一、RocketMQ集群
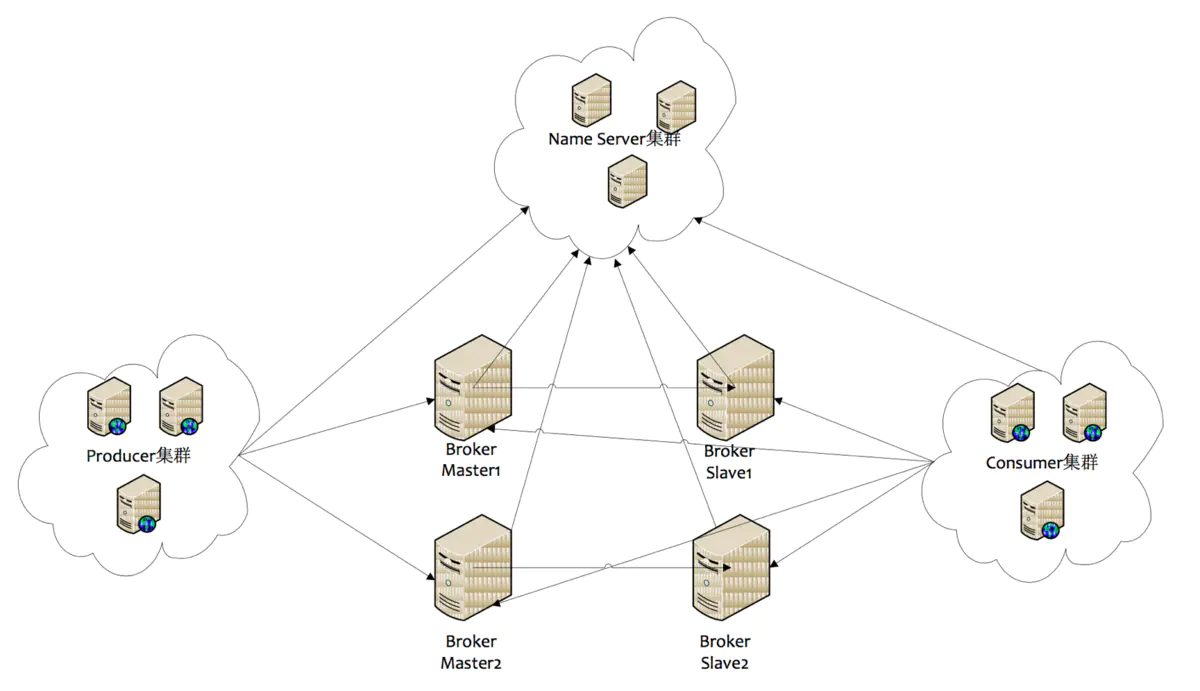
RocketMQ集群由于無法選主,所以當Master掛了以后,slave需要手動切換master,這一點不好
二、RocketMQ為什采用NameSr,而不是zk
ZK是CP,NameSr是AP,RocketMQ選擇了高可用,
RocketMQ的集群思想與Kafka有很大區別,在Kafka中borker這個概念分為Master和slave,可以通過zk選主進行切換和高可用,RocketMQ中Master對應的Borker 和 slave對應的borker是搭建環境的時候指定好的,他不需要選舉,從這里可以看出Kafka的核心思想是通過主從切換保證集群的高可用,而RocketMQ是通過故障轉移保證集群的高可用,例如:當RocketMQ中某個masterBorker掛了,那本來該發送到這個borker中對應佇列的訊息,此時將會被發送到其他Master上(對于普通訊息),
三、RocketMQ的順序訊息
全域順序:就是我希望所有的訊息你都給我按序消費,對應這樣的訊息我們可以創建topic時只分配一個佇列,這樣就失去了高可用的,高吞吐量的效果,
區域順序:這類順序訊息很常見,我們就是根據一定的演算法將同型別的訊息路由到同一個佇列中,發送訊息,要實作 MessageQueueSelector 該介面,重寫select()方法,按照自己的演算法將相同類別的訊息發送大同一個Queue中,
消費端處理: 如何保證消費端順序消費?
