作者:進擊的西西弗斯
本文鏈接:https://blog.csdn.net/qq_42216093/article/details/115587741
著作權宣告:本文為作者原創文章,轉載請附上原文出處鏈接
1.專案說明以及流程概要
- 爬取網站:智聯招聘(https://sou.zhaopin.com/)
- 開發環境:Python3.7(Pycharm編輯器),全流程通過代碼實作
- 爬取時間:2021/3/30 上午1:13 的實時招聘資訊資料
- 爬取城市:共12個,上海、北京、廣州、深圳、天津、武漢、西安、成都、南京、杭州、重慶、廈門
- 主要用到的python庫:
requests、BeautifulSoup、pandas、matplotlib、seaborn
- 說明:本人大四,想在畢業后進入資料分析行業作業,于是,為了更深入地了解資料分析職位相關資訊,我使用python在智聯招聘網站爬取了我國主要的12個城市的“資料分析師”職位的全部招聘資訊資料,包括薪資、公司名稱以及規模、學歷要求、技能要求、作業經驗要求等資料,對資料清洗和整理后進行可視化分析,得到了薪資分布、不同學歷占比、技能詞頻等圖表,目的是能從繁雜的招聘資料中直觀地看到有價值的資訊,
2.爬取網站資料并整理為csv
流程概要:
根據url和相關引數獲取網頁的html,對html決議后正則提取我們需要的標簽資訊,最終以dataframe二維表形式保存為csv檔案,**其中要注意:**智聯招聘在未登陸狀態下無法爬取職位資料,于是我們可以先登陸網站,然后在瀏覽器開發者模式下找到需求頭資訊(Request Headers),復制下來后通過copyheaders庫轉換為字典后加入requests請求的headers引數中,
代碼:(附注釋)
#!/usr/bin/python3
# -*- coding: utf-8 -*-
"""
Created on Fri Aug 14 17:47:47 2020: 2021/3/30 上午1:13
@Author : liudong
@Software: PyCharm
"""
import requests
import re
from copyheaders import headers_raw_to_dict
from bs4 import BeautifulSoup
import pandas as pd
# 根據url和引數獲取網頁的HTML:
def get_html(url, params):
my_headers = b'''
accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
accept-language: zh-CN,zh;q=0.9
cache-control: max-age=0
cookie: x-zp-client-id=448f2b96-6b3a-48e3-e912-e6c8dd73e6cb; adfbid=0; adfbid2=0; Hm_lvt_38ba284938d5eddca645bb5e02a02006=1617108464; sajssdk_2015_cross_new_user=1; sts_deviceid=178832cf3f2680-0b20242883a4a9-6618207c-1296000-178832cf3f3780; sts_sg=1; sts_chnlsid=Unknown; zp_src_url=https%3A%2F%2Fwww.google.com.hk%2F; FSSBBIl1UgzbN7N443S=kc8_mcJe5xsW.UilCMHXpkoWeyQ8te3q7QhYV8Y8aA0Se9k9JJXcnQVvrOJ9NYDP; locationInfo_search={%22code%22:%22538%22%2C%22name%22:%22%E4%B8%8A%E6%B5%B7%22%2C%22message%22:%22%E5%8C%B9%E9%85%8D%E5%88%B0%E5%B8%82%E7%BA%A7%E7%BC%96%E7%A0%81%22}; zp_passport_deepknow_sessionId=a2ea7206sade7641768f38078ea6b45afef0; at=02a0ea392e1d4fd6a4d6003ac136aae0; rt=82f98e13344843d6b5bf3dadf38e8bb2; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%221071739258%22%2C%22first_id%22%3A%22178832cf3bd20f-0be4af1633ae3d-6618207c-1296000-178832cf3be4b8%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%7D%2C%22%24device_id%22%3A%22178832cf3bd20f-0be4af1633ae3d-6618207c-1296000-178832cf3be4b8%22%7D; urlfrom=121126445; urlfrom2=121126445; adfcid=none; adfcid2=none; ZL_REPORT_GLOBAL={%22//www%22:{%22seid%22:%2202a0ea392e1d4fd6a4d6003ac136aae0%22%2C%22actionid%22:%2243ffc74e-c32e-42ee-ba04-1e24611fecde-cityPage%22}}; LastCity=%E4%B8%8A%E6%B5%B7; LastCity%5Fid=538; Hm_lpvt_38ba284938d5eddca645bb5e02a02006=1617111259; zpfe_probe_token=ae612f12s0feb44ac697a7434fe1f22af086; d4d6cd0b4a19fa72b8cc377185129bb7=ab637759-b57a-4214-a915-8dcbc5630065; selectCity_search=538; FSSBBIl1UgzbN7N443T=5pRoIYmxrZTzxVozDFEYjcClKKRpXbK9zf0gYH4zU5AyLqGUMT5fnVzyE0SMv7ZDGFLY0HV8o6iXLPBGBBTJhDhz3TIaQ3omm324Q2m4BSJzD0VgZzesPGIXudf636xQZkuag1QJmdqzgFLv6YPcKq.ukZPymp1IazfsOec5vBcMT9yemSrYb9UBk2XF.rZIeM3mIOBqpNii26kDRzjxHP5TsGLJzWaaZvklHnh61NT4acHPQt3Lq1.w2X4htg9ck.uGhzHt9w954igFEqhLCmggLi9OjPUaiU8TA4yn1oR1T5Qmjm1I5AA0PIu76e0T2u6w2f7thMkv6E7lkoDggrRMta0Z_uVEP3Y1sS8hJw7ycE2PTVtVassRyoN6UuTBHtSZ
sec-ch-ua: "Google Chrome";v="89", "Chromium";v="89", ";Not A Brand";v="99"
sec-ch-ua-mobile: ?0
