2017年NBA資料分析
- 前言
- 獲取資料
- 資料分析
- 資料相關性
- 基本資料排名分析
- Seaborn常用的三個資料可視化方法
- 單變數:
- 雙變數
- 多變數
- 衍生變數的一些可視化實踐-以年齡為例
- 球隊資料分析
- 球隊薪資排行
- 按照球隊綜合實力排名
- 利用箱線圖和小提琴圖進行資料分析
前言
原始資料可以通過我分享的資源獲取
NBA–2017年資料表
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
獲取資料
data = pd.read_csv("./data/nba_2017_nba_players_with_salary.csv")
data.head()
data.shape
(342, 38)
# 粗略觀察資料的各個統計值
data.describe()
| Rk | AGE | MP | FG | FGA | FG% | 3P | 3PA | 3P% | 2P | ... | GP | MPG | ORPM | DRPM | RPM | WINS_RPM | PIE | PACE | W | SALARY_MILLIONS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 320.000000 | 342.000000 | ... | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 | 342.000000 |
| mean | 217.269006 | 26.444444 | 21.572515 | 3.483626 | 7.725439 | 0.446096 | 0.865789 | 2.440058 | 0.307016 | 2.620175 | ... | 58.198830 | 21.572807 | -0.676023 | -0.005789 | -0.681813 | 2.861725 | 9.186842 | 98.341053 | 28.950292 | 7.294006 |
| std | 136.403138 | 4.295686 | 8.804018 | 2.200872 | 4.646933 | 0.078992 | 0.780010 | 2.021716 | 0.134691 | 1.828714 | ... | 22.282015 | 8.804121 | 2.063237 | 1.614293 | 2.522014 | 3.880914 | 3.585475 | 2.870091 | 14.603876 | 6.516326 |
| min | 1.000000 | 19.000000 | 2.200000 | 0.000000 | 0.800000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 2.000000 | 2.200000 | -4.430000 | -3.920000 | -6.600000 | -2.320000 | -1.600000 | 87.460000 | 0.000000 | 0.030000 |
| 25% | 100.250000 | 23.000000 | 15.025000 | 1.800000 | 4.225000 | 0.402250 | 0.200000 | 0.800000 | 0.280250 | 1.200000 | ... | 43.500000 | 15.025000 | -2.147500 | -1.222500 | -2.422500 | 0.102500 | 7.100000 | 96.850000 | 19.000000 | 2.185000 |
| 50% | 205.500000 | 26.000000 | 21.650000 | 3.000000 | 6.700000 | 0.442000 | 0.700000 | 2.200000 | 0.340500 | 2.200000 | ... | 66.000000 | 21.650000 | -0.990000 | -0.130000 | -1.170000 | 1.410000 | 8.700000 | 98.205000 | 29.000000 | 4.920000 |
| 75% | 327.750000 | 29.000000 | 29.075000 | 4.700000 | 10.400000 | 0.481000 | 1.400000 | 3.600000 | 0.373500 | 3.700000 | ... | 76.000000 | 29.075000 | 0.257500 | 1.067500 | 0.865000 | 4.487500 | 10.900000 | 100.060000 | 39.000000 | 11.110000 |
