目錄
- 1. 概率與概率分布
- 1.1離散型隨機變數
- 1.1.1概率質量函式(PMF)
- 1.1.2 累計分布密度函式(CDF)
- 1.1.3 Python的實作
- 1.2 連續型隨機變數
- 2. 期望值與方差
- 3. 二項分布
- 3.1二項分布概述及其與伯努利分布的差別
- 3.2 Numpy生成二項分布亂數
- 3.3 二項分布的PMF與CDF
- 3.3.1 PMF及其影像繪制
- 3.3.2 CDF及其影像繪制
- 3.3.3 二項分布在金融市場的應用
- 4. 正態分布
- 4.1 正態分布概述
- 4.2 Python正態分布相關函式
- 4.3 正態分布在金融市場的應用
- 5. 其他連續分布
- 5.1 卡方分布
- 5.2 t分布
- 5.3 F分布
- 6. 變數的關系
- 6.1 聯合概率分布
- 6.2變數的獨立性
- 6.3 變數的相關性
- 6.4 上證指數與深證成指相關性分析
統計分析是可以幫助人們認清、刻畫不確定性的方法,總體是某一特定事物可能發生結果的集合, 隨機變數(Random Variable) 則是一個不確定事件結果是數值函式(Function),也就是說,把不確定事件的結果用數值來表述,即得到隨機變數,隨機變數又分為 離散型隨機變數(Discrete Random Variable) 和 連續型隨機變數(Continuous Radom Variable),

1. 概率與概率分布
概率(Probability)是用于刻畫事物不確定性的一種測度(Measure),根據概率的大小,我們可以判斷不確定性的高低,
1.1離散型隨機變數
1.1.1概率質量函式(PMF)
假設X是一個離散型隨機變數,其所有可能取值為集合{ak},k=1,2,…,我們定義X的概率質量函式(Probability Mass Function) 為:
f
X
(
a
k
)
=
P
{
X
=
a
k
}
,
k
=
1
,
2
,
?
\displaystyle {f_X}\relax{(a_k)}=P\{X=a_k\} , k=1,2,\cdots
fX?(ak?)=P{X=ak?},k=1,2,?
概率質量函式可以量化地表達隨機變數X取每個數值可能性的大小
1.1.2 累計分布密度函式(CDF)
對于離散型隨機變數,累計分布函式可以用概率質量函式累加來獲得:
F
X
(
a
)
=
P
{
X
≤
a
}
=
∑
i
:
a
i
≤
a
f
X
(
a
i
)
\displaystyle {F_X}\relax{(a)}=P\{X\leq a\}=\sum_{i:a_i\leq a}{f_X}\relax{(a_i)}
FX?(a)=P{X≤a}=i:ai?≤a∑?fX?(ai?)
1.1.3 Python的實作
在Python中我們可以通過Numpy包的random模塊中的choice()函式來生成服從待定的概率質量函式的亂數,
choice()函式:
- choice(a, size=None, replace=True, p=None)
引數a: 隨機變數可能的取值序列,
引數size: 我們要生成亂數陣列的大小,
引數replace: 決定了生成亂數時是否是有放回的,
引數p:為一個與x等長的向量,指定了每種結果出現的可能性,
計算頻數分布使用value_counts()函式
# 以陣列形式
import numpy as np
import pandas as pd
RandomNumber=np.random.choice([1,2,3,4,5],\
size=100, replace=True,\
p=[0.1,0.1,0.3,0.3,0.2])
pd.Series(RandomNumber).value_counts() # 計算頻數分布value_counts()函式
pd.Series(RandomNumber).value_counts()/100 #計算概率分布
結果呈現:
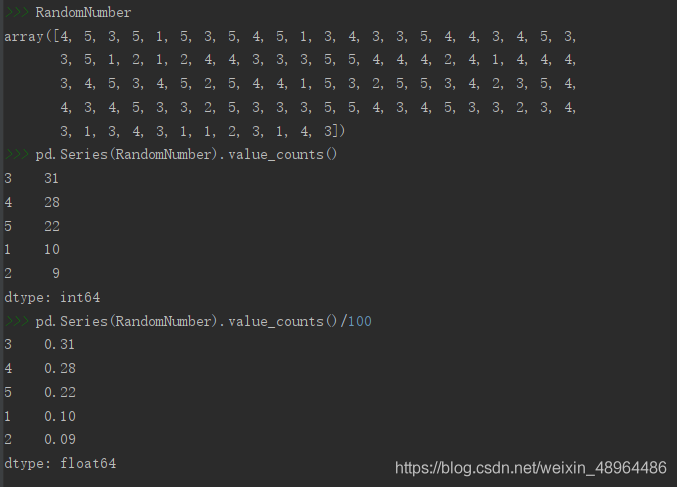
- 增大size引數,即生成亂數的數目,得到的結果則會更接近設定的概率,
1.2 連續型隨機變數
若隨機變數X是連續的,我們則不再能通過概率質量函式來刻畫隨機變數只隨機性,對任意ak都有
P
{
X
=
a
k
}
=
0
\displaystyle P\{X=a_k\}=0
P{X=ak?}=0,
連續型隨機變數沒有PMF,對于連續型隨機變數,累積分布函式
F X ( a ) = P { X ≤ a } \displaystyle {F_X}\relax{(a)}=P\{X\leq a\} FX?(a)=P{X≤a}可以表達為:
F X ( a ) = ∫ ? ∞ a f X ( x ) d x \displaystyle {F_X}\relax{(a)}=\int _{-\infty}^{a}{f_X}\relax{(x)}dx FX?(a)=∫?∞a?fX?(x)dx
其中
f
X
=
d
F
X
(
x
)
d
x
\displaystyle {f_X}=\frac{dF_X(x)}{dx}
fX?=dxdFX?(x)?,被稱作概率密度函式
(Probability Density Function)(PDF),X的取值落在某個區間的概
