文章目錄
- 簡介
- 面向物件
- 例外處理
- 自定義包/模塊
- 封裝
- 多型
- 執行緒
- 行程
- 多任務
- 迭代器
- 生成器
- 協程
- 并發下載器
- 總結
簡介
- 基礎筆記中介紹了資料型別和檔案操作等基本問題,如果想了解的更深入一些可以看看面試篇
- 進階部分主要包括面向物件思想、例外處理、迭代器、生成器和協程
面向物件
- Python從設計之初就已經是一門面向物件的語言
- 類(class): 用來描述具有相同的屬性和方法的物件的集合,主要有以下概念:
- 方法:類中定義的函式
- 類變數:類變數在整個實體化的物件中是公用的,可理解成static型別
- 區域變數:定義在方法中的變數
- 實體變數:也叫類屬性,即用 self 修飾的變數
- 繼承:即一個派生類(derived class)繼承基類(base class)的屬性和方法
- 方法重寫:如果從父類繼承的方法不能滿足子類的需求,可以對其進行改寫,也叫方法的覆寫(override)
- 物件:類的實體
- 構造方法:
__init__,在類實體化時會自動呼叫的方法
class MyClass: def __init__(self): self.i = 12345 def f(self): # 注意成員函式要加self return self.i # 實體化類 x = MyClass() # 訪問類的屬性和方法 print("MyClass 類的屬性 i 為:", x.i) print("MyClass 類的方法 f 輸出為:", x.f()) - 還是得用起來,可以看一下那個基礎小專案,深入理解這種思想的優勢
例外處理
- 在Python無法正常處理程式時就會發生一個例外,我們需要捕獲處理它,否則程式會終止執行
- 常見的例外處理方法:
- 使用
try/except:檢測try陳述句塊中的錯誤,從而讓except陳述句捕獲例外資訊并處理 - 還可以使用
raise陳述句自己觸發例外 - 可以是python標準例外,也可以繼承并自定義
- 使用
- 參看教程,過一遍即可
- 在我的Python面試篇(一)中也提到了例外的繼承關系
# 一般這么寫 try: fh = open("testfile", "w") fh.write("這是一個測驗檔案,用于測驗例外!!") except IOError: # 這是一個標準例外 print("Error: 沒有找到檔案或讀取檔案失敗") else: print("內容寫入檔案成功") fh.close() # python3中沒有了message屬性,可直接str()或者借用sys的exc_info try: a = 1/0 except Exception as e: # 這個e就是例外提示資訊 exc_type, exc_value, exc_traceback = sys.exc_info() print(str(e)) # division by zero print(exc_value) # division by zero finally: # 無論是否發生例外都將執行最后的代碼 print('over!') # 觸發例外 def func(level): if level < 1: raise Exception("Invalid level!", level) # 都可以輸出,你寫就行 # 觸發例外后,后面的代碼就不會再執行 func() # Exception: ('Invalid level!', 0) # 自定義例外 class Networkerror(RuntimeError): # 繼承RuntimeError def __init__(self, arg): self.args = arg # self.message = arg try: raise Networkerror("Bad hostname") except Networkerror as e: # 這個e就是例外提示資訊 print(e.args) # 也可以輸出 format(e) str(e) - Python3會默認使用Traceback跟蹤例外資訊,從下往上找!
自定義包/模塊
-
大型的程式需要自定義很多的包(模塊),既增強代碼的可讀性,也便于維護
-
使用
import匯入內置或者自定義模塊,相當于includeimport my # 匯入my.py 方式一 from my import test # 匯入里面的一個函式test() 方式二 -
匯入時,系統會從設定的路徑搜索,查看系統包含的路徑:
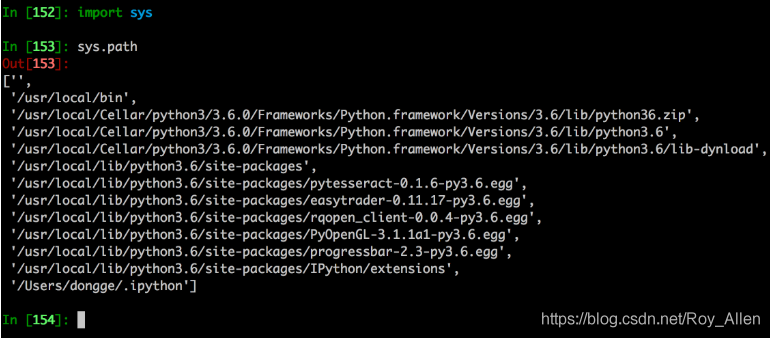
''表示當前路徑
-
當前程式對匯入的模塊會防止重復匯入,即匯入后修改了模塊,無法直接重新匯入
# 需要使用reload模塊重導 from importlib import reload # imp已棄用 reload(module_name) # 查看幫助 help(reload) # The module must have been successfully imported before. -
多模塊開發注意點
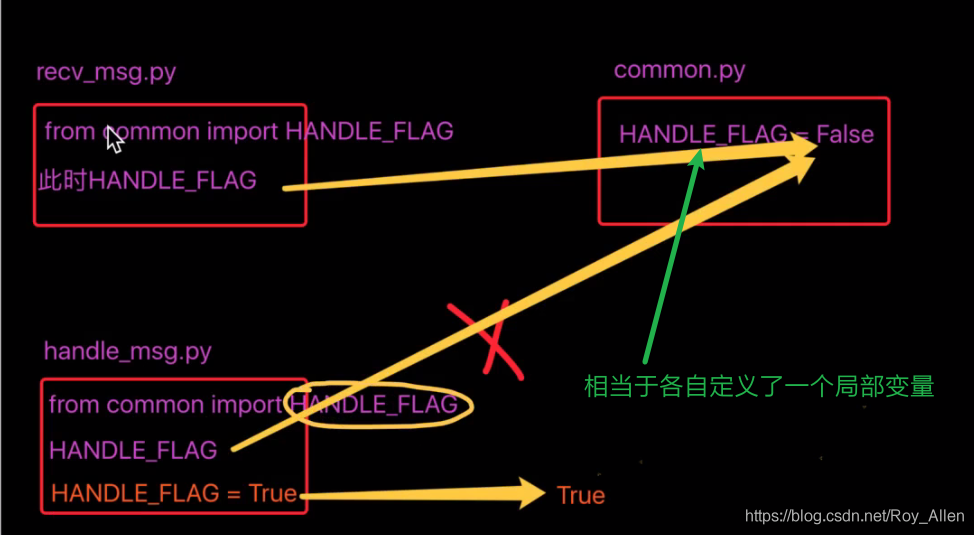
- 匯入方式的不同,決定了變數是全域還是區域
- 如圖所示,指向變了:
- 如果匯入的是串列,使用
append()方法追加,不會重新定義變數 - 如果直接讓HADNLE_FLAG = xxx,相當于新定義變數,并未改變common中的list值
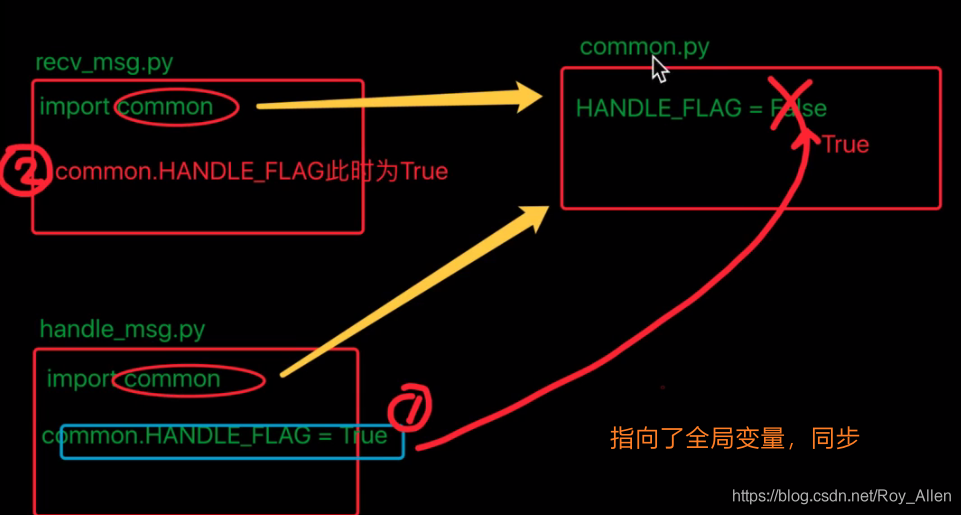
- 因此,只能按第一種方式匯入使用:
-
需要注意:
__name__屬性
# 如果我們想在模塊被引入時,模塊中的某一程式塊不執行,我們可以用__name__屬性 # 使該程式塊僅在該模塊自身運行時執行 # Filename: using_name.py if __name__ == '__main__': print('程式自身在運行%s'%__name__) else: print('我來自另一模塊%s'%__name__)$ python using_name.py 程式自身在運行__main__ # 顯示主模塊 $ python >>> import using_name 我來自另一模塊using_name # 顯示檔案名
封裝
- 封裝、繼承、多型是面向物件(類)的三大特性
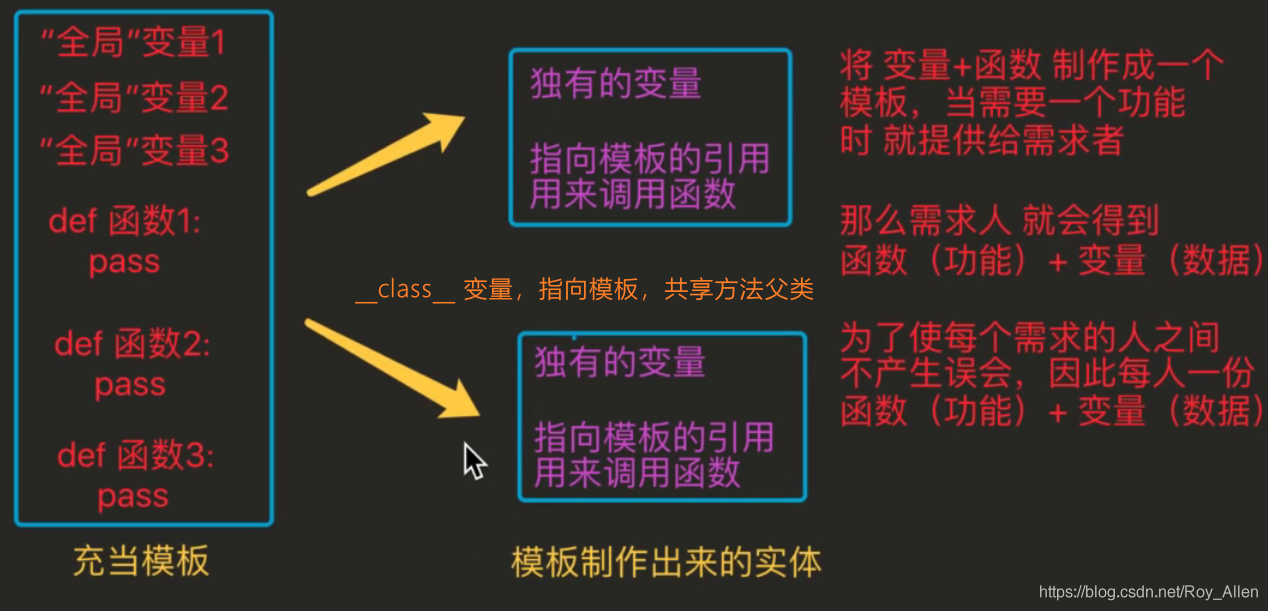
- 如圖,
__class__屬性等價于子類可以呼叫父類的函式(類比C++)
多型
-
類比C++
- 虛函式重寫:
virtual void func(int a){},特點是先不編譯,不確定是哪個類呼叫的 - 在全域函式定義中傳入父類指標,利用父類指標可以指向子類物件的特性,當傳入子類物件時(已經確定是子類物件),通過子類VPTR呼叫子類虛函式表(動態聯編)執行子類的重寫方法
- 詳見我的C++筆記
- 虛函式重寫:
-
在Python中類似,看個例子
# python中繼承就寫在括號里 class MiniOS(object): # 所有類的基類 """MiniOS 作業系統類 """ def __init__(self, name): # 建構式 self.name = name self.apps = [] # 安裝的應用程式名稱串列 list() def __str__(self): # __xxx__(self) 叫魔法方法 """回傳一個物件的描述資訊,print物件時使用""" return "%s 安裝的軟體串列為 %s" % (self.name, str(self.apps)) def install_app(self, app): # 傳入父類指標 # 判斷是否已經安裝了軟體 if app.name in self.apps: print("已經安裝了 %s,無需再次安裝" % app.name) else: app.install() self.apps.append(app.name) class App(object): def __init__(self, name, version, desc): self.name = name self.version = version self.desc = desc def __str__(self): return "%s 的當前版本是 %s - %s" % (self.name, self.version, self.desc) def install(self): # 相當于虛函式 print("將 %s [%s] 的執行程式復制到程式目錄..." % (self.name, self.version)) class PyCharm(App): # 子類繼承App pass # 同一作用域叫多載 class Chrome(App): def install(self): # 相當于虛函式重寫; 類中的普通函式叫重定義 print("正在解壓縮安裝程式...") super().install() # 