| max | 482.000000 | 40.000000 | 37.800000 | 10.300000 | 24.000000 | 0.750000 | 4.100000 | 10.000000 | 1.000000 | 9.700000 | ... | 82.000000 | 37.800000 | 7.270000 | 6.020000 | 8.420000 | 20.430000 | 23.000000 | 109.870000 | 66.000000 | 30.960000 |
8 rows × 35 columns
資料分析
資料相關性
data_cor = data.loc[:, ['RPM', 'AGE', 'SALARY_MILLIONS', 'ORB',
'DRB', 'TRB','AST', 'STL',
'BLK', 'TOV', 'PF',
'POINTS', 'GP', 'MPG', 'ORPM', 'DRPM']]
data_cor.head()
| RPM | AGE | SALARY_MILLIONS | ORB | DRB | TRB | AST | STL | BLK | TOV | PF | POINTS | GP | MPG | ORPM | DRPM | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6.27 | 28 | 26.50 | 1.7 | 9.0 | 10.7 | 10.4 | 1.6 | 0.4 | 5.4 | 2.3 | 31.6 | 81 | 34.6 | 6.74 | -0.47 |
| 1 | 4.81 | 27 | 26.50 | 1.2 | 7.0 | 8.1 | 11.2 | 1.5 | 0.5 | 5.7 | 2.7 | 29.1 | 81 | 36.4 | 6.38 | -1.57 |
| 2 | 1.83 | 27 | 6.59 | 0.6 | 2.1 | 2.7 | 5.9 | 0.9 | 0.2 | 2.8 | 2.2 | 28.9 | 76 | 33.8 | 5.72 | -3.89 |
| 3 | 4.35 | 23 | 22.12 | 2.3 | 9.5 | 11.8 | 2.1 | 1.3 | 2.2 | 2.4 | 2.2 | 28.0 | 75 | 36.1 | 0.45 | 3.90 |
| 4 | 4.20 | 26 | 16.96 | 2.1 | 8.9 | 11.0 | 4.6 | 1.4 | 1.3 | 3.7 | 3.9 | 27.0 | 72 | 34.2 | 3.56 | 0.64 |
# 獲取兩列資料之間的相關性
corr = data_cor.corr()
corr.head()
| RPM | AGE | SALARY_MILLIONS | ORB | DRB | TRB | AST | STL | BLK | TOV | PF | POINTS | GP | MPG | ORPM | DRPM | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RPM | 1.000000 | 0.175820 | 0.477542 | 0.388764 | 0.623515 | 0.587853 | 0.481971 | 0.599008 | 0.463097 | 0.492014 | 0.434226 | 0.604432 | 0.340810 | 0.549449 | 0.769822 | 0.578388 |
| AGE | 0.175820 | 1.000000 | 0.353312 | -0.015752 | 0.088859 | 0.062064 | 0.114908 | 0.069892 | -0.062917 | 0.030673 | 0.005512 | 0.031422 | 0.051863 | 0.099657 | 0.136177 | 0.100636 |
| SALARY_MILLIONS | 0.477542 | 0.353312 | 1.000000 | 0.264954 | 0.531569 | 0.482088 | 0.486159 | 0.446763 | 0.260288 | 0.536993 | 0.341512 | 0.635425 | 0.348093 | 0.594162 | 0.503682 | 0.102307 |