率可以用概率密度函式在這個區間上的積分來求得,
演算法邏輯:
- 使用stats模塊kde包中的gaussian_kde()可以估計資料的概率密度,在其中傳入我們要統計的Series型別的變數名即可,得到的是一個“scipy.stats.kde.gaussian_kde”型別的物件,我們暫先給其命名為density,
- 然后設定好分割區間,設為陣列格式,暫將該物件命名為bins,
- 注意,這次與以往繪圖不同,這次是以研究的物件資料為行進行繪圖,
- 使用上邊得到的資料型別density,以 density(bins)格式的語法可以得到一個以設定的分割區間為界限的概率密度陣列,讓將density(bins)這個物件作為行傳入plot即可,
- 如果要繪制累計分布函式圖,則只需在上邊的density(bins)物件后再呼叫一下cumsum()函式,對陣列資料進行累加后在傳入即可,
以2020年滬深300指數(399300.SZ)的收益率(日漲跌幅)資料為例:
# 調取資料
import numpy as np
import tushare as ts
import pandas as pd
token = 'Your Token' # 輸入你的介面密匙,獲取方式及相關權限見Tushare官網,
pro = ts.pro_api(token)
df = pro.index_daily(ts_code='399300.SZ')
df['trade_date'] = pd.to_datetime(df['trade_date'])
df.set_index(['trade_date'], inplace=True) # 將日期列作為行索引
df = df.sort_index()
# 實作概率分布
import matplotlib.pyplot as plt
from scipy import stats
density = stats.kde.gaussian_kde(df.pct_chg['2020']) #研究資料格式化
bins=np.arange(-5,5,0.02) # 設定分割區間
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.subplot(211)
plt.plot(bins,density(bins))
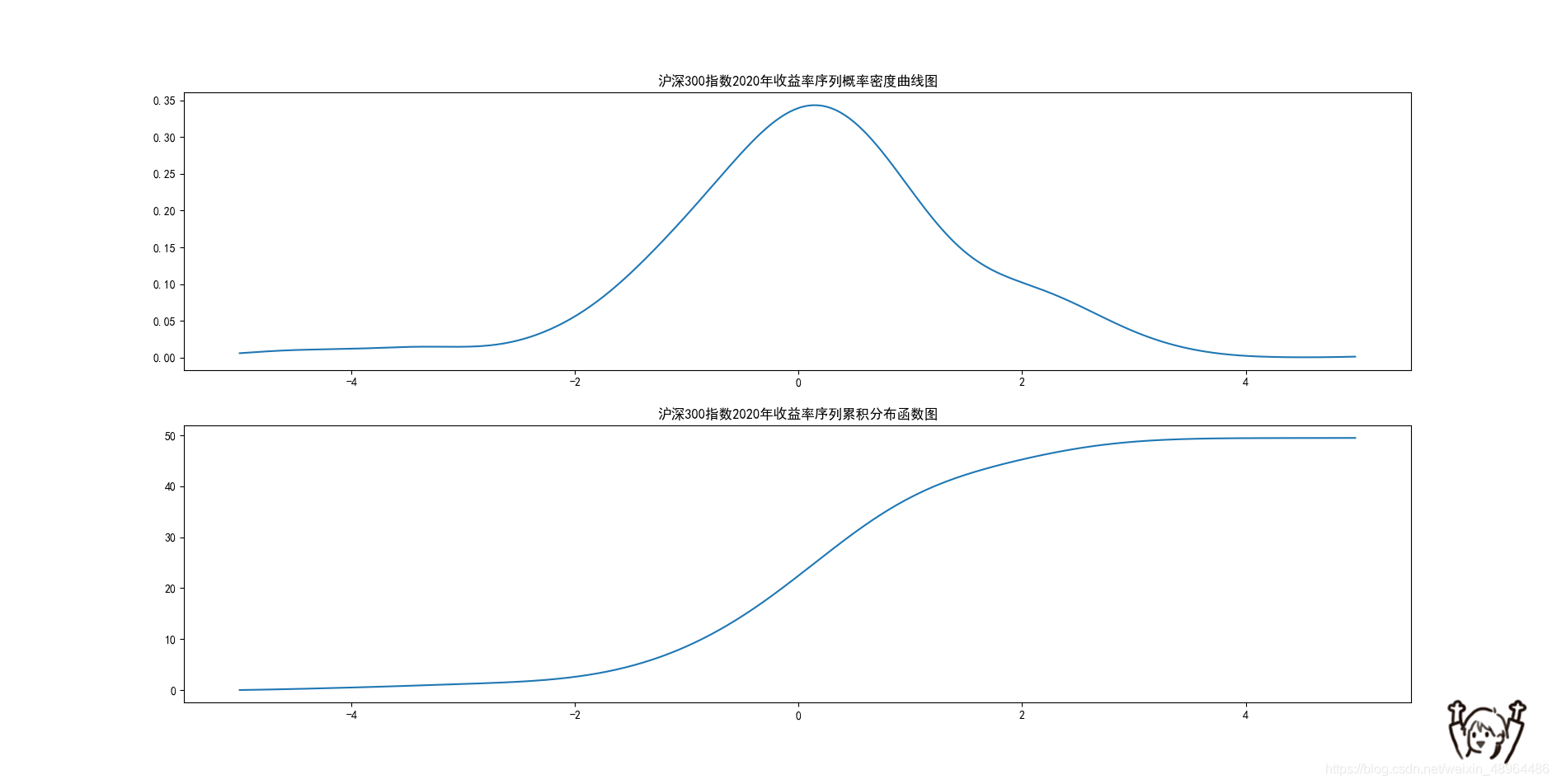
plt.title('滬深300指數2020年收益率序列概率密度曲線圖')
plt.subplot(212)
plt.plot(bins,density(bins).cumsum())
plt.title('滬深300指數2020年收益率序列累積分布函式圖')
plt.show()
結果展示如下:
2. 期望值與方差
可以用樣本資料的平均值來刻畫樣本的中心位置,期望(Expectation)是隨機變數所有可能取的結果的均值,用來呈現總體的中心位置,對于離散型隨機變數,期望是該隨機變數所有可能結果的取值與其概率的乘積之和:
E
(
X
)
=
∑
k
a
k
f
X
(
a
k
)
=
∑
k
a
k
P
{
X
=
a
k
}
\displaystyle E\relax{(X)}=\sum_ka_kf_X\relax{(a_k)}=\sum_ka_kP\{X=a_k\}
E(X)=k∑?ak?fX?(ak?)=k∑?ak?P{X=ak?}
方差(Variance)則是:
V
a
r
(
X
)
=
E
[
X
?
E
]
2
=
∑
k
[
a
k
?
E
(
X
)
2
]
P
{
X
=
a
k
}
\displaystyle Var\relax{(X)}=E\left[X-E\right]^2=\sum_k\left[a_k-E(X)^2\right]P\{X=a_k\}
Var(X)=E[X?E]2=k∑?[ak??E(X)2]P{X=ak?}
對于一類特殊的離散型隨機變數:伯努利(Bernoulli Random Variable)隨機變數,伯努利隨機變數X只能取到兩個值,0或者1,對應的概率質量函式為:
f
X
(
a
)
=
P
(
X
=
a
)
=
{
p
,
a
=
1
1
?
p
,
a
=
0
\displaystyle f_X\relax{(a)}=P\relax{(X=a)}=\begin{cases}p,&a=1 \\1-p,&a=0\end{cases}
fX?(a)=P(X=a)={p,1?p,?a=1a=0?
伯努利隨機變數的期望值 E ( X ) = p \displaystyle E(X)=p E(X)=p
方差為 V a r ( X ) = ( 1 ? p ) ? p \displaystyle Var(X)=(1-p)·p Var(X)=(1?p)?p
若隨機變數X為連續型隨機變數,其概率密度函式為 f X \displaystyle f_X fX?,則期望為: E ( X ) = ∫ ? ∞ ∞ a f X ( a ) d a \displaystyle E(X)=\int_{-\infty}^{\infty}af_X\relax{(a)}d\relax{a} E(X)=∫?∞∞?afX?(a)da
方差為:
V
a
r
(
X
)
=
∫
?