要通過super呼叫,而不是直接用 linux = MiniOS("Linux") print(linux) pycharm = PyCharm("PyCharm", "1.0", "python 開發的 IDE 環境") chrome = Chrome("Chrome", "2.0", "谷歌瀏覽器") # 傳入子類物件 linux.install_app(pycharm) # 相當于全域函式,傳入哪個子類執行哪個子類的虛方法 linux.install_app(chrome) linux.install_app(chrome) print(linux) # Linux 安裝的軟體串列為 ['PyCharm', 'Chrome'] -
仔細體會!
執行緒
- 使用
threading創建子執行緒import threading import time def func1(num1): for i in range(18): print(num1) time.sleep(0.1) def func3(str): for i in range(18): print(str) time.sleep(0.1) def func2(): for i in range(20): print('主執行緒',i) time.sleep(0.1) if __name__ == '__main__': thread = threading.Thread(target=func1, args=(555,)) # 串列引數 thread2 = threading.Thread(target=func3, kwargs={'str':'roy'}) # 關鍵字引數 thread.start() thread2.start() func2() # 主執行緒一般放在后面,不然會先執行完主行程 - 主執行緒一般會等待子執行緒結束再退出
- 可以通過設定守護執行緒,主執行緒結束即全部退出
if __name__ == '__main__': thread = threading.Thread(target=func1, args=(555,)) # 元祖形式傳參 thread2 = threading.Thread(target=func3, kwargs={'str':'roy'})# 字典形式 # 守護行程 thread.setDaemon(True) thread.start() # 必須都設定守護執行緒才會在主執行緒結束時退出 thread2.setDaemon(True) thread2.start() func2() - 互斥鎖——執行緒同步
# 多個執行緒之間同時操作全域變數就會出問題,需要上鎖 lock = threading.Lock() # 互斥鎖 arr = 0 def lockfunc1(): lock.acquire() # 鎖住 global arr # 需要拿到全域變數arr for i in range(500): arr += 1 print('行程1:',arr) lock.release() # 釋放鎖 def lockfunc2(): lock.acquire() global arr for i in range(400): arr += 1 print('行程2:',arr) lock.release()
行程
- 每創建一個行程作業系統都會分配運行資源,真正干活的是執行緒,每個行程會默認創建一個執行緒
- 多行程可以是多個CPU核,但一般指的是單核CPU并發,而多執行緒是在一個核里進行資源調度,可以結合并行并發的概念理解
import multiprocessing def func1(num1): for i in range(18): print(num1) time.sleep(0.1) def func2(str): for i in range(18): print(str) time.sleep(0.1) if __name__ == '__main__': multi1 = multiprocessing.Process(target=func1) multi2 = multiprocessing.Process(target=func2)# 每個行程自帶一個執行緒 multi1.start() multi2.start() - 類似的可以使用守護行程退出子行程
- 守護行程是一種特殊的后臺行程,子行程以守護行程啟動,那么就會看主行程眼色行事,懂了沒有!
