結構化爬取網易云資料并且可視化展示
- 專案說明
- 代碼框架
- 第三方庫說明
- 內容爬取說明
- 頁面詳情
- 完整代碼
- 爬取結果
- 內容可視化
專案說明
網易云音樂歌單資料獲取,獲取某一歌曲風格的所有歌單,進入每個歌單獲取歌單名稱、創建者、播放量、頁面鏈接、收藏數、轉發數、評論數、標簽、介紹、收錄歌曲數、部分收錄歌名,并統計播放量前十的歌單,將播放量前十的歌單以及對應的所有資訊進行另外存盤,對其進行可視化展示,
在做這個爬蟲的時候,對于如何翻頁問題和身邊的人進行了探討,有人說用selenium模擬點擊,但是通過觀察網頁,我發現即使是不用模擬點擊翻頁也能歷遍爬完歌單的資訊,接下來我就帶著大家一起如何爬取資料,
代碼框架
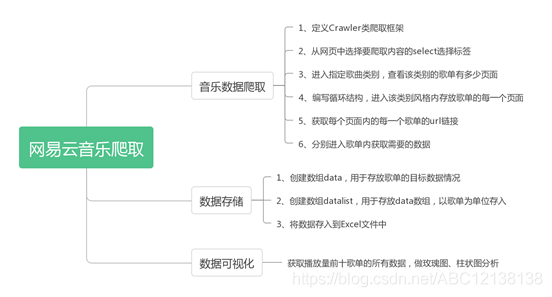
第三方庫說明
在專案中用到的一些第三方庫的介紹:
# bs4
'''
BS4全稱是Beautiful Soup,它提供一些簡單的、
python式的函式用來處理導航、搜索、修改分析樹等功能,
