s='123456qwe'
s='qwe'
o=re.match(pattern,s)
print(o)
print('---------{m}-----------')
pattern='\d{2}'
pattern='\d{3}'
pattern='\d{4}'
s='123qwe'
o=re.match(pattern,s)
print(o)
print('---------{m,n}-----------')
pattern='\d{2,5}'
s='123qwe'
s='123456qwe'
s='qwe'
o=re.match(pattern,s)
print(o)
print('---------{m,}-----------')
pattern='\d{2,}'
s='123qwe'
s='123456qwe'
s='qwe'
o=re.match(pattern,s)
print(o)
- 05重復數量限定符的使用
import re
print('------案例1------')
#匹配出一個字串首字母為大寫字符,后邊都是小寫字符,這些小寫字母可有可無
pattern='[A-Z][a-z]*'
s='Hello'
s='HEllo'
o=re.match(pattern,s)
print(o)
print('------案例2------')
#匹配出有效的變數名 (字母 、數字 下劃線 ,而且數字不能開頭)
# pattern='[a-zA-Z_][a-zA-Z0-9_]*'
pattern='[a-zA-Z_]\w*'
s='userName'
s='age'
s='a'
s='_qwe'
# s='3er'
o=re.match(pattern,s)
print(o)
print('-------案例3----------')
#匹配出1-99直接的數字
pattern='[1-9]\d?'
s='2'
s='99'
s='100'
s='0'
o=re.match(pattern,s)
print(o)
print('----------案例4--------------')
#匹配出一個隨機密碼8-20位以內 (大寫字母 小寫字母 下劃線 數字)
pattern='\w{8,20}'
s='123456789'
s='abc123qwe_'
s='1234567#'
o=re.match(pattern,s)
print(o)
- 06轉義字符的使用
print('d:\\a\\b\\c')
print('\nabc')
print('\\nabc')
print('\t123')
print('\\t123')
import re
s='\\t123'
# pattern='\\\\t\d*'
pattern=r'\\t\d*'
o=re.match(pattern,s)
print(o)
s='\\\\t123'
# pattern='\\\\\\\\t\d*'
pattern=r'\\\\t\d*'
o=re.match(pattern,s)
print(o)
- 07邊界字符的使用
import re
#匹配QQ郵箱 5-10位數字
qq='8656707@qq.com'
qq='8656707@qq.com.cn'
qq='8656707@qq.com.126.com'
# pattern='[1-9]\d{4,9}@qq.com'
pattern=r'[1-9]\d{4,9}@qq.com$'
o=re.match(pattern,qq)
print(o)
print('----------^開始------------')
# s='hello world'
s='hello python'
s='hepython'
pattern=r'^hello.*'
o=re.match(pattern,s)
print(o)
print('-------\\b匹配單詞的左邊界------------')
pattern=r'.*\bab'
s='12345 abc'
o=re.match(pattern,s)
print(o)
print('-------\\b匹配單詞的右邊界------------')
pattern=r'.*ab\b'
s='12345 abc'
s='12345 ab'
o=re.match(pattern,s)
print(o)
print('-------\\B匹配非單詞的邊界------------')
pattern=r'.*ab\B'
s='12345 abc'
s='12345 ab'
o=re.match(pattern,s)
print(o)
- 08search方法的使用
import re
pattern='hello'
s='hello python'
# m=re.search(pattern,s)
m=re.match(pattern,s)
print(m)
print(m.group())
print('-------macth和search的區別----------')
pattern='love'
s='I love you'
m=re.match(pattern,s)
print('使用match進行匹配',m)
o=re.search(pattern,s)
print('使用search進行匹配',o)
- 09匹配多個字符
import re
pattern='aa|bb|cc'
s='aa'
o=re.match(pattern,s)
print(o)
s='bb'
o=re.match(pattern,s)
print(o)
s='my name is cc'
o=re.search(pattern,s)
o=re.match(pattern,s)
print(o)
print('匹配0-100之間所有的數字')
#匹配0-100之間所有的數字 0-99|100
pattern=r'[1-9]?\d$|100$'
s='1'
s='11'
s='99'
s='100'
s='1000'
o=re.match(pattern,s)
print(o)
- 10擇一匹配符合串列使用差異
import re