| ORB | 0.388764 | -0.015752 | 0.264954 | 1.000000 | 0.731345 | 0.861103 | -0.011632 | 0.169075 | 0.654265 | 0.274670 | 0.557957 | 0.284908 | 0.296975 | 0.342140 | 0.102113 | 0.476857 |
| DRB | 0.623515 | 0.088859 | 0.531569 | 0.731345 | 1.000000 | 0.976244 | 0.350786 | 0.485726 | 0.660733 | 0.598043 | 0.670708 | 0.648267 | 0.473376 | 0.684662 | 0.428433 | 0.426536 |
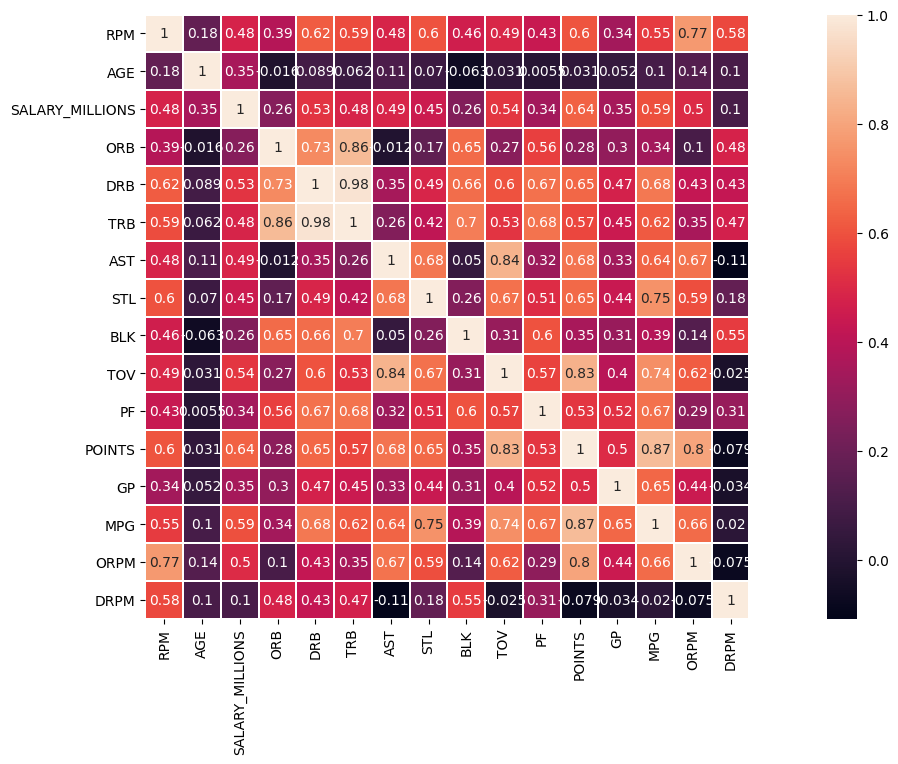
# 創建畫布
plt.figure(figsize=(20, 8), dpi=100)
# 畫出相關性熱圖
# param1: 資料
# param2; 正方形
# param3: 線寬
# param4: 顯示值
sns.heatmap(corr, square=True, linewidths=0.1, annot=True)
基本資料排名分析
# 按照效率值排名
data.loc[:, ["PLAYER", "RPM",
"AGE"]].sort_values(by="RPM", ascending=False).head()
| PLAYER | RPM | AGE | |
|---|---|---|---|
| 6 | LeBron James | 8.42 | 32 |
| 37 | Chris Paul | 7.92 | 31 |
| 8 | Stephen Curry | 7.41 | 28 |
| 120 | Draymond Green | 7.14 | 26 |
| 7 | Kawhi Leonard | 7.08 | 25 |
# 按照球員薪資排名
data.loc[:, ["PLAYER", "RPM", "AGE",
"SALARY_MILLIONS"]].sort_values(by="SALARY_MILLIONS",
ascending=False).head()
| PLAYER | RPM | AGE | SALARY_MILLIONS | |
|---|---|---|---|---|
| 6 | LeBron James | 8.42 | 32 | 30.96 |
| 25 | Mike Conley | 4.47 | 29 | 26.54 |
| 67 | Al Horford | 1.82 | 30 | 26.54 |
| 0 | Russell Westbrook | 6.27 | 28 | 26.50 |
| 1 | James Harden | 4.81 | 27 | 26.50 |
Seaborn常用的三個資料可視化方法
單變數:
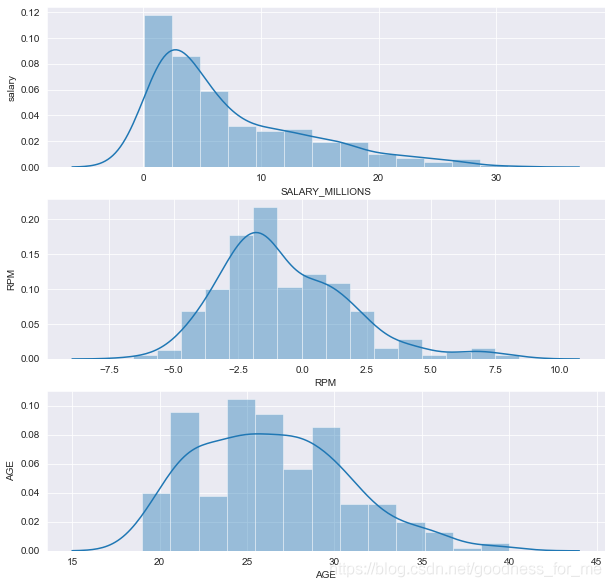
# 利用seaborn中的distplot繪圖來
#分別看一下球員薪水、效率值、年齡這三個資訊的分布情況
# 設定顯示風格
sns.set_style("darkgrid")
# 設定畫布
plt.figure(figsize=(10, 10))
# 分割螢屏 -- 薪水
plt.subplot(3, 1, 1)
sns.distplot(data["SALARY_MILLIONS"])
plt.ylabel("salary")
# 分割螢屏 -- 效率值(真實貢獻值)
plt.subplot(3, 1, 2)
sns.distplot(data["RPM"])
plt.ylabel("RPM")
# 分割螢屏 -- 年齡
plt.subplot(3, 1, 3)
sns.distplot(data["AGE"])
plt.ylabel("AGE")
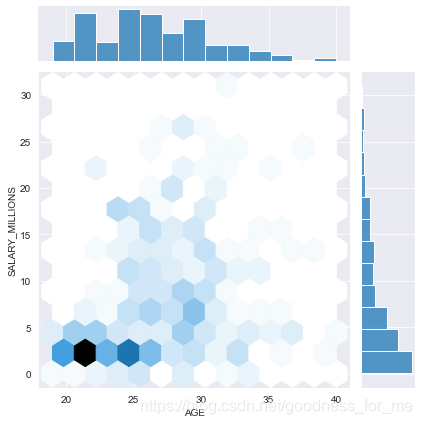
雙變數
sns.jointplot(data.AGE, data.SALARY_MILLIONS, kind="hex")
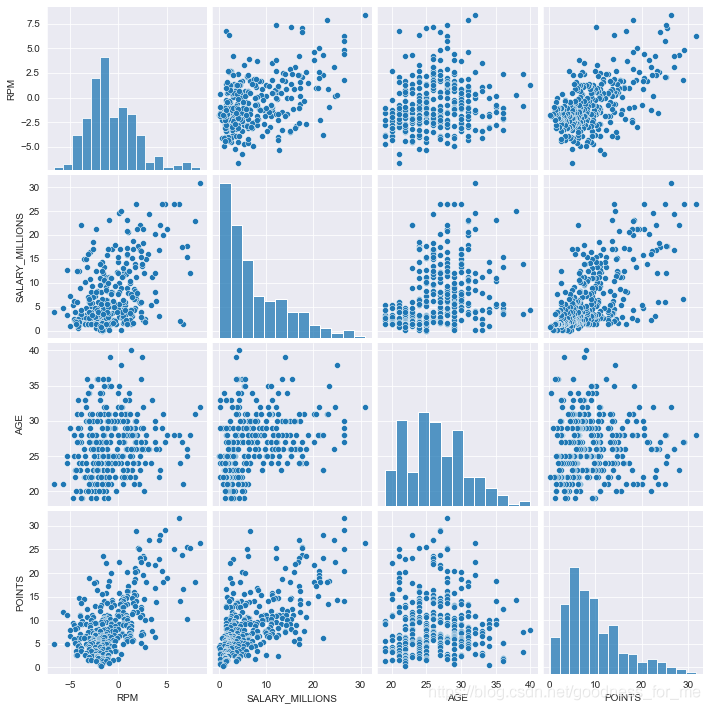
多變數
multi_data = data.loc[:, ['RPM','SALARY_MILLIONS','AGE','POINTS']]
multi_data.head()
| RPM | SALARY_MILLIONS | AGE | POINTS | |
|---|---|---|---|---|
| 0 | 6.27 | 26.50 | 28 | 31.6 |
| 1 | 4.81 | 26.50 | 27 | 29.1 |