它是一個工具箱,通過決議檔案為Beautiful Soup自動將輸入檔案轉換為
Unicode編碼,輸出檔案轉換為utf-8編碼,
'''
# requests
'''
用requests庫來訪問網頁,獲取網頁內容,支持HTTP特性
'''
# time
'''
Time庫是與時間處理有關的模塊,
在這個專案中是用來強制網頁訪問間隔時間的,
'''
# random
'''
Random庫主要功能是提供亂數,在專案中和time庫配合使用,
生產隨機強制訪問的間隔時間的
'''
# xlwt
'''
Python訪問Excel時的庫,其功能是寫入xls檔案,
在本專案中是用于寫入爬取的資料
'''
# pandas
'''
Pandas庫是基于NumPy的一種工具,用于讀取文本檔案的,
可以快速便捷的處理資料的庫,
'''
# pyecharts.charts
'''
pyecharts.charts是用于資料可視化的庫,其中包含很多種畫圖工具,
在本專案中應用到的是畫柱狀圖是Bar,圓餅圖是Pie
'''
# matplotlib.pyplot
'''
matplotlib也是可視化的庫,由各種可視化的類構成,
matplotlib.pyplot是繪制各類可視化圖形的命令子庫
'''
內容爬取說明
爬取鏈接:https://music.163.com/discover/playlist/?cat=
頁面詳情
觀察網頁內容是我們進行爬蟲專案的首要步驟,這里我選擇了華語型別的歌單來觀察一下;
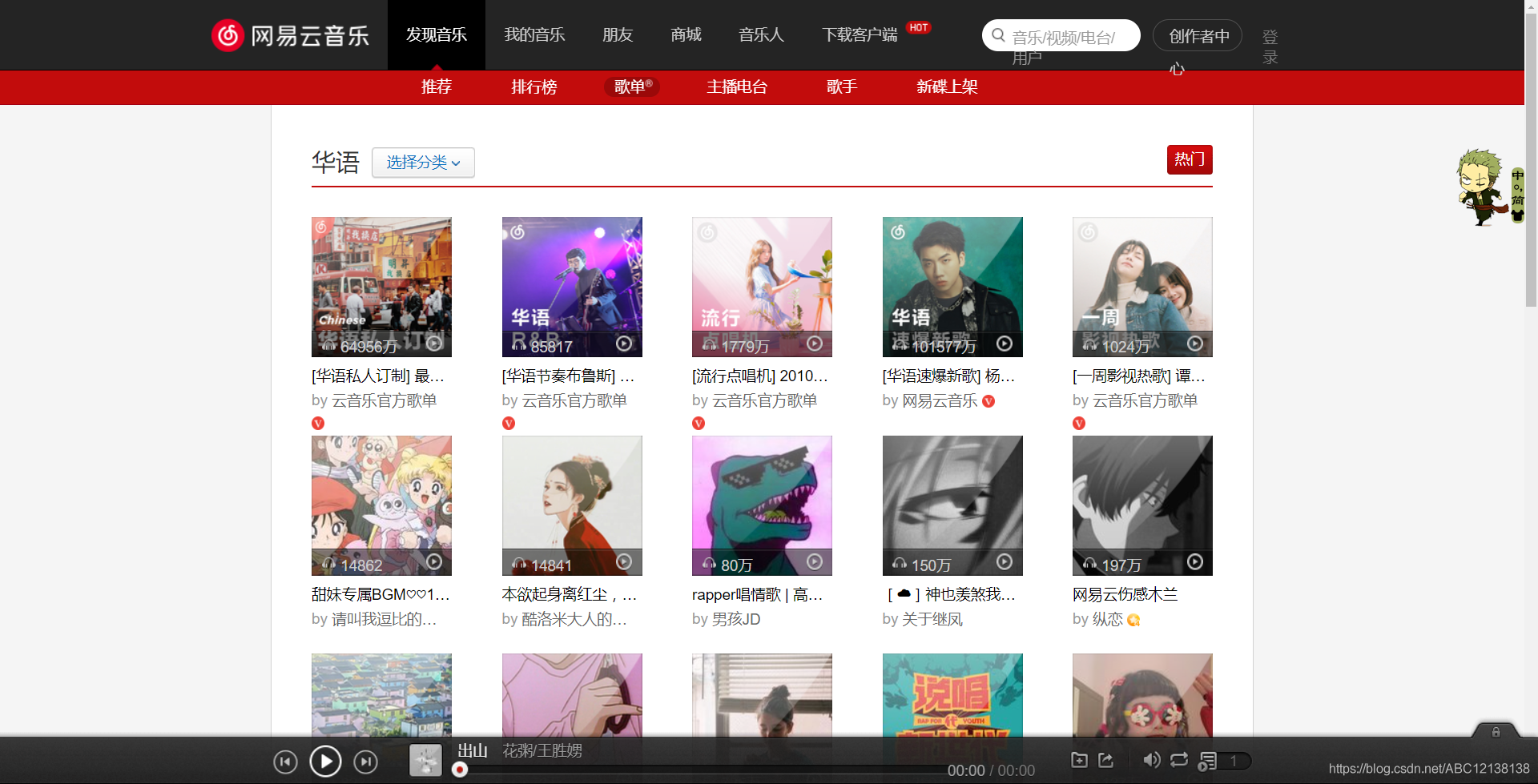
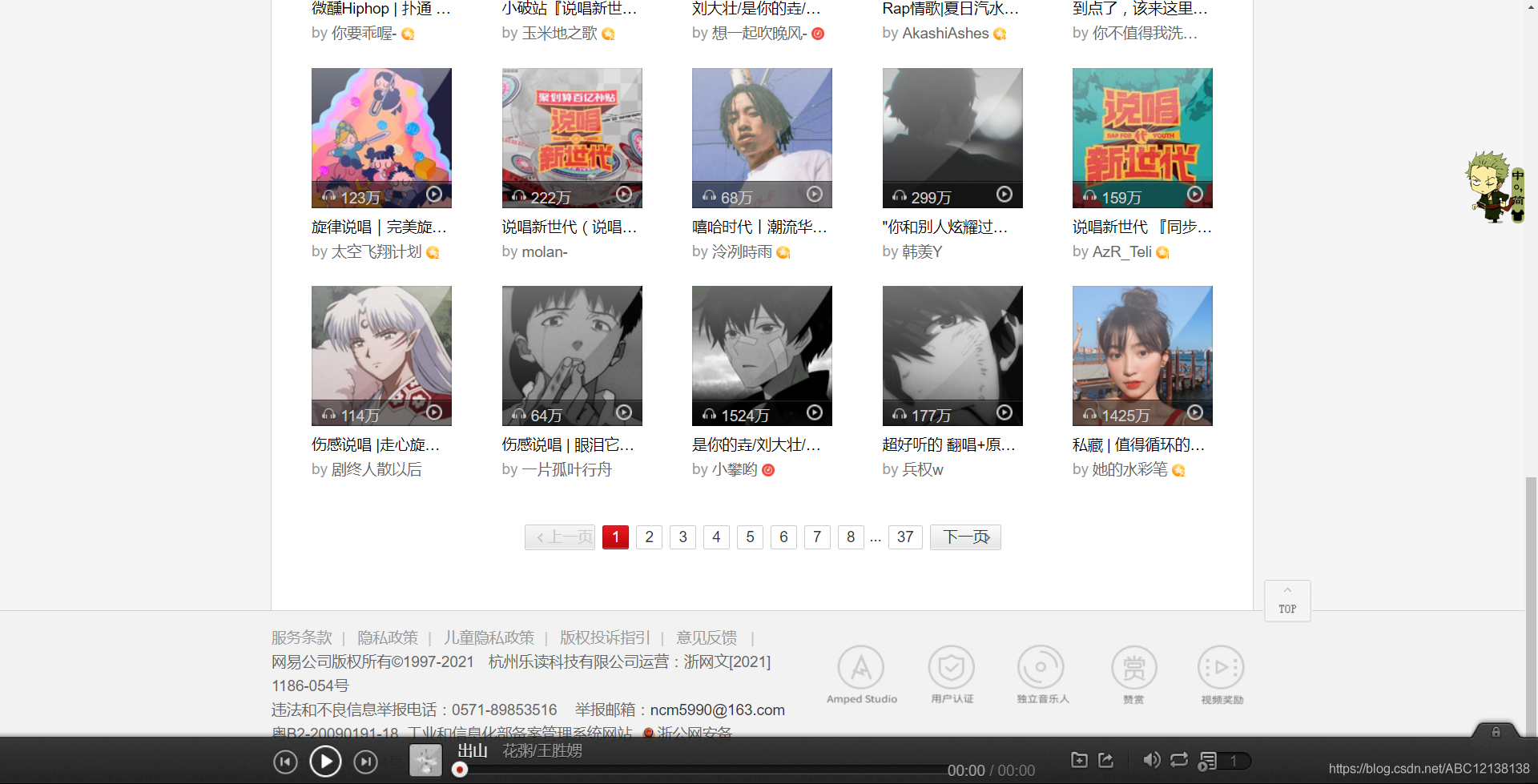
華語風格的歌單總共有37頁,每頁有35個歌單,那總共大約有1295個歌單,一個風格的歌單是代表不了全部的,我們在做爬蟲的時候要避免以偏概全,多看一個頁面,找出規律,這樣才能寫出結構化的爬蟲,當網頁的內容發生變化,但總體框架沒有變化時,我們的代碼就能繼續運行,這也是考驗代碼健壯性的一方面(跑偏了),
在選擇其他歌單類別后,可以看到每個類別的歌單基本都是用37或38個頁面來存放歌單,每個頁面有35個歌單,那如何歷遍每一個頁面呢?
