菜雞自學 Python 筆記:正則運算式
- 一.簡單理解
- 二. re.findall函式
- 三.普通字符與元字符
- 1.普通字符
- 2.元字符
- 四.修飾符(可選標志)
- 五.re.sub函式
- 六.re.match函式
- 七.re.search函式
一.簡單理解
簡單來說,正則運算式是一個特殊的字符序列,判斷一個字串是否與我們所設定的這樣的字符數列相匹配,從而可以將匹配的字符做出檢索、替換、洗掉等操作,它常由 普通字符 以及特殊字符 組成,
例如,我們可以用來檢查用戶輸入的內容是否符合我們需要的格式等等,
下面我們用一個例子,簡單理解一下,正則運算式,(判斷下列字串中是否包含 Python):
如果我們不用正則運算式,我們可以這樣判斷(其實已經很簡單了):
a='C|C++|Java|Python|C#'
print(a.index('Python')>-1) # 索引
print('Python' in a) # in 關鍵詞
# True
# True
下面我們來看看用正則運算式,怎么辦:
import re # 引入一個正則運算式需要的模塊
a='C|C++|Java|Python|C#'
re.findall('Python', a) # 正則運算式(使用了findall函式)
r=re.findall('Python', a) # 列印結果
print(r)
# ['Python']
r1=re.findall('Go', a) # 列印結果
print(r1)
# []
# 所以可以如此應用(規則)
if len(r)!=0:
print('a中含Python')
else:
print('No')
相比于以上兩種方法,正則運算式不僅判斷了其是否存在,而且將此字串以串列的形式回傳,
那有人可能會說了,用正則運算式不是更煩了嗎?矮油,不要著急,它的作用可不止這些,我們下面慢慢講,
二. re.findall函式
我們先來介紹一下re.findall函式
它就是在字串中找到正則運算式所匹配的所有子串,并回傳一個串列,如果沒有找到匹配的,則回傳空串列,
findall(string,a[, pos[, endpos]])
引數:
string : 待匹配的字串,
a: 原字串,
pos : 可選引數,指定字串的起始位置,默認為 0,
endpos : 可選引數,指定字串的結束位置,默認為字串的長度,
還是原來的字串,我們換個匹配字符試試,
import re
a='C|C++|Java|Python|C#'
r=re.findall('C', a)
print(r)
# ['C', 'C', 'C']
三.普通字符與元字符
1.普通字符
普通字符包括沒有顯式指定為元字符的所有可列印和不可列印字符,這包括所有大寫和小寫字母、所有數字、所有標點符號和一些其他符號,
如下列,我想要在一串字串中提取所有的數字,我們可以這樣寫:
import re
a = 'adh0eu2jf3+=dj6*&fa90@4'
r = re.findall('[0-9]', a)
print(r)
#['0', '2', '3', '6', '9', '0', '4']
0-9 就是其中的普通字符,而我們 [ ] 表示的是我們匹配的只要是0-9的數都可以,
同理,我們也可以用這種方式匹配大寫字母,小寫字母,或者個別字符等等,
r = re.findall('[a-z]', a)
r = re.findall('[A-Z]', a)
r = re.findall('[Asu]', a)
2.元字符
元字符也就是特殊字符
當我們想要匹配數字字符,字母字符和一些特殊符號時,我們用普通字符則需要在[ ]里寫上一大長串:
r = re.findall('[0-9a-zA-Z!%^&]', a)
這樣每次書寫,難免會嫌煩了,這時候元字符就能很好的派上用場了,它可以用簡短的字符代替冗雜的普通字符,
a='adh0eu2jf3+=dj6*&fa90@4'
r=re.findall('\d',a) # \d 表示0~9
print(r)
r=re.findall('\D',a) # \D 表示除0-9以外的所有字符
print(r)
我們常見的元字符有:
| 常見元字符 | 作用 |
|---|---|
| \d | 匹配一個數字字符,等價于 [0-9], |
| \D | 匹配一個非數字字符,等價于 [^0-9], |
| \s | 匹配任何空白字符,包括空格、制表符、換頁符等等, |
| \S | 匹配任何非空白字符 |
| \w | 匹配字母、數字、下劃線,等價于’[A-Za-z0-9_]’, |
| \W | 匹配非字母、數字、下劃線,等價于 ‘[^A-Za-z0-9_]’, |
元字符有很多,我們下面邊講邊介紹,
同樣,我們試試匹配一個字符集,
- [ ] 其中的字符為或關系,
- ^ 原意思 取反,
- - 表示一個范圍,
import re
# 字符集
s ='abc,acc,adc,aec,afc,ahc'
# 匹配出acc 或 afc
r = re.findall('a[cf]c', s) # 【】或關系
print(r)
# ['acc', 'afc']
#匹配出除acc和afc以外的字串
r = re.findall('a[^cf]c', s) # ^ 取反
print(r)
# ['abc', 'adc', 'aec', 'ahc']
#匹配出c-f中的所有
r = re.findall('a[c-f]c', s) # - 范圍
print(r)
# ['acc', 'adc', 'aec', 'afc']
數量詞:
我們再看看下面這個例子,[a-z]是上面講過的普通字符,而不同的是后面多了一個{3}.這是什么意思呢?
import re
a = 'python 1111 java739php'
r = re.findall('[a-z]{3}',a)
print(r)