- 一般守護行程會在系統開機時創建,關機時才會退出,默默監視…
- 也可以使用
Precess.terminate()終止 - 行程之間是獨立的(資源分配的基本單位),不共享全域變數
- 那么行程之間如何通信呢?訊息佇列
queue = multiprocessing.Queue(3) # 默認可以存任意多資料- 當然,還有共享記憶體、管道等,可以看我的作業系統筆記
- 個人感覺這個小哥總結的很好,推薦!
多任務
- 了解了行程和執行緒,但在python中還有個特色:協程
- 面試可能會問到三個問題:迭代器是什么?生成器是什么?協程是什么?
迭代器
-
Python三君子:迭代器、生成器、裝飾器
-
迭代器一般用在可迭代物件,包括:串列、字典、元祖、集合,一般用在for回圈中
# 判斷是否可迭代 from collections import Iterable # 使用函式:只要可以迭代,就一定能溯源到Iterable isinstance([], Iterable) # isinstance:是不是一個示例,即前面的屬不屬于后面的 isinstance(a,A) # 物件a是不是類A的實體- 首先判斷物件是否可迭代:看有無
__iter__方法 - 然后呼叫
iter()函式:自動呼叫上述魔法方法,回傳迭代器(物件) - 通過呼叫
next()函式,不斷呼叫可迭代物件的__next__方法,獲取物件的下一個迭代值
- 首先判斷物件是否可迭代:看有無
-