我當時面對這個問題的時候也是想了很久,又不想用selenium模擬點擊,那我們就要多觀察源代碼,看看有沒有蛛絲馬跡,
老規矩 F12 進入開發者選項:
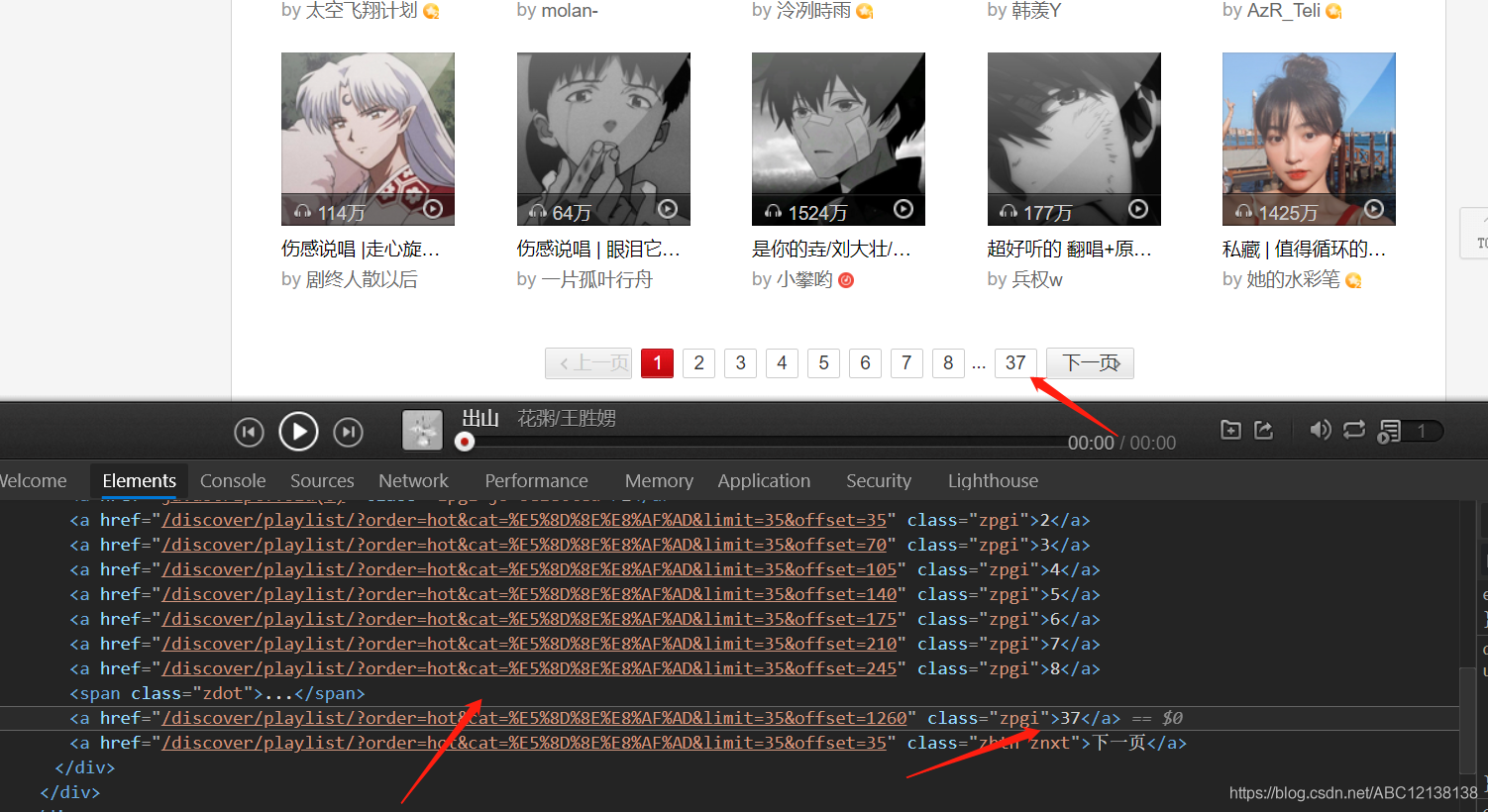
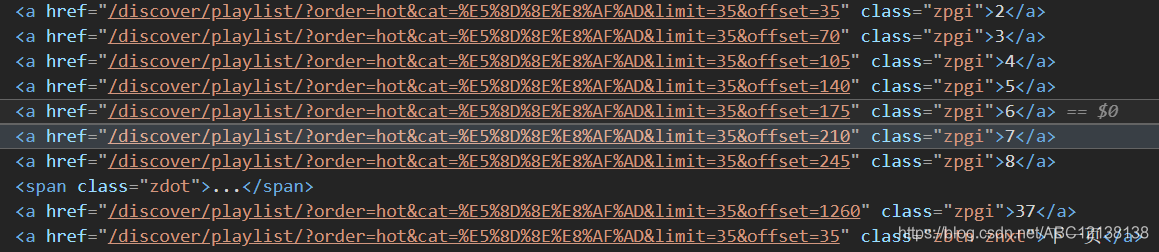
在源代碼中,我們可以看到每個頁面對應的鏈接是有規律的,
例如:“https://music.163.com/#/discover/playlist/?order=hot&cat=%E5%8D%8E%E8%AF%AD&limit=35&offset=35”
通過網頁鏈接觀察,我發現對于網頁翻頁的重點在于“&limit=35&offset=35”的數字35,每個頁面是以鏈接后面的數字決定當前是在第幾個頁面,是以0為首頁面,35為倍數的規律,第一個頁面為 “&limit=0&offset=0”, 第二個頁面為 “&limit=35&offset=35”,第三個頁面為 “&limit=35&offset=70”,以此類推,只要知道當前類別的歌單有多少個頁面,就可以通過for回圈來回圈翻頁,遍歷每一個頁面,
既然我們已經知道了翻頁的規律了,那現在的重點就是獲取歌單的頁數,我們可以在箭頭指引的地方,用開發者選項自帶的復制方式,直接右鍵選擇copy,copy selector直接復制CSS選擇器陳述句;
標簽: #m-pl-pager > div > a:nth-child(11)
#獲取歌單網頁的頁數
result = bs.select('#m-pl-pager > div > a:nth-child(11)')
那接下來就是對單個歌單進行內容爬取了,由于我們爬取的內容較多,所以這里就不一一列舉了,大家可以自行對比參照,不懂可以私信,
獲取歌單名稱
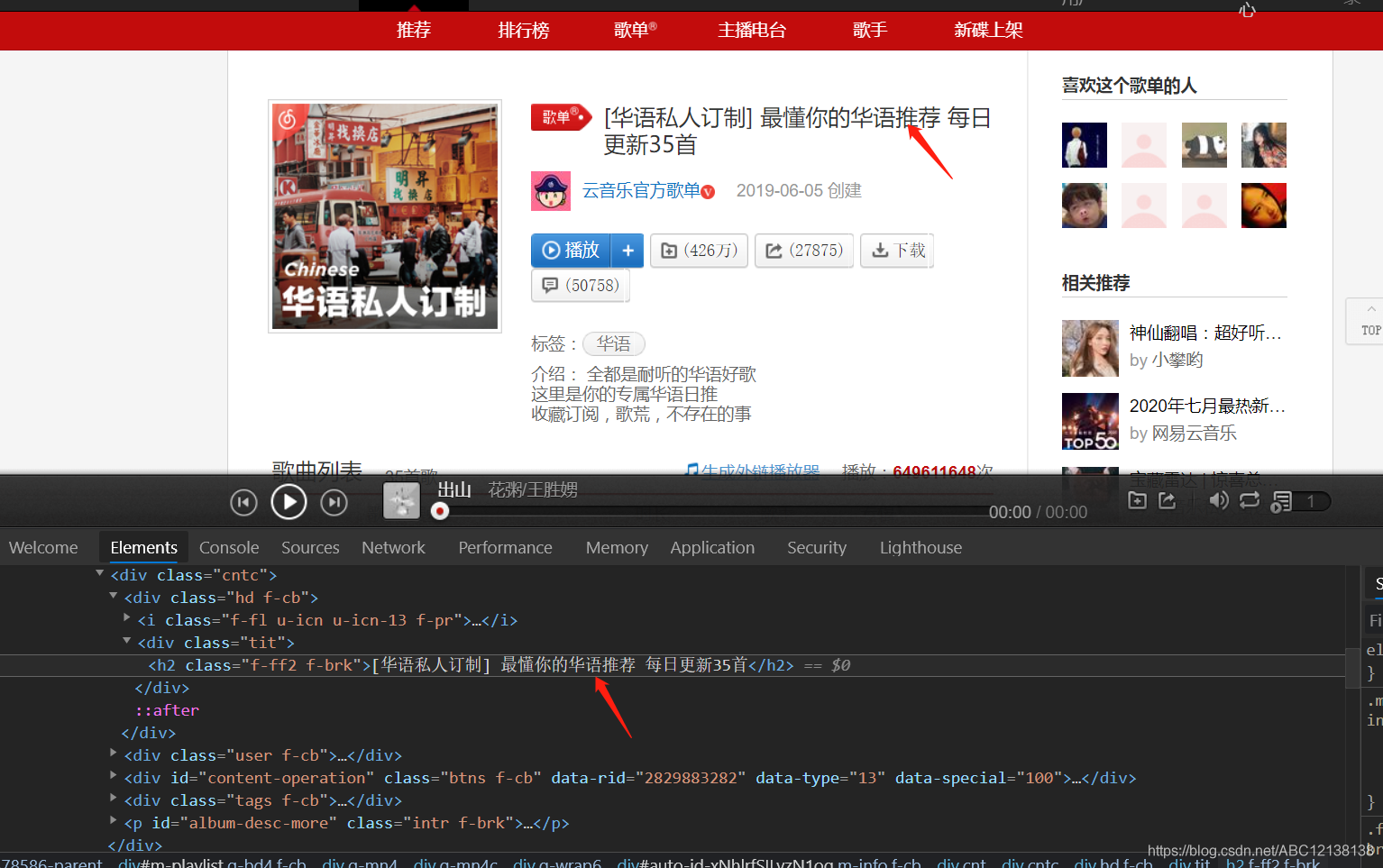
進入每一個頁面,獲取該頁面的每一個歌單,進入單個歌單中,歌單名稱,創建者,播放量等資料都存放在網頁的同一個div內,
id='content-operation'
通過selector選擇器選擇各個內容的,由于是在網易云的網頁版,因此在歌單內的歌曲并沒有顯示所有歌曲,只顯示了10條歌曲,因此在爬取的時候每個歌單只獲取了10條歌曲,如果還想要爬取每天歌曲更多詳細內容,可以進入歌曲的url鏈接,獲取更多的內容,
完整代碼
這里我會定義一個內容類Content 和 網頁資訊類Website,進行結構化爬蟲,如果不是很理解的話,可以看看我之前發過的內容,
爬取三聯生活周刊新聞
Content類和 Website類
class Content:
def __init__(self, url, name, creator, play, collect, transmit, comment, tag,
introduce, sing_num, sing_name):
self.url = url
self.name = name
self.creator = creator
self.play = play
self.collect = collect
self.transmit = transmit
self.comment = comment