∞
∞
[
a
?
E
(
X
)
]
2
f
X
(
a
)
d
a
\displaystyle Var\relax{(X)}=\int_{-\infty}^{\infty}\left[a-E\relax{(X)}\right]^2f_X\relax{(a)}d\relax{a}
Var(X)=∫?∞∞?[a?E(X)]2fX?(a)da
隨機變數可能的取值有很多(比如連續型隨機變數的取值為無窮),但其觀測值(實際值)個數有限,因此現實中隨機變數的概率分布、期望、方差等特征值通常是不可知的,推斷統計就是透過其觀測值的集合——樣本資料來刻畫這些特征的,
3. 二項分布
3.1二項分布概述及其與伯努利分布的差別
研究伯努利分布時,我們關注的期望是進行一次試驗結果的期望值,這樣的結果有兩種情況,所以伯努利分布也稱“兩點分布”,
而研究二項分布時,我們關注的是n次試驗的結果,這樣的結果有多種組合,
為直觀說明,假設二點分布結果0的概率為0.4,結果為1的概率為0.6;
二項分布結果為0的概率為0.4,結果為1的概率為0.6,且進行十次,
則:
n = 10
p1 = 0.6
p2 = 0.6
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.subplot(221)
plt.bar(['0','1'], [1-p1,p1], width=0.5)
plt.title("二點分布PMF")
plt.subplot(222)
plt.plot(['0','0','1','1',' '], [0, 0.4, 0.4, 1.0,1.0])
plt.title("二點分布CDF")
plt.subplot(223)
b = [stats.binom.pmf(i,10,0.6) for i in range(0,11)]
plt.bar([str(i) for i in range(0,n+1)],b)
plt.title('二項分布PMF')
plt.subplot(224)
plt.title("二項分布CDF")
c = [str(i//2) for i in range(0,2*(n+1))]
c.append('')
d = [stats.binom.cdf(i//2,10,0.6) for i in range(0,22)]
d.insert(0,0)
plt.plot(c,d)
plt.show()
展示結果:
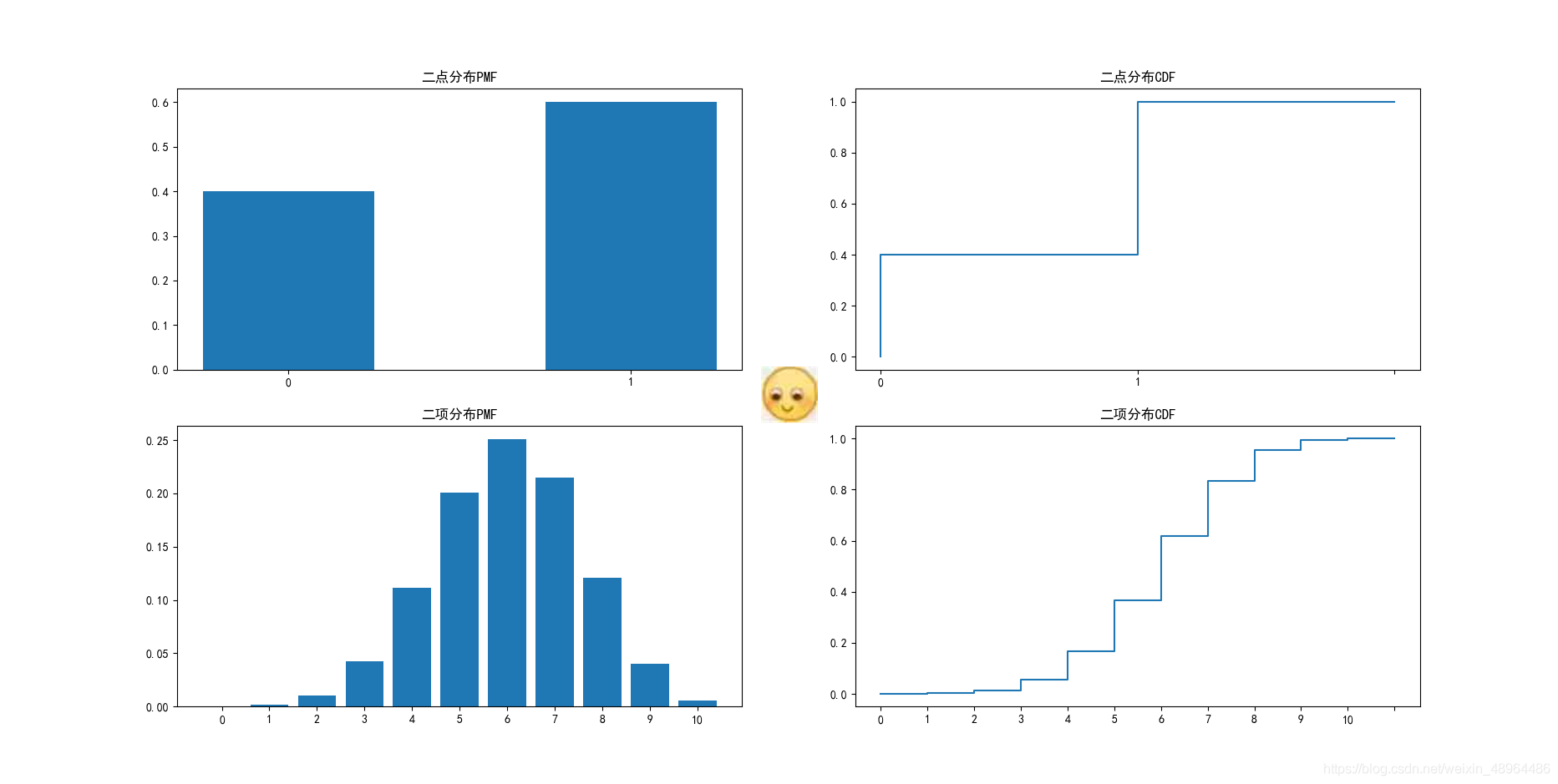
當np≥10,n(1-p)≥10都滿足時,二項分布可以近似為正態分布,
3.2 Numpy生成二項分布亂數
在Numpy庫中可以使用binomial()函式來生成二項分布亂數,
形式為:binomial(n, p, size=None)
引數n是進行伯努利試驗的次數,引數p是伯努利變數取值為1的概率,size是生成亂數的數量,
np.random.binomial(100, 0.5, 20)

3.3 二項分布的PMF與CDF
3.3.1 PMF及其影像繪制
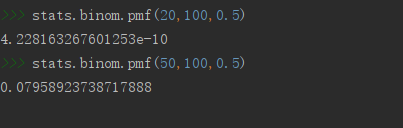
# 求100次試驗,20次成功的概率,p=0.5
stats.binom.pmf(20,100,0.5)
# 求100次試驗,50次成功的概率,p=0.5
stats.binom.pmf(50,100,0.5)
影像繪制
#傳入時n+1是因為10次實驗有十一種可能的結果組合,
n=10 # 十次試驗
p=0.5
plt.rcParams['font.sans-serif'] = ['SimHei']
b = [stats.binom.pmf(i, n, p) for i in range(0,n+1)]
plt.bar([str(i) for i in range(0,len(b))],b)
plt.title('X~B({},{})二項分布PMF'.format(n,p))
plt.show()
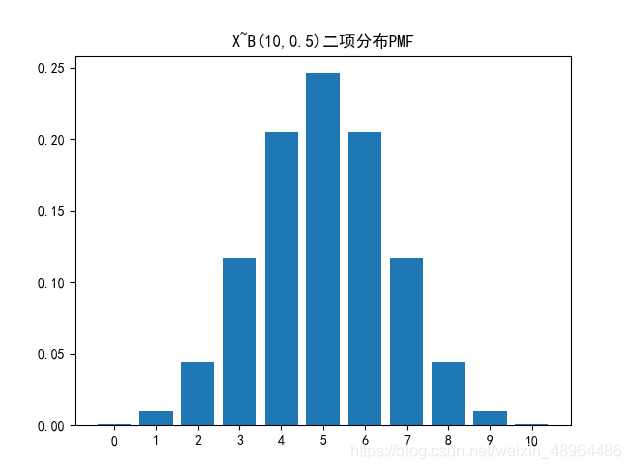
3.3.2 CDF及其影像繪制
可以直接用pmf()函式解決這個問題,