sec-fetch-dest: document
sec-fetch-mode: navigate
sec-fetch-site: same-origin
sec-fetch-user: ?1
upgrade-insecure-requests: 1
user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36
'''
my_headers = headers_raw_to_dict(my_headers) # 把復制的瀏覽器需求頭轉化為字典形式
req = requests.get(url, headers=my_headers, params=params)
req.encoding = req.apparent_encoding
html = req.text
return html
# 輸入url和城市編號,獲取由所有職位資訊的html標簽的字串組成的串列:
def get_html_list(url, city_num):
html_list = list()
for i in range(1, 12):
params = {'jl': str(city_num), 'kw': '資料分析師', 'p': str(i)}
html = get_html(url, params)
soup = BeautifulSoup(html, 'html.parser')
html_list += soup.find_all(name='a', attrs={'class': 'joblist-box__iteminfo iteminfo'})
for i in range(len(html_list)):
html_list[i] = str(html_list[i])
return html_list
# 根據上面的HTML標簽串列,把每個職位資訊的有效資料提取出來,保存csv檔案:
def get_csv(html_list):
# city = position = company_name = company_size = company_type = salary = education = ability = experience = evaluation = list() #
# 上面賦值方法在這里是錯誤的,它會讓每個變數指向同一記憶體地址,如果改變其中一個變數,其他變數會同時發生改變
# table = pd.DataFrame(columns = ['城市','職位名稱','公司名稱','公司規模','公司型別','薪資','學歷要求','技能要求','作業經驗要求'])
city, position, company_name, company_size, company_type, salary, education, ability, experience = ([] for i in range(9)) # 多變數一次賦值
for i in html_list:
if re.search(
'<li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li>',
i):
s = re.search(
'<li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li>',
i).group(1)
city.append(s)
s = re.search(
'<li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li>',
i).group(2)
experience.append(s)