self.tag = tag
self.introduce = introduce
self.sing_num = sing_num
self.sing_name = sing_name
def print(self):
print("URL: {}".format(self.url))
print("NAME:{}".format(self.name))
print("CRAETOR:{}".format(self.creator))
print("PLAY:{}".format(self.play))
print("COLLECT:{}".format(self.collect))
print("TRANSMIT:{}".format(self.transmit))
print("COMMENT:{}".format(self.comment))
print("TAG:{}".format(self.tag))
print("INTRODUCE:{}".format(self.introduce))
print("SING_NUM:{}".format(self.sing_num))
print("SING_NAME:{}".format(self.sing_name))
class Website:
def __init__(self, searchUrl, resultUrl, pUrl, absoluterUrl, nameT, creatorT, playT, collectT, transmitT,
commentT, tagT, introduceT, sing_numT, sing_nameT):
self.resultUrl = resultUrl
self.searchUrl = searchUrl
self.absoluterUrl = absoluterUrl
self.pUrl = pUrl
self.nameT = nameT
self.creatorT = creatorT
self.playT = playT
self.collectT = collectT
self.transmitT = transmitT
self.commentT = commentT
self.tagT = tagT
self.introduceT = introduceT
self.sing_numT = sing_numT
self.sing_nameT = sing_nameT
爬取類 Crawler
from bs4 import BeautifulSoup
import re
import requests
import time
import random
import xlwt #進行excel操作
class Crawler:
#爬取網頁函式
def getWeb(self, url):
try: #例外處理
#請求頭
headers_ = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'}
req = requests.get(url, headers = headers_)
req.encoding = "utf-8" #網頁格式化,避免出現亂碼