| 2 | 1.83 | 6.59 | 27 | 28.9 |
| 3 | 4.35 | 22.12 | 23 | 28.0 |
| 4 | 4.20 | 16.96 | 26 | 27.0 |
# 多變數兩兩做一個表
sns.pairplot(multi_data)
衍生變數的一些可視化實踐-以年齡為例
def age_cut(df):
"""年齡劃分"""
if df.AGE <= 24:
return "young"
elif df.AGE >= 30:
return "old"
else:
return "best"
# 使用apply對年齡進行劃分
# 函式作為一個物件,能作為引數傳遞給其它引數,并且能作為函式的回傳值
# 回圈data的每一個值, 帶入age_cut求值, 得到的結果賦給age_cut colunm
data["age_cut"] = data.apply(lambda x:age_cut(x), axis=1)
data.head()
| Rk | PLAYER | POSITION | AGE | MP | FG | FGA | FG% | 3P | 3PA | ... | MPG | ORPM | DRPM | RPM | WINS_RPM | PIE | PACE | W | SALARY_MILLIONS | age_cut | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Russell Westbrook | PG | 28 | 34.6 | 10.2 | 24.0 | 0.425 | 2.5 | 7.2 | ... | 34.6 | 6.74 | -0.47 | 6.27 | 17.34 | 23.0 | 102.31 | 46 | 26.50 | best |
| 1 | 2 | James Harden | PG | 27 | 36.4 | 8.3 | 18.9 | 0.440 | 3.2 | 9.3 | ... | 36.4 | 6.38 | -1.57 | 4.81 | 15.54 | 19.0 | 102.98 | 54 | 26.50 | best |
| 2 | 3 | Isaiah Thomas | PG | 27 | 33.8 | 9.0 | 19.4 | 0.463 | 3.2 | 8.5 | ... | 33.8 | 5.72 | -3.89 | 1.83 | 8.19 | 16.1 | 99.84 | 51 | 6.59 | best |
| 3 | 4 | Anthony Davis | C | 23 | 36.1 | 10.3 | 20.3 | 0.505 | 0.5 | 1.8 | ... | 36.1 | 0.45 | 3.90 | 4.35 | 12.81 | 19.2 | 100.19 | 31 | 22.12 | young |
| 4 | 6 | DeMarcus Cousins | C | 26 | 34.2 | 9.0 | 19.9 | 0.452 | 1.8 | 5.0 | ... | 34.2 | 3.56 | 0.64 | 4.20 | 11.26 | 17.8 | 97.11 | 30 | 16.96 | best |
5 rows × 39 columns
# 方便計數
data["cut"] = 1
data.loc[data.age_cut == "best"].SALARY_MILLIONS.head()
0 26.50
1 26.50
2 6.59
4 16.96
5 24.33
Name: SALARY_MILLIONS, dtype: float64
# 基于年齡段對球員薪水和效率值進行分析
sns.set_style("darkgrid")
plt.figure(figsize=(10,10), dpi=100)
plt.title("RPM and Salary")
x1 = data.loc[data.age_cut == "old"].SALARY_MILLIONS
y1 = data.loc[data.age_cut == "old"].RPM
plt.plot(x1, y1, "^")
x2 = data.loc[data.age_cut == "best"].SALARY_MILLIONS
y2 = data.loc[data.age_cut == "best"].RPM
plt.plot(x2, y2, "^")
x3 = data.loc[data.age_cut == "young"].SALARY_MILLIONS
y3 = data.loc[data.age_cut == "young"].RPM
plt.plot(x3, y3, ".")
