文章目錄
- 前言
- 資料分析分類
- 資料決議原理概述
- 一、正則re進行資料決議
- 1.1 爬取糗事百科中糗圖板塊下所有的糗圖圖片?
- 二、bs4決議概述
- 2.1 獲取整個標簽
- 2.2 獲取標簽屬性或者存盤的文本內容
- 2.3 實戰專案?
- 三、xpath決議基礎?🌙😃
- 3.1 xpath決議原理
- 3.2 案例講解?
- 3.2.1 爬取58二手房中的房源資訊
- 3.2.2 4k圖片決議爬取
- 3.2.3 全國城市名稱爬取
- 3.4 爬取站長之家免費建立模板并下載??
- 總結
- 1. 正則findall()方法的使用
- 2. format()方法
- 3. re.S和re.M辨析
- 4. 爬取4k圖片出現的亂碼問題?
前言
- 爬蟲在使用場景中的分類
- 通用爬蟲
抓取系統重要組成部分,抓取的是一整張頁面資料聚焦爬蟲?
是建立在通用爬蟲的基礎之上,抓取的是頁面中特定的區域內容,- 增量式爬蟲?
檢測網站中資料更新的情況,只會抓取網站中最新更新出來的資料,
資料分析分類
- 正則
- bs4
xpath?
資料決議原理概述
- 聚焦爬蟲
編碼流程:
- 指定url
- 發起請求
- 獲取回應資料
- 資料決議
- 持久化存盤
- 原理概述概述
- 決議的區域文本內容都會再標簽之間或者標簽對應的屬性中進行存盤
- 進行指定標簽定位
- 標簽或者標簽對應的屬性中存盤的資料值進行提取(決議)
一、正則re進行資料決議
1.1 爬取糗事百科中糗圖板塊下所有的糗圖圖片?

