Python網路爬蟲(一)爬蟲基礎
一、爬蟲基礎
1.HTTP基本原理
1.1URI和URL
URI,全稱:Uniform Resource Identifier,即統一資源標志符;URL,全稱:Universal Resource Locator,即統一資源定位符,
舉例來說,https://github.com/favicon.ico是GitHub的網站圖示鏈接,它是一個URL,也是一個URI,即有這樣一個圖示資源,我們用URL/URI來唯一指定它的訪問方式,這其中包括了訪問協議https、訪問路徑(/即根目錄)和資源名稱favicon.ico,通過這樣一個鏈接,我們便可以從互聯網上找到這個資源,這就是URL/URI,
URL是URI的子集,也就是說每個URL都是URI,但不是每個URI都是URL,URI包括一個子類叫做URN,它的全稱為Universal Resource Name,即統一資源名稱,URN只命名資源而不指定如何定位資源,比如urn:isbn:0451450523指定了一本書的ISBN,可以唯一標識這本書,但是沒有指定到哪里定位這本書,這就是URN,
但是在目前的互聯網中,URN用得非常少,所以幾乎所有的URI都是URL,一般的網頁鏈接我們既可以稱為URL,也可以稱為URI,
1.2超文本
超文本,其英文名稱叫作hypertext,我們在瀏覽器里看到的網頁就是超文本決議而成的,其網頁源代碼是一系列HTML代碼,里面包含了一系列標簽,比如img顯示圖片,p指定顯示段落等,瀏覽器決議這些標簽后,便形成了我們平常看到的網頁,而網頁的源代碼HTML就稱作超文本,
打開瀏覽器按F12,會彈出瀏覽器的開發者模式,在Elements選項卡就可以看到網頁的源代碼,即超文本

1.3HTTP和HTTPS
在淘寶的首頁,URL的開頭會有http或https,這就是訪問資源需要的協議型別,HTTP的全稱是Hyper Text Transfer Protocol,中文名叫做超文本傳輸協議,HTTP協議是從網路傳輸超文本資料到本地瀏覽器的傳送協議,它能保證高效而準確地傳送超文本檔案,HTTP由萬維網協會(World Wide Web Consortium)和Internet作業小組IETF(Internet Engineering Task Force)共同合作制定的規范,
HTTPS的全稱是Hyper Text Transfer Protocol over Secure Socket Layer,是以安全為目標的HTTP通道,簡單講是HTTP的安全版,即HTTP下加入SSL層,簡稱為HTTPS,
HTTPS的安全基礎是SSL,因此通過它傳輸的內容都是經過SSL加密的,它的主要作用是:
·建立一個資訊安全通道來保證資料傳輸的安全
·確認網站的真實性,凡是使用了HTTPS的網站,都可以通過點擊瀏覽器地址欄的鎖頭標志來查看網站認證之后的真實資訊,也可以通過CA機構頒發的安全簽章來查詢
1.4HTTP請求程序
我們在瀏覽器中輸入一個URL,回車之后便會在瀏覽器中觀察到頁面內容,實際上,這個程序是瀏覽器向網站所在的服務器發送了一個請求,網站服務器接收到這個請求后進行處理和決議,然后回傳對應的回應,接著傳回給瀏覽器,回應里包含了頁面源代碼等內容,瀏覽器再對其進行決議,便將網頁呈現了出來,
打開Chrome瀏覽器,右擊并選擇“檢查”項,即可打開瀏覽器的開發者工具,這里訪問百度http://www.baidu.com/,輸入該URL后回車,觀察這個程序中發生了怎樣的網路請求,可以看到,在Network頁面下方出現了一個個條目,其中一個條目就代表一次發送請求和接收回應的程序,如下圖所示
我們先觀察第一個網路請求,即www.baidu.com
其中各列的含義如下,
–第一列Name:請求的名稱,一般會將URL的最后一部分內容當作名稱
–第二列Status:回應的狀態碼,這里顯示為200,代表回應是正常的,通過狀態碼,我們可以判斷發送了請求之后是否得到了正常的回應
–第三列Type:請求的檔案型別,這里為document,代表我們這次請求的是一個HTML檔案,內容就是一些HTML檔案
–第四列Initiator:請求源:用來標記請求是由哪個物件或行程發起的
–第五列Size:從服務器下載的檔案和請求的資源大小,如果是從快取中取得的資源,則該列會顯示from cache
–第六列Time:發起請求到獲取回應所用的總時間
–第七列Waterfall:網路請求的可視化瀑布
點擊這個條目,即可看到更詳細的資訊,如下圖所示

首先是General部分,Request URL為請求的URL,Request Method為請求的方法,Status Code為狀態回應碼,Remote Address為遠程服務器的地址和埠,Referrer Policy為Referrer判別策略
再繼續往下,可以看到,有Response Headers和Request Headers,這分別代表回應和請求頭,請求頭里帶有許多請求資訊,例如瀏覽器標識、Cookies、Host等資訊,這是請求的一部分,服務器會根據請求頭內的資訊判斷請求是否合法,進而作出對應的回應,圖中看到的Response Headers就是回應的一部分,例如其中包含了服務器的型別、檔案型別、日期等資訊,瀏覽器接受到回應后,會決議回應內容,進而呈現網路內容,
1.1.5 請求
請求,由客戶端向服務端發出,可以分為4部分內容:請求方法(Request Method)、請求的網址(Request URL)、請求頭(Request Headers)、請求體(Request Body)
(1)請求方法
常見的請求方法有兩種:GET和POST
在瀏覽器中直接輸入URL并回車,這便發起了一個GET請求,請求的引數會直接包含到URL里,例如,在百度中搜索Python,這就是一個GET請求,鏈接為https://www.baidu.com/s?wd=Python,其中URL中包含了請求的引數資訊,這里引數wd表示要搜尋的關鍵字,POST請求大多在表單提交時發起,比如對于一個登錄表單,輸入用戶名和密碼之后,點擊“登錄”按鈕,通常會發起一個POST請求,其資料通常以表單的形式傳輸,而不會體現在URL中
