一、反爬蟲
1、反爬蟲介紹
反爬蟲是網站限制爬蟲的一種策略,它并不是禁止爬蟲(完全禁止爬蟲幾乎不可能,也可能誤傷正常用戶),而是限制爬蟲,讓爬蟲在網站可接受的范圍內爬取資料,不至于導致網站癱瘓無法運行,
具體網站有哪些反爬蟲措施參考文章:關于反爬蟲,看這一篇就夠了
2、爬取計劃A:請求頭(Request Headers)
通過qq音樂官網為例來講下其中一個反爬蟲的措施請求頭,
我們打開qq音樂官網,按鍵盤上的F12打開開發者工具,點擊Network標簽,然后在Name(請求名稱)列下隨便點擊一個打開
Tips:Network 記錄的是從打開瀏覽器的開發者工具到網頁加載完畢之間的所有請求,如果你在網頁加載完畢后打開,里面可能就是空的,我們開著開發者工具重繪一下網頁即可,
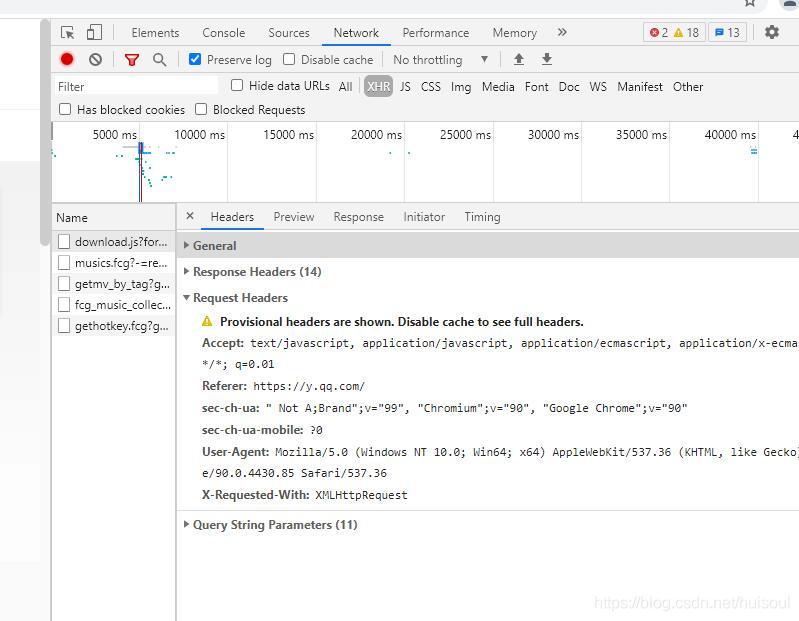
在Request Headers(請求頭)下存盤的就是我們訪問網站時用于身份識別的資訊,服務器會通過請求頭里的資訊來判別訪問者的身份,
Tips:訪問一般的網站,請求頭中只需要添加User-Agent就夠了,而有的網站比如微博就需要把Referer等其他請求頭資訊加進去,具體網站是以哪個為主要識別身份的,那么只能在實戰中一個個試了,
既然知道了網站是如何識別用戶身份的,我們就可以把請求頭加在requests里,例如↓
import requests
from bs4 import BeautifulSoup
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'}
res = requests.get('https://y.qq.com/',headers=header) #headers是一種反爬蟲措施
如果還要添加其他請求頭欄位,只用在header里以逗號為分隔隔開就好了,
3、爬取計劃B:設定爬取睡眠的時間
如果我們訪問過于頻繁,即使改了 user-agent 偽裝成瀏覽器了,也還是會被識別為爬蟲,并限制我們的 IP 訪問該網站,只要我們不過分,弄到服務器負荷過大,網站還是不會限制我們的,因此,我們常常使用 time.sleep() 來降低訪問的頻率,其實就等于給武器冷卻下,避免炸膛,
例如對某個網頁進行50頁的爬取時↓
import time
----中間代碼省略----
for k in range(1,50):
url = 'xxx網頁鏈接'.format(k)
time.sleep(2) #爬取一頁睡眠2s
browser.get(url)
通過上面的代碼,我們就將訪問頻率降了下來,雖然爬取速度被減慢了,但怎么也好過爬取不了吧= =
其他的爬取計劃就不制定了,這兩個已經足夠我們后續的爬取,想要了解更多的可以參考:史上最全反爬蟲方案匯總
4、robots.txt
robots.txt 是一種存放于網站根目錄下的文本檔案,用于告訴爬蟲此網站中的哪些內容是不應被爬取的,哪些是可以被爬取的,我們只要在網站域名后加上 /robots.txt 即可查看,
二、保存爬取資料到Excel
1、匯入模塊
from openpyxl import Workbook # 從 openpyxl 引入 Workbook(作業簿)類
2、使用openpyxl創建Excel表格
from openpyxl import Workbook # 從 openpyxl 引入 Workbook(作業簿)類
wb = Workbook() # 選擇默認的作業表
sheet = wb.active # 給作業表重命名
sheet.title = 'Python' #設定表格內的標題
wb.save('Python爬取求職網第三天.xlsx') # 保存 Excel 檔案
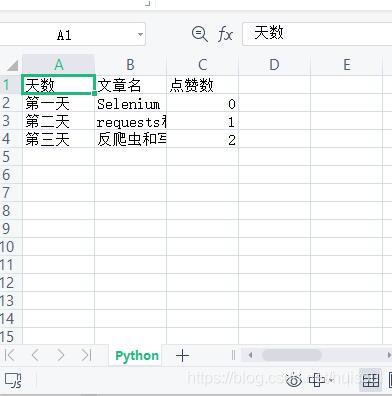
檔案夾截圖↓

保存的Excel檔案默認存放在Python代碼同目錄下,這里我們能看到通過上面的代碼,一個名為‘學習Python第三天’的Excel表格已經生成了,
3、往創建的表格記憶體放資料
存放資料的方法一般分為:格輸入和行輸入
- 格輸入↓
sheet['A1'] = '天數' # 往 A1 單元格寫入天數
- 行輸入↓
如果只有一行資料的時候,我們可以通過將各單元格的值以逗號分隔,將其裝進一個串列內,
row = ['天數', '文章名', '點贊數']# 寫入一行資料
sheet.append(row) #呼叫append()函式把以一行資料填進表格
但大多數情況下,我們輸入的資料絕不止僅僅一行而已,面對多行資料時,我們需要用一個for回圈遍歷這個串列,然后一行行地把資料填進表格內,我們通過下面的代碼看看面對大多數情況是如何存放資料的,