- 需求分析
先使用通用爬蟲獲取一整張頁面,再使用聚焦爬蟲獲取圖片內容

- 具體分析

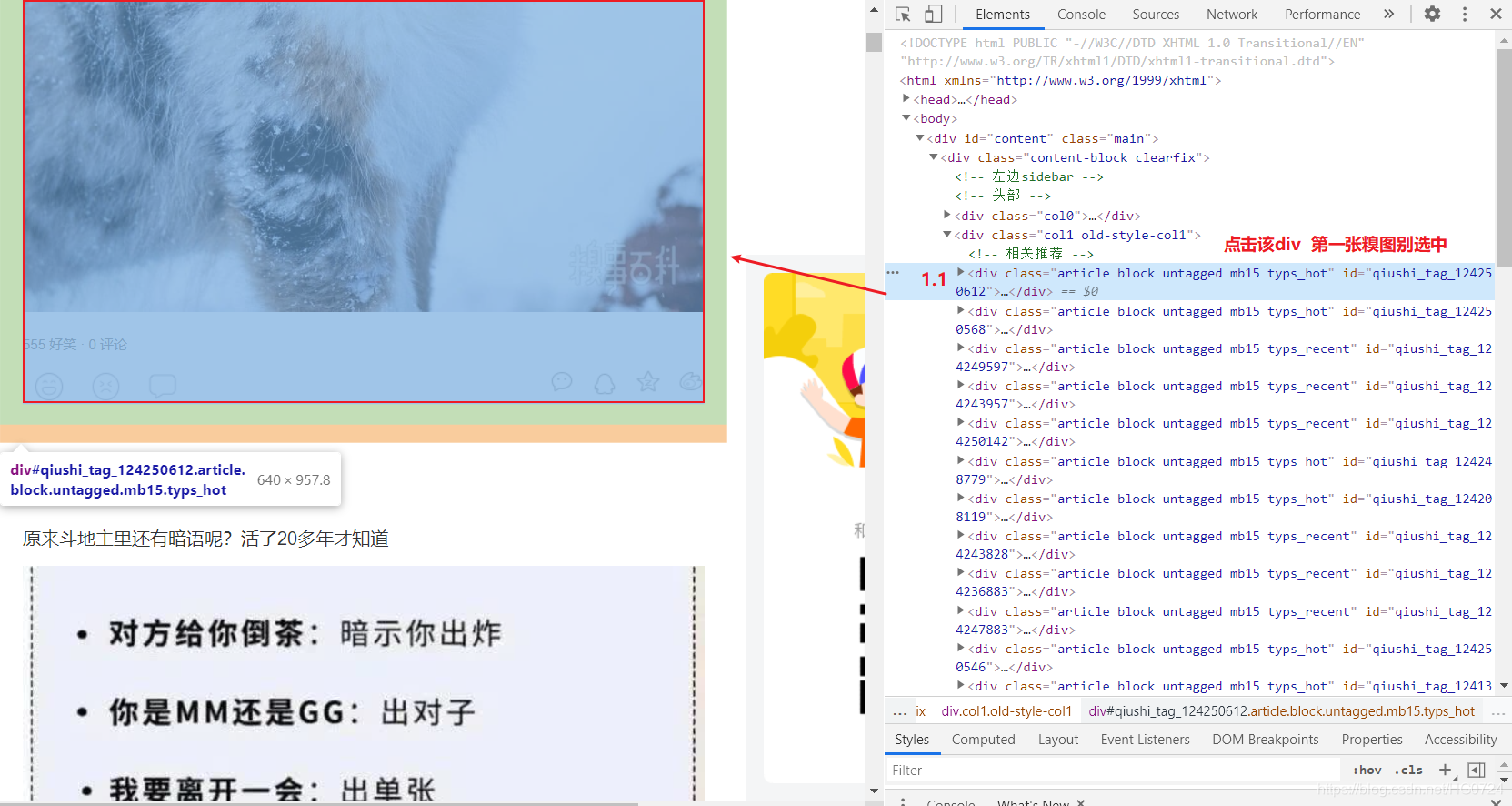
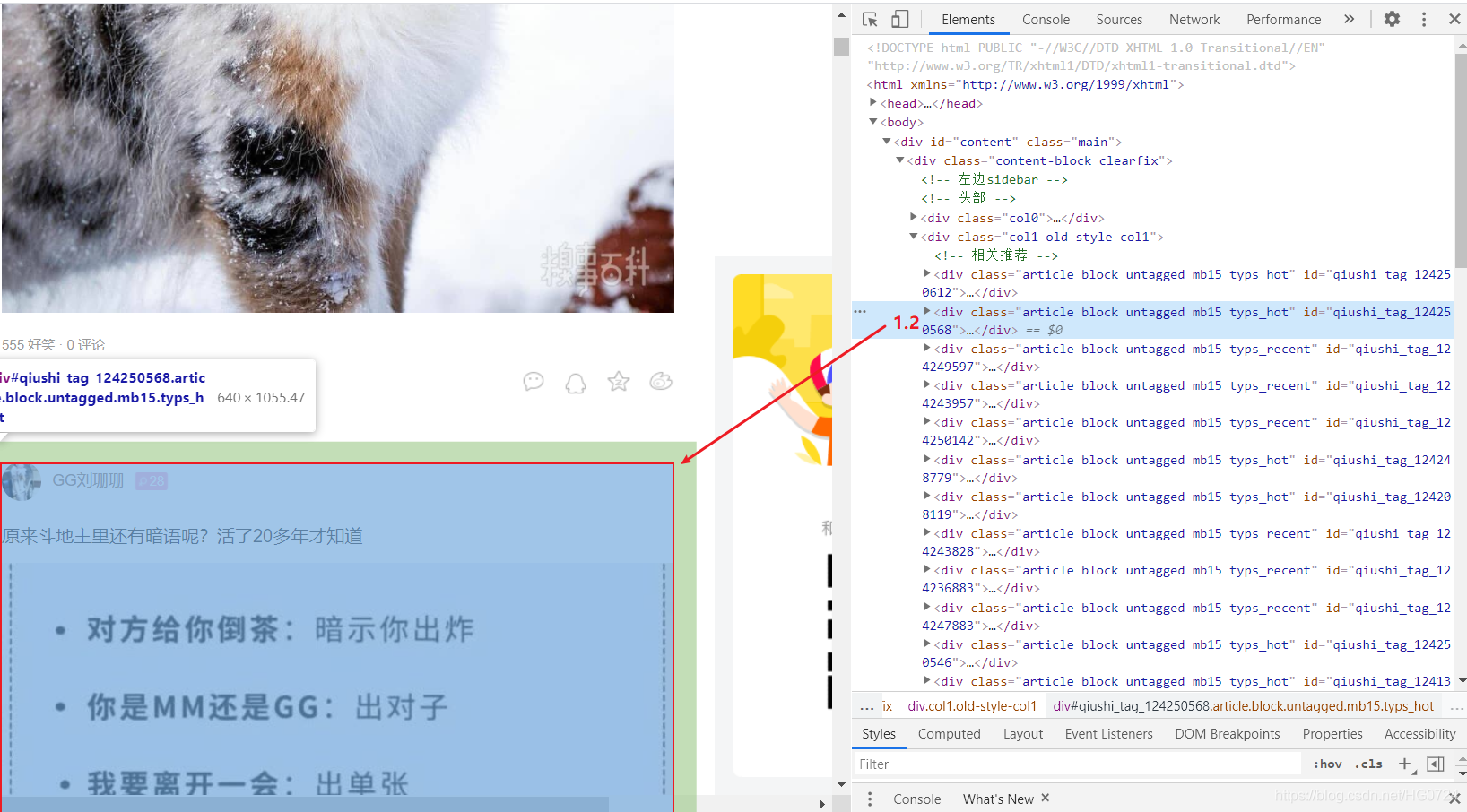
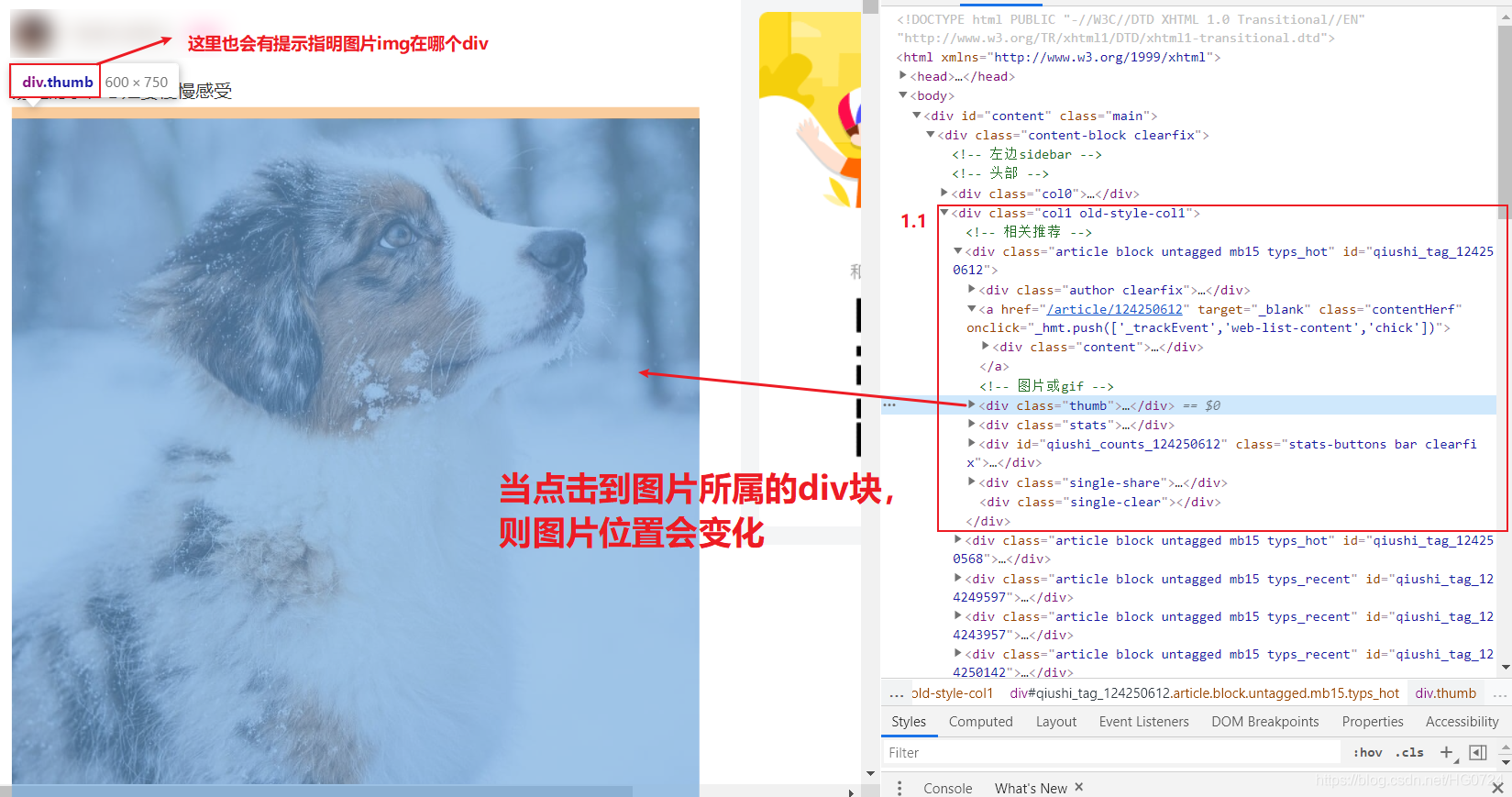
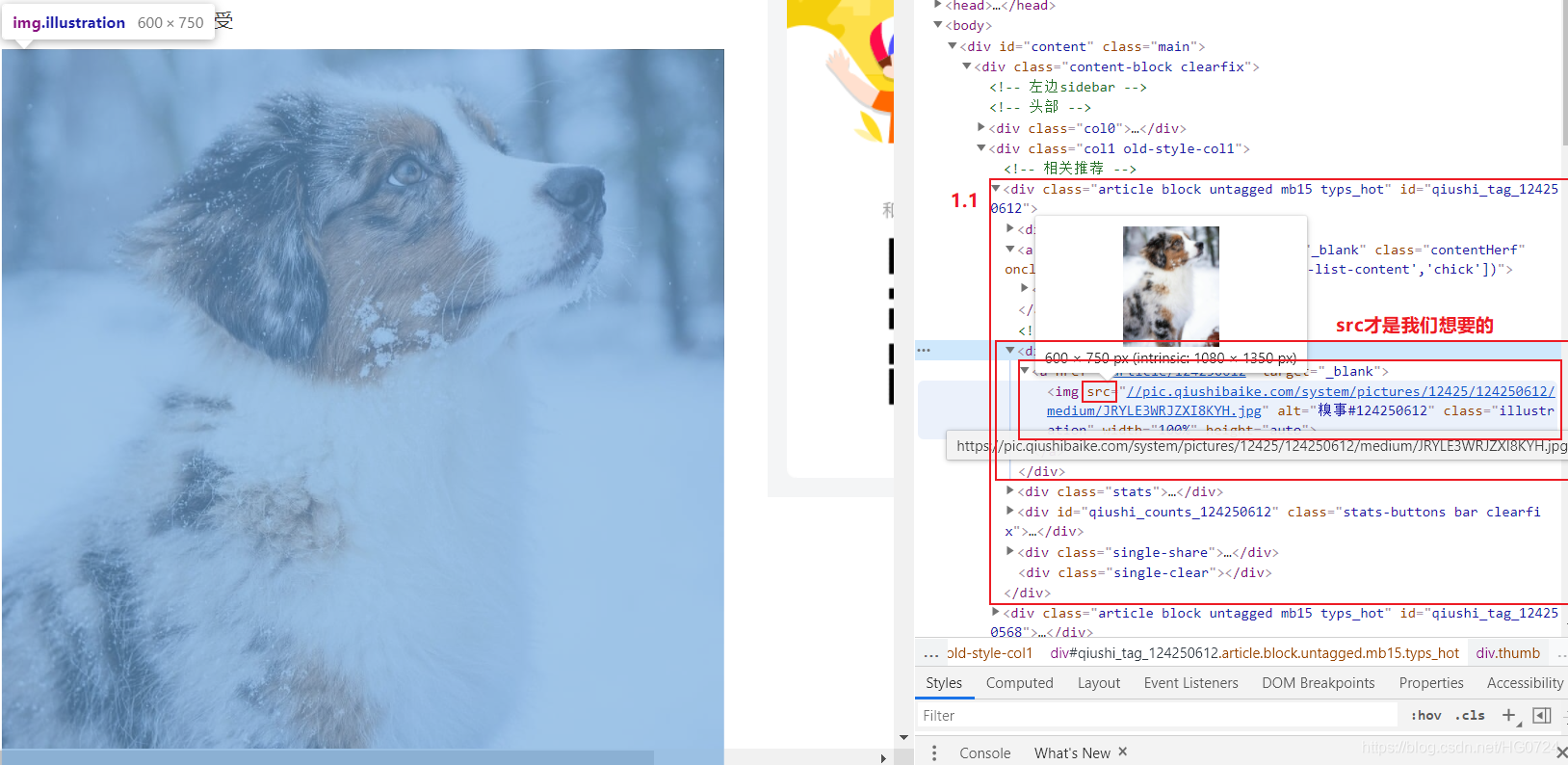
拷貝最小的區域原始碼:
- 目的:提取div中的img標簽中的src屬性值提取出來
<div class="thumb">
<a href="/article/124250612" target="_blank">
<img src="//pic.qiushibaike.com/system/pictures/12425/124250612/medium/JRYLE3WRJZXI8KYH.jpg" alt="糗事#124250612" class="illustration" width="100%" height="auto">
</a>
</div>
- 撰寫正則
ex = '<div class="thumb">.*?<img src="(.*?) alt.*?</div>'
# ()括號內容是我們想要的
- 代碼撰寫
處理第一頁資料:
- 獲取圖片路徑并存盤到串列
import requests
import re
if __name__ == '__main__':
url = 'https://www.qiushibaike.com/imgrank/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
# 使用通用爬蟲對url對應的一整張頁面進行爬取
# 一整張頁面資料使用.text 進行獲取
page_text = requests.get(url=url, headers=headers).text
# 使用聚焦爬蟲將頁面中所有的糗圖進行決議/提取
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
# 回傳串列
img_src_list = re.findall(ex,page_text,re.S)# re.S 叫做單行匹配 re.M 叫做多行匹配
print(img_src_list)
['//pic.qiushibaike.com/system/pictures/12424/124248898/medium/9EBHN0P7Z704IRNA.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250569/medium/IYVWM19GECVE35N6.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251068/medium/T42KZBCK2BODVH9N.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251038/medium/R1C15IV0JA3O5GK7.jpg', '//pic.qiushibaike.com/system/pictures/12423/124237042/medium/B7C6RN8FG1ECU4QO.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250034/medium/70UZCFWLI4PL3937.jpg', '//pic.qiushibaike.com/system/pictures/12414/124148138/medium/IBZA9V3283IO5809.jpg', '//pic.qiushibaike.com/system/pictures/12423/124238731/medium/936HVUV7OOMN9L4P.jpg', '//pic.qiushibaike.com/system/pictures/12424/124241238/medium/WKQS193J9BDN9MEW.jpg', '//pic.qiushibaike.com/system/pictures/12424/124241248/medium/NP2I6R4SYNPQG3H9.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251192/medium/HMIK71X9R6RZFNY1.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250567/medium/EQWD2NB6B1TUFD21.jpg', '//pic.qiushibaike.com/system/pictures/12423/124239461/medium/I1MFATNSTI7XQP6V.jpg', '//pic.qiushibaike.com/system/pictures/12423/124238410/medium/YG8Z33RG54KR7OC2.jpg', '//pic.qiushibaike.com/system/pictures/12423/124236773/medium/JAPN635V0G2V2BLA.jpg', '//pic.qiushibaike.com/system/pictures/12423/124235383/medium/JI0L091QQVS7PQHO.jpg', '//pic.qiushibaike.com/system/pictures/12424/124247459/medium/EAEV8Z68C99FU12L.jpg', '//pic.qiushibaike.com/system/pictures/12423/124239804/medium/11DVRSZJQ78HNT8D.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250516/medium/ZEKVE91EMMMJ3JTB.jpg', '//pic.qiushibaike.com/system/pictures/12423/124237782/medium/S0O4E74O52K5YZW3.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251193/medium/VEP5BC2ZKRHYYOOT.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251161/medium/3SXGPJXG5C13JBAU.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250224/medium/MZQF7KXXBDHMUS13.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251222/medium/TOT961UBURC8WKTA.jpg', '//pic.qiushibaike.com/system/pictures/12423/124239840/medium/0MHKXBDTU7XLMCYW.jpg']
通過分析上圖串列中路徑發現少了些許東西:
https://pic.qiushibaike.com/system/pictures/12425/124250612/medium/JRYLE3WRJZXI8KYH.jpg
- 修改后下載到指定檔案夾
# 需求:爬取糗事百科中糗圖板塊下所有的糗圖圖片
import requests
import re
import os
if __name__ == '__main__':
# 創建一個檔案見 用來保存所有的圖片
if not os.path.exists('./qiutuLibs'):
os.makedirs('./qiutuLibs')
url = 'https://www.qiushibaike.com/imgrank/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
# 使用通用爬蟲對url對應的一整張頁面進行爬取
# 一整張頁面資料使用.text 進行獲取
page_text = requests.get(url=url, headers=headers).text
# 使用聚焦爬蟲將頁面中所有的糗圖進行決議/提取
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
# 回傳串列
# findall()方法的使用見總結①
img_src_list = re.findall(ex,page_text,re.S)# re.S 叫做單行匹配 re.M 叫做多行匹配
print(img_src_list)
# 單獨便利串列 并做get請求
for src in img_src_list:
# 拼接出完整的圖片地址
src = 'https:' + src
# 發起get請求 獲取二進制圖片資料
img_data = requests.get(url=src,headers=headers).content
# 生成圖片名稱 從原始切分出來
# '//pic.qiushibaike.com/system/pictures/12417/124176031/medium/VC2AHAHUEUUX1KY3.jpg"'
img_name = src.split('/')[-1] # 最后一個
# 圖片存盤路徑
imgPath = './qiutuLibs/' + img_name
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下載成功')