#stats.binom.pmf函式很神奇,傳入的第一個引數是數字(指定伯努利試驗成功的次數),生成結果就也是一個數字,如果傳入的第一個引數是陣列,則會將會以該陣列的shape輸出其中每個數字成功次數的條件下,對應的概率,
dd = stats.binom.pmf(np.arange(0, 21, 1), 100, 0.5)
dd
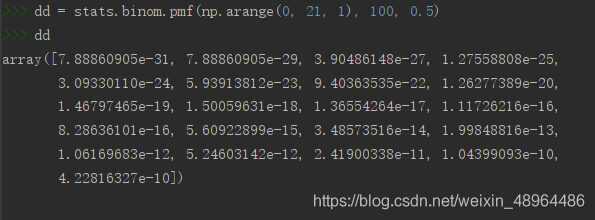
# 然后對陣列求和即求出小于等于20次發生這一事件的概率
dd.sum()
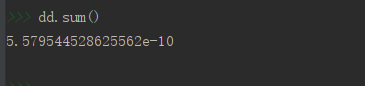
此外,也可以用binom中的cdf()函式來直接解決這個問題
# 依然100次試驗成功20次,每次p=0.5
stats.binom.cdf(20,100,0.5)

影像繪制
n=10 # 十次試驗
p=0.5
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('X~B({},{})二項分布CDF'.format(n,p))
c = [str(i//2) for i in range(0, 2*(n+1))]
c.append('')
d = [stats.binom.cdf(i//2, n, p) for i in range(0, 22)]
d.insert(0,0)
plt.plot(c,d)
plt.show()
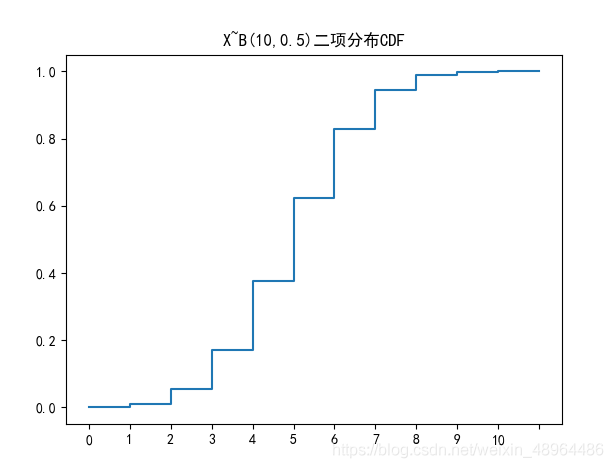
3.3.3 二項分布在金融市場的應用
二項分布常常用于描述金融市場中只有兩個結果的重復事件,
如研究平安銀行股票2020年資料:
# 匯入相關模塊
import numpy as np
import tushare as ts
import pandas as pd
from scipy import stats
# 設定好介面 注意這句不能照抄,需要輸入自己的介面密匙
token = 'Your token' # 輸入你的介面密匙,獲取方式及相關權限見Tushare官網,
pro = ts.pro_api(token)
# 獲取資料
df = pro.daily(ts_code='000001.SZ') # daily為tushare的股票日線資料介面,
df['trade_date'] = pd.to_datetime(df['trade_date'])
df.set_index(['trade_date'], inplace=True) # 將日期列作為行索引
df = df.sort_index()
ret = df.pct_chg['2020']
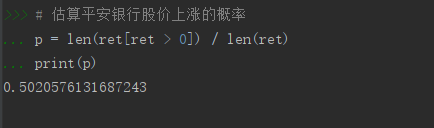
# 估算平安銀行股價上漲的概率
p = len(ret[ret > 0]) / len(ret)
print(p)
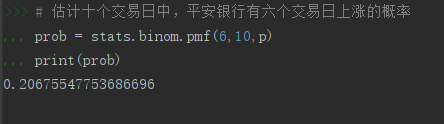
# 估計十個交易日中,平安銀行有六個交易日上漲的概率
prob = stats.binom.pmf(6,10,p)
print(prob)
4. 正態分布
4.1 正態分布概述
正態分布(Normal Distribution)又名高斯分布(Gaussiam Distribution),是人們最常用的描述連續型隨機變數的概率分布,在金融學研究中,收益率等變數的分布假定為正態分布或者對數正態分布(取對數后服從正態分布),因為形狀的原因,正態分布曲線也被經常稱為鐘形曲線,
正態分布分布律: 若隨機變數X滿足服從一個數學期望為u, 方差為
σ
2
\displaystyle \sigma^2
σ2的正態分布,記為X ~
(
N
,
σ
2
)
\displaystyle(N,\sigma^2 )
(N,σ2),則X的取值范圍為(
?
∞
,
+
∞
\displaystyle -\infty,+\infty
?∞,+∞),其概率密度為:
f
X
(
x
)
=
1
2
π
σ
e
x
p
[
?
(
x
?
u
)
2
2
σ
2
]
\displaystyle f_X\relax{(x)}=\frac{1}{\sqrt{2\pi\sigma}}exp\left[\frac{-(x-u)^2}{2\sigma^2}\right]
fX?(x)=2πσ
?1?exp[2σ2?(x?u)2?]