迭代器還應用在類中,怎么讓類成為可迭代物件呢?
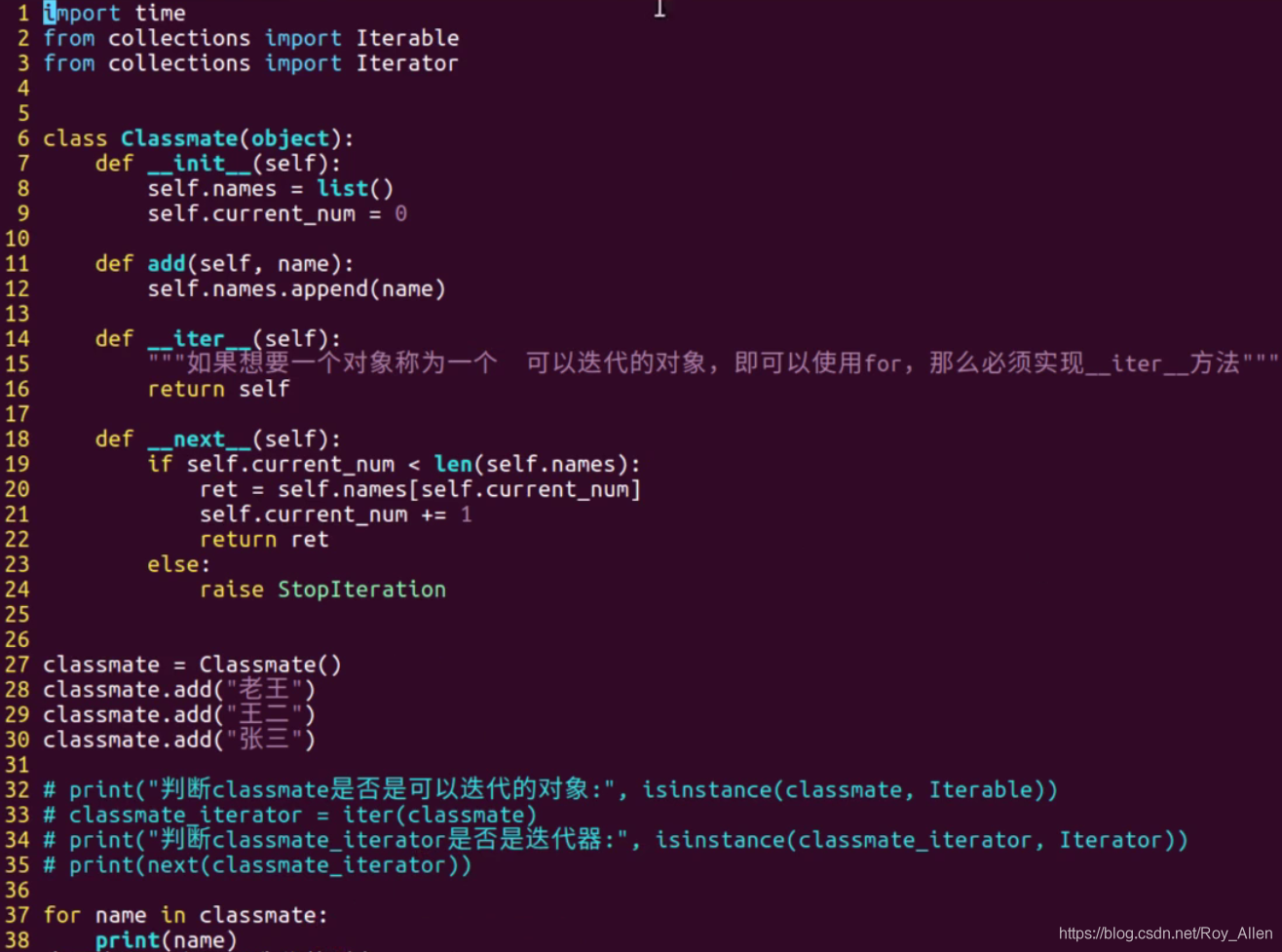
- 直接在類中實作
__iter__和__next__方法 - 通過for回圈呼叫next方法
- 直接在類中實作
-
也可以將類本身作為迭代器回傳
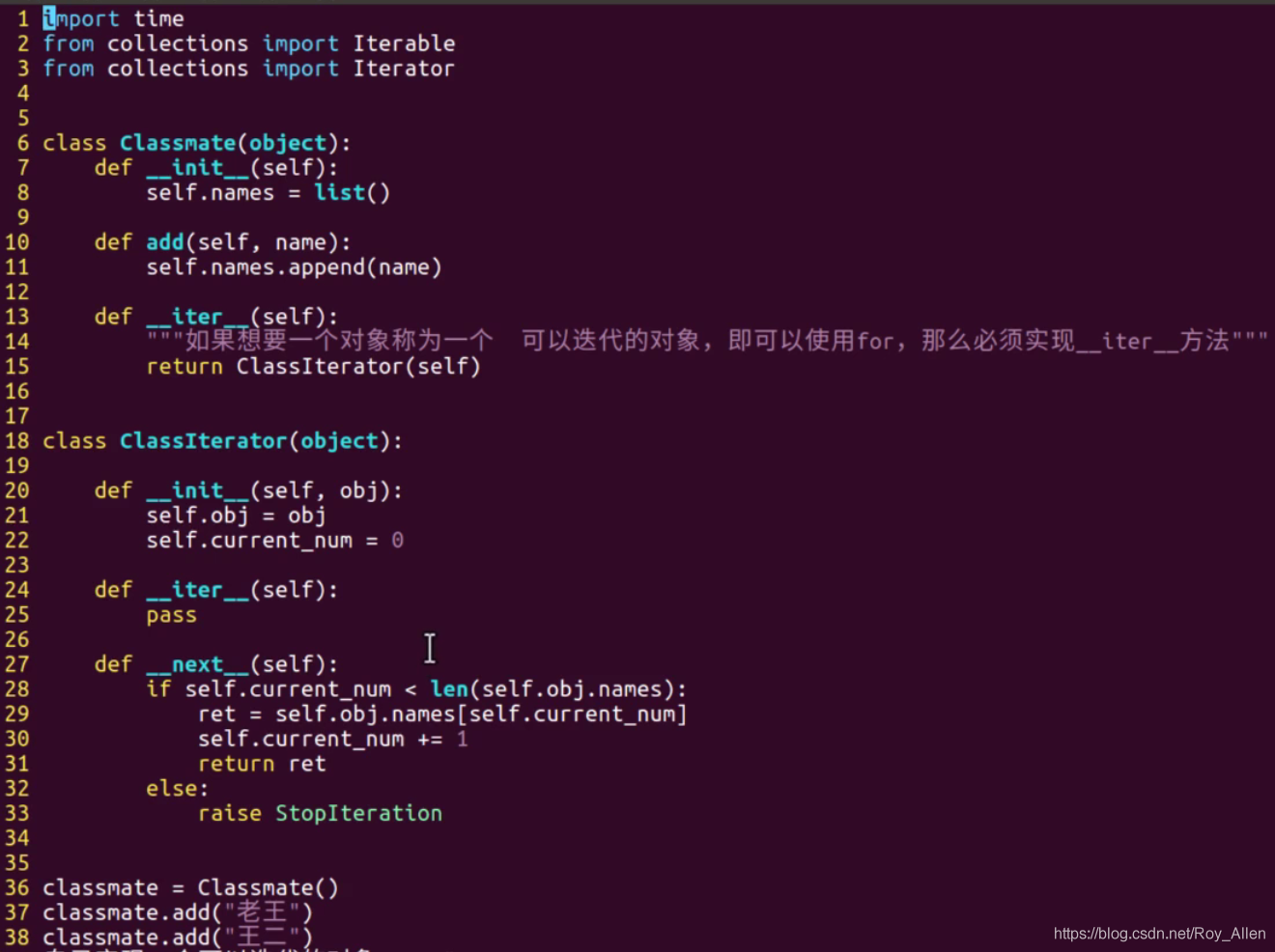
- 上面自定義個類Classmate,先實作
__iter__方法,讓它是一個可迭代物件,同時回傳ClassIterator迭代器 - 迭代器必須也是可迭代物件,所以也得實作
__iter__方法 - 同理,當實體化類后,呼叫
next方法即可獲得ret值 - 也說明:迭代器一定可迭代,可迭代的不一定是迭代器(得看有沒有
__next__方法)
- 上面自定義個類Classmate,先實作
-
下面這個例子也說明了迭代器原理:
class MyIterator: def __iter__(self): # 回傳迭代器物件(初始化) self.a = 1 # 標記迭代位置 return self def __next__(self): # 回傳下一個物件 x = self.a self.a += 1 # 可以發現,這里是得到下一個值的方法 return x myclass = MyIterator() myiter = iter(myclass) # 得到迭代器 print(next(myiter)) # 1 print(next(myiter)) # 2 print(next(myiter)) # 3 print(next(myiter)) # 4 print(next(myiter)) # 5- 這里還呼叫了