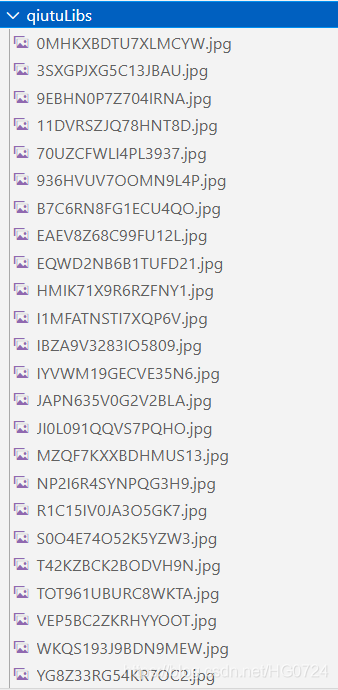
處理第多頁資料:
第一頁:https://www.qiushibaike.com/imgrank/
(其實我們用這個url也是該頁面:https://www.qiushibaike.com/imgrank/page/1/)
第二頁:https://www.qiushibaike.com/imgrank/page/2/
第二頁:https://www.qiushibaike.com/imgrank/page/3/
# 需求:爬取糗事百科中糗圖板塊下所有的糗圖圖片
import requests
import re
import os
if __name__ == '__main__':
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
# 創建一個檔案見 用來保存所有的圖片
if not os.path.exists('./qiutuLibs'):
os.makedirs('./qiutuLibs')
# 設定一個通用url模板
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
# 對1-13頁做請求
for pageNum in range(1,13):
# 對應頁碼的url
new_url= format(url%pageNum)
# 使用通用爬蟲對url對應的一整張頁面進行爬取
# 一整張頁面資料使用.text 進行獲取
page_text = requests.get(url=url, headers=headers).text
# 對每一頁進行決議
# 使用聚焦爬蟲將頁面中所有的糗圖進行決議/提取
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
# 回傳串列
img_src_list = re.findall(ex,page_text,re.S)# re.S 叫做單行匹配 re.M 叫做多行匹配
# print(img_src_list)
# 單獨便利串列 并做get請求
for src in img_src_list:
# 拼接出完整的圖片地址
src = 'https:' + src
# 發起get請求 獲取二進制圖片資料
img_data = requests.get(url=new_url,headers=headers).content
# 生成圖片名稱 從原始切分出來
# '//pic.qiushibaike.com/system/pictures/12417/124176031/medium/VC2AHAHUEUUX1KY3.jpg"'
img_name = src.split('/')[-1] # 最后一個
# 圖片存盤路徑
imgPath = './qiutuLibs/' + img_name
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下載成功')
format()用法是重點,見總結
二、bs4決議概述
利用正則進行決議,即可以應用于Python語言中,也可以應用于其他語言中,而本節所講解內容只能應用于Python語言
- 資料決議原理:
- 標簽定位
- 提取標簽、標簽屬性中存盤的資料值
bs4資料決議原理:
- 實體化一個BeautifulSoup物件,并且將頁面原始碼資料加載到該物件中
- 通過呼叫BeautifulSoup物件中相關的屬性或者方法進行標簽定位和資料獲取
- 環境安裝
pip install bs4
BeautifulSoup物件存在于bs4模塊中pip install lxml
lxml是一種決議器,不僅在bs4中能用到,在xpath中也能用到
2.1 獲取整個標簽
- 如何例化BeautifulSoup物件?
f rom bs4 import BeautifulSoup- 物件的實體化:(兩種)①②
- ①:將本地的html檔案中的資料加載到該物件中(檔案下載)
fp = open('./test.html','r',encoding = 'utf-8')
soup = BeautifulSoup(fp,'lxml')
資料加載和物件實體化是同步實作的
- ②:將互聯網上獲取的頁面原始碼加載到該物件中
page_text = response.text
soup = BeautifulSoup(page_text ,'lxml')
- 該物件中用于資料決議的方法和屬性:??
- ①
soup.tagName:回傳的是html中第一次出現的tagName標簽- ②
soup.find():
- soup.find(‘tagName’)等同于soup.div
- 屬性定位:可以根據具體的屬性定位到屬性對應的標簽
print(soup.find(‘div’,class_/id/attr= ‘song’))
class加_ 防止與關鍵字class沖突soup.find()只回傳第一個符合條件的結果,所以soup.find()后面可以直接接.text或者get_text()來獲得標簽中的文本
- ③
soup.find_all():用法同soup.find()但是回傳串列
- soup.find_all(‘tagName’)
- 屬性定位:soup.find_all(‘a’,class_ = ‘du’)
- ④
soup.select(‘選擇器’):
- (‘id,class,標簽,,,選擇器’),回傳的是一個串列
- 層級選擇器 :
- 一個層級>:通過
>來不斷剝離選擇自己想要的
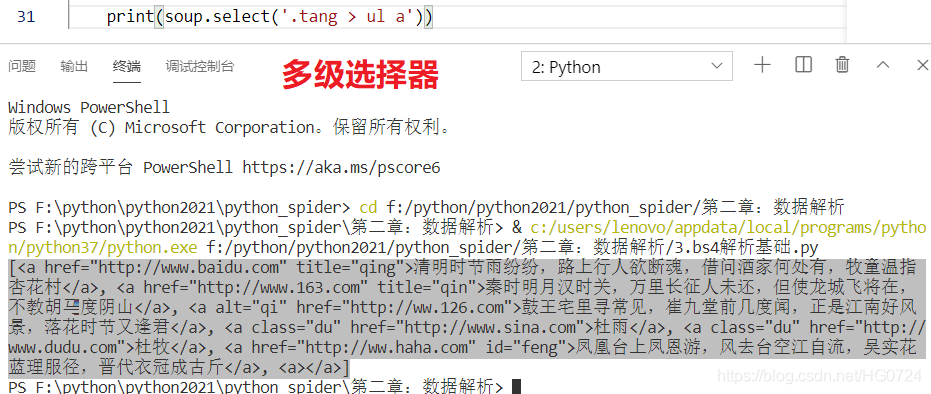
- 多級選擇器:使用空格 例如<ul> 與 <a>之間間隔<li>
選擇器知識會在總結章節做補充,我聽到這里也挺蒙的,網頁基本知識已經還給老師了
# 實體化 ①:
from bs4 import BeautifulSoup
if __name__ == '__main__':
# 將本地的html檔案中的資料加載到該物件中
fp = open('./test.html','r',encoding = 'utf-8')
soup = BeautifulSoup(fp,'lxml')
# 列印出的就是原檔案內容
print(soup)

