目錄
- 一、截斷操作df.truncate()
- 二、Fancy Indexing
- (1)類串列切片[]
- (2)基于標簽df.loc[]
- ①單個標簽——單行
- ②單個串列標簽——多行
- ③切片標簽
- ④逗號雙標簽
- (3)基于下標位置df.iloc[]
- (4)取具體某一資料 .at/.iat
- (5)運算式,bool陣列
- 三、函式篩選
- (1)where 和 mask
- (2)query()
- (3)filter()
資料篩選是處理資料的重要一步,源Excel檔案Fancy_Indexing.xlsx:
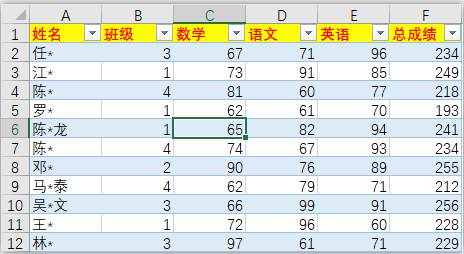
df = pd.read_excel(r'C:/Users/asus/Desktop/Python/Fancy_Indexing.xlsx')
df
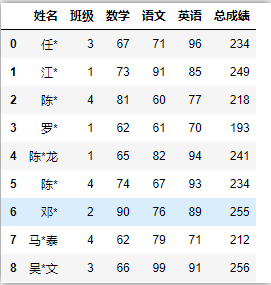
一、截斷操作df.truncate()
df.truncate()需要對索引排序才能截斷,
# 資料截斷
df.truncate(before=2,after=8)
# 對列索引進行排序才能截斷,根據索引值截斷,而不是下標
df.sort_index(axis=1).truncate(before='班級',after='語文',axis=1)
二、Fancy Indexing
(1)類串列切片[]
# 列操作
df['姓名'] # 選擇1列,回傳Series
df[['姓名']] # 選擇1列,回傳DataFrame
df[['姓名','語文']] # 選擇多列,回傳DataFrame
# 行操作:對下標進行切片,不包含終止位置
df[:] # 全切
df[:3] # 回傳前三行
df[4:6] # 回傳第5、6行
df[:20:2] # 步長截取
df['數學'][::-1] # 逆序
# 行列同時操作,不可以直接操作
# df[:,['語文']]
(2)基于標簽df.loc[]
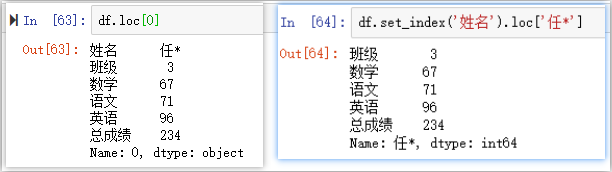
①單個標簽——單行
# 單個標簽——單行
df.loc[0] # 0代表是索引值,而不是像串列切片的下標值,字符型索引需要加引號
df.set_index('姓名').loc['任*'] # 字符型索引加引號
# df.set_index('姓名').index.dtype -->dtype('O')
②單個串列標簽——多行
# 單個串列標簽——多行
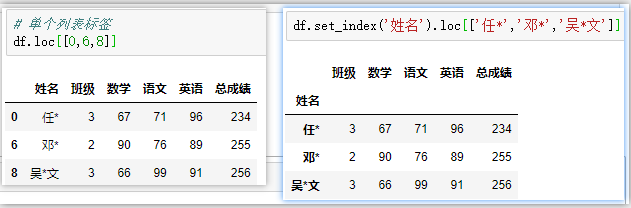
df.loc[[0,6,8]]
df.set_index('姓名').loc[['任*','鄧*','吳*文']] # 字符型索引加引號
# df.set_index('姓名').loc[[0,6,8]] ->KeyError: 'None of [[0, 6, 8]] are in the [index]'
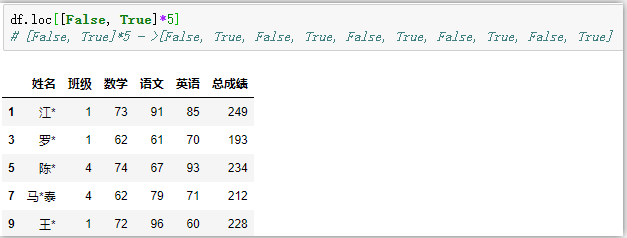
df.loc[[False, True]*5] # bool陣列標簽,隔行查找
③切片標簽
# 切片標簽,標簽也可以切片,且和串列切片不同,包含終止位置
# 根據索引值進行切片,所以先排序才能切,和truncate截斷一樣
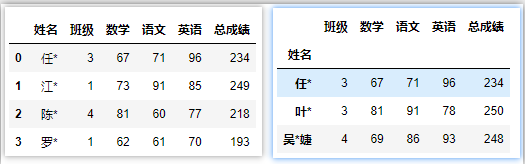