- MessageListenerOrderly(順序消費):有序消費,同一佇列的訊息同一時刻只能一個執行緒消費,可保證訊息在同一佇列嚴格有序消費
- MessageListenerConcurrently(并發消費):如果是使用該方式,則需要把執行緒池改為單執行緒模式,
四、訊息重試的原理與死信佇列
Producer
- 如果是異步發送 那么重試次數只有1次
- 對于同步而言,超時例外也是不會再去重試,
- Product默認是2次;他是立即重試
- 發送超時,不會重試
Consumer:
- Consumer默認是16次
- Consumer是有一定時間間隔的,它照1S,5S,10S,30S,1M,2M····2H進行重試,
- Consumer在廣播情況下重試失效
RocketMQ 規定,以下三種情況統一按照消費失敗處理并會發起重試,
- 業務消費方回傳 ConsumeConcurrentlyStatus.RECONSUME_LATER
- 業務消費方回傳null
- 業務消費方主動/被動拋出例外
RocketMQ 消費失敗后會將訊息加入到重試佇列(設定重試訊息的TOPIC, 重試佇列名稱為:%RETRY%+consumergroup),如果當前訊息的重試次數大于最大重試次數,那么就開始走死信佇列, 跟重試訊息一樣,也是設定死信佇列的TOPIC %DLQ%+ 實際的消費組 ,我們可以對死性對了進行處理,但是在實際作業中我們一般重試三次,如果還是失敗也給borker回傳成功,同時我們會將該訊息記錄下來,后期補償,
注意:RocketMQ訊息重試功能需要區分事務訊息、順序訊息、與普通訊息,
- 普通訊息:該型別訊息的重試,會觸發故障轉移,就是當第一次發送訊息失敗,重試發送會換一個borker,
- 順序訊息:該型別訊息重試,不會觸發故障轉移,就是一直往同一個borker上發送,
五、如何保證訊息零丟失
生產者:
- 同步發送: Producer 向 broker 發送訊息,阻塞當前執行緒等待 broker 回應 發送結果,
- 異步發送: Producer 首先構建一個向 broker 發送訊息的任務,把該任務提交給執行緒池,等執行完該任務時,回呼叫戶自定義的回呼函式,執行處理結果,
- Oneway發送: Oneway 方式只負責發送請求,不等待應答,Producer 只負責把請求發出去,而不處理回應結果,我們使用同步發送返送,并且捕獲回傳結果進行重試,可以減小訊息發送丟失,
Conusmer:PushConsumer為了保證訊息肯定消費成功,只有使用方明確表示消費成功,RocketMQ才會認為訊息消費成功,中途斷電,拋出例外等都不會認為成功——即都會重新投遞,ConsumeConcurrentlyStatus.CONSUME_SUCCESS
brocker存盤訊息:采用同步刷盤模式,當刷盤成功后才回傳producer投遞訊息成功,
六、如何保證訊息的最終一致性
事務訊息
- 發送方向 MQ 服務端發送訊息,該訊息為prepare訊息,即消費者不可見,
- MQ Server 將訊息持久化成功之后,向發送方 ACK 確認訊息已經發送成功,此時訊息為半訊息,
- 發送方開始執行本地事務邏輯,發送方根據本地事務執行結果向 MQ Server 提交二次確認(Commit 或是 Rollback),MQ Server 收到Commit 狀態則將半訊息標記為可投遞,訂閱方最終將收到該訊息;MQ Server 收到 Rollback 狀態則洗掉半訊息,訂閱方將不會接受該訊息,
- 在斷網或者是應用重啟的特殊情況下,上述步驟4提交的二次確認最終未到達 MQ Server,經過固定時間后MQ Server 將對該訊息發起訊息回查,發送方收到訊息回查后,需要檢查對應訊息的本地事務執行的最終結果,發送方根據檢查得到的本地事務的最終狀態再次提交二次確認,MQ Server 仍按照步驟4對半訊息進行操作,
Producer Group:標識發送同一類訊息的Producer,通常發送邏輯一致,發送普通訊息的時候,僅標識使用,并無特別用處,若事務訊息,如果某條發送某條訊息的producer-A宕機,使得事務訊息一直處于PREPARED狀態并超時,則broker會回查同一個group的其 他producer,確認這條訊息應該commit還是rollback,但開源版本并不支持事務訊息,
七、Broker是怎么保存資料的
RocketMQ主要的存盤檔案包括commitlog檔案、consumequeue檔案、indexfile檔案,
Broker在收到訊息之后,會把訊息保存到commitlog的檔案當中,而同時在分布式的存盤當中,每個broker都會保存一部分topic的資料,同時,每個topic對應的messagequeue下都會生成consumequeue檔案用于保存commitlog的物理位置偏移量offset,indexfile中會保存key和offset的對應關系,
ommitLog檔案保存于${Rocket_Home}/store/commitlog目錄中,從圖中我們可以明顯看出來檔案名的偏移量,每個檔案默認1G,寫滿后自動生成一個新的檔案,

由于同一個topic的訊息并不是連續的存盤在commitlog中,消費者如果直接從commitlog獲取訊息效率非常低,所以通過consumequeue保存commitlog中訊息的偏移量的物理地址,這樣消費者在消費的時候先從consumequeue中根據偏移量定位到具體的commitlog物理檔案,然后根據一定的規則(offset和檔案大小取模)在commitlog中快速定位,

八、Master和Slave之間是怎么同步資料的呢?
而訊息在master和slave之間的同步是根據raft協議來進行的:
- 在broker收到訊息后,會被標記為uncommitted狀態
- 然后會把訊息發送給所有的slave
- slave在收到訊息之后回傳ack回應給master
- master在收到超過半數的ack之后,把訊息標記為committed
- 發送committed訊息給所有slave,slave也修改狀態為committed
九、RocketMQ為什么速度快
是因為使用了順序存盤、Page Cache和異步刷盤,
我們在寫入commitlog的時候是順序寫入的,這樣比隨機寫入的性能就會提高很多
寫入commitlog的時候并不是直接寫入磁盤,而是先寫入作業系統的PageCache
最后由作業系統異步將快取中的資料刷到磁盤
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/277612.html
標籤:Java
上一篇:zookeeper