- soup.tagName
print(soup.a)

print(soup.div)

- soup.find()
soup.find(‘tagName’)
print(soup.find('div'))

soup.find(‘div’,class_= ‘song’)
# class加_ 防止與關鍵字class沖突
print(soup.find('div',class_= 'song'))
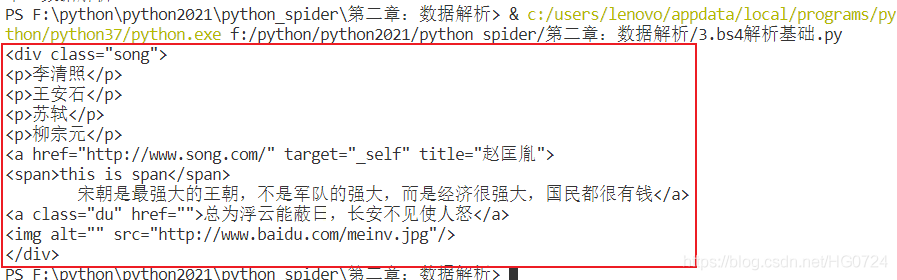
- soup.find_all()
soup.find_all(‘a’)
# 回傳的是串列
print(soup.find_all('a'))

soup.find_all(‘a’,class_ = ‘du’)
print(soup.find_all('a',class_ = 'du'))