GET和POST請求方法有如下區別:
·GET請求中的引數包含在URL里,資料可以在URL中看到,而POST請求的URL不會包含這些資料,資料都是通過表單形式傳輸,會包含在請求體中
·GEt請求提交的資料最多只有1024位元組,而POST方式沒有限制
一般來說,登錄時,需要提交用戶名和密碼,其中包含了敏感資訊,使用GET方式請求的話,密碼就會暴露在URL里,造成密碼泄露,所以最好使用POST發送,上傳檔案時,由于檔案內容比較大,也會選用POST方式
我們平常遇到的絕大部分請求都是GET或POST請求,另外還有一些請求方法,如HEAD、PUT、DELETE、OPTIONS、CONNECT、TRACE等
| 方法 | 描述 |
|---|---|
| GET | 請求頁面,并回傳內容 |
| HEAD | 類似于GET請求,只不過回傳的回應中沒有具體的內容,用于獲取報頭 |
| POST | 大多用于提交表單或上傳檔案,資料包含在請求中 |
| PUT | 從客戶端向服務器傳送的資料取代指定檔案中的內容 |
| DELETE | 請求服務器洗掉指定的頁面 |
| CONNECT | 把服務器當作跳板,讓服務器代替客戶端訪問其他網頁 |
| OPTIONS | 允許客戶端查看服務器的性能 |
| TRACE | 回顯服務器收到的請求,主要用于測驗或診斷 |
(2)請求的網址
請求的網址,即統一資源定位符URL,它可以唯一確定我們想請求的資源
(3)請求頭
請求頭,用來說明服務器要使用的附加資訊,比較重要的資訊有Cookie、Referrer、User-Agent等
–Accept:請求報頭域,用于指定客戶端可接受哪些型別的資訊
–Accept-Language:指定客戶端可接受的語言型別
–Accept-Encoding:指定客戶端可接受的內容編碼
–Host:用于指定請求資源的主機IP和埠號,其內容為請求URL的原始服務器或網關的位置,從HTTP1.1版本開始,請求必須包含此內容
–Cookie:也常用復數形式Cookies,這是網站為了辨別用戶進行會話跟蹤而存盤在用戶本地的資料,它的主要功能是維持當前會話,例如,我們輸入了用戶名和密碼成功登錄了某個網站后,服務器會用會話保存登錄狀態資訊,后面我們每次重繪或請求該站點的其他頁面時,會發現都是登錄狀態,這就是Cookies的功勞,Cookies里有資訊表示標識了我們所對應的服務器的會話,每次瀏覽器在請求該站點的頁面時,都會在請求頭中加上Cookies并將其發送給服務器,服務器通過Cookies識別出是我們自己,并且查出當前狀態是登錄狀態,所以回傳結果就是登錄之后才能看到的網頁內容
–Referer:此內容用來標識這個請求是從哪個頁面發過來的,服務器可以拿到這一資訊并做相應的處理,如做來源統計、防盜鏈處理等
–User-Agent:簡稱UA,它是一個特殊的字串頭,可以使服務器識別客戶使用的作業系統及版本、瀏覽器及版本等資訊,在做爬蟲時加上此資訊,可以偽裝為瀏覽器;如果不加,很可能會被識別出為爬蟲
–Content-Type:也叫互聯網媒體型別(Internet Media Type)或者MIME型別,在HTTP協議訊息頭中,它用來表示具體請求的媒體型別資訊,例如,text/html代表HTML格式,image/gif代表GIF圖片,application/json代表JSON型別,更多對應關系可以查看此對照表:https://tool.oschina.net/commons
因此,請求頭是請求的重要組成部分,在寫爬蟲時,大部分情況下都需要設定請求頭
(4)請求體
請求體一般承載的內容是POST請求中的表單資料,而對于GET請求,請求體則為空
例如,下圖是登錄GitHub時捕獲到的請求和相應

登錄之前,我們填寫了用戶名和密碼資訊,提交時這些內容就會以表單資料的形式提交給服務器,此時需要注意Request Headers中指定Content-Type為application/x-www-form-urlencoded,只有設定Content-Type設定為application/json來提交JSON資料,或設定為multipart/form-data來上傳檔案,
下表為Content-Type和POST提交資料方式的關系
| Content-Type | 提交資料的方式 |
|---|---|
| application/x-www-form-urlencoded | 表單資料 |
| multipart/form-data | 表單檔案上傳 |
| application/json | 序列化JSON資料 |
| text/xml | XML資料 |
在爬蟲時,如果要構造POST請求,需要使用正確的Content-Type,并了解各種請求庫的各個引數設定時使用的是哪種Content-Type,不然可能會導致POST提交后無法正常回應
1.1.6 回應
回應,由服務器回傳給客戶端,可以分為三部分:狀態回應碼(Response Status Code)、回應頭(Response Headers)和回應體(Response Body)
(1)回應狀態碼
回應狀態碼表示服務器的回應狀態,如200代表服務器正常回應,404代表頁面未找到,500代表服務器內部發生錯誤,在爬蟲中,我們可以根據狀態碼來判斷服務器回應狀態,如狀態碼200,則證明成功回傳資料,再進行進一步的處理,否則直接忽略,
常見的錯誤代碼及錯誤原因
| 狀態碼 | 說明 | 詳情 |
|---|---|---|
| 100 | 繼續 | 請求者應當繼續提出請求,服務器已收到請求的一部分,正在等待其他部分 |
| 101 | 切換協議 | 請求者已要求服務器切換協議,服務器已確認并準備切換 |
| 200 | 成功 | 服務器已成功處理了請求 |
| 201 | 已創建 | 請求成功并且服務器創建了新的資源 |