s = re.search(
'<li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li> <li class="iteminfo__line2__jobdesc__demand__item">(.*?)</li>',
i).group(3)
education.append(s)
else:
city.append(' ')
experience.append(' ')
education.append(' ')
if re.search('<span class="iteminfo__line1__jobname__name" title="(.*?)">', i):
s = re.search('<span class="iteminfo__line1__jobname__name" title="(.*?)">', i).group(1)
position.append(s)
else:
position.append(' ')
if re.search('<span class="iteminfo__line1__compname__name" title="(.*?)">', i):
s = re.search('<span class="iteminfo__line1__compname__name" title="(.*?)">', i).group(1)
company_name.append(s)
else:
company_name.append(' ')
if re.search(
'<span class="iteminfo__line2__compdesc__item">(.*?) </span> <span class="iteminfo__line2__compdesc__item">(.*?) </span>',
i):
s = re.search(
'<span class="iteminfo__line2__compdesc__item">(.*?) </span> <span class="iteminfo__line2__compdesc__item">(.*?) </span>',
i).group(1)
company_type.append(s)
s = re.search(
'<span class="iteminfo__line2__compdesc__item">(.*?) </span> <span class="iteminfo__line2__compdesc__item">(.*?) </span>',
i).group(2)
company_size.append(s)
else:
company_type.append(' ')
company_size.append(' ')
if re.search('<p class="iteminfo__line2__jobdesc__salary">([\s\S]*?)<', i):
s = re.search('<p class="iteminfo__line2__jobdesc__salary">([\s\S]*?)<', i).group(1)
s = s.strip()
salary.append(s)
else:
salary.append(' ')
s = str()
l = re.findall('<div class="iteminfo__line3__welfare__item">.*?</div>', i)
for i in l:
s = s + re.search('<div class="iteminfo__line3__welfare__item">(.*?)</div>', i).group(1) + ' '