- soup.select()
soup.select(‘.tang’):(‘id,class,標簽,,,選擇器’)
# 回傳的是串列
print(soup.select('.tang'))
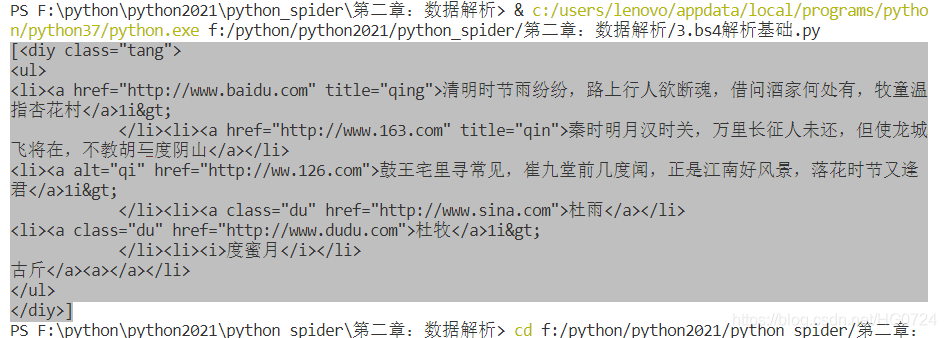
層級選擇器
- 一級選擇器
# > 表示一個層級: 即 一級一級往下剝離開來
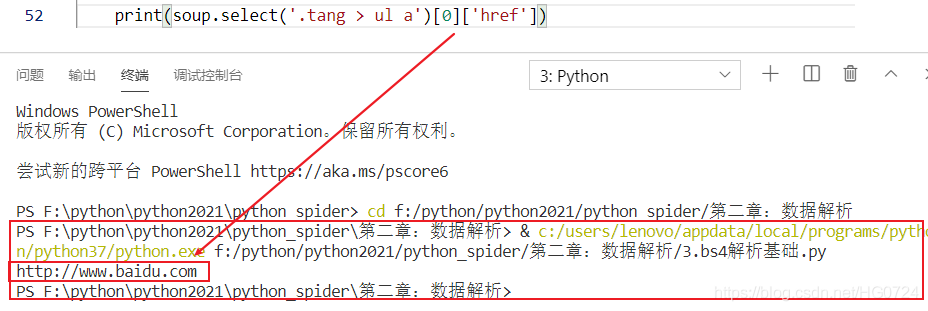
print(soup.select('.tang > ul > li > a'))
print(soup.select('.tang > ul > li > a')[0])
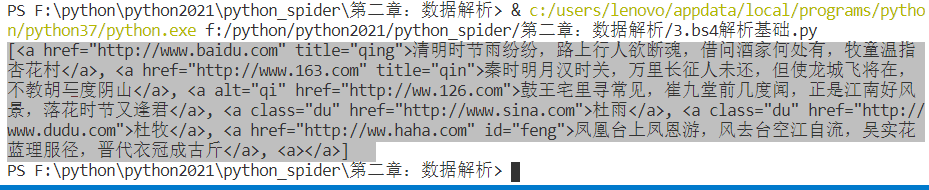

- 多級選擇器
使用空格 :例如<ul> 與 <a>之間 間隔<li>

2.2 獲取標簽屬性或者存盤的文本內容
獲取標簽的目的就是為了獲取標簽屬性或者存盤的文本內容,而2.1章節的內容很好的幫助我們解決了標簽如何獲取的步驟
- 獲取標簽之間的文本資料
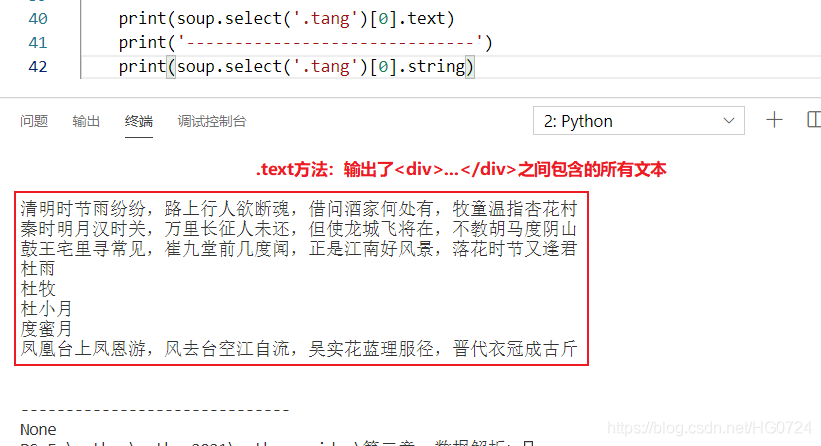
soup.a.text/string/get_text():定位到了a標簽后直接使用相關屬性或者方法獲取文本
屬性與方法之間的區別:
- text/get_text():可以獲取某一個標簽中所有的文本內容
- string:只可以獲取該標簽下面直系的文本內容
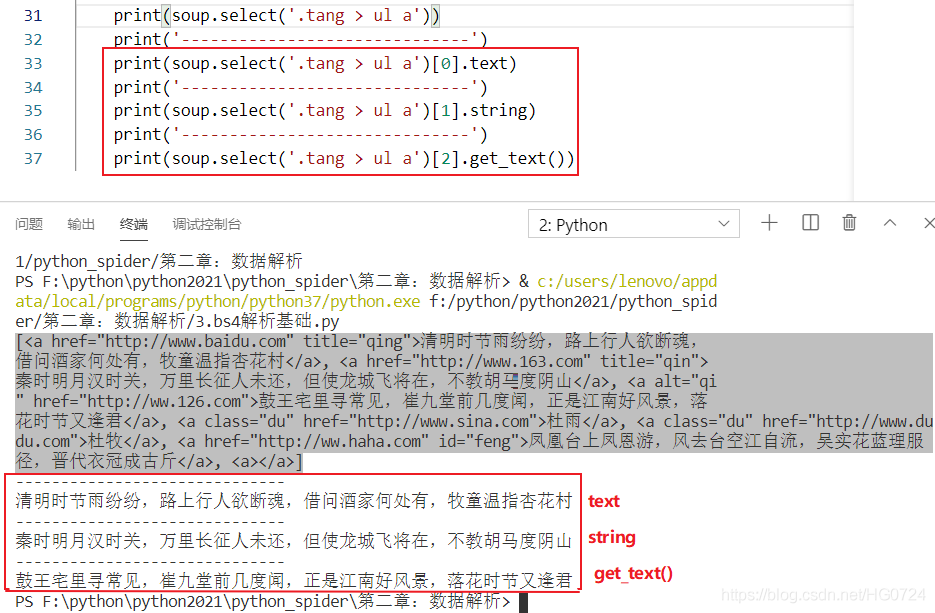
- 獲取標簽中的屬性值
2.3 實戰專案?
需求:爬取三國演義小說的所有章節標題和章節內容
三國演義
- 需求分析
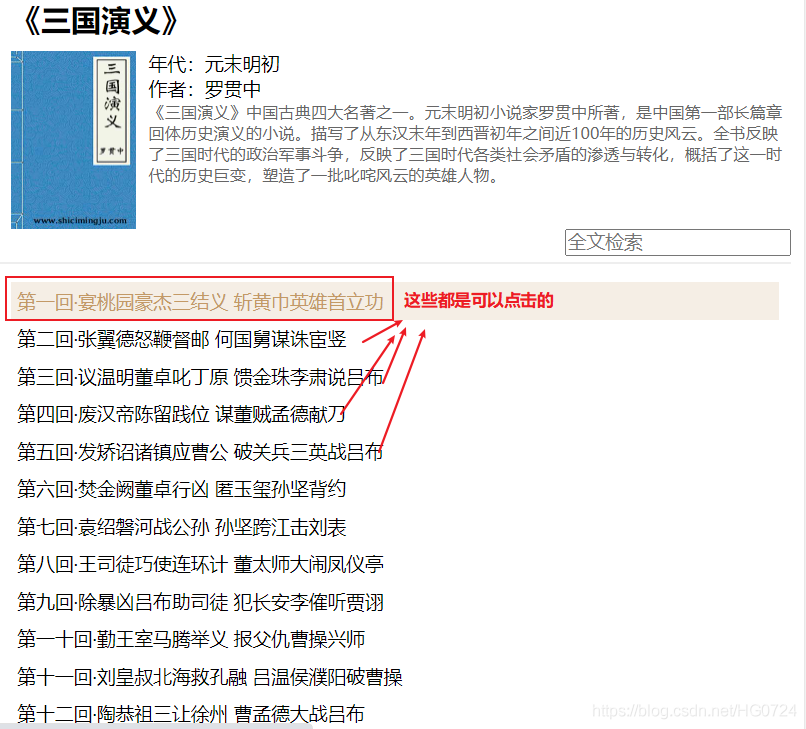