| 202 | 已接受 | 服務器已接受請求,但尚未處理 |
| 203 | 非授權資訊 | 服務器已成功處理了請求,但回傳的資訊可能來自另一個源 |
| 204 | 無內容 | 服務器成功處理了請求,但沒有回傳任何內容 |
| 205 | 重置內容 | 服務器成功處理了請求,內容被重置 |
| 206 | 部分內容 | 服務器成功處理了部分請求 |
| 300 | 多種選擇 | 針對請求,服務器可執行多種操作 |
| 301 | 永久移動 | 請求的網頁已永久移動到新位置,即永久重定向 |
| 302 | 臨時移動 | 請求的網頁暫時跳轉到其他頁面,即暫時重定向 |
| 303 | 查看其他位置 | 如果原來的請求是POST,重定向目標檔案應該通過GET提取 |
| 304 | 未修改 | 此次請求回傳的頁面未修改,繼續使用上次的資源 |
| 305 | 使用代理 | 請求者應該使用代理訪問該頁面 |
| 307 | 臨時重定向 | 請求的資源臨時從其他位置回應 |
| 400 | 錯誤請求 | 服務器無法決議該請求 |
| 401 | 未授權 | 請求沒有進行身份驗證或驗證未通過 |
| 403 | 禁止訪問 | 服務器拒絕此請求 |
| 404 | 未找到 | 服務器找不到請求的頁面 |
| 405 | 方法禁用 | 服務器禁用了請求中指定的方法 |
| 406 | 不接受 | 無法使用請求的內容回應請求的頁面 |
| 407 | 需要代理授權 | 請求者需要使用代理授權 |
| 408 | 請求超時 | 服務器請求超時 |
| 409 | 沖突 | 服務器在完成請求時發生沖突 |
| 410 | 已洗掉 | 請求的資源已永久洗掉 |
| 411 | 需要有效長度 | 服務器不接受不含有效內容長度標頭欄位的請求 |
| 412 | 未滿足前提條件 | 服務器未滿足請求者在請求中設定的其中一個前提條件 |
| 413 | 請求物體過大 | 請求物體過大,超出服務器的處理能力 |
| 414 | 請求URL過長 | 請求網址過長,服務器無法處理 |
| 415 | 不支持型別 | 請求格式不被請求頁面支持 |
| 416 | 請求范圍不符 | 頁面無法提供請求的范圍 |
| 417 | 未滿足期望值 | 服務器未滿足期望請求標頭欄位的要求 |
| 500 | 服務器內部錯誤 | 服務器遇到錯誤,無法完成請求 |
| 501 | 未實作 | 服務器不具備完成請求的功能 |
| 502 | 錯誤網關 | 服務器作為網關或代理,從上游服務器收到無效回應 |
| 503 | 服務不可用 | 服務器目前無法使用 |
| 504 | 網關超時 | 服務器作為網關或代理,但是沒有及時從上游服務器收到請求 |
| 505 | HTTP版本不支持 | 服務器不支持請求中所用的HTTP協議版本 |
(2)回應頭
回應頭包含了服務器對請求的應答資訊,如Content-Type、Server、Set-Cookie等,下面簡要說明常用的頭資訊
–Date:標識回應產生的時間
–Last-Modified:指定資源的最后修改時間
–Content-Encoding:檔案型別,指定回傳的資料型別是什么,如text/html代表回傳HTML檔案,application/x-javascript則代表回傳JavaScript檔案,image/jpeg則代表回傳圖片
–Set-Cookie:設定Cookies,回應頭中的Set-Cookie告訴瀏覽器需要將此內容放在Cookies中,下次請求攜帶Cookies請求
–Expires:指定回應的過期時間,可以代理服務器或瀏覽器將加載的內容更新到快取中,如果再次訪問時,就可以直接從快取中加載,降低服務器負載,縮短加載時間
(3)回應體
最重要的當屬回應體的內容了,回應的正文資料都在回應體中,比如請求網頁時,它的回應體就是網頁的HTML代;請求一張圖片時,它的回應體就是圖片的二進制資料,我們做爬蟲請求網頁后,要決議的內容就是回應體

在瀏覽器開發者工具中點擊Response,就可以看到網頁的源代碼,也就是回應體的內容,它是決議的目標,
在做爬蟲時,我們主要通過回應體得到網頁的源代碼、JSON資料等,然后從中做出相應內容的提取
2.網頁基礎
2.1網頁的組成
網頁可以分為三大部分——HTML、CSS和JavaScript,如果把網頁比作一個人的話,HTML相當于骨干,JavaScript相當于肌肉,CSS相當于皮膚,三者結合起來才能形成一個完善的網頁,
(1)HTML
HTML是用來描述網頁的一種語言,其全稱叫作Hyper Text Markup Language,即超文本標記語言,網頁包括文字、按鈕、圖片和視頻等各種復雜的元素,其基礎架構就是HTML,不同型別的文字通過不同型別的標簽來表示,如圖片用img標簽來表示,視頻用video標簽來表示,段落用p標簽來表示,它們之間的布局又常通過標簽div嵌套組合而成,各種標簽通過不同的排列和嵌套才形成了網頁的框架
在Chrome瀏覽器中打開百度,右擊并選擇“檢查”項(或按F12),打開開發者模式,這是在Element選項卡中即可看到網頁的源代碼
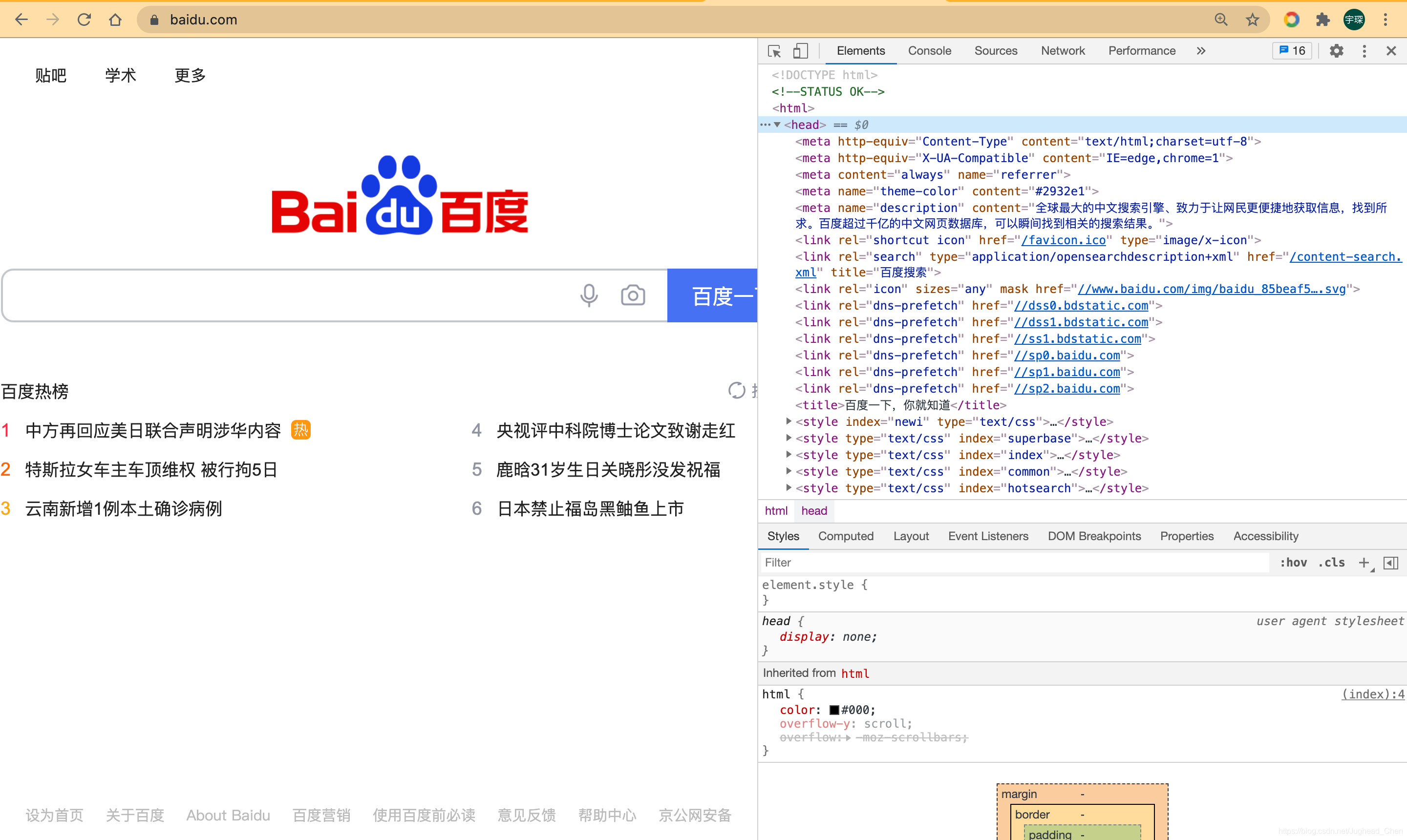
這就是HTML,整個網頁就是由各種標簽嵌套組合而成的,這些標簽定義的節點元素相互嵌套和組合形成了復雜的層次關系,就形成了網頁的架構
(2)CSS
HTML定義了網頁的結構,但是只有HTML頁面的布局觀并不完美,可能還是簡單的節點元素的排列,為了讓網頁更好看一些,這里借助了CSS
CSS,Cascading Style Sheets,即層疊樣式表,“層疊”是指當在HTML中參考了數個樣式檔案,并且樣式發生沖突時,瀏覽器能依據層疊順序處理,“樣式”指網頁中文字大小、顏色、元素間距、排列等格式
CSS是目前唯一的網頁頁面排版樣式標準,例如
#head_wrapper.s-ps-islite .s-p-top {
position: absolute;