except requests.exceptions.RequestException:
return None
return BeautifulSoup(req.text, "html.parser")
#爬取所需內容的函式
def getContent(self, pageObj, selector):
childObj = pageObj.select(selector)
# print("\n".join(line.text for line in childObj))
return "\n".join(line.text for line in childObj)
#搜索函式,主函式
def search(self, topic, site):
# 爬取某種風格的歌單有多少頁
newurl = site.searchUrl + topic
newurl = requests.utils.quote(newurl, safe=':/?=&') #對url鏈接上存在的中文字符進行處理
bs = self.getWeb(newurl)
result = bs.select('#m-pl-pager > div > a:nth-child(11)')
num = int("\n".join(link.text for link in result)) #某種風格歌單的頁數
# 翻頁,選取一種歌曲風格,有多個頁面加載歌單,分別讀取
for i in range(0, num+1):
j = 35*i
url = site.searchUrl + topic + '&limit=35&offset=' + str(j) #構造每個頁面的url鏈接
url = requests.utils.quote(url, safe=':/?=&')
bs = self.getWeb(url)
searchResults = bs.select(site.resultUrl)
for link in searchResults:
url = link.attrs["href"]
# 判斷是否為絕對鏈接
if(site.absoluterUrl):
bs = self.getWeb(url)
else:
bs = self.getWeb(site.pUrl + url)
# print(site.pUrl + url)
if(bs is None):
print("something was wrong with that page or URL. Skipping")
return
else:
#爬取歌曲名稱
main = bs.find('ul',{'class':'f-hide'})
sing_name = "\n".join(music.text for music in main.find_all('a'))
# 爬取相關內容
data = [] #申請一個陣列,以歌單為單位,存盤每個歌單里面所需要的內容
url = site.pUrl + url
data.append(url)
# print(data)
# 加入一個引數,判斷目前讀取的資料是字串還是整數
name = self.getContent(bs, site.nameT)
data.append(name)