在當前頁(圖一)可以決議出章節的標題和和章節內容所對應的鏈接地址(通過鏈接可以跳轉到文章內容)
是否是AJAX請求的判斷在爬蟲入門概念與硬核實戰鞏固(一)這一節中做了詳細的介紹,在此不做贅述,
- 實戰代碼
我的代碼一開始是亂碼的(爬取首頁資料和章節內容資料都是亂碼),代碼中的print陳述句是除錯的
出現亂碼后,加入了這句話:
page_text = page_text.encode('iso-8859-1').decode("UTF-8")
你一開始可以不加,視頻中也是沒有加的,所以遇到問題具體分析
import requests
from bs4 import BeautifulSoup
# 需求:爬取三國演義小說的所有章節標題和章節內容
if __name__=='__main__':
# 對首頁的內容進行爬取
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(url=url,headers=headers).text
page_text = page_text.encode('iso-8859-1').decode("UTF-8")# 出現亂碼加上這句
#print(page_text)
# 在首頁決議出章節的標題和詳情頁的url
# 1. 實體化BeautifulSoup物件,需要將頁面原始碼資料加載到物件中
soup = BeautifulSoup(page_text,'lxml')
# 決議章節標題和詳情頁的url
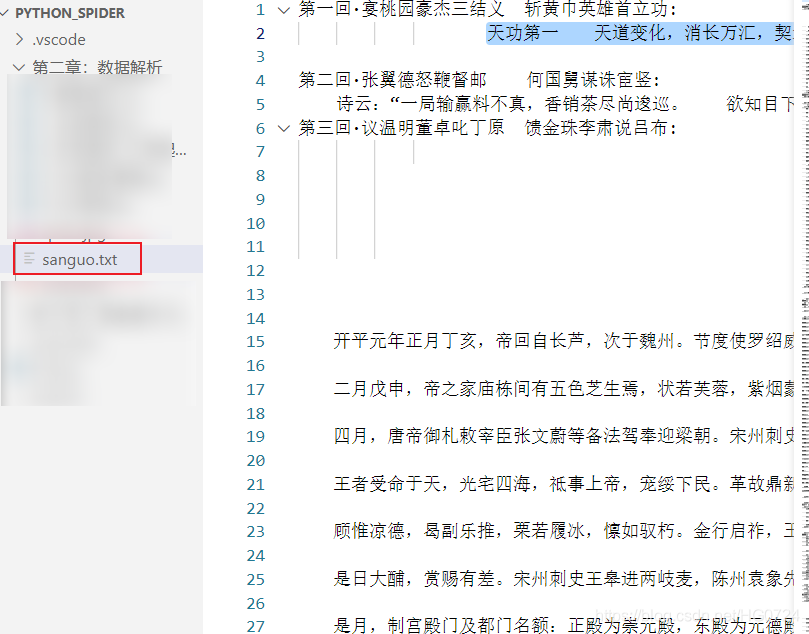
li_list = soup.select('.book-mulu > ul > li')# 回傳的是一系列<li>標簽
fp = open('./sanguo.txt','w',encoding='UTF-8')
for li in li_list:
title = li.a.string # 獲取了<a>標簽 即章節標題
# print(li.a)
detail_url = 'https://www.shicimingju.com'+li.a['href']# 獲取屬性值
# 對詳情頁發起請求,決議出章節內容
detail_page_text = requests.get(url=detail_url,headers=headers).text
detail_page_text = detail_page_text.encode('iso-8859-1').decode("UTF-8")# 出現亂碼加上這句
# 決議出詳情頁的章節內容 <div class="chapter_content">,,,</div>
detail_soup = BeautifulSoup(detail_page_text,'lxml')
dic_tag = detail_soup.find('div',class_ = 'chapter_content')
content = dic_tag.text # 或者dic_tag.get_text() 即章節內容
# 至此 獲得了 一個章節的標題和內容
# 持久化存盤
fp.write(title+":"+content+"\n")
print(title+'爬取成功!!')
fp.close()