iter()方法,這和定義相關,因為要初始化self.a,所以這不是必須的 - 重點是:迭代器回傳的是得到資料的方式,可以節省記憶體
- 這里還呼叫了
-
例如:range()和==xrange()==的區別
# 在python2中 range(100) # 回傳0到99的串列,占用較多記憶體 xrange(100) # 回傳生成資料的方式 # 在py3中range()相當于xrange() range() -
實際應用一下,徹底接受迭代器:
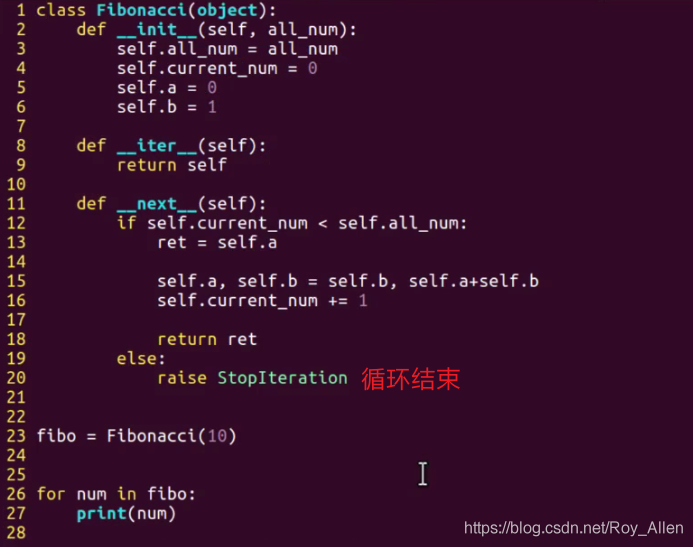
- 使用迭代器的形式得到斐波那契數列
- 你不會不知道吧?0、1、1、2、3、5、8、13、21、34…叫Fibonacci sequence
- 重點是:使用for回圈的形式默認呼叫next方法;這也是前面為什么說應用在for回圈中
- 還有Python中這個swap的寫法,很常見,記一下!
- 使用迭代器的形式得到斐波那契數列
-
當然,不止for回圈可以接收迭代物件,型別轉換本質也是迭代器
li = list(FibIterator(15)) print(li) tp = tuple(FibIterator(6)) print(tp) -
迭代器是什么?