均值越大影像越靠右,方差越小影像越瘦高
服從正態分布的變數X滿足其線性變換aX+b~(
a
u
+
b
,
a
2
σ
2
\displaystyle au+b,a^2\sigma^2
au+b,a2σ2),
若令a =
1
σ
\displaystyle\frac{1}{\sigma}
σ1?,b =
?
u
σ
\displaystyle\frac{-u}{\sigma}
σ?u?,即可得到標準正態分布,該程序即標準化,數學式記作:
Z
=
X
?
u
σ
\displaystyle Z=\frac{X-u}{\sigma}
Z=σX?u? ~ N
(
0
,
1
)
\displaystyle(0,1)
(0,1)
任何正態分布都可以進行標準化,轉變成標準正態分布,
4.2 Python正態分布相關函式
正態分布亂數的生成函式是normal(),其語法為:
normal(loc=0.0, scale=1.0, size=None)
- 引數loc:表示正態分布的均值
- 引數scale:表示正態分布的標準差,默認為1
- 引數size:表示生成亂數的數量
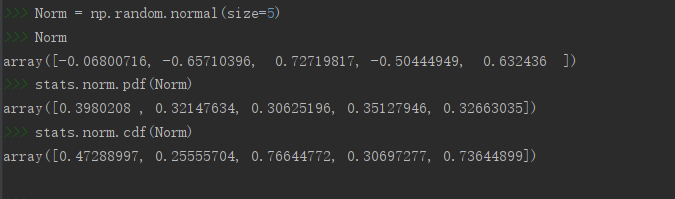
# 生成五個標準正態分布亂數
Norm = np.random.normal(size=5)
# 求生成的正態分布亂數的密度值
stats.norm.pdf(Norm)
# 求生成的正態分布亂數的累積密度值
stats.norm.cdf(Norm)
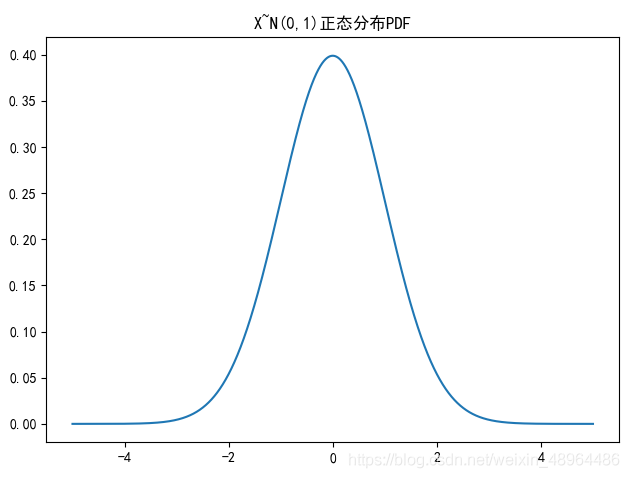
繪制正態分布PDF
# 注意這里使用的pdf和cdf函式是norm包里的
u=0
sigma=1
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('X~N({},{})正態分布PDF'.format(u,sigma**2))
x = np.linspace(-5,5,100000) # 設定分割區間
y1 = stats.norm.pdf(x,u,sigma**2)
plt.plot(x,y1)
plt.tight_layout() # 自動調整子圖,使之充滿畫布整個區域
plt.show()
影像效果:
繪制正態分布CDF
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('X~N({},{})正態分布CDF'.format(u,sigma**2))
x = np.linspace(-5,5,100000) # 設定分割區間
y2 = stats.norm.cdf(x,u,sigma**2)
plt.plot(x,y2)
plt.tight_layout()
plt.show()
影像效果:
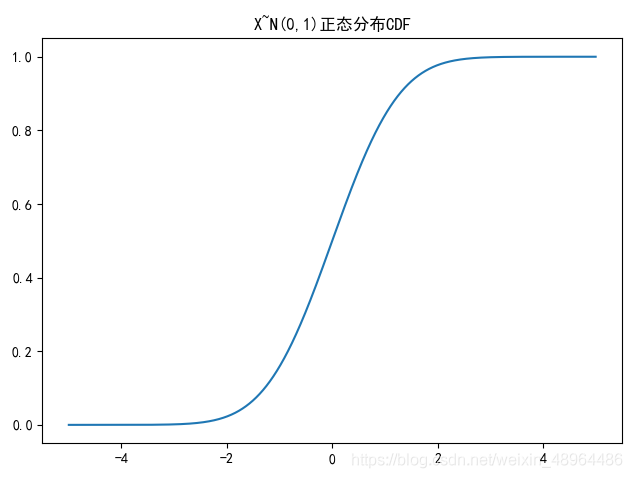
4.3 正態分布在金融市場的應用
VAR(Value at Risk),即在險價值,是指在一定概率水平(α%)下,某一金融資產或金融資產組合在未來特定一段時間內的最大可能的損失,該定義可表達為:
P
{
X
t
<
?
V
a
R
}
\displaystyle P\{X_t < -VaR\}
P{Xt?<?VaR} = α%
其中,隨機變數Xt為金融資產或金融資產組合在持有期
Δ
t
\displaystyle \Delta t
Δt內的損失,1-α%被叫做VaR的置信水平,
這里用到了ppf() 函式,來獲取指定分位數的累積密度值,
假設平安銀行股價2020年日收益率序列服從正態分布,下面用Python來求解當概率水平為5%時平安銀行股價日收益率在2021年初個交易日的VaR:
# 上邊已經定義過ret變數了,為平安銀行2020年股價日收益率資料,
# 這里直接接著使用
ret_mean = ret.mean() # 求均值
ret_variance = ret.var() # 求方差
# 查詢累積密度值為0.05的分位數
stats.norm.ppf(0.05, ret_mean, ret_variance**0.5)

也就是說,在2021年的第一個交易日,有95%概率平安銀行股票的損失不會超過3.475523569%,
(雖然當天實際跌了3.83,產生了例外值,)
5. 其他連續分布
5.1 卡方分布
若Z1, Z2, … Zn,為n個服從標準正態分布的隨機變數,則變數:
X
=
Z
1
2
+
Z
2
2
+
?
+
Z
n
2
\displaystyle X=Z_1^2+Z_2^2+\cdots+Z_n^2
X=Z12?+Z22?+?+Zn2?