creator = self.getContent(bs, site.creatorT)
data.append(creator)
play = self.getContent(bs, site.playT)
data.append(play)
collect = self.getContent(bs, site.collectT)
data.append(collect)
transmit = self.getContent(bs, site.transmitT)
data.append(transmit)
comment = self.getContent(bs, site.commentT)
data.append(comment)
tag = self.getContent(bs, site.tagT)
data.append(tag)
introduce = self.getContent(bs, site.introduceT)
data.append(introduce)
sing_num = self.getContent(bs, site.sing_numT)
data.append(sing_num)
# sing_name = self.getContent(bs, site.sing_nameT)
data.append(sing_name)
datalist.append(data) #以歌單為單位存入陣列中
# print(datalist)
content = Content(url, name, creator, play, collect, transmit, comment, tag, introduce, sing_num, sing_name)
# content.print()
# return datalist
#資料寫入檔案
def saveData(self, datalist, savepath):
print("保存到Excel檔案中!")
# xlwt.Workbook用來創建一個作業表,style_compression=0表示是否被壓縮
music = xlwt.Workbook(encoding = 'utf-8', style_compression=0)
# 添加sheet表格,并允許重復修改
sheet = music.add_sheet('網易云音樂資料爬取', cell_overwrite_ok=True)
# 定義列名
col = ("url", "歌單名稱", "創建者", "播放量", "收藏量", "轉發量",
"評論量", "標簽", "介紹", "歌曲數量", "歌曲名稱" )
for i in range(0,11):
sheet.write(0, i, col[i]) #將列名寫進表格
for i in range(0, len(datalist)-1):
# print("第{}行正在寫入".format(i+1))
data = datalist[i]
for j in range(0, 11):
sheet.write(i+1, j, data[j])
music.save('E:/新建檔案夾/Python爬蟲/網易云音樂.xls')
print("資料保存成功!")