bottom: 40px;
width: 100%;
height: 181px;
}
大括號前面是一個CSS選擇器,此選擇器 的意思是首先選中id為head_wrapper且class為s-ps-islite的節點,然后再選中其內部的class為s-p-top的節點,大括號內部寫的就是一條條樣式規則,例如position指定了這個元素的布局方式為絕對布局,bottom指定元素的下邊距為40像素,width指定了寬度為100%占滿父元素,height則指定了元素的高度,
在網頁中,一般會統一定義整個網頁的樣式規則,并寫入CSS檔案(.css),在HTML中,只需要用link標簽即可引入寫好的CSS檔案,這樣整個頁面就會變得美觀、優雅,
(3)JavaScript
JavaScript,簡稱JS,是一種腳本語言,HTML和CSS配合使用,提供給用戶的只是一種靜態資訊,缺乏互動性,我們在網頁里可能會看到一些互動和影片效果,如下載進度條、提示框、輪播圖扽話,這就是JavaScript的作用,實作了一種實時、動態、互動的頁面功能
JavaScript通常也是以單獨的檔案形式加載的,后綴為js,在HTML中通過script標簽即可引入,
如
<script src"jquery-2.1.0.js"></script>
總結一下,HTML定義了網頁的內容和結構,CSS描述了網頁的布局,JavaScript定義了網頁的行為
2.2網頁的結構
我們首先用例子來感受一下HTML的基本結構,新建一個文本檔案,名稱可以自取,后綴為html,內容如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>This is a Demo</title>
</head>
<body>
<div id="container">
<div class="wrapper">
<h2 class="title">Hello World</h2>
<p class="text">Hello, this is a paragraph.</p>
</div>
</div>
</body>
</html>
這就是一個最簡單的HTML實體,開頭用DOCTYPE定義了檔案型別,其次最外層是html標簽,最后還有對應的結束標簽來表示閉合,其內部是head標簽和body標簽,分別代表網頁頭和網頁體,它們也需要結束標簽,head標簽內定義來一些頁面的配置和參考,如<meta charset="UTF-8"> ,它指定了網頁的編碼為UTF-8.
title標簽則定義來網頁的標題,會顯示在網頁的選項卡中,不會顯示在正文中,body標簽則是在網頁正文中顯示的內容,div標簽定義了網頁區塊,它的id是container,這是一個非常常用的屬性,且id的內容在網頁中是唯一的,我們可以通過它來獲取這個區塊,然后在此區塊內又有一個div標簽,它的class為wrapper,這也是一個非常常用的屬性,經常與CSS配合使用來設定樣式,然后此區塊內部又有一個h2標簽,這代表一個二級標題,另外,還有一個p標簽,這代表一個段落,在這兩者中直接寫入相應的內容即可在網頁中呈現出來,它們也有各自的class屬性
我們將代碼保存,在瀏覽器中打開該檔案,就可以看到顯示內容

可以看到,在選項卡上顯示了This is a Demo字樣,這是我們在head中title里定義的文字,而網頁正文是body標簽內部定義的各個元素生成的,可以看到這里顯示了二級標題和段落
這個實體便是網頁的一般結構,一個網頁的標準形式是html標簽內嵌套head和body標簽,head內定義了網頁的配置和參考,body內定義網頁的正文,
2.3節點樹及節點間的關系
在HTML中,所有標簽定義的內容都是節點,它們構成了一個HTML DOM樹,
我們先看下什么是DOM,DOM是W3C(萬維網聯盟)的標準,其英文全稱Document Object Model,即檔案物件模型,它定義了訪問HTML和XML檔案的標準:
W3C檔案物件模型(DOM)是中立于平臺和語言的介面,它允許程式和腳本動態地訪問和更新檔案的內容、結構和樣式,
W3C DOM標準被分為3個不同的部分
–核心DOM:針對任何結構檔案的標準模型
–XML DOM:針對XML檔案的標準模型
–HTML DOM:針對HTML檔案的標準模型
根據W3C的HTML DOM標準,HTML檔案中的所有內容都是節點,
–整個檔案是一個檔案節點
–每個HTML元素是元素節點
–HTML元素內的文本是文本節點
–每個HTML屬性是屬性節點
–注釋是注釋節點
通過HTML DOM,樹的所有節點均可通過JavaScript訪問,所有HTML節點元素均可被修改,也可以被創建或洗掉
節點樹的節點彼此擁有層級關系,我們常用父(parent)、子(child)、和兄弟(sibling)等術語描述這些關系,父節點擁有子節點,同級的子節點被稱為兄弟節點,在節點樹中,頂端節點被稱為根(root),除了根節點之外,每個節點都有父節點,同時可擁有任意數量的子節點或兄弟節點,
2.4選擇器
在CSS中,我們使用CSS選擇器來定位節點,例如,上例中的div節點的id為container,那么就可以表示為#container,其中#開頭代表選擇id,其后緊跟id的名稱,另外,如果我們想選擇class為wrapper的節點,便可以使用.wrapper,這里以點(.)開頭代表選擇class,其后緊跟class的名稱,另外還有一種選擇方式,就是根據標簽名篩選,例如想選擇二級標題,直接用h2即可,這是最常用的3種表示,分別是id、class、標簽名篩選,請牢記它們的寫法
另外,CSS選擇器還支持嵌套選擇,各個選擇器之間加上空格分隔開便可以代表嵌套關系,如#container .wrapper p則代表先選擇id為container的節點,然后選中其內部的class為wrapper的節點,然后再進一步選中其內部的p節點,如果不另外加空格的話,則代表并列關系,如div#container .wrapper p.text代表先選擇id為container的div節點,然后選中其內部的class為wrapper的節點,再進一步選中其內部的class為text的p節點,
