C語言中的字串與字符集詳解
1. 字符集
2.1. ANSI
ANSI, 是美國國家標準學會頒布的一個字符集標準. 它規定用0x00~0x7f的范圍來表示英文字符,數字字符,標點符號和控制字符, 也就是我們所熟知的ASCII碼. 后來由于需要表示法文, 德文, 西班牙文等有特殊符號的西方文字, 0x80~0xff的范圍也被使用了.
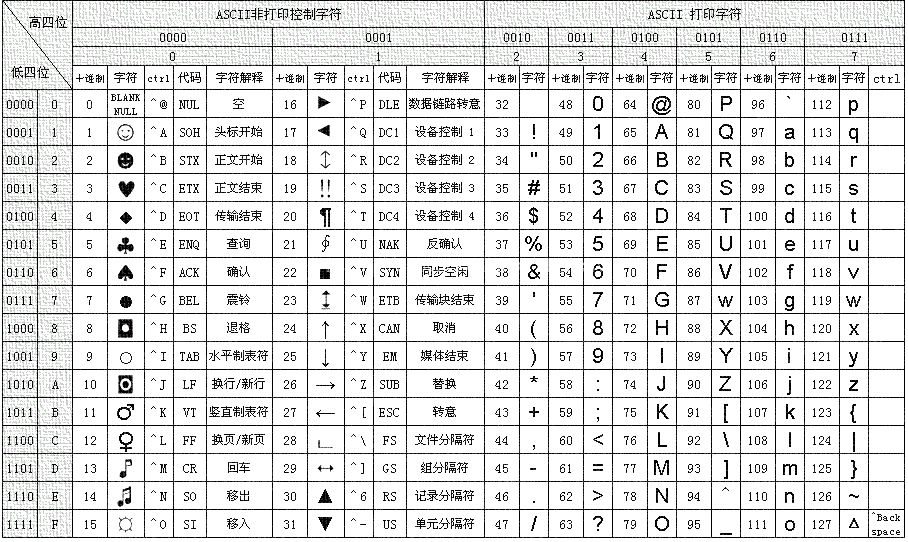
ascii碼表
但不幸的是, 這并沒有從根本上解決問題. 當需要表示中文, 日文和朝鮮文等字符及其之多的語言時, 一個位元組的范圍顯然是不夠的. 于是產生了ANSI擴展編碼, 使用了第二個位元組. 這兩個位元組就可以表示65536個字符. 對于不同的語言, 擴展表的結構都不同(但是0x00~0x7f這個范圍都是相同的), 我們把每種語言自己的ANSI表叫做代碼頁. 例如, 簡體中文的代碼頁就是GB-2312, 繁體中文就是Big5, 日文就是Shift-JIS. 但是問題仍然存在: 由于不同語言的ANSI編碼表不同, 同樣的值在不同的代碼頁中所代表的字符是不一樣的. 例如, '測'在GB-2312中的值是e2b2(注意, 在電腦中存盤方式是小端存盤, 所以你在除錯器中看到的應該是b2 e2), 但e2b2在Big5中表示的卻是'聆'. 這樣就會造成資訊理解的錯誤, 并且無法在同一個檔案中使用多種語言.
ANSI編碼的字符的長度是不固定的. 總體而言, 在任何的代碼頁中, 英語字母和拉丁字母都只占1位元組, 并且編碼與ASCII相同. 但是對于其他字符, 其長度與編碼則因代碼頁而異.
2.2. Unicode
為了根本的解決這個問題, unicode出現了. unicode將地球上所有的文字統一編碼, 沒有重復, 每一個字符都有自己獨一無二的編碼. unicode編碼的范圍為0~10FFFF, 最多需要3個位元組來存盤. Unicode分為17個平面, 每個平面包含65536個字符. 其中第一個平面(0~0xFFFF)稱為“基本多語言平面”, 剩下的16個平面稱為“輔助平面”.
然而, 對于許多的字符來說, 它們的高位都是0, 如果還用3個位元組表示它們, 就會浪費掉很多的記憶體. 為了解決這個問題, 人們研究出來了許多種存盤方式, 主要包括UTF-8, UTF-16, UTF-32, UCS-2以及UCS-4. 總體來說, 這些都只是編碼方式而已, 真正的字符資料都是unicode碼.