存放資料進Excel的完整代碼↓
from openpyxl import Workbook
wb = Workbook() # 新建作業簿
sheet = wb.active # 選擇默認的作業表
sheet.title = 'Python' # 給作業表重命名
data = [
['天數', '文章名', '點贊數'],
['第一天', 'Selenium', 0],
['第二天', 'requests和BeautifulSoup', 1],
['第三天', '反爬蟲和寫入檔案', 2]
]
# 寫入多行資料
for row in data:
sheet.append(row)
wb.save('Python爬取求職網第三天.xlsx') # 保存 Excel檔案
Excel表格內容截圖↓
三、保存爬取資料到Csv
保存資料的檔案格式除了Excel之外,還能選擇保存為.Csv檔案,方法只和Excel有些許不同,更重要的是相比較之下,保存為.csv的方法要更加的方便,
1、CSV介紹
CSV 全稱 Comma-Separated Values,它是一種通用的、相對簡單的檔案格式,和 JSON 一樣,CSV 也是按照一定規范書寫的文本,xlsx 格式的檔案是二進制的,只能被 Excel 打開,而 CSV 格式的檔案是純文本,當用 Excel 打開 CSV 檔案時,會將其決議成表格形式展示,和 xlsx 檔案相比,CSV檔案占用空間和內容小,打開的速度也更快,但CSV檔案功能受限,不能存盤圖表、公式、圖片等,
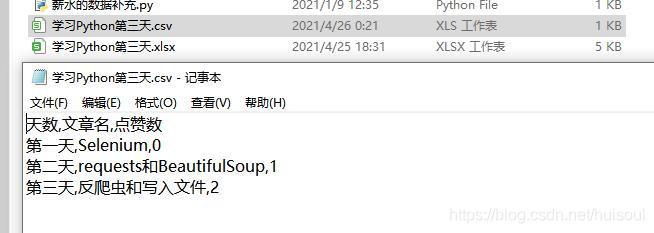
用記事本打開的話,它的名稱逗號分隔值一樣,每列資料都是用英文逗號分隔開的,而每行資料用換行符分隔,也就是每行資料都換行
2、匯入模塊
import csv
3、讀取csv檔案
我們把前面“Python爬取求職網第三天”的xlsx檔案,將其后綴名更改為csv檔案后為例

import csv
with open('學習Python第三天.csv', newline='') as file: #引數newline=''是為了讓檔案內容中的換行符能被正確決議
csv_reader = csv.reader(file)
for row in csv_reader:
print(row)
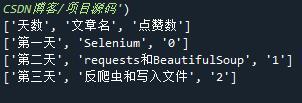
通過 import csv匯入 csv庫,然后用 open()函式打開 csv檔案,將得到的 file物件傳入 csv.reader() 方法進行處理,最終得到一個可讀取物件,我們可以用 for回圈遍歷得到的可讀取物件 csv_reader獲取 csv 檔案中的每一行資料,
Tips:如果出現編碼格式錯誤的話,可以在open()函式里增加一個encoding引數,如‘utf-8’,‘gbk’,‘gb18030’等,
輸出結果↓
4、CSV檔案寫入
與資料存入Excel表格的方法有些許不同,首先還是匯入 csv 庫,接著用 w 模式(寫入模式)新建一個 csv 檔案,然后將得到的 file 物件傳遞給 csv.writer() 方法進行處理,得到一個可寫入物件,接下來就可以用它來寫入 csv 檔案了,
代碼↓
import csv
with open('學習Python第三天.csv', 'w', newline='') as file:
csv_writer = csv.writer(file)
data = [
['天數', '文章名', '點贊數'],
['第一天', 'Selenium', 0],
['第二天', 'requests和BeautifulSoup', 1],
['第三天', '反爬蟲和寫入檔案', 2]
]
for row in data:
csv_writer.writerow(row)
和 openpyxl 類似,CSV 檔案也能逐行寫入,openpyxl 呼叫的是 append() 方法,而 CSV供了一個更加快捷的寫入多行內容的方法——writerows(),通過該方法不再需要使用 for 回圈,直接將多行資料的二維串列傳進去即可將表格的一行內容按順序放到串列中作為引數傳進去即可
好了,三篇文章已經把爬取網站前期準備介紹完了,下一篇文章將會向大家上一個實體,分享一下爬取一個網站的方法,
本次分享就到這里,謝謝大家!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/280701.html
標籤:python