- 迭代器支持next()方法獲取可迭代物件下一個值
- 一般應用在for回圈和類中,本質是實作了iter和next魔法方法
- 迭代器通過給出資料生成的方式,節省程式運行時資料對記憶體空間的占用
生成器
-
在實作一個迭代器時,需要我們手動回傳,并實作next方法,進而生成下一個資料
-
可以采用更簡便的生成器語法,即生成器(generator)是一類特殊的迭代器
-
方式一:
L = [ x*2 for x in range(5)] # [0, 2, 4, 6, 8] G = ( x*2 for x in range(5)) # <generator object <genexpr> at ... # 區別僅在于外層的(),可以按照迭代器的使用方法來使用 next(G) # 0 G此時就是一個迭代器 next(G) # 1 next(G) # 2- 只要是迭代器,就可以用next()來發動
-
方式二:
- 使用
yield關鍵字創建生成器,特點是執行到yield即回傳后面的值 - 下次迭代可以接著執行,即特殊的流程控制
- 看個例子:還是得到斐波那契數列
def create_num(all_num): print('------1------') a, b = 0, 1 cur = 0 while(cur<all_num): print('------2------') yield a # 回傳a print('回傳接著執行') a, b = b, a+b cur += 1 if __name__ == '__main__': obj = create_num(5) for num in obj: print(num)- 可以發現,相比直接用迭代器實作,這里省去了
return和__next__方法 - yield直接回傳后面的資料,并且能在此次回圈后回來,接著向下執行
- 使用
-
常用在爬蟲中資料處理的流程控制:

- 如圖,使用css選擇器獲取所有網頁鏈接后(urls),需要對每個鏈接發起請求爬取原始碼
- 使用yield,到此處時把Request的執行回傳給呼叫parse函式的物件,此物件回圈(next),yield回來繼續回圈
- 當然,爬蟲框架可以將此行為做成異步執行,無需阻塞等待(或者說回傳的是個函式,你那邊處理)
- 在深度學習訓練中,我們需要分批次喂入資料,就可以使用yield;每次獲取一批資料,回傳給模型,模型呼叫next()方法 / 回圈獲取下一批資料
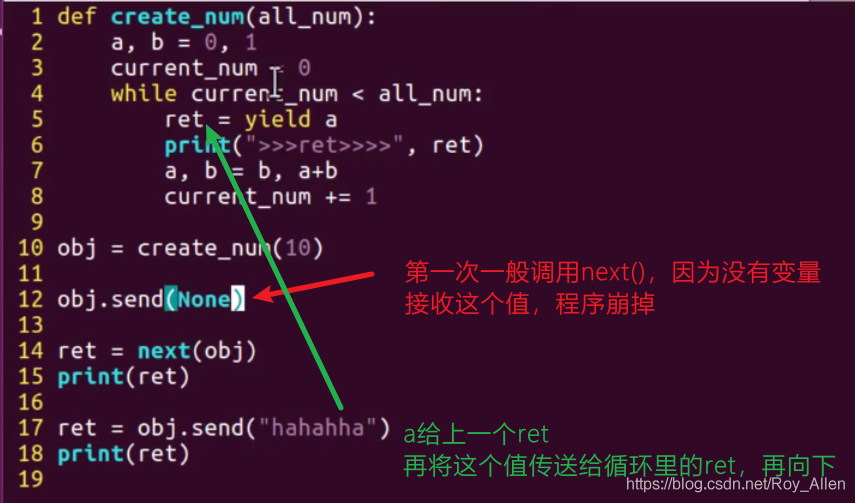
-
使用
send()代替next()喚醒,區別是可以傳參
-
現在,終于可以回到這個大標題:多任務
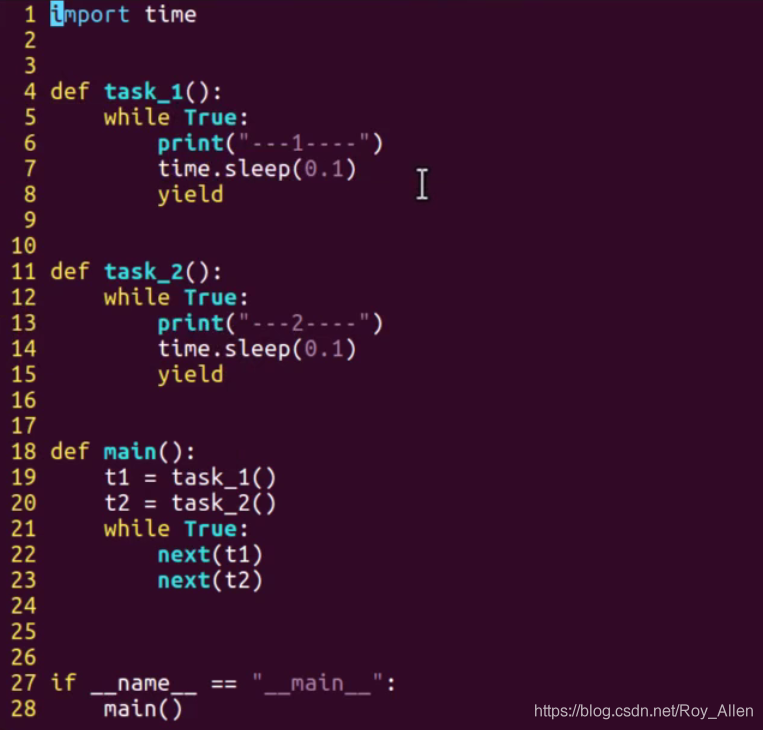
- 生成器實作交替任務,即簡單協程
-
什么是生成器?
- 生成器是一類特殊的迭代器
- 一般使用yield創建生成器,包含yield關鍵字的函式叫做生成器函式
- 特點是執行到yield即回傳后面的值,可以跟函式
- 因為回傳后可以接著執行,所以是一種特殊的流程控制,一般應用在爬蟲、深度學習訓練中
- 多個函式間使用yield相當于函式間切換,這也是協程的基本原理
-
注:迭代器和生成器的迭代只能往后不能往前
協程
-
實作簡單協程代碼
import time def work1(): while True: print("----work1---") yield time.sleep(0.5) def work2(): while True: print("----work2---") yield time.sleep(0.5) def main(): w1 = work1() w2 = work2() while True: next(w1) next(w2) if __name__ == "__main__": main() -
什么是協程:協程是python個中另外一種實作多任務的方式,只不過比執行緒更小占用更小執行單元
-
它自帶CPU背景關系,這樣只要在合適的時機, 我們可以把一個協程切換到另一個協程;
-
與執行緒的區別:
- 在實作多任務時,作業系統為了程式運行的高效性每個執行緒都有自己快取Cache等等資料
- 作業系統還會幫你做這些資料的恢復操作,所以執行緒的切換比較耗性能
- 但是協程的切換只是單純的操作CPU的背景關系,所以可以一秒鐘切換個上百萬次系統
- CPU背景關系是CPU暫存器和程式計數器PC,是在運行任何任務前,必須的依賴環境
- 即:協程輕裝上陣,扔掉多余的狀態,相當于只進行程式中函式間的切換,自帶邏輯,資料從別處拿,執行完回傳結果,結束!