下表為CSS選擇器的其他語法規則
| 選擇器 | 例子 | 例子描述 |
|---|---|---|
| .class | .intro | 選擇class="intro"的所有節點 |
| #id | #firstname | 選擇id="firstname"的所有節點 |
| * | * | 選擇所有節點 |
| element | p | 選擇所有p節點 |
| element,element | div,p | 選擇所有div節點和所有p節點 |
| element element | div p | 選擇div節點內部的所有p節點 |
| element>element | div>p | 選擇父節點為div節點的所有p節點 |
| element+element | div+p | 選擇緊接在div節點之后的所有p節點 |
| [arttribute] | [target] | 選擇帶有target屬性的所有節點 |
| [arttribute=value] | [target=blank] | 選擇target="blank"的所有節點 |
| [arttribute~=value] | [title~=flower] | 選擇title屬性包含單詞flower的所有節點 |
| :link | a:link | 選擇所有未被訪問的鏈接 |
| :visited | a:visited | 選擇所有已被訪問的鏈接 |
| :active | a:active | 選擇活動鏈接 |
| :hover | a:hover | 選擇滑鼠指標位于其上的鏈接 |
| :focus | input:focus | 選擇獲得焦點的input節點 |
| :first-letter | p:first-letter | 選擇每個p節點的首字母 |
| :first-line | p:first-line | 選擇每個p節點的首行 |
| :first-child | p:first-child | 選擇屬于父節點的第一個子節點的所有p節點 |
| :before | p:before | 在每個p節點的內容之前插入內容 |
| :after | p:after | 在每個p節點的內容之后插入內容 |
| :lang(language) | p:lang | 選擇帶有以it開頭的lang屬性值的所有p節點 |
| element~element2 | p~ul | 選擇前面有p節點的所有ul節點 |
| [attribute^=value] | a[src^=“https”] | 選擇其src屬性值以https開頭的所有a節點 |
| [attribute$=value] | a[src$=".pdf"] | 選擇其src屬性以.pdf結尾的所有a節點 |
| [attribute*=value] | a[src*=“abc”] | 選擇其src屬性中包含abc子串的所有a節點 |
| :first-of-type | p:first-of-type | 選擇屬于其父節點的首個p節點的所有p節點 |
| :last-of-type | p:last-of-type | 選擇屬于其父節點的最后p節點的所有p節點 |
| :only-of-type | p:only-of-type | 選擇屬于其父節點的唯一的p節點的所有p節點 |
| :only-child | p:only-child | 選擇屬于其父節點的唯一子節點的所有p節點 |
| :nth-child(n) | p:nth-child | 選擇屬于其父節點的第二個子節點的所有p節點 |
| :nth-last-child(n) | p:nth-last-child | 同上,從最后一個子節點開始計數 |
| :nth-of-type(n) | p:nth-of-type | 選擇屬于其父節點第二個p節點的所有p節點 |
| :nth-last-of-type(n) | p:nth-last-of-type | 同上,但是從最后一個子節點開始計數 |
| :last-child | p:last-child | 選擇屬于其父節點最后一個子節點的所有p節點 |
| :root | :root | 選擇檔案的根節點 |
| :empty | p:empty | 選擇沒有子節點的所有p節點(包括文本節點) |
| :target | #news:target | 選擇當前活動的#news節點 |
| :enabled | input:enables | 選擇每個啟用的input節點 |
| :disabled | input:disabled | 選擇每個禁用的input節點 |
| :checked | input:checked | 選擇每個被選中的input節點 |
| :not(selector) | :not | 選擇非p節點的所有節點 |
| ::selection | ::seclection | 選擇被用戶選取的節點部分 |
另外,還有一種比較常用的選擇器是XPath,后續部分會提到
3.爬蟲的基本原理
我們可以把互聯網比作一張大網,而爬蟲(即網路爬蟲)便是在網上爬行的蜘蛛,把網的節點比作一個個網頁,爬蟲爬到這就相當于訪問了該頁面,獲取了其資訊,可以把節點間的連線比作網頁與網頁之間的鏈接關系,這樣蜘蛛通過一個節點后,可以順著節點繼續爬行到達下一個節點,即通過一個網頁繼續獲取后續的網頁,這樣整個網的節點便可以被蜘蛛全部爬取到,網站的資料就可以被抓取下來
3.1爬蟲概述
簡單來說,爬蟲就是獲取網頁并提取和保存資訊的自動化程式,
(1)獲取網頁
爬蟲首先要做的作業就是獲取網頁,這里就是獲取網頁的源代碼,源代碼里包含了網頁的部分有用資訊,所以只要把源代碼獲取下來,就可以從中提取想要的資訊了