看看運行結果就可以知道,{n} 可以表示一種成組匹配的方式,如上,三個字母為一組,一一取出,
除了{n},我們還有 {n,m} (n,m都是非負整數,且n<m):意思是最少匹配 n 次且最多匹配 m 次,同樣, {n,} 至少匹配n 次,
a = 'python 1111 java739php'
r = re.findall('[a-z]{3,6}',a)
# {3,6}表示最少匹配3次,最多匹配6次
print(r)
結果:

這時候有人可能會問了,匹配最少3次,最多6次,那最開始為什么不只匹配3、4、5次呢?為什么‘Python’這個詞全被匹配出來了呢?
這就涉及到了貪婪和非貪婪的概念了,
- 貪婪匹配:趨向于最大長度匹配 ,盡可能多的匹配,直到不滿足條件為止,(正則運算式默認都為貪婪匹配)
- 非貪婪匹配:就是匹配到結果就好,就少的匹配字符,
正則運算式默認都為貪婪匹配,
那如果我們不需要它貪婪匹配,讓它們到非貪婪匹配行不行呢?這也是有辦法的,在后面加上一個 ? 就可以了,
r = re.findall('[a-z]{3,6}?',a)
print(r)

元字符中的數量詞還有:
| 量詞元字符 | 含義 |
|---|---|
| * | 匹配0次或無限多次 |
| + | 匹配1次或無限多次 |
| ? | 匹配0次或者一次 |
下面用例子來理解:
import re
a = 'pytho1111 python739pythonn^'
r = re.findall('python*', a)
print(r)
r = re.findall('python+', a)
print(r)
r = re.findall('python?', a)
print(r)
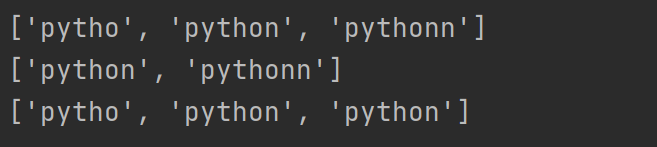
以上a字串中有三組字串‘pytho’,‘python’,‘pythonn’,
對于n來說 ‘pytho’中 n數為0次,‘python’ 中n數為1次,'pythonn’中 n數為2次,
所以,根據上面的表格,* 從0到無限次都能匹配,+ 不能匹配0次,?只能匹配0次到1次,
注意:這里的 ? 與之前講非貪婪匹配時出現的 ? 的區別,兩者并不相同,
邊界匹配:
邊界匹配不得不提兩個元字符:
| 元字符 | 含義 |
|---|---|
| ^ | 匹配輸入字串的開始位置, |
| $ | 匹配輸入字串的結束位置, |
如以下例子,我想要判斷用戶輸入的是否符合4-8位的qq號格式,
import re
qq='qq1000001qq'
r=re.findall('\d{4,8}',qq)
print(r)