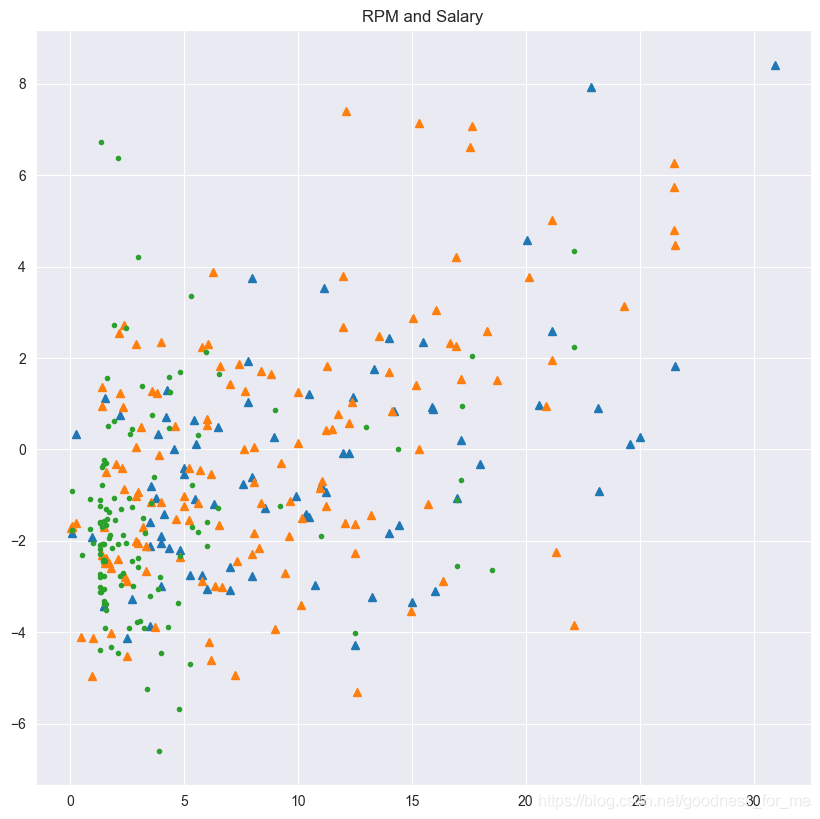
# 取出多個變數畫圖
multi_data2 = data.loc[:, ['RPM','POINTS',
'TRB','AST','STL','BLK','age_cut']]
# 用hue來指定對應colunm所有取值中每一種對應的顏色
sns.pairplot(multi_data2, hue="age_cut")
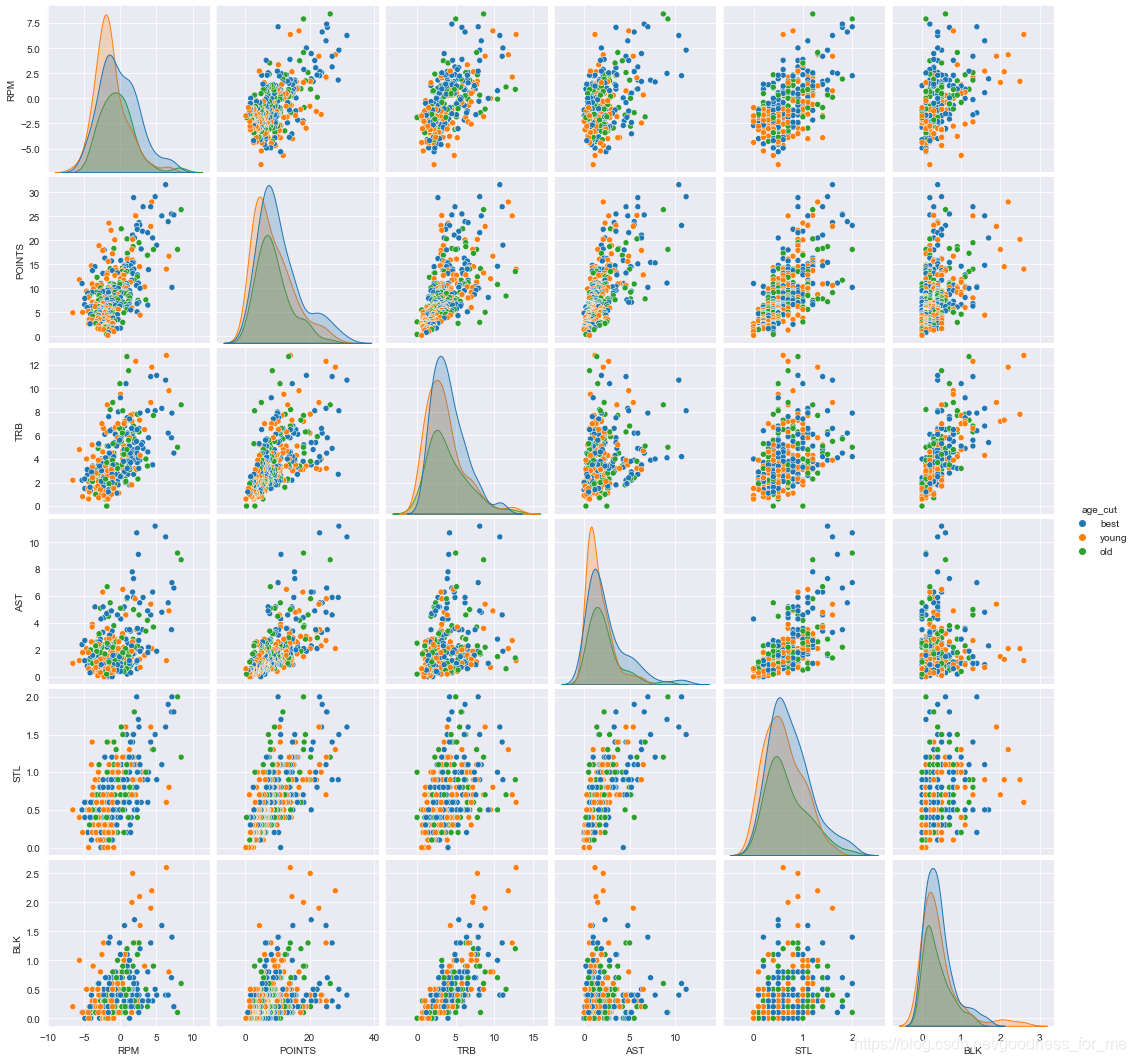
球隊資料分析
球隊薪資排行
# .agg() 聚合方法 -- 字典
data.groupby(by="age_cut").agg({"SALARY_MILLIONS":np.max})
| SALARY_MILLIONS | |
|---|---|
| age_cut | |
| best | 26.54 |
| old | 30.96 |
| young | 22.12 |
# 按照球隊進行分類
data_team = data.groupby(by="TEAM").agg({"SALARY_MILLIONS":np.mean})
# 按照薪資進行分類, 降序排列
data_team.sort_values(by="SALARY_MILLIONS",
ascending=False).head(10)
| SALARY_MILLIONS | |
|---|---|
| TEAM | |
| CLE | 17.095000 |
| HOU | 13.432000 |
| GS | 12.701429 |
| ORL/TOR | 11.125000 |
| POR | 9.730000 |
| WSH | 9.628889 |
| ORL | 9.490000 |
| MIL/CHA | 9.425000 |
| SA | 9.347273 |
| NO/SAC | 8.970000 |
# 按照分球隊分年齡段,上榜球員降序排列,
# 如上榜球員數相同,則按效率值降序排列,
data_rpm = data.groupby(by=["TEAM",
"age_cut"]).agg({"SALARY_MILLIONS": np.mean,