-
為了更好使用協程來完成多任務,python中的
greenlet模塊對其封裝# sudo pip3 install greenlet # pip 就安裝到Python2上去了 from greenlet import greenlet import time def test1(): while True: print "---A--" gr2.switch() time.sleep(0.5) def test2(): while True: print "---B--" gr1.switch() time.sleep(0.5) gr1 = greenlet(test1) gr2 = greenlet(test2) #切換到gr1中運行 gr1.switch() # 這個函式對yield封裝 # 實際上這是假的多任務,完全交替執行 -
更常用的是
gevent- 安裝
pip3 --default-timeout=100 install gevent http://pypi.douban.com/simple/ --trusted-host pypi.douban.com - 或者使用
http://mirrors.aliyun.com/pypi/simple/ - 但是報錯,還是使用
sudo pip3 install gevent,慢一點 - 可以用
pip3 list查看已安裝庫
# 拿著greenlet進一步封裝 import gevent def f(n): for i in range(n): print(gevent.getcurrent(), i) g1 = gevent.spawn(f, 5) g2 = gevent.spawn(f, 5) g3 = gevent.spawn(f, 5) g1.join() g2.join() g3.join() # 運行發現是依次運行 - 安裝
-
多任務:在單核中各任務并發交替執行
import gevent def f1(n): for i in range(n): print(gevent.getcurrent(), i) #用來模擬一個耗時操作,注意不是time模塊中的sleep gevent.sleep(1) # 都要使用gevent里面的模塊 def f2(n): for i in range(n): print(gevent.getcurrent(), i) gevent.sleep(1) # 碰到耗時操作就切換 def f3(n): for i in range(n): print(gevent.getcurrent(), i) gevent.sleep(1) g1 = gevent.spawn(f1, 5) # 創建一個協程 g2 = gevent.spawn(f2, 5) # 目標函式,引數 g3 = gevent.spawn(f3, 5) g1.join() # join會阻塞耗時 g2.join() # 加入并執行 g3.join() # 會等待所有函式執行完畢 # 相當于在函式之間切換,即所謂的自帶CPU背景關系,節省資源 -
執行緒依賴于行程,協程依賴于執行緒;協程最小
from gevent import monkey # 補丁,自動轉換time等為gevent import gevent import random import time def coroutine_work(coroutine_name): for i in range(10): print(coroutine_name, i) time.sleep(random.random()) gevent.joinall([ gevent.spawn(coroutine_work, "work1"), gevent.spawn(coroutine_work, "work2") ]) -
協程是什么?
- 協程相當于微執行緒
- GIL鎖和執行緒間切換耗費資源較多
- 而協程自帶CPU背景關系,可以依賴于一個執行緒,實作協程間的切換,速度更快、代價更小
- 相當于程式函式間的切換
并發下載器
- 使用協程實作一個圖片下載器
from gevent import monkey # 即運行時替換,python動態性的體現! import gevent import urllib.request import random # 有耗時操作時需要 monkey.patch_all() def my_downLoad(url): print('GET: %s' % url) resp = urllib.request.urlopen(url) # file_name = random.randint(0,100) data = resp.read() with open(file_name, "wb") as f: f.write(data) def main(): gevent.joinall([ gevent.spawn(my_downLoad, "1.jpg", 'https://rpic.douyucdn.cn/live-cover/appCovers/2021/01/10/9315811_20210110043221_small.jpg'), gevent.spawn(my_downLoad, "2.jpg", 'https://rpic.douyucdn.cn/live-cover/appCovers/2021/01/04/9361042_20210104170409_small.jpg'), gevent.spawn(my_downLoad, "3.jpg", 'https://rpic.douyucdn.cn/live-cover/roomCover/2020/12/01/5437366001ecb82edfe1e098d28ebc36_big.png'), ]) if __name__ == "__main__": main()
總結
- 行程是資源分配的單位,行程之間獨立所以穩定,但切換需要的資源很最大,效率很低
- 執行緒是CPU調度的基本單位,執行緒切換需要的資源量一般,效率一般(不考慮GIL的情況下)
- 協程切換消耗資源很小,效率高,有較多網路請求(較多阻塞)時使用,可以理解為是執行緒的增強
- 多行程、多執行緒根據CPU核數不一樣可能是并行的,即一個行程的各執行緒可以利用多核并行;但是協程是在一個執行緒中,所以是并發
- 下一篇介紹python高級操作

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/277333.html
標籤:python
上一篇:淺談Python基本資料型別