服從自由度(Degree of Freedom)為n的卡方分布,
通常表示為 X 2 \displaystyle X^2 X2~ χ 2 \displaystyle \chi^2 χ2
因為n的取值可以不同,所以卡方分布是一族分布而不是一個單獨的分布,根據X的運算式,服從卡方分布的隨機變數值不可能取負值,其期望值為n,方差為2n,
plt.plot(np.arange(0, 5, 0.002),\
stats.chi.pdf(np.arange(0, 5, 0.002), 3))
plt.title('卡方分布PDF(自由度為3)')
生成影像如下:
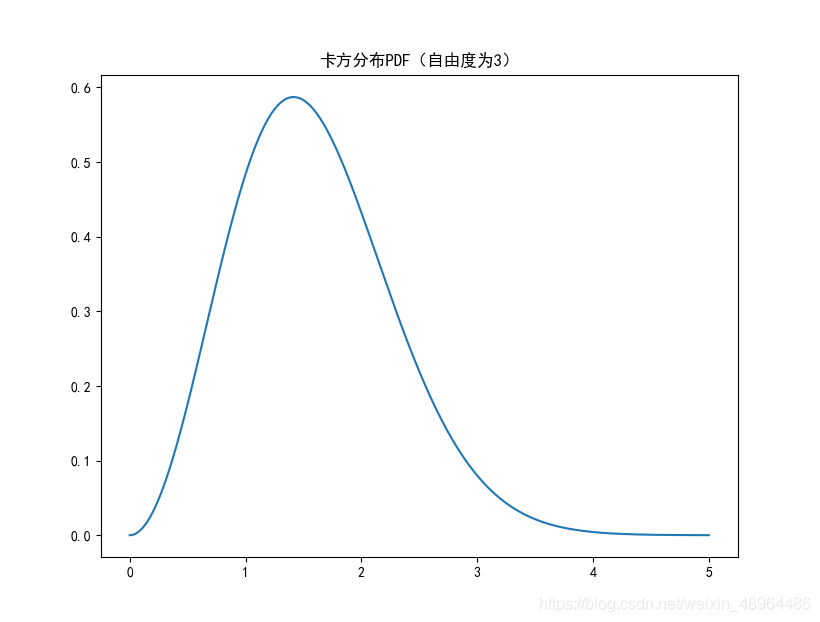
卡方分布以0為起點,分布是偏斜的,即非對稱的,在自由度為3的卡方分布下,大多數值都小于8,查表可知只有5%的值大于7.82%,
5.2 t分布
若隨機變數
Z
\displaystyle Z
Z ~
N
(
0
,
1
)
\displaystyle N(0,1)
N(0,1),
Y
\displaystyle Y
Y ~
χ
2
(
n
)
\displaystyle\chi^2(n)
χ2(n),且二者相互獨立,
則變數
X
=
Z
Y
/
n
\displaystyle X=\frac{Z}{\sqrt{Y/n}}
X=Y/n
?Z?服從自由度為n的t分布,
可以記作
X
\displaystyle X
X~
t
(
n
)
\displaystyle t(n)
t(n),
類似卡方分布,t分布也是整整一族,自由度n不同t分布即不同,
t分布變數取值范圍為(
?
∞
,
+
∞
\displaystyle -\infty,+\infty
?∞,+∞),其期望值與方差存在于否,取值大小均與t分布的自由度有關,
- t(1)分布無有限期望值,
- t(2)有有限期望值,但方差不存在,
- n>2時,t(n)才同時有有限的期望值和方差,其中期望值為0,方差為n/(n-2),因此自由度越大,變數的方差越小,也就是說分布的離散程度越小,
下邊使用Python繪制不同自由度下的t分布的概率分布圖:
x = np.arange(-4,4.004,0.004)
plt.plot(x, stats.norm.pdf(x), label='Normal')
plt.plot(x, stats.t.pdf(x,5), label='df=5')
plt.plot(x, stats.t.pdf(x,30), label='df=30')
plt.legend()
結果如圖所示:
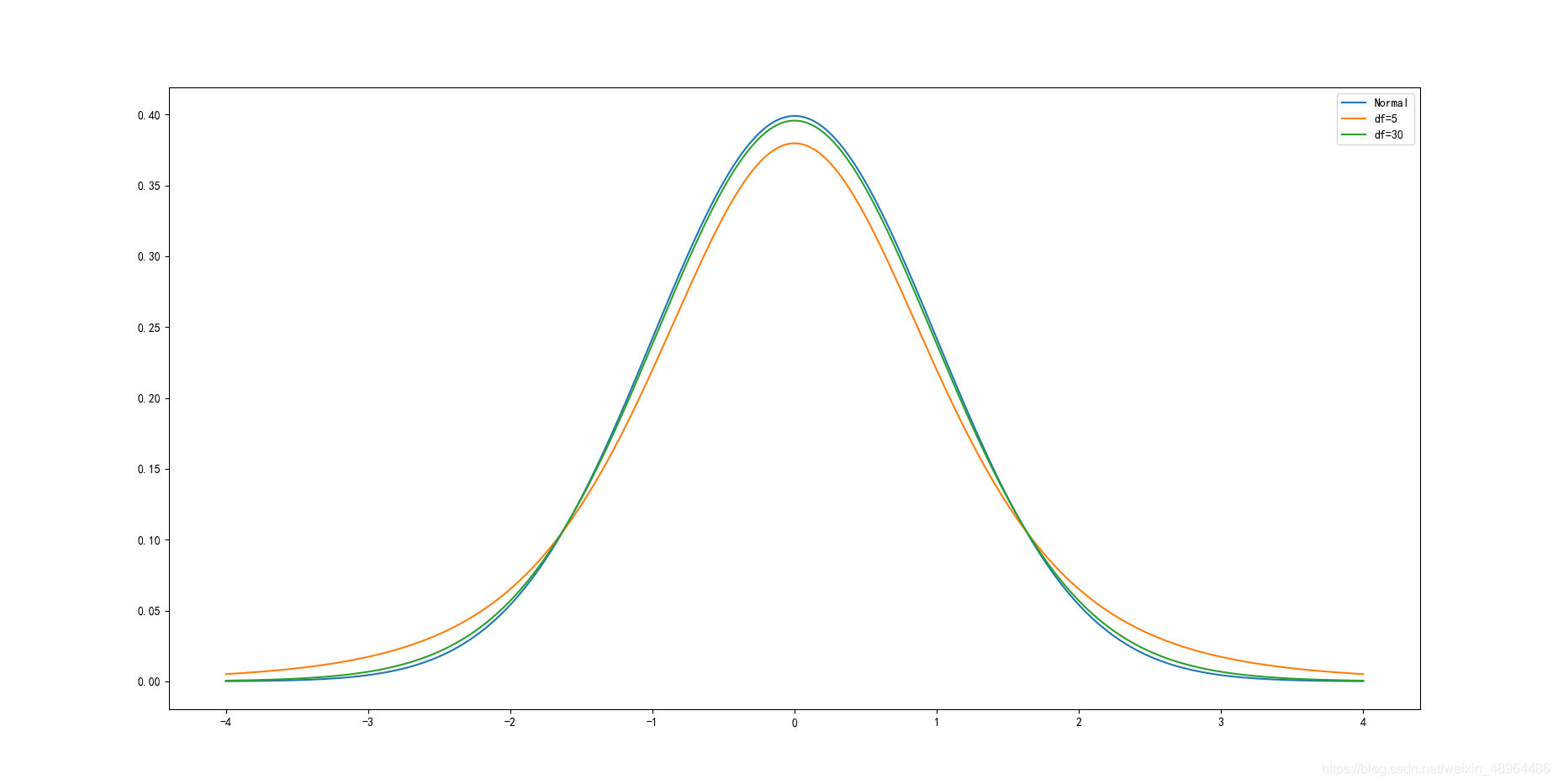
t分布的pdf曲線是以0為中心,左右對稱的單峰分布,其形態變化與自由度n的大小有關,自由度越小,分布越分散;自由度越大,變數在其均值周圍的聚集程度越高,也越接近標準正態分布曲線,
自由度為30時,t分布已經接近標準正態分布曲線,相較于標準正態分布,t分布的密度函式呈現出“尖峰厚尾”的特點,在現實中資產收益率分布往往呈現這種形態,因此t分布在對實際抽樣結果的刻畫上更為精確,t分布是在推斷統計中常用的分布,
————
5.3 F分布
若Z,Y為兩個獨立的隨機變數,且 Z \displaystyle Z Z~ χ 2 ( m ) \displaystyle \chi^2(m) χ2(m)、 Y \displaystyle Y Y~ χ 2 ( n ) \displaystyle ~\chi^2(n) χ2(n),
則變數 X = Z / m Y / n \displaystyle X=\frac{Z/m}{Y/n} X=Y/nZ/m?服從第一自由度為m,第二自由度為n的F分布,
記作X~ F ( m , n ) \displaystyle F(m, n) F(m,n)
變數X是兩個卡方變數(非負)之比,因此X的取值范圍也為非負,其期望和方差存在于否取決于第二自由度n,
n > 2時,才存在期望,為 n n ? 2 \displaystyle \frac{n}{n-2} n?2n?
