一、requests庫
1、requests簡介
requests庫就是一個發起請求的第三方庫,requests允許你發送HTTP/1.1 請求,你不需要手動為 URL 添加查詢字串,也不需要對 POST 資料進行表單編碼,Keep-alive 和 HTTP 連接池的功能是 100% 自動化的,一切動力都來自于根植在 requests 內部的 urllib3,簡單來說有了這個庫,我們就能輕而易舉向對應的網站發起請求,從而對網頁資料進行獲取,還可以獲取服務器回傳的回應內容和狀態碼,
requesets中文檔案頁面https://requests.kennethreitz.org/zh_CN/latest/
2、安裝requests庫
一般電腦安裝的Python都會自帶這個庫,如果沒有就可在命令列輸入下面這行代碼安裝
pip install requests
3、使用requests獲取網頁資料
- 我們先匯入模塊
import requests
- 對想要獲取資料的網站發起請求,以下以qq音樂官網為例
res = requests.get('https://y.qq.com/') #發起請求
print(res) #輸出<Response [200]>
輸出的200其實就是一個回應狀態碼,下面給大家列出有可能回傳的各狀態碼含義
| 狀態碼 | 含義 |
|---|---|
| 1xx | 繼續發送資訊 |
| 2xx | 請求成功 |
| 3xx | 重定向 |
| 4xx | 客戶端錯誤 |
| 5xx | 服務端錯誤 |
- 獲取qq音樂首頁的網頁源代碼
res = requests.get('https://y.qq.com/') #發起請求
print(res.text) #res.text就是網頁的源代碼
4、總結requests的一些方法
| 屬性 | 含義 |
|---|---|
| res.status_code | HTTP的狀態碼 |
| res.text | 回應內容的文本 |
| res.content | 回應內容的二進制形式文本 |
| res.encoding | 回應內容的編碼 |
既然我們學好了如何獲取網頁源代碼,接下來我們就學習下怎么用BeautifulSoup庫對我們獲取的內容進行提取,
二、BeautifulSoup庫
1、BeautifulSoup簡介
BeautifulSoup是Python里的第三方庫,處理資料十分實用,有了這個庫,我們就可以根據網頁源代碼里對應的HTML標簽對資料進行有目的性的提取,BeautifulSoup庫一般與requests庫搭配使用, 不熟的HTML標簽的最好去百度下,了解一些常用的標簽,
2、安裝BeautifulSoup庫
同樣的如果沒用這個庫,可以通過命令列輸入下列代碼安裝
pip install beautifulsoup4
3、使用BeautifulSoup決議并提取獲取的資料
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一種反爬蟲措施
soup = BeautifulSoup(res.text,'html.parser') #第一個引數是HTML文本,第二個引數html.parser是Python內置的編譯器
print(soup) #輸出qq音樂首頁的源代碼
部分輸出結果↓
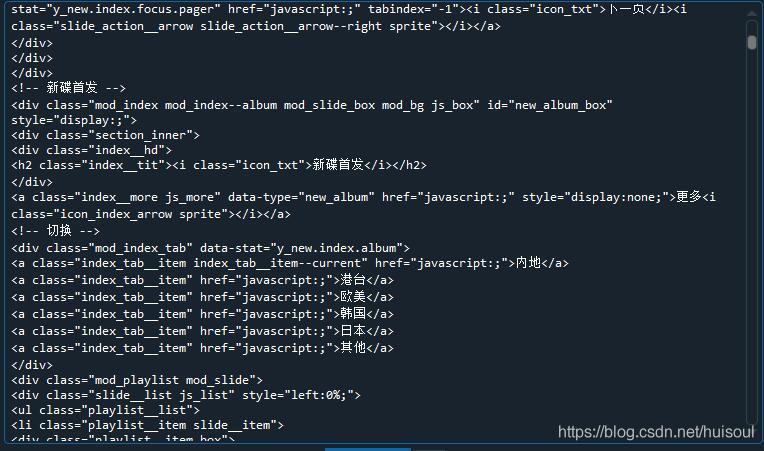
看到輸出結果,我們已經成功將網頁源代碼決議成BeautifulSoup物件,這時可能有人就會問res.text輸出的不就是網頁代碼了嗎,何苦再將它轉為BeautifulSoup物件呢?
