準備資料
2016年北京PM2.5資料集
資料源說明:美國駐華使館的空氣質量檢測資料
資料清洗
1. 匯入資料
用Pandas庫的read_csv()匯入csv檔案
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 匯入2016年北京PM2.5資料集
df = pd.read_csv("Beijing_2016_HourlyPM25_created20170201.csv")
df.head()
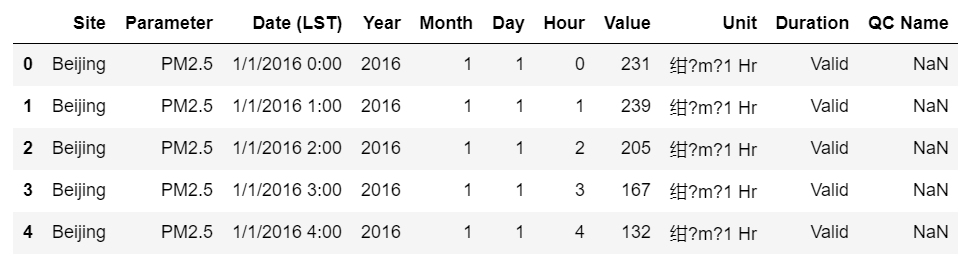
2. 洗掉對資料分析沒有用的列
用Pandas庫的drop()洗掉行或列,axis=0 表示行,axis=1 表示列
df.drop(["Unit","Duration","QC Name"], axis = 1, inplace=True)
df.head()
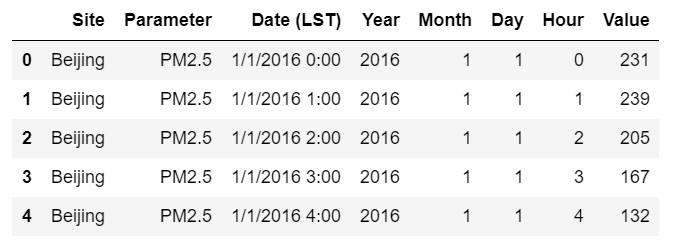
3. 查看資料的簡要資訊
用Pandas庫的describe()來查看資料的簡要資訊,包括了計數,平均值,標準差,最小值,最大值等
df.describe()
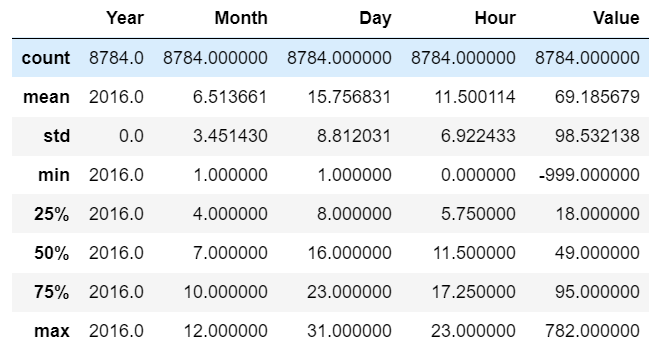
4. 洗掉指定的資料
通過資料的簡要資訊發現PM2.5的值存在負數,而PM2.5的值不能為負數
我們來查看一下PM2.5的值為負數的數量
count = 0
print('PM2.5的值為負數的數量:')
for i in range(df.shape[0]):
if(df.at[i,'Value']<0):
count = count + 1
print(count)

PM2.5的值為負數的資料有45條,而整個資料集的資料有8000多條
洗掉這45條資料對資料分析沒有影響,那怎么洗掉這45條沒用的資料呢
我們要把PM2.5的值為負數的資料變成空值(NaN),再用Pandas庫的dropna()洗掉空值
# 把負數的值變成空值(NaN)
df.loc[df.Value<0,'Value']=np.nan
# 洗掉有空值的資料
df.dropna(inplace=True)
# 此時已經沒有負數的PM2.5值了
df.describe()
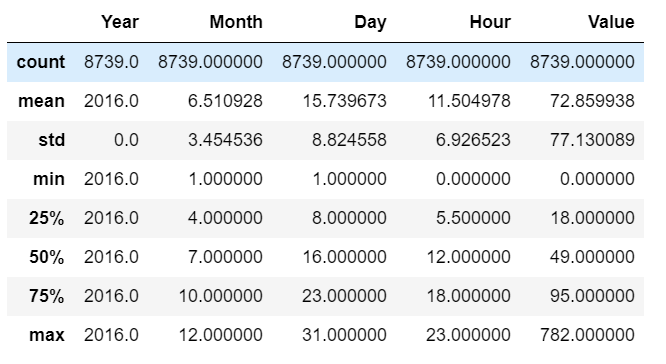
5. 查看是否有空值
用Pandas庫的isnull()來查看是否有空值,value_counts()用來統計個數
df.isnull().value_counts()

6. 查看是否有重復行
用Pandas庫的duplicated()來查看是否有重復行
df.duplicated()
7. 保存資料清洗后的檔案
用Pandas庫的to_csv()保存csv檔案
df.to_csv('Beijing_2016_PM25.csv',encoding='utf-8')
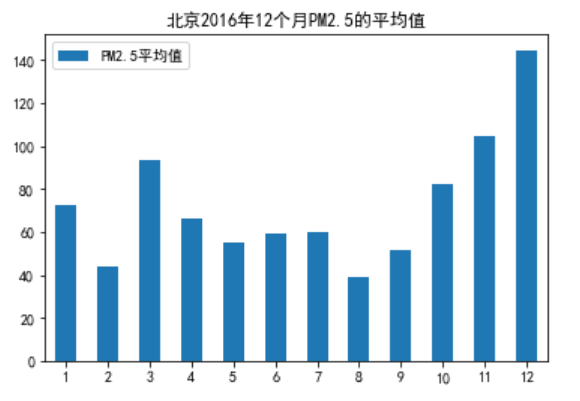
畫圖
匯入資料清洗后的檔案,統計北京2016年12個月PM2.5的平均值
我們用條形圖來表示:
PM25 = pd.read_csv("Beijing_2016_PM25.csv")
month_avg = PM25.groupby(['Month'])['Value'].mean()
PM25_month = pd.DataFrame({'PM2.5平均值':month_avg}, index = np.arange(1,13))
PM25_month.plot(kind='bar',title='北京2016年12個月PM2.5的平均值')
plt.xticks(rotation=360)
plt.show()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/277294.html
標籤:其他
上一篇:Pyinstaller原理詳解