2.2.1. UTF-8
utf-8中, 單個字符的長度是變化的. 其存盤方式為:
| 范圍 | 原始值(二進制) | utf-8編碼值(二進制) | 長度(位元組) |
| 0~007F | 00000000 00000000 0aaaaaaa | 0aaaaaaa | 1 |
| 0080~07FF | 00000000 00000bbb bbaaaaaa | 110bbbbb 10aaaaaa | 2 |
| 0800~FFFF | 00000000 ccccbbbb bbaaaaaa | 1110cccc 10bbbbbb 10aaaaaa | 3 |
| 10000~10FFFF | 000dddcc ccccbbbb bbaaaaaa | 11110ddd 10cccccc 10bbbbbb 10aaaaaa | 4 |
舉個例子:

三個字符分別為三個字型, 其字碼都是相同的
字符'??', 其unicode碼為23C55. 要想得到它的utf-8編碼, 需要以下步驟:
1: 0x23C55在0x10000與0x10FFFF之間, 它的結構應該符合上表中的第四行所描述的結構;
2: 將0x23C55轉為二進制, 應為:
00000010 00111100 01010101
3: 按照規則, 進行轉換:
00000010 00111100 01010101
↓ ↓ ↓
11110000 10100011 10110001 10010101
4: 為方便展示, 我們再把它給轉成16進制, 得到F0A3B195. 這就是它的utf-8編碼.
小結: 我們可以發現, 在unicode碼比較小的時候, utf-8編碼可以節省很多記憶體, 但當它變大之后, utf-8編碼反而會增加記憶體的消耗. 同時, 為了方便處理, 計算機中的utf-8編碼的字符全部以大端格式存盤.
2.2.2. UTF-16
utf-16中, 單個字符的長度也是變化的. 其存盤方式為:
| 范圍 | 原始值(二進制) | utf-16編碼值(二進制) | 長度(位元組) |
| 0~D7FF | 00000000 aaaaaaaa aaaaaaaa | aaaaaaaa aaaaaaaa | 2 |
| D800~DFFF (保留) | 00000000 11011xxx xxxxxxxx | 11011xxx xxxxxxxx | (保留) |
| E000~FFFF | 00000000 aaaaaaaa aaaaaaaa | aaaaaaaa aaaaaaaa | 2 |
| 10000~10FFFF | 000aaaaa aaaaaaaa aaaaaaaa | 110110bb bbbbbbbb 110111cc cccccccc | 4 |
當字符的unicode碼在0~FFFF之間時, 它的utf-16編碼長度為兩個位元組, 值就是它的unicode碼的低字(最低的兩個位元組). 其中D800~DFFF區間為保留區間, 沒有定義任何字符.
當字符的unicode碼在10000~10FFFF之間時, 兩個位元組已經不夠存盤它了, 所以它的utf-16編碼長度為四個位元組. 這中情況下, utf-16編碼的取值就要麻煩一點了:
設其unicode碼為X, X的范圍就是[0x10000, 10FFFF]
X' = X - 0x10000 (這樣子的話X'的范圍就是[0, 0xFFFFF], 最少就可以用20個位來表示)
Xh = X' >> 10 + 0xD800 (取X'的高十位, 加上0xD800, 得到其utf-16編碼的高字. 0xD800的二進制為11011000 00000000, 黑色部分長度是十位, 相加后正好可以放下X'的高十位)
Xl = X' & 0x03FF + 0xDC00 (取X'的低十位, 加上0xDC00, 得到其utf-16編碼的低字. 0xDC00的二進制為11011100 00000000, 黑色部分長度是十位, 相加后正好可以放下X'的高十位. 注意, 0xD800與0xDC00只有綠色部分一位的差別)
Xutf16 = Xl + Xh << 16 (高低字拼在一起就行了)
仍然使用字符'??'來舉個例子:
1: 0x23C55在0x10000與0x10FFFF之間, 它的結構應該符合上表中的第四行所描述的結構;
2: 將0x23C55減去0x10000, 得到0x13C55;
3: 為了方便觀察, 把0x13C55轉為2進制:
0001 00111100 01010101
4: 按照規則, 進行轉換:
0001 00111100 01010101
高10位 低10位
0001001111 0001010101
+0xD800 +0xDC00
↓ ↓ ↓
高字 低字
11011000 01001111 11011100 01010101
5: 為方便觀察, 轉成16進制, 得到0xD84FDC55. 這就是它的utf-16編碼. 在計算機中, 兩個字是大端存盤的, 但是每個字中的兩個位元組是小端存盤的. 所以'??'的utf-16編碼在計算機中存盤的形式應該是4FD855DC.
2.2.3 UTF-32
utf-32的單個字符是4個位元組, 這樣就可以存盤下所有的unicode碼. 因此, utf-32的單個字符的長度是固定的, 為4個位元組. 它的值和字符的unicode碼完全相同.
2.2.4. UCS-2
UCS是由ISO(國際標準化組織)指定的, 全稱為Universal Character Set(通用字符集). 后來為了和unicode兼容, UCS的有效編碼范圍也為0~0x10FFFF, 并且編碼值與unicode保持一致. 片面的說, UCS碼和Unicode碼就是一個東西.