"RPM": np.mean, "PLAYER": np.size})
data_rpm.sort_values(by=["PLAYER", "RPM"], ascending=False).head()
data_rpm.head()
| SALARY_MILLIONS | RPM | PLAYER | ||
|---|---|---|---|---|
| TEAM | age_cut | |||
| ATL | best | 4.678000 | -1.768000 | 5 |
| old | 12.775000 | 0.982500 | 4 | |
| young | 1.926667 | -3.076667 | 3 | |
| ATL/CLE | old | 5.040000 | -2.485000 | 2 |
| ATL/PHI/OKC | best | 8.400000 | 1.720000 | 1 |
按照球隊綜合實力排名
data_rpm2 = data.groupby(by=['TEAM'],
as_index=False).agg({'SALARY_MILLIONS': np.mean,
'RPM': np.mean,
'PLAYER': np.size,
'POINTS': np.mean,
'eFG%': np.mean,
'MPG': np.mean,
'AGE': np.mean})
data_rpm2.head()
| TEAM | SALARY_MILLIONS | RPM | PLAYER | POINTS | eFG% | MPG | AGE | |
|---|---|---|---|---|---|---|---|---|
| 0 | ATL | 6.689167 | -1.178333 | 12 | 7.416667 | 0.442667 | 18.541667 | 27.000000 |
| 1 | ATL/CLE | 5.040000 | -2.485000 | 2 | 7.650000 | 0.582000 | 21.050000 | 35.500000 |
| 2 | ATL/PHI/OKC | 8.400000 | 1.720000 | 1 | 13.100000 | 0.511000 | 26.100000 | 29.000000 |