crawler = Crawler()
# searchUrl, resultUrl, pUrl, absoluterUrl, nameT, creatorT, playT, collectT, transmitT,
# commentT, tagT, introduceT, sing_numT, sing_nameT
#對應website類的引數,將website定義的引數進行實體化
siteData = [['https://music.163.com/discover/playlist/?cat=', 'a.msk',
'https://music.163.com', False, 'div.tit h2.f-ff2.f-brk', 'span.name a',
'strong#play-count', 'a.u-btni.u-btni-fav i', 'a.u-btni.u-btni-share i',
'#cnt_comment_count', 'div.tags.f-cb a i', 'p#album-desc-more',
'div.u-title.u-title-1.f-cb span.sub.s-fc3', 'span.txt a b']]
sites = []
datalist = []
for row in siteData:
sites.append(Website(row[0], row[1], row[2], row[3], row[4], row[5], row[6], row[7], row[8], row[9], row[10], row[11], row[12], row[13]))
topics = "華語" #選擇自己想要的歌曲風格
time.sleep(random.random()*3)
for targetSite in sites:
crawler.search(topics, targetSite)
savepath = '網易云音樂.xls'
crawler.saveData(datalist, savepath)
爬取結果
爬取的結果

由于資料太多了,這里就只截取了一部分,有興趣可以自己運行一下;
內容可視化
可視化代碼
import pandas as pd
from pyecharts.charts import Pie #畫餅圖
from pyecharts.charts import Bar #畫柱形圖
from pyecharts import options as opts
import matplotlib.pyplot as plt
# 讀入資料,需要更改
#可視化
data = pd.read_excel('網易云音樂.xls')
#根據播放量排序,只取前十個
df = data.sort_values('播放量',ascending=False).head(10)
v = df['歌單名稱'].values.tolist() #tolist()將資料轉換為串列形式
d = df['播放量'].values.tolist()
#設定顏色
color_series = ['#2C6BA0','#2B55A1','#2D3D8E','#44388E','#6A368B'
'#7D3990','#A63F98','#C31C88','#D52178','#D5225B']
# 實體化Pie類
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
# 設定顏色
pie1.set_colors(color_series)
# 添加資料,設定餅圖的半徑,是否展示成南丁格爾圖
pie1.add("", [list(z) for z in zip(v, d)],
radius=["30%", "135%"],
center=["50%", "65%"],
rosetype="area"
)
# 設定全域配置項
# TitleOpts標題配置項
# LegendOpts圖例配置項 is_show是否顯示圖例組件
# ToolboxOpts()工具箱配置項 默認項為顯示工具列組件
pie1.set_global_opts(title_opts=opts.TitleOpts(title='播放量top10歌單'),
legend_opts=opts.LegendOpts(is_show=False),
toolbox_opts=opts.ToolboxOpts())
# 設定系列配置項
# LabelOpts標簽配置項 is_show是否顯示標簽; font_size字體大小;
# position="inside"標簽的位置,文字顯示在圖示里面; font_style文字風格
# font_family文字的字體系列
pie1.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="inside", font_size=12,
formatter="{b}:{c}播放量", font_style="italic",
font_weight="bold", font_family="Microsoft YaHei"
),
)
# 生成html檔案
pie1.render("E:/玫瑰圖.html")
print("玫瑰圖保存成功!")
print("-----"*15)
# print(df['創建者'].values.tolist())
bar = (
Bar()
.add_xaxis([i for i in df['創建者'].values.tolist()])
.add_yaxis('播放量排名前十對應的評論量', df['評論量'].values.tolist())
)
bar.render("E:/條形圖.html")
print("柱形圖保存成功!")
詞云代碼
import wordcloud
import pandas as pd
import numpy as np
data = pd.read_excel('網易云音樂.xls')
#根據播放量排序,只取前十個
data = data.sort_values('播放量',ascending=False).head(10)
print(data["歌單名稱"])
#font_path指明用什么樣的字體風格,這里用的是電腦上都有的微軟雅黑
w1 = wordcloud.WordCloud(width=1000,height=700,
background_color='white',
font_path='msyh.ttc')
txt = "\n".join(i for i in data['歌單名稱'])
w1.generate(txt)
w1.to_file('E:\\詞云.png')`
玫瑰圖

柱形圖
詞云

結束,有興趣的朋友可以來交流一下,這期的內容就到這了,大家晚安,拜拜!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/276634.html
標籤:python
上一篇:18條很棒的python一行代碼