ability.append(s)
table = list(zip(city, position, company_name, company_size, company_type, salary, education, ability, experience))
return table
if __name__ == '__main__':
url = 'https://sou.zhaopin.com/'
citys = {'上海':538, '北京':530, '廣州':763, '深圳':765, '天津':531, '武漢':736, '西安':854, '成都':801, '南京':635, '杭州':653, '重慶':551, '廈門':682}
for i in citys.keys():
html_list = get_html_list(url, citys[i])
table = get_csv(html_list)
df = pd.DataFrame(table, columns=['city', 'position', 'company_name', 'company_size', 'company_type', 'salary',
'education', 'ability', 'experience'])
file_name = i + '.csv'
df.to_csv(file_name)
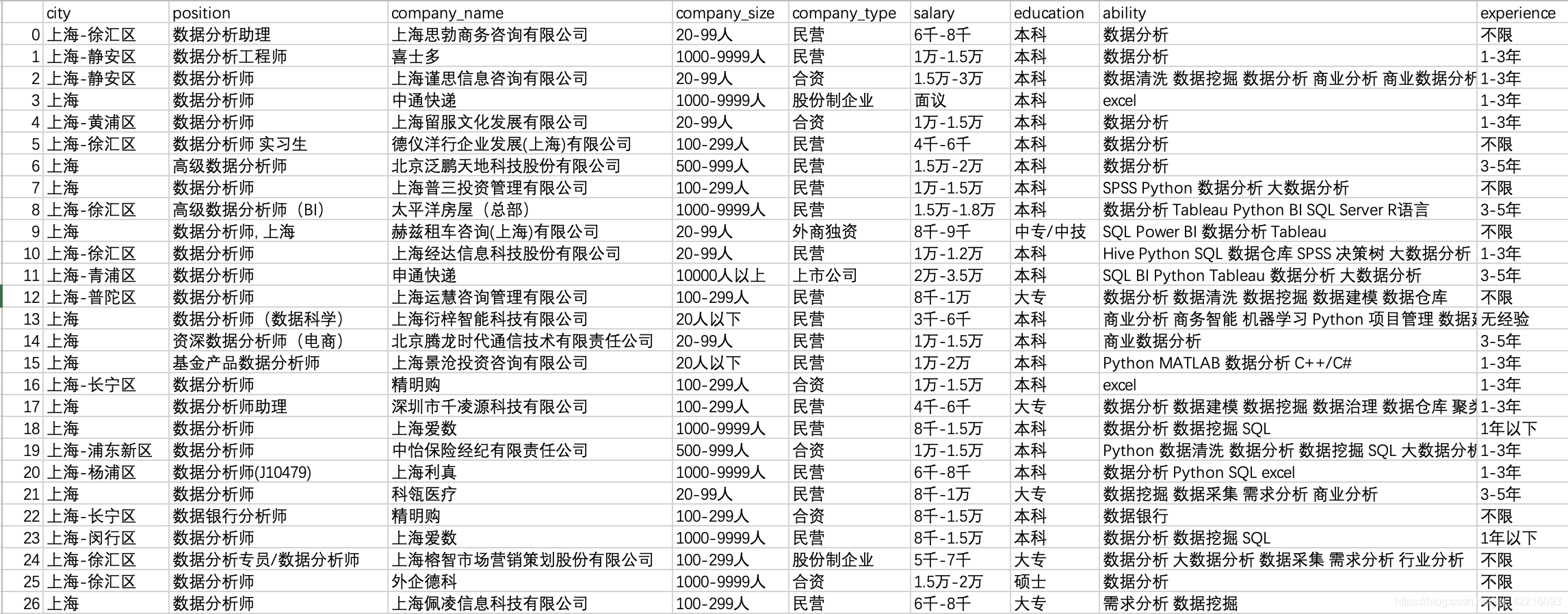
結果:
3.對資料結果進行可視化
流程概要:
先對資料結果進行清洗,salary屬性下的欄位都是類似于“8千-1.5萬”這種無法進行后續統計和處理的字串,我們需要將其全部修改為數值結果從而方便后續處理,此處我使用pandas和re(正則運算式)把每個欄位的薪資統一處理成了范圍的中間值,關于薪資的缺失值,我本來打算用所在城市薪資的平均值替換處理,但考慮到后續可視化分析只使用到平均值,替換處理與否并不影響結果,故沒有再做處理,由于時間關系,還有其他空值、例外值等資料清洗并沒有再繼續處理,最后,使用matplotlib和seaborn進行資料可視化,共得到5個結果圖
代碼:(附注釋)
#!/usr/bin/python3
# -*- coding: utf-8 -*-
"""
Created on Fri Aug 14 17:47:47 2020: 2021/4/2 上午1:30
@Author : liudong
@Software: PyCharm
"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
plt.rcParams['font.sans-serif'] = ['Heiti TC'] # 指定默認字體:解決plot不能顯示中文問題
plt.rcParams['axes.unicode_minus'] = False # 解決保存影像是負號'-'顯示為方塊的問題
import re
import os
import seaborn as sns
from wordcloud import WordCloud
citys = ['上海', '北京', '廣州', '深圳', '天津', '武漢', '西安', '成都', '南京', '杭州', '重慶', '廈門']
#資料清洗:
def data_clear():
for i in citys:
file_name = './' + i + '.csv'
df = pd.read_csv(file_name, index_col = 0)