前面講了請求和相應的概念,向網站發送了一個請求,回傳的回應體便是網頁源代碼,所以,關鍵在于構造一個請求并發送給服務器,然后接收到回應并將其決議出來,
在Python中,我們可以使用許多庫來完成這個操作,如urllib、requests等,我們可以用這些庫來幫助我們實作HTTP請求操作,請求和回應都可以用類別庫提供的資料結構來表示,得到回應之后只需決議資料結構中的Body部分即可,即得到網頁的源代碼,
(2)提取資訊
獲取網頁源代碼后,接下來就是分析網頁源代碼,從中提取我們想要的資料,首先,最通用的方法便是采用正則運算式,但是在構造正則運算式時比較復雜且容易出錯
另外,由于網頁的結構具有一定的規則,所以還有一些根據網頁節點屬性、CSS選擇器或XPath來提取網頁資訊的庫,如Beautiful Soup、pyquery、lxml等,使用這些庫,我們可以高效快速地從中提取網頁資訊,如節點的屬性、文本值等
提取資訊是爬蟲非常重要的部分,它可以使雜亂的資料變得條理清晰,以便我們后續處理和分析
(3)保存資料
提取資訊后,我們一般會將提取到的資料保存到某處以便后續使用,這里保存形式有多種多樣,如可以簡單保存為TXT文本或JSON文本,也可以保存到資料庫,如MySQL和MongoDB等,也可以保存至遠程服務器,借助SFTP操作等
(4)自動化程式
說到自動化程式,意思是爬蟲可以代替人來完成這些操作,首先,我們手工當然可以提取這些資訊,但是當量特別大或者想快速獲取大量資料的話,肯定還是要借助程式,爬蟲就是代替我們完成這份爬取作業的自動化程式,它可以在抓取程序中進行各種例外處理、錯誤重試等操作,確保爬取持續高效地運行
3.2能抓怎樣的資料
在網頁中我們能看到各種各樣的資訊,最常見的便是常規網頁,它們對應著HTML代碼,而最常抓取的便是HTML源代碼
另外,可能有些網頁回傳的不是HTML代碼,而是一個JSON字串(其中API介面大多采用這樣的形式),這種格式的資料方便傳輸和決議,它們同樣可以抓取,而且資料提取更加方便
此外,我們還可以看到各種二進制資料,如圖片、視頻和音頻等,利用爬蟲,我們可以將這些二進制資料抓取下來,然后保存成對應的檔案名
另外,還可以看到各種二進制資料,如CSS、JavaScript和組態檔等,這些其實也是最普通的檔案,只要在瀏覽器里面可以訪問到,就可以將其抓取下來
3.3JavaScript渲染頁面
有時候,我們在用urllib或requests抓取網頁時,得到的源代碼實際和瀏覽器中看到的不一樣
這就是一個非常常見的問題,現在網頁越來越多地采用Ajax、前端模塊化工具來構建,整個網頁可能都是由JavaScript渲染出來的,也就是說原始的HTML代碼就是一個空殼,例如
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>This is a Demo</title>
</head>
<body>
<div id="container">
</div>
</body>
<script src="app.js"></script>
</html>
body節點里面只有一個id為container的節點,但是需要注意在body節點后引入來app.js,它便負責整個網站的渲染
在瀏覽器中打開這個這個頁面時,首先會加載這個HTML內容,接著瀏覽器會發現其中引入來一個app.js檔案,然后便會接著去請求這個檔案,獲取到該檔案后,便會執行其中的JavaScript代碼,而JavaScript則會改變HTML中的節點,向其添加內容,最后得到完整的頁面
但是在用urllib或requests等庫請求當前頁面時,我們得到的只是這個HTML代碼,它不會幫助我們去加載這個JavaScript檔案,這樣也就看不到瀏覽器中的內容,
因此,使用基本HTTP請求庫得到的源代碼可能跟瀏覽器的頁面中的頁面源代碼不太一樣,對于這樣的情況,我們可以分析其后臺Ajax介面,也可以使用Selenium、Splash這樣的庫來實作模擬JavaScript渲染,
4.會話和Cookies
在瀏覽器網站的程序中,我們經常會遇到需要登錄的情況,有些頁面只有登錄之后才可以訪問,而且登錄之后可以連續訪問很多次網站,但是有時候過一段時間就需要重新登錄,這就涉及到會話(Session)和Cookies的相關知識,
4.1靜態網頁和動態網頁
開始之前,先了解一下靜態網頁和動態網頁的概念,
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>This is a Demo</title>
</head>
<body>
<div id="container">
<div class="wrapper">
<h2 class="title">Hello World</h2>
<p class="text">Hello, this is a paragraph.</p>
</div>
</div>
</body>
</html>
這是最基本的HTML代碼,我們將其保存為一個.html檔案,然后把它放在某臺具有固定公網IP的主機上,主機上裝上Apache或Nginx等服務器,這樣這臺主機就可以作為服務器來,其他人便可以通過訪問服務器看到這個頁面,這就搭建了一個最簡單的網站
這種網頁的內容是HTML代碼撰寫的,文字、圖片等內容均通過寫好的HTML代碼來指定,這種頁面叫做靜態網頁,它加載速度快,撰寫簡單,但是存在很大的缺陷,如可維護性差,不能根據URL靈活多變地顯示內容等,例如,我們想要給這個網頁的URL傳入一個name引數,讓其在網頁中顯示出來,是無法做到的
因此,動態網頁應運而生,他可以動態決議URL中引數的變化,關聯資料庫并動態呈現不同的頁面內容,非常靈活,我們現在遇到的大多數網站都是動態網站,它們不再是一個簡單的HTML,而是可能由JSP、PHP、Python等語言撰寫的,其功能比靜態網頁強大和豐富太多了
此外,動態網站還可以實作用戶登錄和注冊的功能,再回到開頭提到的問題,很多頁面是需要登錄之后才可以查看的,按照一般的邏輯來說,輸入用戶名和密碼登錄之后,肯定是拿到了一種憑證的東西,有了它,我們才能保持登錄狀態,才能訪問登錄之后才能看到的頁面