UCS-2中, 單個字符的長度是固定的, 都為2位元組. 因此, 它只能表示0~0xFFFF中一共65536個字符. 這個范圍其實是Unicode的“基本多語言平面”, 也就是它包含了大多數常用字符, 一般情況下是夠用了的. 但是如果字符超出了這個范圍(某些“輔助平面”中的特殊字符, 例如本篇文章中一直用來舉例的'??'), 就沒辦法用UCS-2來表示了.
2.2.5. UCS-4
UCS-4和utf-32一樣, 使用4個位元組來存盤. 大體來講, 它和utf-32沒有什么區別, 都是完整地存盤字符的unicode碼.
2. char和wchar_t
char: 字符型別, 大小1位元組.
wchar_t: 寬字符型別, 大小2位元組.
3. 多位元組字串和寬字串
注意: 以下所有示例的運行環境為Windows10, 編譯環境為Visual Studio 2019.
多位元組字串(multi-byte string)是指, 字串中的每一個字符所占用的空間≥1位元組. 具體每個字符占多少空間, 因語言而異. 多位元組字串一般存盤在char*字串里面, 例如:
char* str = "C測";
在執行字符集是utf-8的情況下(命令列中設定"/excution-charset:utf-8"),通過除錯器, 我們可以看到str的內容是:
43 e6 b5 8b
其中43就對應字符'C', 占一個位元組; e6 b5 8b就對應字符'測', 占三個位元組. 由于源代碼編碼是utf-8, "C測"字串本質上是一串utf-8編碼的資料, 因此它也被編譯器以utf-8的編碼保存在了程式中. 在運行的程序中, 它會被以utf-8的編碼形式被加載到記憶體中, 因此我們在除錯器中看到的是它的utf-8形式.
在執行字符集是GB-2312字符集的情況下(命令列中設定"/excution-charset:GB2312"),通過除錯器, 我們可以看到str的內容是:
43 b2 e2
其中43就對應字符'C', 占一個位元組; b2 e2就對應字符'測', 占兩個位元組. 由于源代碼編碼是GB-2312, "C測"字串本質上是一串ANSI編碼的資料, 因此它也被編譯器以ANSI的編碼保存在了程式中. 在運行的程序中, 它會被以ANSI的編碼形式被加載到記憶體中, 因此我們在除錯器中看到的是它的ANSI形式.
小結: 多位元組字串一般用char*進行存盤. 多位元組字串常量的字符集因設定的執行字符集而異, 如果執行字符集為ANSI, 多位元組字串常量的字符集就是ANSI; 如果執行字符集為utf-8, 多位元組字串常量的字符集就是utf-8. 默認情況下, 執行字符集為ANSI.
寬字串(wide-character string)是指, 字串中的每一個字符都是寬字符. 寬字串一般存盤在wchar_t*字串里面, 例如:
wchar_t* str2 = L"??";//注意, 多位元組字串常量的引號前面要加一個L
無論使用什么執行字符集, 通過除錯器, 我們可以看到str的內容都是:
4f d8 55 dc
這正好是'??'的utf-16編碼的小端存盤形式.
小結: 寬字串一般用wchar_t*進行存盤. 寬字串常量的存盤形式與執行字符集無關, 始終為UTF-16LE(LE, little endian, 小端位元組序).
4. 編程實踐
上面講的只是字串的理論知識. 要想在計算機中實作, 還需要一些C語言技術細節的支持. 下面主要介紹C語言中處理字串的編程技術.
4.1. 控制臺輸入與輸出
要想在C語言中使用控制臺輸入和輸出字串(尤其是非英文字串), 可不能只是簡簡單單的使用printf和scanf, 還要進行其他的設定.
4.1.1. setlocale
setlocale是用來設定國家和地區的. 在本篇文章中, 它被用來設定輸入輸出字串時使用的字符集.
char *setlocale(int category, const char *locale);
這是setlocale函式的定義. 需要包含頭檔案locale.h
category: 設定的范圍(如時間格式, 數字格式, 字符集等), 這里為了簡化步驟, 一律使用LC_ALL.