我們先來通過type()函式看下它們的型別↓
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一種反爬蟲措施
soup = BeautifulSoup(res.text,'html.parser') #第一個引數是HTML文本,第二個引數html.parser是Python內置的編譯器
print(type(res.text))
print(type(soup))
輸出結果↓
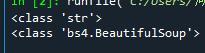
我們可以看到res.text的型別是字串型別,而soup則是BeautifulSoup物件型別,相比于res.text的字串型別,soup的BeautifulSoup物件型別擁有著更多可用的方法,以便我們快速提取出需要的資料,這就是為什么我們要多此一步了,
4、BeautifulSoup提取資料的方法
- 先來了解兩個最常用的方法↓
| 方法 | 作用 |
|---|---|
| find() | 回傳第一個符合要求的資料 |
| find_all() | 回傳所有符合要求的資料 |
這兩個函式傳入的引數就是我們對資料的篩選條件了,我們可以向這兩個函式分別傳入什么引數呢?
我們以下面在qq音樂首頁截取的源代碼片段為例,試用兩個函式
<div class="index__hd">
<h2 class="index__tit"><i class="icon_txt">歌單推薦</i></h2>
</div>
<!-- 切換 -->
<div class="mod_index_tab" data-stat="y_new.index.playlist">
<a href="javascript:;" class="index_tab__item index_tab__item--current js_tag" data-index="0" data-type="recomPlaylist" data-id="1">為你推薦</a>
<a href="javascript:;" class="index_tab__item js_tag" data-type="playlist" data-id="3056">網路歌曲</a>
<a href="javascript:;" class="index_tab__item js_tag" data-type="playlist" data-id="3256">綜藝</a>
<a href="javascript:;" class="index_tab__item js_tag" data-type="playlist" data-id="59">經典</a>
<a href="javascript:;" class="index_tab__item js_tag" data-type="playlist" data-id="3317">官方歌單</a>
<a href="javascript:;" class="index_tab__item js_tag" data-type="playlist" data-id="71">情歌</a>
</div>
- find()函式
如果想要獲取歌單推薦這一行的內容,我們就需要先對歌單推薦的HTML標簽進行識別,我們發現它在class="icon_txt"的i標簽下,接著就可以通過以下這種方法進行提取
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一種反爬蟲措施
soup = BeautifulSoup(res.text,'html.parser') #第一個引數是HTML文本,第二個引數html.parser是Python內置的編譯器
print(soup.find('i', class_='icon_txt')) #找到 class_='icon_txt'的 i 標簽
因為 class 是 Python 中定義類的關鍵字,所以用 class_ 表示 HTML 中的 class
輸出結果↓

- find_all()函式
如果我們想要把歌單推薦的全部主題提取下來的話,就要用到find_all()函式
同樣的,我們發現這幾個主題都在 class="index_tab__item js_tag"的 a標簽下,這時為了避免篩選到源代碼中其他同為class="index_tab__item js_tag"的標簽,我們需要再加多一個條件data-type=“playlist”,具體怎么操作呢?
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一種反爬蟲措施
soup = BeautifulSoup(res.text,'html.parser') #第一個引數是HTML文本,第二個引數html.parser是Python內置的編譯器
print(soup.find('i', class_='icon_txt'))
items = soup.find_all('a',attrs={"class" :"index_tab__item js_tag","data-type":"playlist"})
實作的方法就是在第二個引數處傳入一個鍵值對,在里面添加篩選的屬性
輸出結果↓

通過上面兩個小案例,我們發現find()和find_all()函式回傳的是Tag物件和Tag物件組成的串列,而我們需要的并不是這一大串東西,我們需要的只是Tag物件的text屬性或者href(鏈接)屬性,實作代碼如↓
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一種反爬蟲措施
soup = BeautifulSoup(res.text,'html.parser') #第一個引數是HTML文本,第二個引數html.parser是Python內置的編譯器
tag1=soup.find('i', class_='icon_txt')
print(tag1.text)
items = soup.find_all('a',attrs={"class" :"index_tab__item js_tag","data-type":"playlist"})
for i in items: #遍歷串列
tag2=i.text
print(tag2)
輸出結果↓
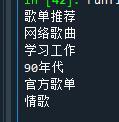
這樣我們就成功把主題的文本內容獲取了,而想要提取標簽中的屬性值,則可以用物件名[‘屬性’]的方法獲取,這里就不演示了
本次分享就到這里了,在下次介紹完反爬蟲和如何將資料寫進檔案的方法后,我會結合我所寫的三篇文章的方法來做一個爬取求職網的實體跟大家分享,有興趣的可以看下,謝謝大家!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/279802.html
標籤:python
上一篇:Unet如何制作自己的訓練集