df.loc[:3] # 回傳前4行,包含3終止位置
df.set_index('姓名').sort_index().loc['任*':'吳*婕'] # 要先進行排序
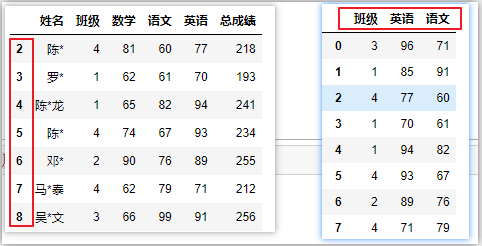
④逗號雙標簽
# 逗號雙標簽——篩選列
# 必須有行元素
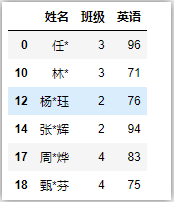
df.loc[:,['姓名','語文']] # 行全要,只要‘姓名’‘語文’這兩列
df.loc[:10,['姓名','數學']] # 前11行
(3)基于下標位置df.iloc[]
df.iloc[]無論是行選還是列選,都只能用自然索引下標(0-n),不包含終止位置.
df.iloc[2:4,2:3]
df.iloc[:,2:]
df.iloc[[5,2],[4,1]]
df.iloc[5,3] # 回傳一個值
# np.r_支持隨意篩選,篩選不連續的行或列
df.iloc[np.r_[0,10:15:2,17:19],np.r_[:2,4]]
(4)取具體某一資料 .at/.iat
(5)運算式,bool陣列
df[df['班級'] == 1] # 篩選1班資訊
df[~(df['班級'] == 1)] # 不等
df[df['姓名'] == '馬*泰'] # '馬*泰'的所有資訊
df.loc[df['姓名'] == '馬*泰',['姓名','數學']] # 只篩選'馬*泰'姓名、數學成績
df.loc[(df['數學'] > 90) & (df['語文'] >90)] # 且
df.loc[(df['數學'] > 90) | (df['語文'] >90)] # 或
df.loc[df['語文'] > df['英語']] # 列間判斷,比較愛國的同學資訊
# df.isin()判斷
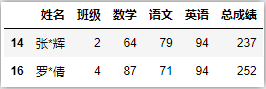
df[df['姓名'].isin(['羅*倩','張*輝'])]
三、函式篩選
(1)where 和 mask
df.where(cond, other=nan, inplace=False,
axis=None, level=None, errors='raise',
try_cast=False, raise_on_error=None)
如果 cond 為真,保持原來的值,否則替換為other,默認為NaN值,mask相反,
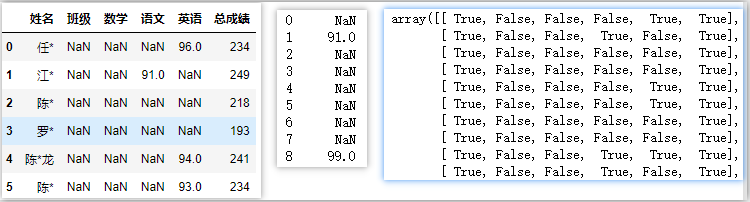
df.where(df > 90) # 不大于90分為NaN
df['語文'].where(df['語文'] > 90) # 語文不大于90為NaN
np.where(df > 90,True,False) # 回傳Adarray bool陣列
# 2 的偶數倍分數顯示,否則為相反數
df[['語文','數學']].where(df[['語文','數學']] % 2 == 0,other=-df[['語文','數學']])
(2)query()
(3)filter()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/279502.html
標籤:Python
上一篇:Mybatis的日志工廠
下一篇:python應該注意的小細節