| 3 | BKN | 5.704545 | -1.224545 | 11 | 9.045455 | 0.487273 | 20.227273 | 27.636364 |
| 4 | BKN/WSH | 4.910000 | -4.045000 | 2 | 8.150000 | 0.470000 | 17.350000 | 27.000000 |
# 按照效率值降序排列
data_rpm2.sort_values(by="RPM", ascending=False).head()
| TEAM | SALARY_MILLIONS | RPM | PLAYER | POINTS | eFG% | MPG | AGE | |
|---|---|---|---|---|---|---|---|---|
| 18 | GS | 12.701429 | 3.478571 | 7 | 14.528571 | 0.575143 | 26.700000 | 28.714286 |
| 9 | CLE | 17.095000 | 2.566667 | 6 | 15.883333 | 0.555833 | 29.766667 | 28.000000 |
| 2 | ATL/PHI/OKC | 8.400000 | 1.720000 | 1 | 13.100000 | 0.511000 | 26.100000 | 29.000000 |
| 20 | HOU | 13.432000 | 1.582000 | 5 | 15.420000 | 0.534600 | 29.980000 | 27.200000 |
| 44 | SA | 9.347273 | 0.901818 | 11 | 9.818182 | 0.524182 | 21.472727 | 29.545455 |
利用箱線圖和小提琴圖進行資料分析
# 篩選資料
data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC',
'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS']).head()
0 True
1 False