n > 4時,才存在方差,為 2 n 2 ( m + n ? 2 ) m ( n ? 2 ) 2 ( n ? 4 ) \displaystyle \frac{2n^2(m+n-2)}{m(n-2)^2(n-4)} m(n?2)2(n?4)2n2(m+n?2)?
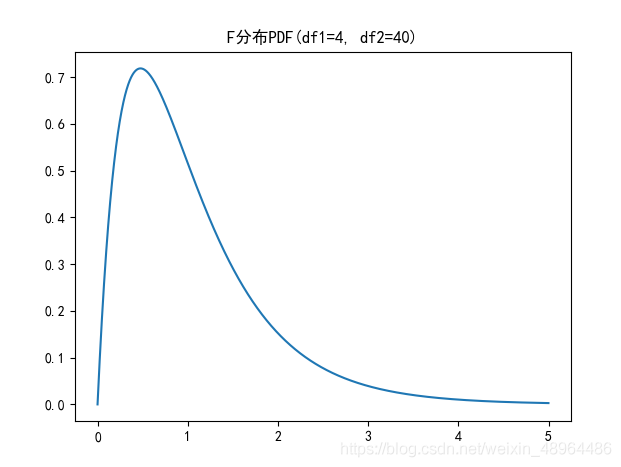
plt.plot(np.arange(0,5,0.002),\
stats.f.pdf(np.arange(0,5,0.002), 4, 40))
plt.title('F分布PDF(df1=4, df2=40)')
它的概率密度函式形態如圖所示
6. 變數的關系
我們面對的多個隨機變數,之間可能會有互相影響,
6.1 聯合概率分布
多個變數之間的聯合行為可以用聯合概率分布(Joint Probability Distribution)來刻畫,
若變數X, Y是離散的,其所有可能取值的集合為{ak}和{bk}, k=1,2,…,
則X,Y的聯合概率質量函式(Joint Probability Mass Function)為:
f
X
,
Y
(
a
,
b
)
=
P
{
X
=
a
i
且
Y
=
b
j
}
\displaystyle f_{X,Y}(a,b)=P\{X=a_i 且 Y=b_j\}
fX,Y?(a,b)=P{X=ai?且Y=bj?}, i,j=1,2…
雙變數X和Y的聯合累積分布函式(Joint Cumulative Distribution Function)為: F X , Y ( a , b ) = P { X ≤ a 且 Y ≤ b } \displaystyle F_X,Y(a,b)=P\{X \leq a 且 Y \leq b\} FX?,Y(a,b)=P{X≤a且Y≤b}
- 當X和Y是離散型的:
F ( X , Y ) ( a , b ) = ∑ i : a i ≤ a ∑ j : b j ≤ b P { X = a i 且 Y = b j } = ∑ i : a i ≤ a ∑ j : b j ≤ b f X , Y ( a i , b j ) \displaystyle F_{(X,Y)}(a,b)=\sum_{i:a_i \leq a} \sum_{j:b_j \leq b} P \{X=a_i且Y=b_j\}=\sum_{i:a_i \leq a} \sum_{j:b_j \leq b}f_{X,Y}(a_i,b_j) F(X,Y)?(a,b)=i:ai?≤a∑?j:bj?≤b∑?P{X=ai?且Y=bj?}=i:ai?≤a∑?j:bj?≤b∑?fX,Y?(ai?,bj?) - 當X和Y是連續型的:
F ( X , Y ) ( a , b ) = ∫ ? ∞ a ∫ ? ∞ b f X , Y ( x , y ) d x d y \displaystyle F_{(X,Y)}(a,b)=\int_{-\infty}^a\int_{-\infty}^bf_{X,Y}(x,y)dxdy F(X,Y)?(a,b)=∫?∞a?∫?∞b?fX,Y?(x,y)dxdy
其中
f
X
,
Y
(
x
,
y
)
d
x
d
y
\displaystyle f_{X,Y}(x,y)dxdy
fX,Y?(x,y)dxdy是聯合概率密度函式(Joint Probability Density Function)>
若已知X和Y的聯合概率分布,則X的期望值為:
E
(
X
)
=
∑
i
∑
j
a
i
f
X
,
Y
(
a
i
,
b
j
)
\displaystyle E(X)=\sum_i \sum_ja_if_{X,Y}(a_i,b_j)
E(X)=i∑?j∑?ai?fX,Y?(ai?,bj?)
= ∑ i a i ∑ j f X , Y ( a i , b j ) \displaystyle =\sum_i a_i\sum_jf_{X,Y}(a_i,b_j) =i∑?ai?j∑?fX,Y?(ai?,bj?)
= ∑ i a i f X ( a i ) \displaystyle =\sum_i a_if_X(a_i) =i∑?ai?fX?(ai?)