for i in range(0, df.shape[0]):
s = df.loc[[i],['salary']].values.tolist()[0][0]
if re.search('(.*)-(.*)',s):
a = re.search('(.*)-(.*)', s).group(1)
if a[-1] == '千':
a = eval(a[0:-1]) * 1000
elif a[-1] == '萬':
a = eval(a[0:-1]) * 10000
b = re.search('(.*)-(.*)', s).group(2)
if b[-1] == '千':
b = eval(b[0:-1]) * 1000
elif b[-1] == '萬':
b = eval(b[0:-1]) * 10000
s = (a + b) / 2
df.loc[[i], ['salary']] = s
else:
df.loc[[i], ['salary']] = ''
os.remove(file_name)
df.to_csv(file_name)
#各個城市資料分析職位數量條形圖:
def citys_jobs():
job_num = list()
for i in citys:
file_name = './' + i + '.csv'
df = pd.read_csv(file_name, index_col = 0)
job_num.append(df.shape[0])
df = pd.DataFrame(list(zip(citys, job_num)))
df = df.sort_values(1, ascending = False)
x = list(df[0])
y = list(df[1])
fig = plt.figure(dpi=200)
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
ax.bar(x,y,alpha = 0.8)
ax.set_title('資料分析職位在全國主要城市的數量分布')
ax.set_ylim(0,350)
plt.savefig('./資料分析職位在全國主要城市的數量分布.jpg')
plt.show()
#不同城市薪資分布條形圖:
def citys_salary():
y = list()
x = citys
for i in citys:
file_name = './' + i + '.csv'
df = pd.read_csv(file_name, index_col=0)
y0 = df['salary'].mean()
y.append(round(y0/1000, 1))
df = pd.DataFrame(list(zip(x,y)))
df = df.sort_values(1, ascending = False)
x = list(df[0])
y = list(df[1])
fig = plt.figure(dpi=200)
ax = fig.add_axes([0.1, 0.1, 0.8, 0.8])
ax.bar(x, y, alpha = 0.8)
ax.set_title('資料分析職位在一些主要城市的薪資分布(單位:千)')
ax.set_ylim(5, 18)
for a, b, label in zip(x, y, y): # 內置函式zip():將幾個串列合并為二維串列并轉置,回傳一個特殊物件,可通過list()串列化之后查看
plt.text(a, b, label, horizontalalignment = 'center', fontsize = 10) # plt.text()函式:在圖中(a,b)位置添加一個文字標簽label
