目錄
- 一、pandas、python、numpy資料型別對應關系
- 二、匯入初始化指定
- 三、pandas智能推斷
- 四、常見方法——型別轉換 astype()
- 五、通過創建自定義的函式進行資料轉化
- ①apply()應用自定義函式
- ②lambda函式
- ③簡單內置函式
- 六、pandas提供的轉換函式pd.to_numeric/pd.to_datatime
- ①pd.to_numeric()
- ②pd.to_datetime()
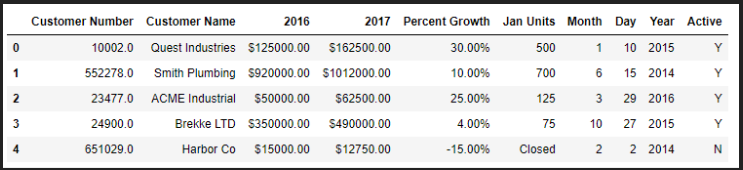
??不同的資料型別可以用不同的處理方法,合適的資料型別,才能更高效處理資料,一個列只能有一個總資料型別,但具體值可以是不同的資料型別,源Excel檔案pandas_dtypes.csv:

df = pd.read_csv(r"pandas_dtypes.csv")
df
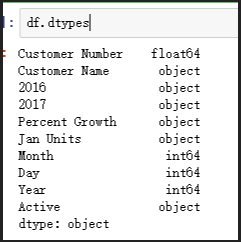
df.dtypes
# Customer Number 列是float64,然而應該是int64
# 2016 2017兩列的資料是object,并不是float64或者int64格式
# Percent以及Jan Units 也是objects而不是數字格式
# Month,Day以及Year應該轉化為datetime64[ns]格式
# Active 列應該是布林值
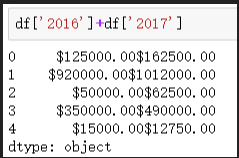
# 求2016和2017資料總和,兩列的資料型別為object,相加后不是想要的結果,而是得到一個更長的字串
df['2016']+df['2017']
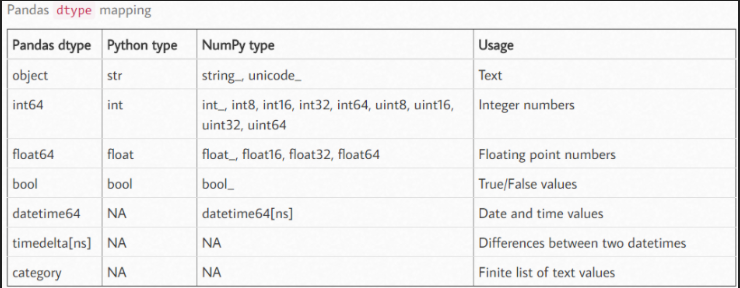
一、pandas、python、numpy資料型別對應關系
二、匯入初始化指定
# 一次性指定所有列為object
df = pd.read_csv(r"pandas_dtypes.csv",dtype='object')
# 每個欄位分別指定
df = pd.read_csv(r"pandas_dtypes.csv",dtype# ={'Customer Number': 'int64','Year':'int32'})
??有些欄位匯入時無法指定想要的資料,比如無法將’2016‘和’2017‘這兩列字符型資料直接指定為數值型資料,必須經過一定的加工處理后才可以轉換(把$符號去掉),
??默認的資料型別是 int64 和 float64,文字型別是 object,
三、pandas智能推斷
??再匯入時,假若未指定資料型別,pandas會根據資料情況選擇合適的默認資料型別,避免資料發生缺失,匯入后,也可以通過一些函式,智能推斷,
# 自動轉換合適的資料型別
df.convert_dtypes()
df.infer_objects()
四、常見方法——型別轉換 astype()
# 想要真正改變原始資料框,通常需要通過賦值來進行
df['Customer Number'] = df['Customer Number'].astype('int')
??像2016,2017 Percent Growth,Jan Units 這幾列帶有特殊符號的object是不能直接通過astype('flaot')方法進行轉化的,這與python中的字串轉化為浮點數,都要求原始的字符都只能含有數字本身,不能含有其他的特殊字符,
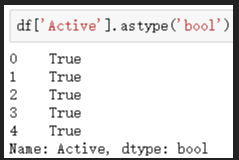
# 將Active列轉化為布林值,五個結果全是True,不是想要的結果
df['Active'].astype('bool')
# 2016列中含有特殊字符$,無法直接轉換,直接報錯
df['2016'].astype('float')