locale: 代表國家和地區的字串
回傳值: 當前的國家和地區
其中locale引數最為重要, 它代表了所要設定的語言字符集. 它的取值可以是下表中的一種
| Language string | Equivalent Locale Name |
|---|---|
american |
en-US |
american english |
en-US |
american-english |
en-US |
australian |
en-AU |
belgian |
nl-BE |
canadian |
en-CA |
chh |
zh-HK |
chi |
zh-SG |
chinese |
zh |
chinese-hongkong |
zh-HK |
chinese-simplified |
zh-CN |
chinese-singapore |
zh-SG |
chinese-traditional |
zh-TW |
dutch-belgian |
nl-BE |
english-american |
en-US |
english-aus |
en-AU |
english-belize |
en-BZ |
english-can |
en-CA |
english-caribbean |
en-029 |
english-ire |
en-IE |
english-jamaica |
en-JM |
english-nz |
en-NZ |
english-south africa |
en-ZA |
english-trinidad y tobago |
en-TT |
english-uk |
en-GB |
english-us |
en-US |
english-usa |
en-US |
french-belgian |
fr-BE |
french-canadian |
fr-CA |
french-luxembourg |
fr-LU |
french-swiss |
fr-CH |
german-austrian |
de-AT |
german-lichtenstein |
de-LI |
german-luxembourg |
de-LU |
german-swiss |
de-CH |
irish-english |
en-IE |
italian-swiss |
it-CH |
norwegian |
no |
norwegian-bokmal |
nb-NO |
norwegian-nynorsk |
nn-NO |
portuguese-brazilian |
pt-BR |
spanish-argentina |
es-AR |
spanish-bolivia |
es-BO |
spanish-chile |
es-CL |
spanish-colombia |
es-CO |
spanish-costa rica |
es-CR |
spanish-dominican republic |
es-DO |
spanish-ecuador |
es-EC |
spanish-el salvador |
es-SV |
spanish-guatemala |
es-GT |
spanish-honduras |
es-HN |
spanish-mexican |
es-MX |
spanish-modern |
es-ES |
spanish-nicaragua |
es-NI |
spanish-panama |
es-PA |
spanish-paraguay |
es-PY |
spanish-peru |
es-PE |
spanish-puerto rico |
es-PR |
spanish-uruguay |
es-UY |
spanish-venezuela |
es-VE |
swedish-finland |
sv-FI |
swiss |
de-CH |
uk |
en-GB |
us |
en-US |
usa |
en-US |
如果要輸出GB2312字符集的中文, 則應在輸入輸出之前執行
setlocale(LC_ALL, "zh-CN");
值得注意的是, 如果要想輸出utf-16字符集的中文寬字串, 也要運行上面的代碼.
如果要UTF-8字符集的文字, 則應在輸入輸出之前執行
setlocale(LC_ALL, "zh-CN.UTF8");
4.1.2. printf, wprintf, scanf, wscanf
這幾個函式大家都應該已經十分熟悉了, 這里就做個總結, 畢竟有的時候它們還是很坑人的.
//以"多位元組字串"的形式輸出str(使用utf-8或者ANSI字符集): printf("%s", str); printf("%hs", str); wprintf(L"%hs", str); //以"寬字串"的形式輸出str(使用utf-16LE字符集): wprintf(L"%s", str); wprintf(L"%ls", str); printf("%ls", str);
scanf也是類似的, 只不過是輸入.
要提醒大家的是, 控制臺并不能輸出所有字符, 例如上文中經常被用來舉例的'??'. 所以建議大家不要在控制臺輸出亂七八糟的文字, 盡量用英文就行了.
4.1.3. 測量單個字符的大小
對于ANSI字符, 直接使用系統提供的mblen函式(需要包含頭檔案stdlib.h), 其定義如下
int mblen(const char *mbstr, size_t count);
mbstr: 被檢測的字符的地址
count: 最多檢測多少位元組 (對于ANSI字符, 一般設定為2)
回傳值: 這個字符的大小(單位:位元組)
對于utf-8字符, 可以使用以下函式
int UTF8size(char* ch) { int mask; int chsize; //mask=10000000B 當mask&*str為假,mask中的1對應的那一位就是0,chsize就代表從左往右第一個0之前有多少個1 for (mask = 0x80, chsize = 0; mask & *ch; mask >>= 1, chsize++); if (!chsize) chsize++;//一個位元組的utf8首位就是0,對應的chsize也會是0,這里予以糾正 return chsize; }
對于utf-16字符, 可以使用以下函式
int UTF16size(wchar_t* ch) { //*ch右移十位,只剩下前6位.如果等于0x36(110110),說明它是utf-16編碼中的高字,進而說明它的長度有4個位元組 if (*ch >> 10 == 0x36) return 4; else return 2; }
參考文獻:
https://www.loc.gov/marc/specifications/speccharucs.html
https://www.cnblogs.com/malecrab/p/5300503.html
https://zhuanlan.zhihu.com/p/106379925
https://baike.baidu.com/item/ANSI/10401940
The Unicode Standard, Version 13.0, http://www.unicode.org/charts/PDF/Unicode-13.0/
https://docs.microsoft.com/zh-cn/cpp/c-runtime-library/reference/setlocale-wsetlocale
https://docs.microsoft.com/zh-cn/cpp/c-runtime-library/language-strings
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/276535.html
標籤:C