plt.savefig('./資料分析職位在一些主要城市的薪資分布.jpg')
plt.show()
#資料分析崗位總體薪資的分布
def salary_distribute():
salary_list = list()
for i in citys:
file_name = './' + i + '.csv'
df = pd.read_csv(file_name, index_col = 0)
salary_list += list(df['salary'])
salarys = list()
for i in range(len(salary_list)):
if not pd.isnull(salary_list[i]): #由于該串列是從pandas中讀出的資料,故不能用if salary_list[i] == np.nan,會識別不出來
salarys.append(round(salary_list[i]/1000, 1))
mean = np.mean(salarys)
plt.figure(dpi=200)
sns.distplot(salarys, hist = True, kde = True, kde_kws={"color":"r", "lw":1.5, 'linestyle':'-'})
plt.axvline(mean, color='r', linestyle=":")
plt.text(mean, 0.01, '平均薪資: %.1f千'%(mean), color='r', horizontalalignment = 'center', fontsize = 15)
plt.xlim(0,50)
plt.xlabel('薪資分布(單位:千)')
plt.title('資料分析職位整體薪資分布')
plt.savefig('./資料分析職位整體薪資分布.jpg')
plt.show()
#資料分析職位對學歷要求的分布
def education_distribute():
table = pd.DataFrame()
for i in citys:
file_name = './' + i + '.csv'
df = pd.read_csv(file_name, index_col=0)
table = pd.concat([table, df])
table = pd.DataFrame(pd.value_counts(table['education']))
table = table.sort_values(['education'], ascending = False)
x = list(table.index)
y = list(table['education'])
print(x)
fig = plt.figure(dpi=200)
ax = fig.add_axes([0.1,0.1,0.8,0.8])
explode = (0, 0, 0, 0.2, 0.4, 0.6, 0.8)
ax.axis('equal')
ax.pie(y,labels = x,autopct='%.1f%%',explode=explode) #autopct顯示每塊餅的百分比屬性且自定義格式化字串,其中%%表示字串%,類似正則
ax.set_title('資料分析職位對學歷要求的占比')
ax.legend(x, loc = 1)
plt.savefig('./資料分析職位對學歷要求的占比.jpg')
plt.show()
#技能關鍵詞頻統計
def wordfrequence():
table = pd.DataFrame()
for i in citys:
file_name = './' + i + '.csv'
df = pd.read_csv(file_name, index_col=0)
table = pd.concat([table, df])
l1 = list(table['ability'])
l2 = list()
for i in range(len(l1)):
if not pd.isnull(l1[i]):
l2.append(l1[i])
words = ''.join(l2)
cloud = WordCloud(
font_path='/System/Library/Fonts/STHeiti Light.ttc', # 設定字體檔案獲取路徑,默認字體不支持中文
background_color='white', # 設定背景顏色 默認是black
max_words=20, # 詞云顯示的最大詞語數量
random_state = 1, # 設定隨機生成狀態,即多少種配色方案
collocations = False, # 是否包括詞語之間的搭配,默認True,可能會產生語意重復的詞語
width=1200, height=900 # 設定大小,默認圖片比較小,模糊
).generate(words)
plt.figure(dpi=200)
plt.imshow(cloud) # 該方法用來在figure物件上繪制傳入影像資料引數的影像
plt.axis('off') # 設定詞云圖中無坐標軸
plt.savefig("./技能關鍵詞頻統計.jpg")
plt.show()
if __name__ == "__main__":
data_clear()
citys_jobs()
citys_salary()
salary_distribute()
wordfrequence()
結果:
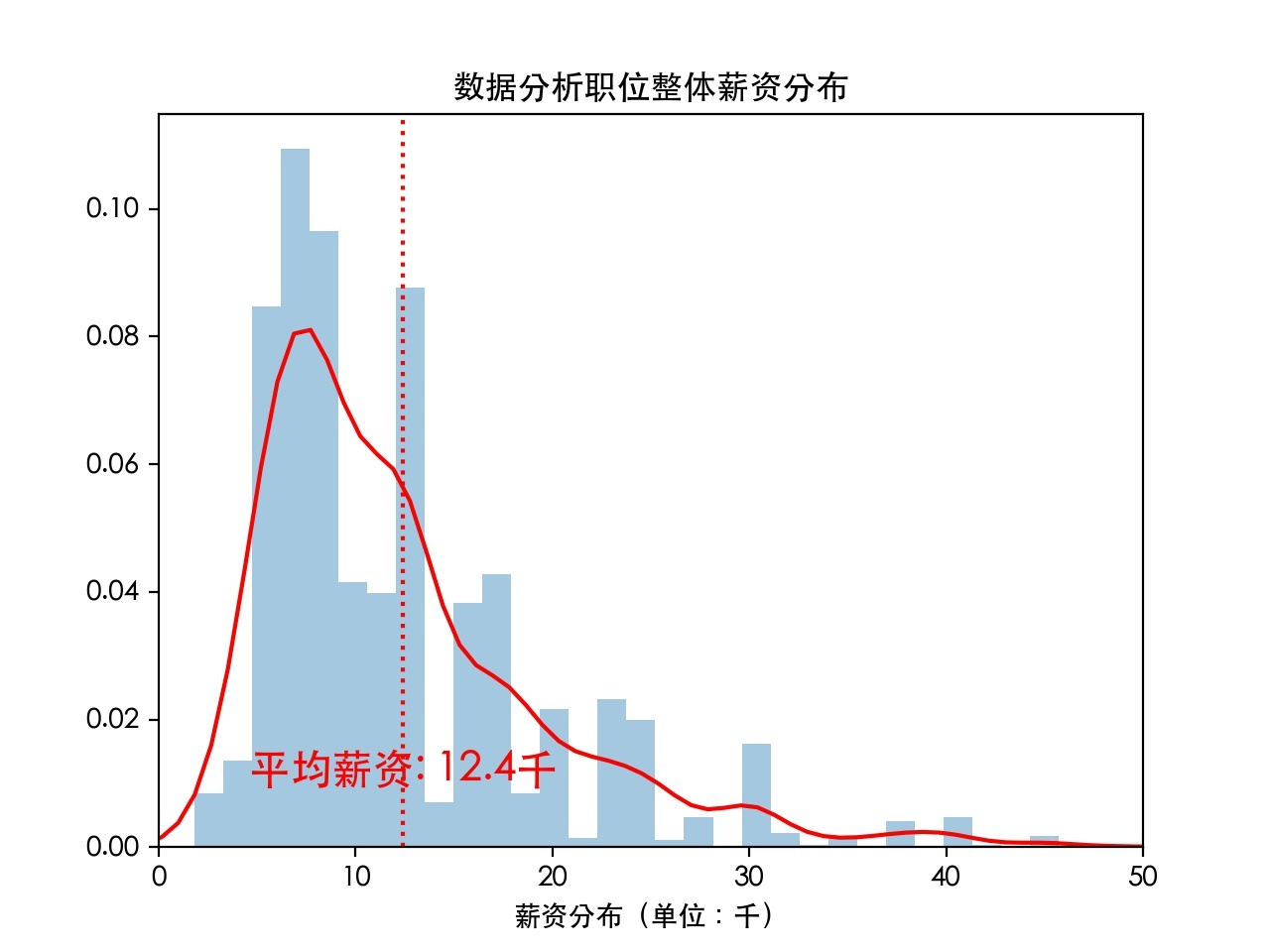
1). 在這12個城市總體的薪資分布情況:(直方圖+核密度分布函式)
可以看出,資料分析職位整體上薪資分布大致符合左偏態分布,薪資分布的密集區間大約在8k-15k之間,而平均薪資12.4k在整個IT行業中大致處于中等薪酬位置
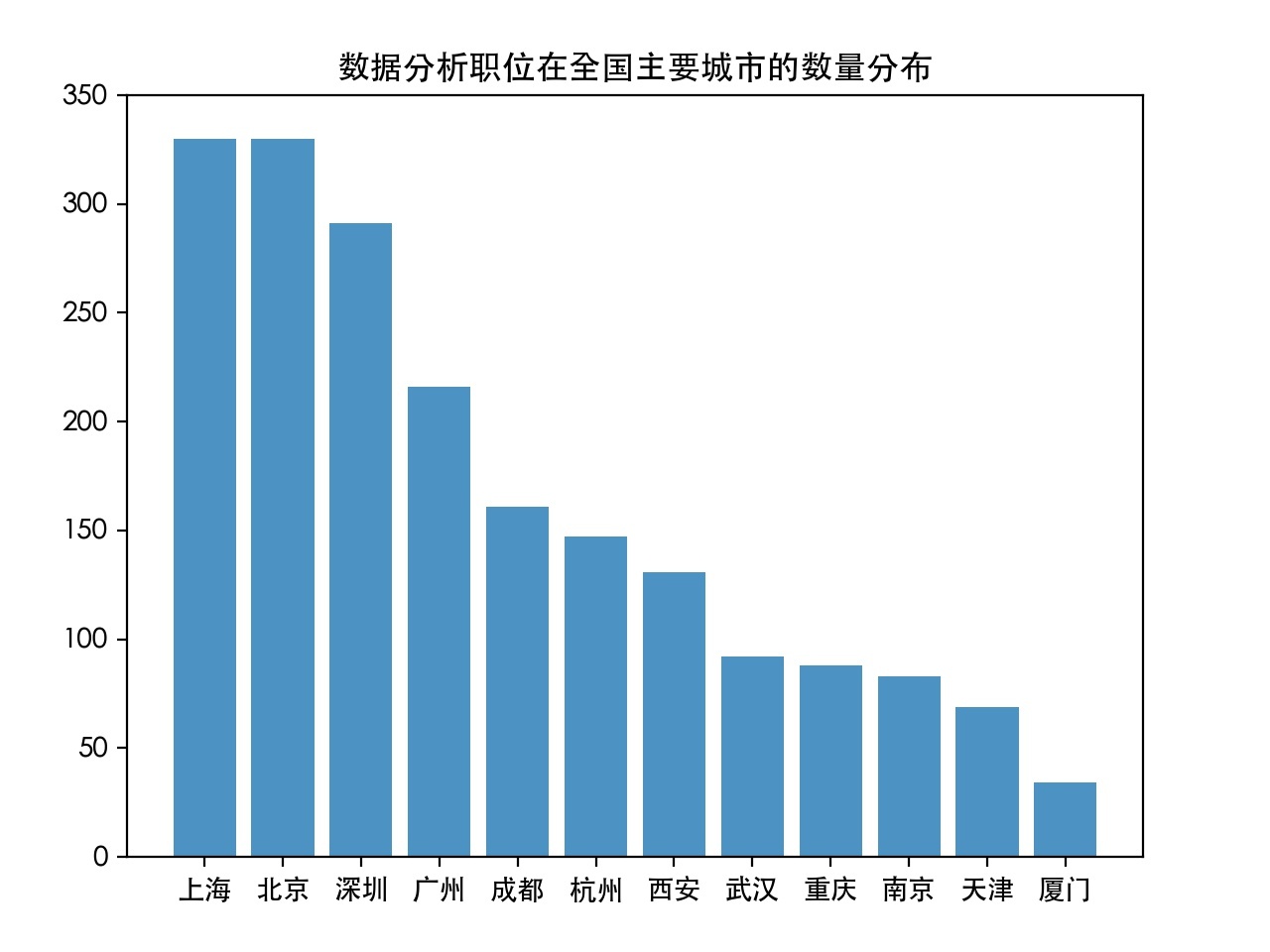
2). 在不同城市的職位招聘數量分布情況:(已降序處理)
可以看出,一線城市北上廣深位列榜首,結果符合常理,接下來是成都、杭州、西安,如果想去二線城市發展,這幾個城市應該重點考慮,
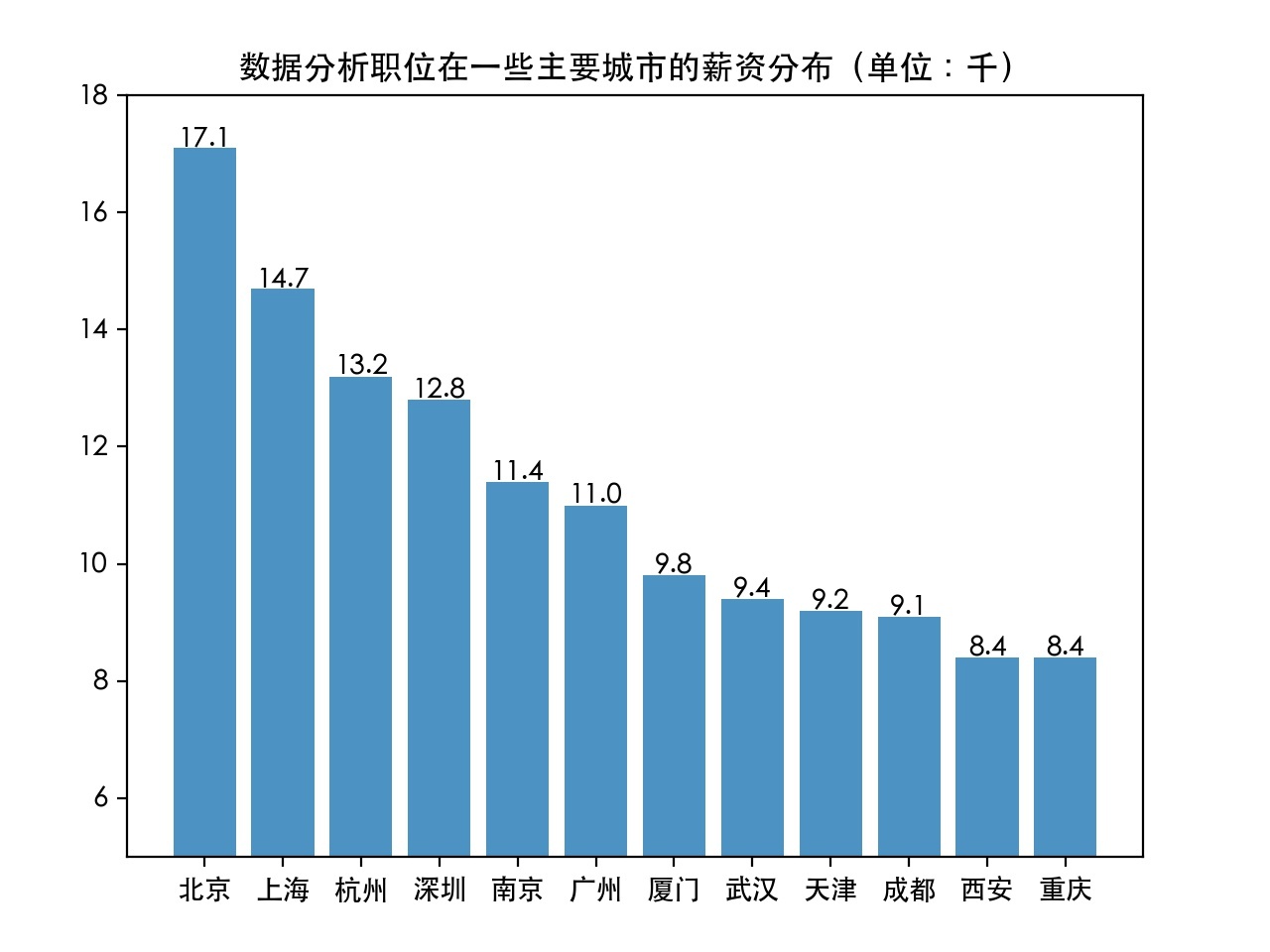
3). 在不同城市的薪資分布情況:(已降序處理)
可以看出,在不同城市間的薪資分布大致與上面的職位數量分布相似,但出乎意料的是,廣州被二線城市杭州、南京超越,這可能是由于杭州的阿里巴巴公司等以及南京的蘇寧等這些大公司拉高了杭州和南京的資料分析薪資水平,也可能是爬取的智聯招聘網站的資料樣本有一定的局限性,具體原因有待進一步考查,
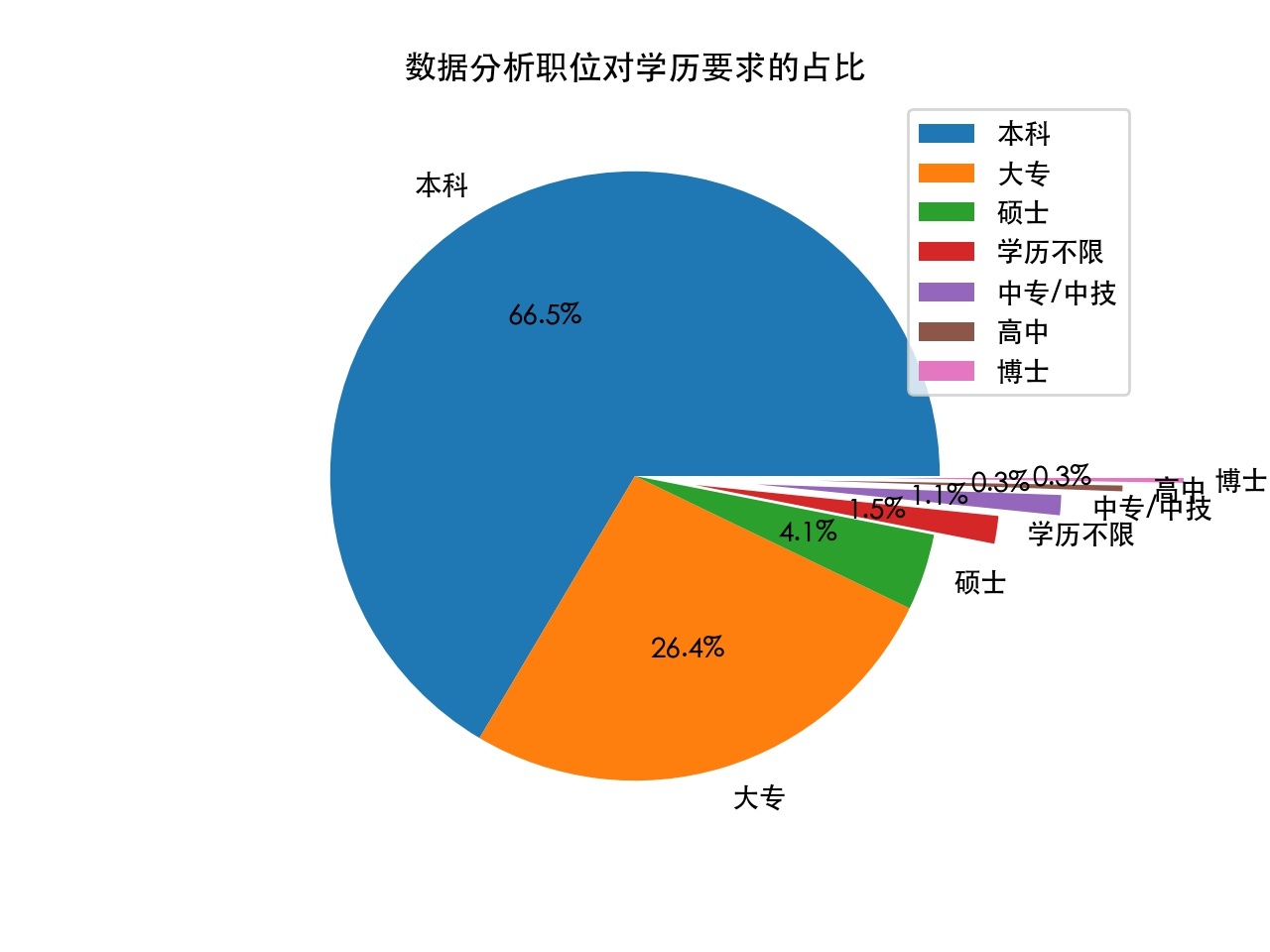
4). 招聘中對學歷要求的占比:
可以看出,本科占比最大,為66.5%,其次是大專,而其余學歷加起來只占比7.1%,因此,資料分析職位目前對于學歷要求相對較低,適合于不打算讀研的本科畢業生等人群,
5). 職位技能要求關鍵詞頻統計:
可以看出,資料分析職位主要需求技能是Python、SQL、資料挖掘、大資料、資料建模等,因此熟練掌握這些技能能夠增加求職中的核心競爭力,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/275479.html
標籤:python
上一篇:控制流作業