astype()總結:
- 如果資料是純凈的資料,可以轉化為數字
- astype基本也就是兩種用作,數字轉化為單純字串,單純數字的字串轉化為數字,含有其他的非數字的字串是不能通過astype進行轉化的,
- 需要引入其他的方法進行轉化,自定義函式方法
五、通過創建自定義的函式進行資料轉化
①apply()應用自定義函式
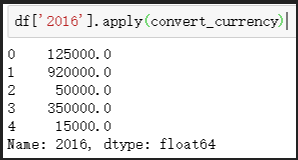
# 通過replace函式將$去掉,然后字串轉化為浮點數,讓pandas選擇pandas認為合適的特定型別,float或者int,該例子中將資料轉化為了float64
# 通過pandas中的apply函式將2016列中的資料全部轉化
def convert_currency(var):
'''
convert the string number to a float
- 去除$
- 轉化為浮點數型別
'''
new_value = https://www.cnblogs.com/xiaoshun-mjj/p/var.replace('$','')
return float(new_value)
df['2016'].apply(convert_currency)
②lambda函式
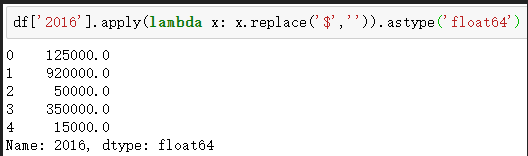
# 通過lambda 函式將這個比較簡單的函式一行帶過
df['2016'].apply(lambda x: x.replace('$','')).astype('float64')
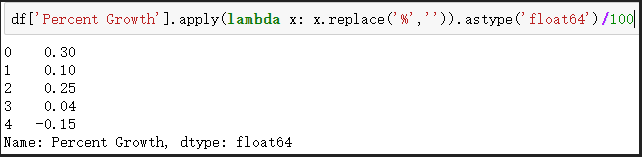
# 同樣的,利用lambda運算式將PercentGrowth進行資料清理
df['Percent Growth'].apply(lambda x: x.replace('%','')).astype('float64')/100
③簡單內置函式
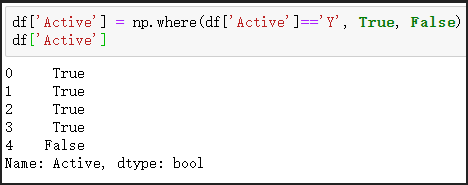
# 利用np.where() function 將Active 列轉化為布林值
df['Active'] = np.where(df['Active']=='Y', True, False)
六、pandas提供的轉換函式pd.to_numeric/pd.to_datatime
①pd.to_numeric()
pd.to_numeric()官方檔案
pd.to_numeric(arg,errors = 'raise',downcast = None)
功能:將arg轉換為數字型別,默認回傳dtype為float64或int64,
引數說明:
- arg:標量,串列,元組,一維陣列或系列,
- errors :{'ignore','raise','coerce'},默認為'raise'
“ raise”,則無效的決議將引發例外,
“coerce”,則無效決議將設定為NaN,
“ ignore”,則無效的決議將回傳輸入 - downcast {'integer','signed','unsigned','float'},默認值none,控制回傳的dtype,
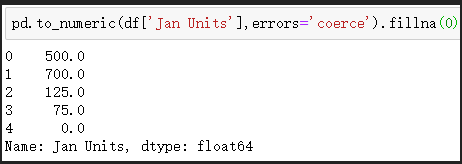
# pd.to_numeric()處理Jan Units中的資料
# 無效決議設定為NaN值,fillna()將NaN用0填充
pd.to_numeric(df['Jan Units'],errors='coerce').fillna(0)
②pd.to_datetime()
和時間序列資料有關:pd.to_datetime()官方檔案
# pd.to_datatime()將年月日進行合并
pd.to_datetime(df[['Month','Day','Year']])

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/280156.html
標籤:Python
上一篇:IDE 常用配置