2 True
3 True
4 False
Name: TEAM, dtype: bool
# 箱線圖
#設定圖片背景
sns.set_style("whitegrid")
plt.figure(figsize=(20, 10))
# 獲取需要的資料
data_team2 = data[data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC',
'OKC', 'UTAH', 'CHA',
'TOR', 'NO', 'BOS'])]
# 進行相應的繪圖\
# 年薪
plt.subplot(3,1,1)
sns.boxplot(x="TEAM", y="SALARY_MILLIONS", data = data_team2)
# 年齡
plt.subplot(3,1,2)
sns.boxplot(x="TEAM", y="AGE", data = data_team2)
# 場均上場時間
plt.subplot(3,1,3)
sns.boxplot(x="TEAM", y="MPG", data = data_team2)
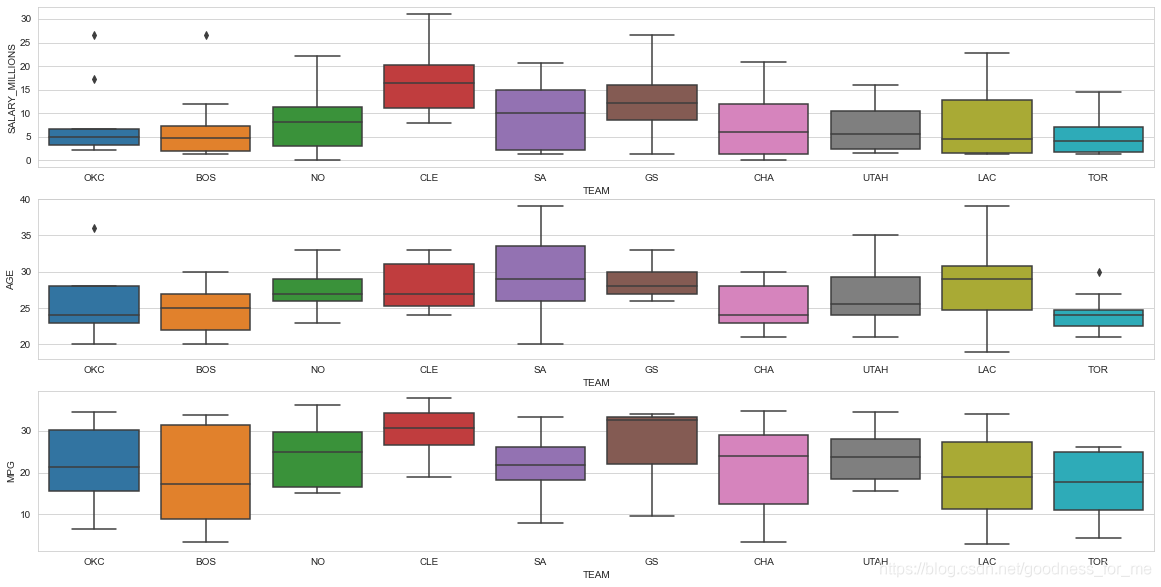
# 繪制小提琴圖
# 設定圖背景
sns.set_style("whitegrid")
plt.figure(figsize=(20, 10))
# 三分命中率
plt.subplot(3,1,1)
sns.violinplot(x="TEAM", y="3P%", data=data_team2)
# 有效命中率
plt.subplot(3,1,2)
sns.violinplot(x="TEAM", y="eFG%", data=data_team2)
# 得分
plt.subplot(3,1,3)
sns.violinplot(x="TEAM", y="POINTS", data=data_team2)
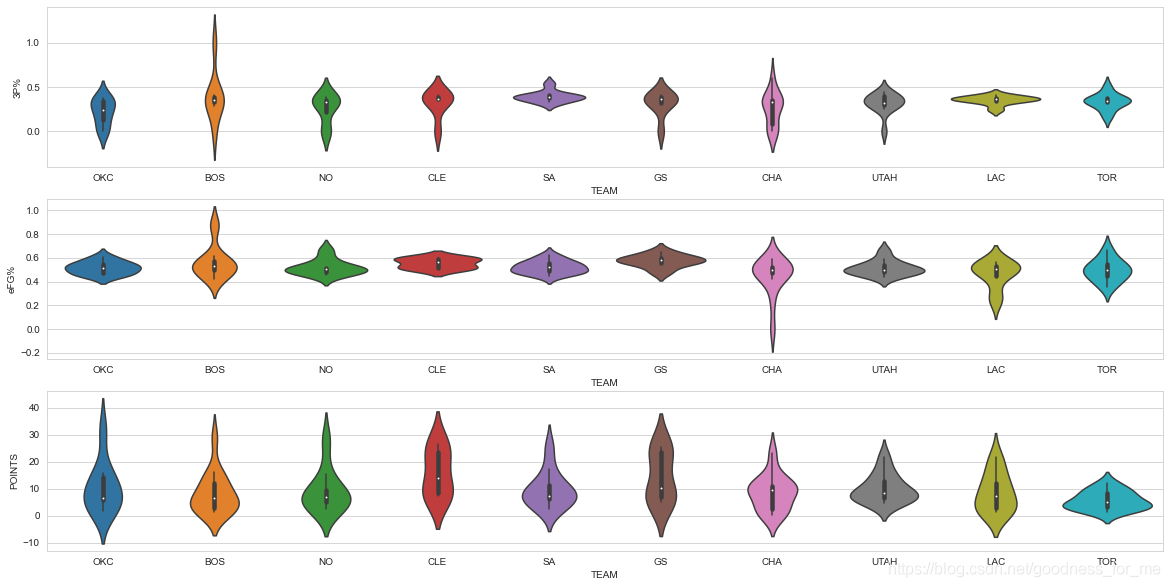
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/279807.html
標籤:python
下一篇:LeetCode:鏈表(2)