4.2無狀態HTTP
在了解會話和Cookies之前,我們還需要了解HTTP的一個特點,叫做無狀態
HTTP的無狀態是指HTTP協議對事務處理是沒有記憶能力對,也就是說服務器不知道客戶端是什么狀態,當我們向服務器發送請求后,服務器決議此請求,然后回傳對應的回應,服務器負責完成這個程序,而且這個程序是完全獨立的,服務器不會記錄前后狀態的變化,也就是缺少狀態記錄,這意味這著如果后續需要處理前面的資訊,則必須重傳,這導致需要額外傳遞一些前面的重復請求,才能獲取后續回應,然而這種效果顯然不是我們想要的,為了保持前后狀態,我們肯定不能將前面的請求全部重傳一次,這太浪費資源了,對于這種需要登錄的頁面來說,更加棘手
這時兩個用于保持HTTP連接狀態的技術就出現了,它們分別是會話和Cookies,會話在服務端,也就是網站的服務器,用來保存用戶的會話資訊;Cookies在客戶端,也可以理解為瀏覽器端,有了Cookies,瀏覽器在下次訪問網頁時會自動附帶上它發送給服務器,服務器通過識別Cookies并鑒定出是哪個用戶,然后再判斷用戶是否為是登錄狀態,然后回傳對應的回應
我們可以理解為Cookies里面保存了登錄的憑證,有了它,只需要在下次請求攜帶Cookies發送請求而不必重新輸入用戶名、密碼等登錄資訊了
因此在爬蟲中,有時候處理需要登錄才能訪問的頁面時,我們一般會直接將登陸成功后獲取的Cookies放在請求頭里面直接請求,而不必重新模擬登錄
(1)會話
會話,其本來的含義是指有始有終的一系列動作/訊息,比如,打電話時,從拿起電話撥號到掛斷電話這中間的一系列程序可以稱為一個會話,
而在Web中,會話物件用來存盤特定用戶會話所需的屬性及配置資訊,這樣,當用戶在應用程式的Web頁面之間跳轉時,存盤在會話物件中的變數將不會丟失,而是在整個用戶會話中一直存在下去,當用戶請求來自應用程式的Web頁時,如果該用戶還沒有會話,則Web服務器將自動創建一個會話物件,當會話過期或被放棄后,服務器將終止該會話,
(2)Cookies
Cookies指某些網站為了辨別用戶身份、進行會話跟蹤而存盤在用戶本地終端上的資料
·會話維持
當客戶端第一次請求服務器時,服務器會回傳一個請求頭中帶有Set-Cookie欄位的回應給客戶端,用來標記哪一個用戶,客戶端瀏覽器會把Cookies保存起來,當瀏覽器下一次再請求該網站時,瀏覽器會把此Cookies放到請求頭一起提交給服務器,Cookies攜帶了會話ID資訊,服務器檢查該Cookies即可找到對應的會話是什么,然后再判斷會話來以此辨別用戶狀態
在成功登錄某個網站時,服務器會告訴客戶端設定哪些Cookies資訊,在后續訪問頁面時客戶端會把Cookies發送給服務器,服務器再找到對應的會話加以判斷,如果會話中的某些設定登錄狀態的變數是有效的,那就證明用戶處于登錄狀態,此時回傳登錄之后才可以查看的網頁內容,瀏覽器再進行決議便可以看到了
反之,如果傳給服務器的Cookies是無效的,或者會話已經過期了,我們將不能繼續訪問頁面,此時可能會收到錯誤的回應或者跳轉到登錄頁面重新登錄
所以,Cookies和會話需要配合,一個處于客戶端,一個處于服務端,二者共同協作,就實作了登錄會話控制
·屬性控制
接下來,我們來看看Cookies都有哪些內容,這里以知乎為例,在瀏覽器開發者工具中打開Application選項卡,然后在左側會有一個Storage部分,最后一項即為Cookies,將其點開,如下圖所示,這些就是Cookies
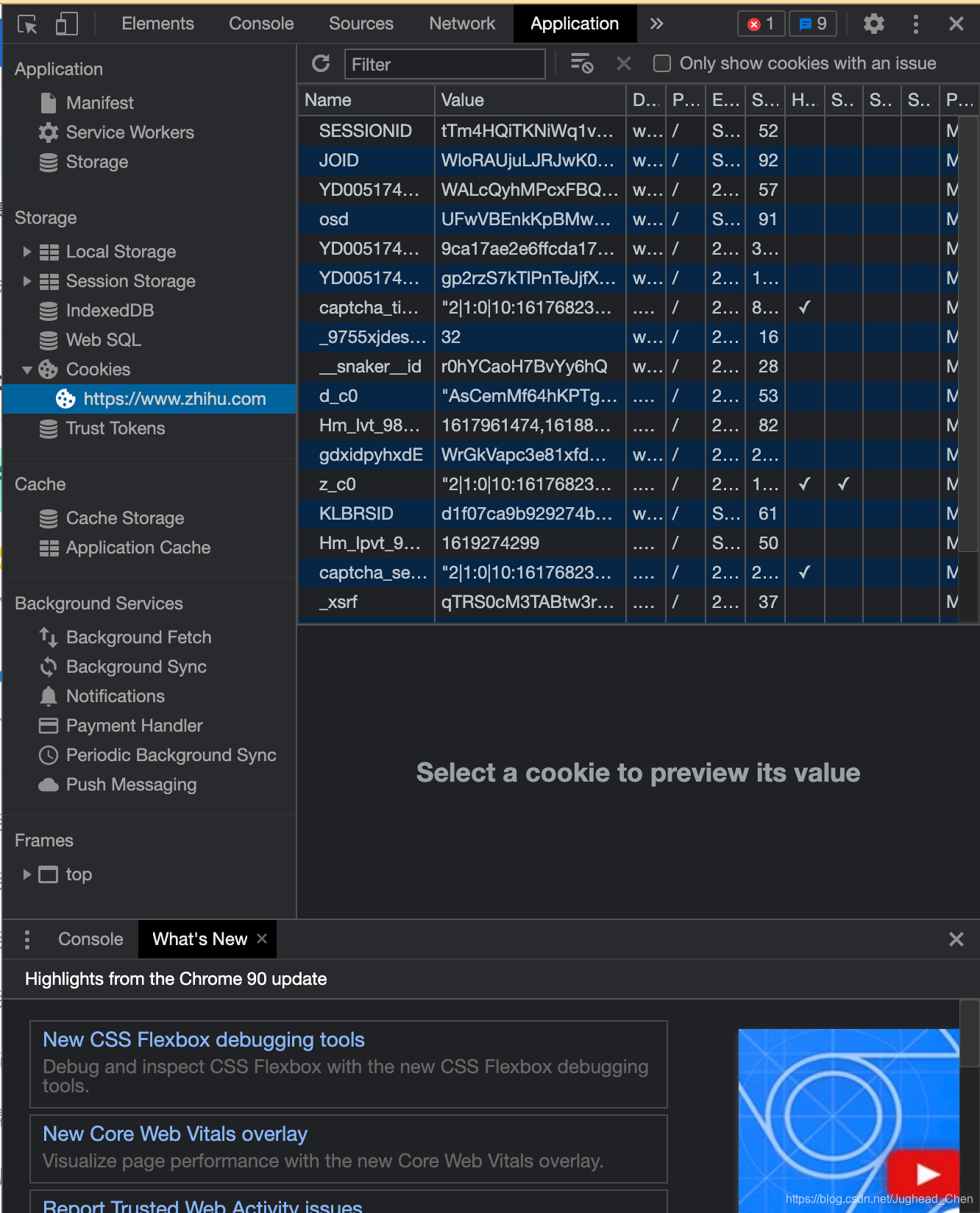
可以看到,這里有很多條目,其中每個條目可以稱為Cookie,它如下屬性:
– Name:該Cookie的名稱,一旦創建,該名稱便不可更改,
– Value:該Cookie的值,如果值為Unicode字符,需要為字符編碼,如果值為二進制資料,則需要使用BASE64編碼
–Domain:可以訪問該Cookie的域名,例如,如果設定為.zhihu.com,則所有以zhihu.com結尾的域名都可以訪問該Cookie
–Max Age:該Cookie失效的時間,單位為秒,也常和Expires一起使用,通過它可以計算出其有效時間,Max Age如果為正數,則該Cookie在Max Age秒之后失效,如果為負數,則關閉瀏覽器時Cookie即失效,瀏覽器也不會以任何形式保存該Cookie
– Path:該Cookie的使用路徑,如果設定為/path/,則只有路徑為/path/的頁面可以訪問該Cookie,如果設定為/,則本域名下的所有頁面都可以訪問該Cookie
– Size欄位:此Cookie的大小
–HTTP欄位:Cookie的httponly屬性,若此屬性為true,則只有在HTTP頭中會帶有此Cookie的資訊,而不能通過document.cookie來訪問此Cookie
–Secure:該Cookie是否僅被使用安全協議傳輸,安全協議有HTTPS和SSL等,在網路上傳輸資料之前先將資料加密,默認為false
·會話Cookie和持久Cookie
從表面意思來說,會話Cookie就是把Cookie放在瀏覽器記憶體里,瀏覽器在關閉之后該Cookie即失效;持久Cookie則會保存到客戶端的硬碟,下次還可以繼續使用,用于長久保持用戶登錄狀態,
其實嚴格來說,沒有會話Cookie和持久Cookie之分,只是由Cookie的Max Age或Expires欄位決定了過期的時間
4.3常見誤區
在談論會話機制的時候,常常聽到這樣的誤解——“只要關閉瀏覽器,會話就消失了”,可以想象一下會員卡的例子,除非顧客主動對店家提出銷卡,否則店家絕對不會輕易洗掉顧客資料,對會話來說,也是一樣,除非程式通知服務器洗掉一個會話,否則服務器會一直保留,比如,程式都是在我們做注銷操作時才去洗掉會話