其中 f X ( a i ) = ∑ j f X , Y ( a i , b i ) \displaystyle f_X(a_i)=\sum_jf_{X,Y}(a_i,b_i) fX?(ai?)=j∑?fX,Y?(ai?,bi?)為變數X的邊際概率函式(Marginal Probability Function),代表的是變數X自己的概率分布,所以這里 f X ( a i ) \displaystyle f_X(a_i) fX?(ai?)依然滿足 f X ( a k ) = P { X = a k } \displaystyle {f_X}\relax{(a_k)}=P\{X=a_k\} fX?(ak?)=P{X=ak?}定義式,同理可得 E ( Y ) = ∑ j b j f Y ( b j ) \displaystyle E(Y)=\sum_j b_jf_Y(b_j) E(Y)=j∑?bj?fY?(bj?),其形式與單變數的形式無差別,方差求解亦是如此,
6.2變數的獨立性
如果隨機變數X和Y的聯合累積分布函式滿足:
F ( X , Y ) ( a , b ) = F X ( a ) F Y ( b ) \displaystyle F_{(X,Y)}(a,b)=F_X(a)F_Y(b) F(X,Y)?(a,b)=FX?(a)FY?(b)
則稱X和Y是獨立的,否則二者是相依的,
兩變數的獨立關系也可以表達成,
f X , Y ( a , b ) = f X ( a ) f Y ( b ) \displaystyle f_{X,Y}(a,b)=f_X(a)f_Y(b) fX,Y?(a,b)=fX?(a)fY?(b)
對于離散型隨機變數,此式等價于
P
{
X
=
a
且
Y
=
b
}
=
P
{
X
=
a
}
P
{
Y
=
b
}
\displaystyle P\{X=a且Y=b\}=P\{X=a\}P\{Y=b\}
P{X=a且Y=b}=P{X=a}P{Y=b}
變數之間的相互獨立是眾多統計分析的基本假設,也是變數之間的基本關系,
6.3 變數的相關性
隨機變數X和Y的協方差(Covariance)可以衡量二者之間的關系,描述的是兩隨機變數與各自期望的偏差共同的變動狀況,運算式為:
C
o
v
(
X
,
Y
)
=
E
[
(
X
?
E
(
X
)
)
(
Y
?
E
(
Y
)
)
]
Cov(X,Y)=E\left[(X-E(X))(Y-E(Y))\right]
Cov(X,Y)=E[(X?E(X))(Y?E(Y))]
協方差為正說明,平均而言變數X、Y與各自期望的偏差呈同方向變動;如果為負,則為反方向變動,
協方差有如下性質:
- C o v ( X , Y ) = C o v ( Y , X ) Cov(X,Y)=Cov(Y,X) Cov(X,Y)=Cov(Y,X)
- C o v ( a X , b Y ) = a b C o v ( Y , X ) Cov(aX,bY)=abCov(Y,X) Cov(aX,bY)=abCov(Y,X) (a,b是常數)
- C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( Y , X 2 ) Cov(X_1+X_2,Y)=Cov(X_1,Y)+Cov(Y,X_2) Cov(X1?+X2?,Y)=Cov(X1?,Y)+Cov(Y,X2?)
第二個性質說明,協方差受比例影響,并不能準確地衡量兩變數相關性的大小,,不能直接衡量兩變數相關性強弱,對協方差進一步處理,清除比例的影響,于是就有了相關系數(Correlation Coefficient):
ρ X , Y = C o v ( X , Y ) σ X σ Y \displaystyle \rho_{X,Y}=\frac{Cov(X,Y)}{\sigma_X\sigma_Y} ρX,Y?=σX?σY?Cov(X,Y)?
相關系數取值范圍為[-1,+1]
ρ=0時,說明兩個變數是不相關的,
0<ρ<1時, 說明兩變數呈正向的線性關系
-1<ρ<0時,說明兩變數呈負向的線性關系,
aX和bX的相關性:
ρ a X , b Y = C o v ( a X , b Y ) V a r ( a X ) ( V a r ( b Y ) ) \displaystyle \rho_{aX,bY}=\frac{Cov(aX,bY)}{\sqrt{Var{(aX)}}\sqrt{(Var(bY))}} ρaX,bY?=Var(aX) ?(Var(bY)) ?Cov(aX,bY)?
= a b C o v ( X , Y ) ∣ a ∣ σ X ∣ b ∣ σ Y \displaystyle=\frac{abCov(X,Y)} {|a|\sigma_X|b|\sigma_Y} =∣a∣σX?∣b∣σY?abCov(X,Y)?
= ± ρ X , Y \displaystyle=\pm \rho_{X,Y} =±ρX,Y?
如果變數Y是X的線性變換,滿足Y=a+bX,則二者之間的相關系數為:‘
ρ
X
,
Y
=
C
o
v
(
X
,
a
+
b
X
)
σ
X
V
a
r
(
a
+
b
X
)
\displaystyle \rho_{X,Y}=\frac{Cov(X,a+bX)}{\sigma_X\sqrt{Var(a+bX)}}
ρX,Y?=σX?Var(a+bX)
?Cov(X,a+bX)?
b V a r ( X ) ∣ b ∣ V a r ( X ) = ± 1 \displaystyle \frac{b{Var(X)}}{|b|Var(X)}=\pm1 ∣b∣Var(X)bVar(X)?=±1
6.4 上證指數與深證成指相關性分析
上證指數和深證成指是股票市場常用的反映股票市場情況的指數,我們認為兩個指數的日收益率可以存在相關的關系,代碼如下:
import numpy as np
import tushare as ts
import pandas as pd
token = 'Your Token' # 輸入你的介面密匙,獲取方式及相關權限見Tushare官網,
pro = ts.pro_api(token)
# 深證成指
SZindex = pro.index_daily(ts_code='399001.SZ')
SZindex['trade_date'] = pd.to_datetime(SZindex['trade_date'])
SZindex.set_index(['trade_date'], inplace=True)
SZindex = SZindex.sort_index()
# 上證指數
SHindex = pro.index_daily(ts_code='000001.SH')
SHindex['trade_date'] = pd.to_datetime(SHindex['trade_date'])
SHindex.set_index(['trade_date'], inplace=True)
SHindex = SHindex.sort_index()
# 用2020年日收益率資料繪制散點圖
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter(SHindex.pct_chg['2020'],SZindex.pct_chg['2020'])
plt.title('上證指數與深證成指2020年收益率散點圖')
plt.xlabel('上證指數收益率')
plt.ylabel('深證成指收益率')
plt.show()
生成影像展示如下:
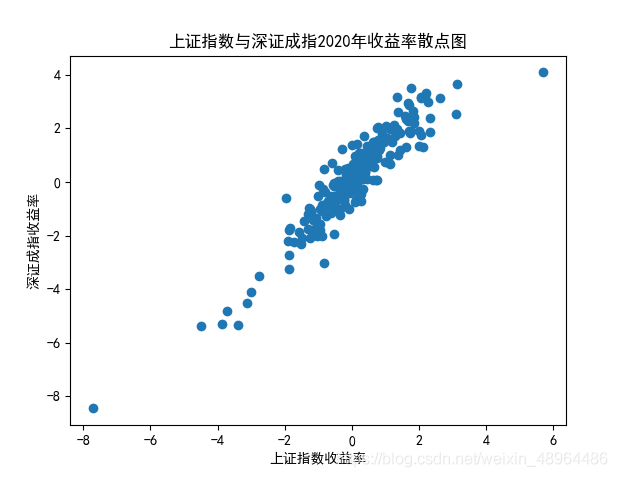
# 計算上證綜指和深證成指收益率相關系數
SHindex.pct_chg['2020'].corr(SZindex.pct_chg['2020'])

相關系數為0.9308847411746248,可以認為二者存在較強的相關性,二者呈現正向的線性關系,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/280366.html
標籤:python
上一篇:Python(七)之郵件處理