三、xpath決議基礎?🌙😃
3.1 xpath決議原理
- 實體化一個
etree的物件,且需要將被決議的頁面原始碼資料加載到該物件中- 呼叫etree物件中的xpath方法結合著xpath運算式實作標簽的定位和內容的捕獲
- 環境安裝
pip install lxml# 決議器
- 如何實體化物件?
- 將本地的html檔案中的原始碼資料加載到etrr物件中:(本地檔案下載)
etree.parse(filePath)
- 可以將互聯網上的原始碼資料加載到該物件中
etree.HTML('page_text')
- xpath(‘xapth運算式’)
- xapth運算式
- 定位標簽
/:表示的是從根節點開始定位,表示的是一個層級,//:表示的是多個層級,可以表示從任意位置開始定位,- 屬性定位:
//div[@class = 'song']{tag[@attrName = ‘attrValue’]}
r = tree.xpath(’//div[@class=“song”]’)# 可能定位到一個或者多個- 索引定位:(
索引從1開始)
- r = tree.xpath(’//div[@class=“song”]/p[3]’)# 該div下有四個p 蘇軾位于第三個
# r = tree.xpath('/html/head/title')#第一個/表示根節點,其他/表示一個層級
# print(r)#
# [<Element title at 0x27d21b1f8c8>]
# r = tree.xpath('/html/body/div')#第一個/表示根節點,其他/表示一個層級
# print(r)
# [<Element div at 0x1ce0925f988>, <Element div at 0x1ce0925fa88>, <Element div at 0x1ce0925fac8>]
# r = tree.xpath('/html//div')#第一個/表示根節點,//表示多個層級
# print(r)
# [<Element div at 0x16a52d5f888>, <Element div at 0x16a52d5f988>, <Element div at 0x16a52d5f9c8>]
r = tree.xpath('//div')#//表示多個層級
print(r)
# [<Element div at 0x162887cf988>, <Element div at 0x162887cfa88>, <Element div at 0x162887cfa8>]
- 獲取標簽文本內容
- 如何取文本?
例如:獲取杜牧文本
<li><a href="http://www.dudu.com" class="du">杜牧</a></li>
/text():獲取的是標簽中直系的文本內容//text():獲取的是非直系的所有的文本內容
# 獲取文本內容 /text() 或者 //text()
# 1. <li><a href="http://www.dudu.com" class="du">杜牧</a></li> --->直系文本
# r = tree.xpath('//div[@class="tang"]//li[5]/a/text()')[0]# /text()取文本 回傳的是串列
# print(r)# ['杜牧']
# 2. <li><i>度蜜月</i></li> --> 通過<li>獲取文本 使用//
# r = tree.xpath('//div[@class="tang"]//li[7]//text()')[0]
# print(r)
# r = tree.xpath('//li[7]//text()')[0]
# print(r)
r = tree.xpath('//div[@class="tang"]//text()')
print(r)
- 如何取屬性?
/@attrName:
r = tree.xpath(’//div[@class=“song”]/img/@src’)
3.2 案例講解?
3.2.1 爬取58二手房中的房源資訊
- 需求分析
爬取58二手房中的房源資訊:58同城
需要通過抓包工具逐層決議出xpath運算式
視頻教程和我寫的有出入,可能當你看到這篇文章的時候,url也已經變化了,標簽也變化了,所以你要具體問題具體分析
- 案例原始碼
import requests
from lxml import etree
if __name__ == '__main__':
# 爬取頁面原始碼資料
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://bj.58.com/ershoufang/?PGTID=0d100000-0000-1c69-0eaf-c4c0d938b9b6'
page_text = requests.get(url=url,headers=headers).text
# 1. 實體化etree物件并加載
tree = etree.HTML(page_text)
div_property_list = tree.xpath('//section[@class="list"]/div')
print(div_property_list)
print('----------------------------------------------------------')
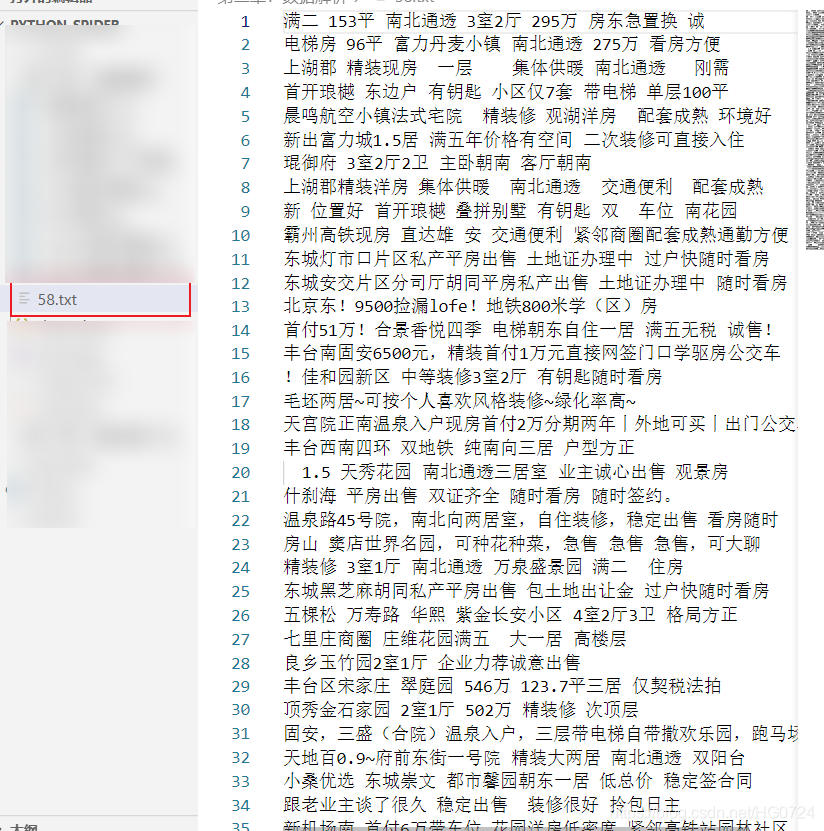
fp = open('./58.txt','w',encoding='utf-8')
# 頁面資料區域決議
for div_title in div_property_list:
# ./表示 div[@class="property-content-title"]
title = div_title.xpath('./a/div[2]/div/div/h3/text()')[0]# 我們要單獨的從div_title中決議出h3標簽
print(title)
fp.write(title+'\n')
fp.close()
3.2.2 4k圖片決議爬取
- 需求分析
鏈接:4k圖片地址
獲取img標簽的src屬性值獲取圖片,alt屬性值作為圖片名稱
- 案例原始碼
這里展示的是完整沒有錯誤的代碼,但試想一下撰寫程式的程序不可能是一帆風順的,因此我將本案例遇到的問題放在了總結中的第四小節
import requests
from lxml import etree
import os
if __name__ == '__main__':
# 爬取頁面原始碼資料
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://pic.netbian.com/4kmeinv/'
response = requests.get(url=url,headers=headers)
# 可以手動設定回應資料編碼格式
# response.encoding = 'utf-8'
page_text = response.text
# 資料決議
# 獲取img標簽的src屬性值獲取圖片,alt屬性值作為圖片名稱
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
# 創建一個存盤4k圖片的檔案夾
if not os.path.exists('./picLibs'):
os.mkdir('./picLibs')
for li in li_list:
img_src = 'https://pic.netbian.com' + li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0] + '.jpg'
# 通用處理中文亂碼的方案
img_name = img_name.encode('iso-8859-1').decode("gbk")
# print(img_name,img_src)
# 請求圖片進行持久化存盤
img_data = requests.get(url=img_src,headers=headers).content
img_path = './picLibs/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'下載成功!!!')
3.2.3 全國城市名稱爬取
- 需求分析
全國城市名稱
- 案例原始碼
- 方法一:
import requests
from lxml import etree
if __name__ == '__main__':
# 爬取頁面原始碼資料
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://www.aqistudy.cn/historydata/'
response = requests.get(url=url,headers=headers)
page_text = response.text
tree = etree.HTML(page_text)
all_city_names = []
hot_li_list = tree.xpath('//div[@class="bottom"]/ul/li')
# 方法一
# 決議熱門城市名稱
for li in hot_li_list:
hot_city_name = li.xpath('./a/text()')[0]
all_city_names.append(hot_city_name)
city_names = tree.xpath('//div[@class="bottom"]/ul/div[2]/li')
# 決議全部城市名稱
for li in city_names:
city_name = li.xpath('./a/text()')[0]
all_city_names.append(city_name)
print(all_city_names,len(all_city_names))
上述用了兩個for回圈進行城市名稱獲取
思考:能不能用一個通用的xpath運算式一次性獲取城市名稱呢?
答案當然是可以的
- 方法二
import requests
from lxml import etree
if __name__ == '__main__':
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://www.aqistudy.cn/historydata/'
response = requests.get(url=url,headers=headers)
page_text = response.text
tree = etree.HTML(page_text)
# 想要決議熱門城市和全部城市對應的a標簽
# 熱門城市 //div[@class="buttom"]/ul/li/a
# 全部城市 //div[@class="buttom"]/ul/div[2]/li/a
# 用 按位或 使用
a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a')
all_city_names = []
for a in a_list:
city_name = a.xpath('./text()')[0]
all_city_names.append(city_name)
print(all_city_names,len(all_city_names))
兩種方法的運行結果都如下圖所示:

xpath運算式如何更加具有通用性?
- 在xpth運算式中使用管道符分割
- 作用:可以使管道符左右兩側的子xpath運算式同時生效或者一個生效
本例中:
- 熱門城市: //div[@class=“buttom”]/ul/li/a
- 全部城市: //div[@class=“buttom”]/ul/div[2]/li/a
# 用 按位或 使用
a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a')
3.4 爬取站長之家免費建立模板并下載??
- 需求分析
鏈接:免費模板
- 對頁面資料的每一個模板的詳情資料決議 —> 模板下載頁的鏈接src
- 點擊模板之后再決議下載地址對應的鏈接 —> 模板的壓縮包下載鏈接href
- 對href發請求下載即可
- 資料持久化存盤
由于一頁的模板下載我的電腦就慢了,因此在此不做分頁多頁下載
- 案例原始碼
xpath決議案例-爬取免費簡歷模板.py
- 編程問題整理