但是當我們關閉瀏覽器時,瀏覽器不會主動在關閉之前通知服務器它將要關閉,所以服務器根本不會有機會知道瀏覽器已經關閉,之所以會有這種錯覺,是因為大部分會話機制都使用會話Cookie來保存會話ID資訊,而關閉瀏覽器后Cookie就消失了,再次連接服務器時,也就無法找到原來的會話了,如果服務器設定的Cookies保存到硬碟上,或者使用某種手段改寫瀏覽器發出的HTTP請求頭,把原來的Cookies發送給服務器,則再次打開瀏覽器,仍然能夠找到原來的會話ID,,依舊還是可以保持登錄狀態
而且恰恰是由于關閉瀏覽器不會導致會話被洗掉,這就需要服務器為會話設定一個失效時間,當距離客戶端上一次使用會話的時間超過這個失效時間時,服務器就可以認為客戶端已經停止了活動,才會把會話洗掉以節省存盤空間
5.代理的基本原理
我們在做爬蟲的程序中經常會遇到這樣的情況,最初爬蟲正常運行,正常抓取資料,一切看起來都是那么美好,然而過一會就會出現錯誤,比如403Forbidden,這時候打開網頁一看,可能會看到“您的IP訪問頻率太高”這樣的提示,出現的原因是網站采取了一些反爬蟲措施,比如,服務器會檢測某個IP在單位時間內的請求次數,如果超過了這個閾值,就會直接拒絕服務,回傳一些錯誤資訊,這種情況可以稱為封IP
既然服務器檢測的是某個IP單位時間的請求次數,那么借助某種方式來偽裝我們的IP,讓服務器識別不出是由我們本機發起的請求,就可以成功防止封IP,一種有效的方式就是使用代理,后續會提到使用方式,先來了解代理的基本原理
5.1基本原理
代理實際上指的就是代理服務器,英文叫做proxy server,它的功能是代理網路用戶去取得網路資訊,形象地說,它是網路資訊的中轉站,在我們正常請求一個網站時,是發送了請求給Web服務器,Web服務器把相應資訊傳回給我們,如果設定了代理服務器,實際上就是在本機和服務器之間搭建了一個橋,此時本機不是直接向Web服務器發起請求,而是向代理服務器發起請求,請求會發送給代理服務器,然后由代理服務器再發送給Web服務器,接著由代理服務器再把Web服務器回傳的回應轉發給本機,這樣我們同樣可以正常訪問網頁,但這個程序中Web服務器識別出的真實IP就不再是我們本機的IP,就成功實作了IP偽裝,這就是代理的基本原理
5.2代理的作用
那么,代理有什么作用呢?
1.突破自身IP訪問限制,訪問一些平時不能訪問的站點
2.訪問一些單位或團體內部資源;比如使用教育網內地址段免費代理服務器,就可以用于對教育網開放的各類FTP下載上傳,以及各類資料查詢共享等服務
3.提高訪問速度:通常代理服務器都設定一個較大的硬碟緩沖區,當外界的資訊通過時,同時也將其保存到緩沖區中,當其他用戶再訪問相同資訊時,則直接由緩沖區中取出資訊,傳給用戶,以提高訪問速度
3.隱藏真實IP:上網者也可以通過這種方法隱藏自己的IP,免受攻擊,對于爬蟲來說,我們用代理就是為了隱藏自身IP,防止自身的IP被封鎖
5.3爬蟲代理
對于爬蟲來說,由于爬蟲爬取速度過快,在爬取程序中可能遇到同一個IP訪問過于頻繁的問題,此時網站就會讓我們輸入驗證碼登錄或者直接封鎖IP,這樣會給爬取帶來極大的不便
使用代理隱藏真實的IP,讓服務器誤以為是代理服務器在請求自己,這樣在爬取程序中通過不斷更換代理,就不會被封鎖,可以達到很好的爬取效果
5.4代理分類
代理分類時,既可以根據協議區分,也可以根據其匿名程度區分
1.根據協議區分
根據代理的協議,代理可以分為如下類別
–FTP代理服務器:主要用于訪問FTP服務器,一般有上傳、下載以及快取功能,埠一般為21、2121等
–HTTP代理服務器:主要用于訪問網頁,一般有內容過濾和快取功能,埠一般為80、8080、3128等
–SSL/TLS代理:主要用于訪問加密網站,一般有SSL或者TLS加密功能(最高支持128位加密強度),埠一般為443
–RTSP代理:主要用于訪問Real流媒體服務器,一般有快取功能,埠一般為554
– Telnet代理:主要用于telnet遠程控制(黑客入侵計算機時常用于隱藏身份),埠一般為23
–POP3/SMTP代理:主要用于POP3/SMTP方式收發郵件,一般有快取功能,埠一般為110/25
– SOCKS代理:只是單純傳遞資料包,不關心具體協議和用法,所以速度快很多,一般有快取功能,埠一般為8080.SOCKS代理協議又分為SOCKS4和SOCKS5,前者只支持TCP,而后者支持TCP和UDP,還支持各種身份驗證機制、服務器端域名決議等,簡單來說,SOCKS4能做到的SOCKS5都可以做到,但是SOCKS5能做到的SOCKS4不一定能做到
2.根據匿名程度區分
根據代理的匿名程度,代理可以分為如下類別
–高度匿名代理:會將資料包原封不動地轉發,在服務端看來好像真的是一個普通客戶端在訪問,而記錄的IP是代理服務器的IP
–普通匿名代理:會在資料包上做一些改動,服務端上有可能發現這是個代理服務器,也有一定幾率追查到客戶端的真實IP,代理服務器通常會加入的HTTP頭有HTTP_VIA和HTTP_X_FORWARDED_FOR.
–透明代理:不但改動了資料包,還會告訴服務器客戶端的真實IP,這種代理除了能快取技術提高瀏覽速度,能用內容過濾提高安全性之外,并無其他顯著作用,最常見的例子是內網中的硬體防火墻
–間諜代理:指組織或個人創建的用于記錄用戶傳輸的資料,然后進行研究、監控等目的的代理服務器
5.5常見代理設定
–使用網上的免費代理:最好使用高匿代理,另外可用的代理不多,需要在使用前篩選一下可用代理,也可以進一步維護一個代理池
– 使用付費代理服務:互聯網上存在許多代理商,可以付費使用,質量比免費代理好很多
–ADSL撥號:撥一次號換一次IP,穩定性高,也是一種比較有效的解決方案
本周講述了爬蟲的基礎知識,下周將會開始對Python網路爬蟲要用到的庫進行介紹
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/280362.html
標籤:python
上一篇:安裝python包出現Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None))
下一篇:Two Sum