這個結果,顯然不是我們想要的,以上字串明明不符合所要的qq號格式,卻也能匹配出結果,
這時候就可以用到邊界匹配了,
- ^ 從開頭開始匹配,開頭不符合就無法匹配到結果,
- $ 結尾匹配,結尾不符合也無法達到要求,
qq='qq1000001'
r=re.findall('^\d{4,8}',qq)
# []
r=re.findall('\d{4,8}$',qq)
# ['1000001']
r=re.findall('^\d{4,8}$',qq)
#[]
qq='1000001qq'
r=re.findall('\d{4,8}$',qq)
# []
r=re.findall('^\d{4,8}',qq)
# ['1000001']
r=re.findall('^\d{4,8}$',qq)
#[]
還記得上面說過的 [ ] 是或關系嗎?下面這個 ( ) 則代表的是且關系,
import re
a='PythonPythonPythonPythonPython'
r=re.findall('(Python){3}',a) # 括號表示一個組
print(r) # ()且關系【】或關系
# ['Python']
四.修飾符(可選標志)
正則運算式可以包含一些可選標志修飾符來控制匹配的模式,修飾符被指定為一個可選的標志,多個標志可以通過按位 OR(|) 它們來指定,
| 修飾符 | 含義 |
|---|---|
| re.I | 匹配忽略大小寫 |
| re.S | 使 . 匹配包括換行在內的所有字符 |
| re.M | 多行匹配,影響 ^ 和 $ |
| re.L | 做本地化識別(locale-aware)匹配 |
| re.U | 根據Unicode字符集決議字符,這個標志影響 \w, \W, \b, \B. |
| re.X | 該標志通過給予你更靈活的格式以便你將正則運算式寫得更易于理解, |
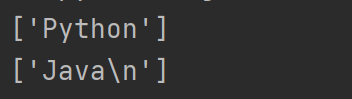
import re
a = 'Python293jddjkJava\n$%'
r=re.findall('python',a,re.I) # 忽略大小寫
print(r)
r=re.findall('java.{1}',a,re.I|re.S) # 且關系
print(r) # 匹配java后的一個字符,包括換行符,
五.re.sub函式
re.sub用于替換字串中的匹配項,
語法:
re.sub(pattern, repl, string, count=0, flags=0)
- pattern : 正則中的模式字串,
- repl : 替換的字串,也可為一個函式,
- string : 要被查找替換的原始字串,
- count : 模式匹配后替換的最大次數,默認 0 表示替換所有的匹配,
- flags : 編譯時用的匹配模式,數字形式,
前三個為必選引數,后兩個為可選引數,
有了例子,好理解:
import re
a = 'Python293jddjkJava$%PythonPython'
r=re.sub('Python', 'C', a)
print(r)
r=re.sub('Python', 'C', a, 1) # 換一次
print(r)

不止可以用字串替換,還可以用函式替換,也就是把這個函式作為引數傳遞,函式的回傳值替換匹配的字串,
import re
a = 'Python293jddjkJava$%PythonPython'
def convert(value):
matched=value.group()
return '!!'+matched+'!!'
r=re.sub( 'Python', convert, a)
print(r)

在這里,再舉一個例子,我們把字串中大于等于6的數都替換成9,小于6的都替換為0.
import re
a = ' A9C123456D78'
# 把函式作為引數傳遞
def convert(value):
matched = value.group() # 拿到具體物件
if int(matched)>=6:
return '9'
else:
return '0'
r=re.sub( '\d', convert, a)
print(r)

六.re.match函式
re.match 嘗試從字串的起始位置匹配一個模式,如果不是起始位置匹配成功的話,match()就回傳none,
import re
a='A83C34D90FE'
r=re.match('\d',a)
print(r)
# 起始位置不是0-9,所以回傳一個None
七.re.search函式
re.search 掃描整個字串并回傳第一個成功的匹配,匹配成功re.search方法回傳一個匹配的物件,否則回傳None,
我們可以使用group(num) 或 groups() 匹配物件函式來獲取匹配運算式,
語法:
re.search(pattern, string, flags=0)
- pattern 匹配的正則運算式
- string 要匹配的字串,
- flags 標志位,用于控制正則運算式的匹配方式,如:是否區分大小寫,多行匹配等等,
import re
a='A83C34D90FE'
r1=re.search('\d',a)
print(r1)
print(r1.group())
print(r1.span()) # 跨度位置
# 匹配一次就停止

group() 中我們也可以一次輸入多個組號,在這種情況下它將回傳一個包含那些組所對應值的元組,
import re
a = 'Asu is a beautiful girl.Haha!'
# 提取Asu girl之間的所有字符
r = re.search('Asu(.*)girl.*', a)
# . 匹配除\n外所有字符
print('r.group():'+r.group())
print('r.group(0):'+r.group(0))
print('r.group(1):'+r.group(1))

import re
a = 'Asu is a beautiful girl.Asu is cute. Asu is lovely.'
r = re.search('Asu(.*)Asu(.*)Asu',a)
print(r.group(0))
print(r.group(1))
print(r.group(2))
print(r.group(0,1,2))
print(r.groups())
r = re.findall('Asu(.*)Asu(.*)Asu',a)
print(r)

這樣我們也可以來看看re.search與re.findall之間的差別:
import re
a = 'Asu is a beautiful girl.Asu is cute. Asu is lovely.'
r = re.search('Asu(.*)Asu(.*)Asu',a)
print(r.group())
r = re.findall('Asu(.*)Asu(.*)Asu',a)
print(r)

re.findall會將中間的字串以元組的方式取出,而對于re.search中的group()則會結合前后的字串一同列印出來,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/276328.html
標籤:python
上一篇:b站直播消費記錄爬取