- 結果展示

總結
1. 正則findall()方法的使用
想了解更多正則運算式的知識:?模式匹配與正則運算式
search()將回傳一個Match物件,包含被查找字串中的“第一次”匹配的文本
findall()方法將回傳一組字串串列(回傳的是串列,串列內容是字串),包含被查找字串中的所有匹配
- 案例展示
>>> phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
>>> mo = phoneNumRegex.search('Cell: 415-555-9999 Work: 212-555-0000')
>>> mo.group()
'415-555-9999'
- 沒有分組 —沒有括號
findall()不是回傳一個Match 物件,而是回傳一個
字串串列(沒有括號或只有一個括號),只要在正則運算式中沒有分組,串列中的每個字串都是一段被查找的文本,它匹配該正則運算式,
>>> phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d') # has no groups
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
['415-555-9999', '212-555-0000']
- 有分組 —有括號
有分組,那么findall()將回傳
元組的串列(多個括號[>1]的情況下),每個元組表示一個找到的匹配,其中的項就是正則運算式中每個分組的匹配字串
- 上述驗證
>>> import re
# --------------只有一個括號和沒有括號的情況相同-----------------------
# 1. 一個括號
>>> phoneNumRegex = re.compile(r'(\d\d\d-\d\d\d-\d\d\d\d)')
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
['415-555-9999', '212-555-0000']
>>> phoneNumRegex = re.compile(r'(\d\d\d-\d\d\d)-\d\d\d\d')
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
['415-555', '212-555']
# 2. 沒有括號
>>> phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d') # has no groups
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
['415-555-9999', '212-555-0000']
-------------------------------------------------------------------------
# 3. 兩個括號 回傳的串列中含有元組
>>> phoneNumRegex = re.compile(r'(\d\d\d-\d\d\d)-(\d\d\d\d)')
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
[('415-555', '9999'), ('212-555', '0000')]
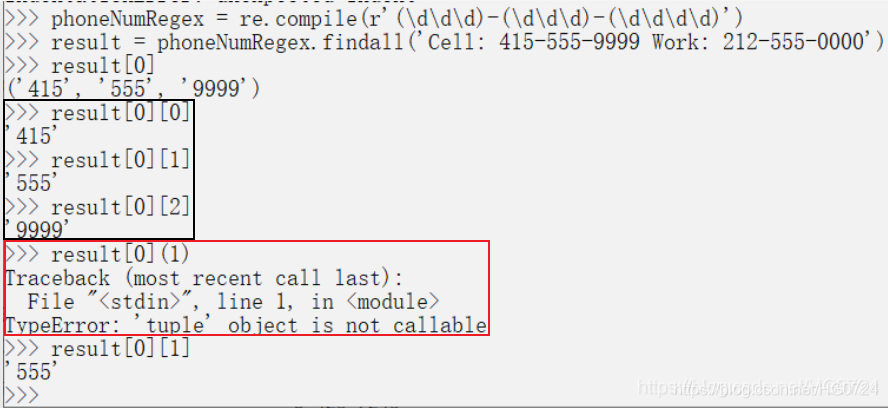
# 4. 三個括號 回傳的串列中含有元組
>>> phoneNumRegex = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)') # has groups
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
[('415', '555', '1122'), ('212', '555', '0000')]
- 結論
- 如果呼叫在一個沒有分組或只有一個分組的正則運算式上,例如:
\d\d\d-\d\d\d-\d\d\d\d,方法
findall()將回傳一個匹配字串的串列,例如[‘415-555-9999’, ‘212-555-0000’],- 如果呼叫在一個有分組的正則運算式上,例如:
(\d\d\d)-(\d\d\d)-(\d\d\d\d),方法findall()將回傳一個字串的元組的串列(每個分組對應一個字串),例如[(‘415’,‘555’, ‘1122’), (‘212’, ‘555’, ‘0000’)]
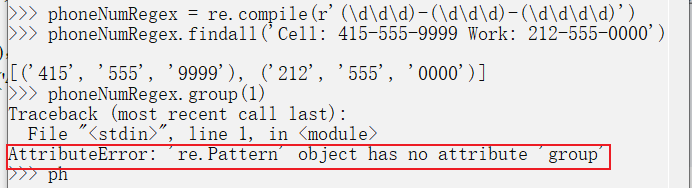
使用findall()方法,無法使用group()函式
2. format()方法
# 方法一
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
# 對1-13頁做請求
for pageNum in range(1,3):
# 對應頁碼的url
new_url= format(url%pageNum)
# 方法二
>>> url = 'https://www.qiushibaike.com/imgrank/page/{id}/'
>>> for num in range(1,10):
... newurl = url.format(id=num)
... print(newurl)
...
https://www.qiushibaike.com/imgrank/page/1/
https://www.qiushibaike.com/imgrank/page/2/
https://www.qiushibaike.com/imgrank/page/3/
https://www.qiushibaike.com/imgrank/page/4/
https://www.qiushibaike.com/imgrank/page/5/
https://www.qiushibaike.com/imgrank/page/6/
https://www.qiushibaike.com/imgrank/page/7/
https://www.qiushibaike.com/imgrank/page/8/
https://www.qiushibaike.com/imgrank/page/9/
# 方法三
>>> url = 'https://www.qiushibaike.com/imgrank/page/{0}/'
>>> for num in range(1,10):
... newurl = url.format(num)
... print(newurl)
...
https://www.qiushibaike.com/imgrank/page/1/
https://www.qiushibaike.com/imgrank/page/2/
https://www.qiushibaike.com/imgrank/page/3/
https://www.qiushibaike.com/imgrank/page/4/
https://www.qiushibaike.com/imgrank/page/5/
https://www.qiushibaike.com/imgrank/page/6/
https://www.qiushibaike.com/imgrank/page/7/
https://www.qiushibaike.com/imgrank/page/8/
https://www.qiushibaike.com/imgrank/page/9/
3. re.S和re.M辨析
詳情見:Python正則運算式里的單行re.S和多行re.M模式
原理:Python 正則運算式里的單行s和多行m模式?
一段多行文本,盡管在文本編輯器中顯示為二維的形狀,但是在正則運算式決議器看來,檔案是一維的字串,在碰到包含換行符的字串時,有多種匹配模式,分別能得到不同的結果
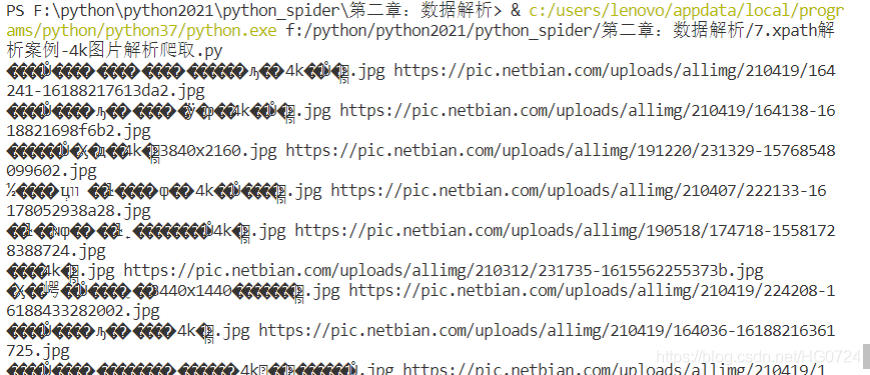
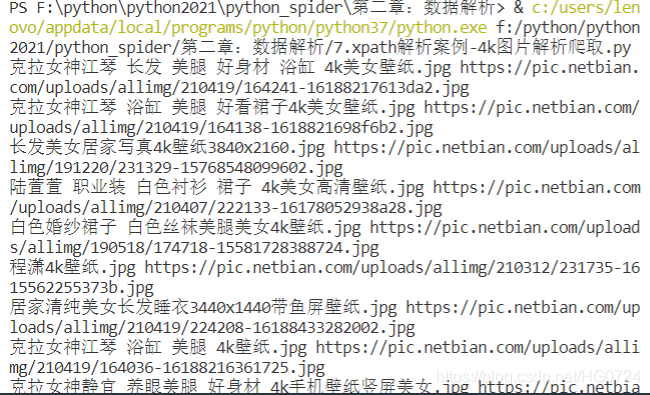
4. 爬取4k圖片出現的亂碼問題?

??à-??é??-?ù 3¤·¢ ?àíè o?éí2? ???× 4k?à??±ú??.jpg https://pic.netbian.com/uploads/allimg/210419/164241-16188217613da2.jpg
??à-??é??-?ù ???× ?àíè o??′è1×ó4k?à??±ú??.jpg https://pic.netbian.com/uploads/allimg/210419/164138-1618821698f6b2.jpg
3¤·¢?à???ó?òD′??4k±ú??3840x2160.jpg https://pic.netbian.com/uploads/allimg/191220/231329-15768548099602.jpg
......
前面出現亂碼 ----原因?
分析發現:原始頁面編碼是gbk <meta charset="gbk">
解決辦法:
方法一:
我們可以手動設定回應資料,使得VSCODE編碼和回應資料編碼相同
response = requests.get(url=url,headers=headers)
# 可以手動設定回應資料編碼格式
response.encoding = 'utf-8'
page_text = response.text
結果:可能起作用
因為:資料有些可以是直接手動修改的,有些則不能直接編碼的
結果發現仍然存在亂碼,但是另一方面也證明了設定編碼格式是生效的
方法二:
哪一塊發生了亂碼則單獨對這一塊進行編碼
# 通用處理中文亂碼的方案
img_name = img_name.encode('iso-8859-1').decode("gbk")
- 設定了回應資料編碼后的結果:
- 設定通用處理方法后的結果:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/279593.html
標籤:python
上一篇:python3 + opencv +pyzbar實時檢測二維碼 / 定位二維碼,并繪制出二維碼的框和提取二維碼內容
下一篇:LeetCode:鏈表(1)