# pattern=r'[xyz]'
# s='y'
# o=re.match(pattern,s)
# print('使用串列[]:',o)
#
# pattern=r'x|y|z'
# s='y'
# o=re.match(pattern,s)
# print('擇一匹配符|:',o)
# print('字符集([])和擇一匹配符(|)的用法,及它們的差異')
# pattern=r'[ab][cd]'
# s='ac'
# s='ab'
# o=re.match(pattern,s)
# print(o)
# pattern=r'ab[cd]'
# # s='ab'
# # s='abc'
# s='abd'
# o=re.match(pattern,s)
# print(o)
pattern='ab|cd'
# s='abc'
# s='abd'
# s='cd'
s='ad'
s='ac'
o=re.match(pattern,s)
print(o)
- 11匹配分組
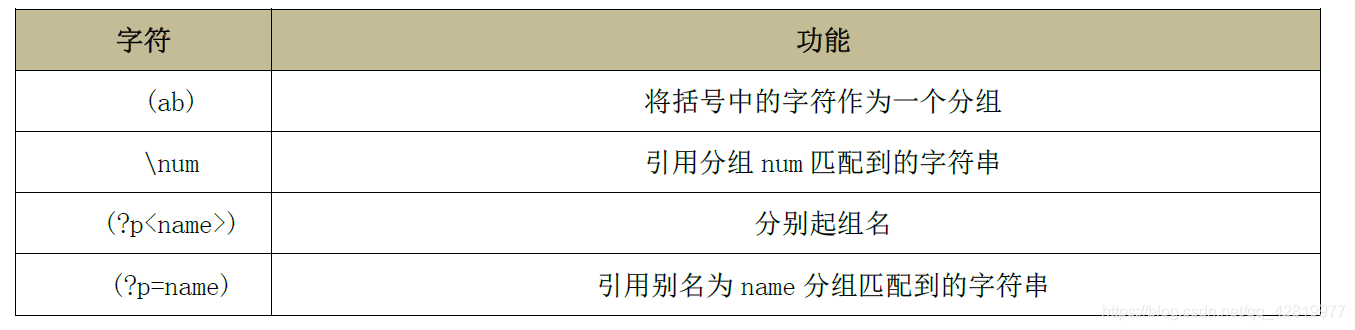
'''
(ab) 將括號中的字符作為一個分組
\num 參考分組num匹配到的字串
(?p<name>) 分別起組名
(?p=name) 參考別名為name分組匹配到的字串
'''
import re
print('匹配座機號碼')
#匹配座機號碼 區號{3,4}-電話號碼{5,8} 010-43222 0432-447727
pattern=r'\d{3,4}-[1-9]\d{4,7}$'
pattern=r'(\d{3,4})-([1-9]\d{4,7}$)'
s='010-786545'
o=re.match(pattern,s)
print(o)
print(o.group())
print(o.group(1))
print(o.group(2))
# print(o.groups())
# print(o.groups()[0])
# print(o.groups()[1])
print('匹配出網頁標簽內的資料')
# pattern=r'<.+><.+>.+</.+></.+>'
pattern=r'<(.+)><(.+)>.+</\2></\1>'
# s='<html><head>head部分</head></html>'
s='<html><title>head部分</head></body>'
o=re.match(pattern,s)
print(o)
#<body><h1><div><div></div></div></h1></body>
print('(?P<name>) 分別起組名')
pattern=r'<(?P<k_html>.+)><(?P<k_head>.+)>.+</(?P=k_head)></(?P=k_html)>'
s='<html><head>head部分</head></html>'
s='<html><title>head部分</head></body>'
o=re.match(pattern,s)
print(o)
- 12其他函式的使用
import re
print('--------sub-------------')
phone='2004-959-559 # 這是一個國外電話號碼'
#將phone中的注釋去掉
pattern=r'#.*$'
result=re.sub(pattern,'',phone)
print('sub:',result)
pattern=r'#\D*'
result=re.sub(pattern,'',phone)
print('sub:',result)
print('---------subn-----------')
result=re.subn(pattern,'',phone)
print(result)
print(result[0])
print(result[1])
print('---------compile------------')
s='first123 line'
pattern=r'\w+'
regex=re.compile(pattern)
o=regex.match(s)
print(o)
print('---------findall-------------')
s='first 1 second 2 third 3'
pattern=r'\w+'
result=re.findall(pattern,s)
print(result)
print('---------finditer-------------')
s='first 1 second 2 third 3'
pattern=r'\w+'
result=re.finditer(pattern,s)
print(result)
for i in result:
print(i.group(),end='\t')
print()
print('----------split-------------')
s='first 11 second 22 third 33'
pattern=r'\d+'
result=re.split(pattern,s)
print(result)
result=re.split(pattern,s,maxsplit=2)
print(result)
- 13貪婪模式和非貪婪模式
import re
v = re.match(r'(.+)(\d+-\d+-\d+)','This is my tel:133-1234-1234')
print('----------貪婪模式---------')
print(v.group(1))
print(v.group(2))
print('----------非貪婪模式---------')
v = re.match(r'(.+?)(\d+-\d+-\d+)','This is my tel:133-1234-1234')
print(v.group(1))
print(v.group(2))
print('-------實體2--------')
print('貪婪模式')
v= re.match(r'abc(\d+)','abc123')
print(v.group(1)) #123
#非貪婪模式
print('非貪婪模式')
v= re.match(r'abc(\d+?)','abc123')
print(v.group(1)) #1
總結
這里對文章進行總結: 如果有問題請聯系作者,私信+評論+QQ任選其一 作者QQ號碼:2423095292 作者Email: 2423095292@qq.comj2423095292@163.com
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/275162.html
標籤:python
下一篇:python-js逆向人人網登錄