k-means總結
- k-means
- 概述
- 基本概念
- 基本方法
- fit(X,y=None)
- predict(X)
- clustercenters
- labels_
- 作業流程
- 優勢 vs 劣勢
- 優勢
- 劣勢
- DBSCAN 演算法
- 概述
- 基本概念
- 圖解
- 作業流程
- 優勢 vs 劣勢
- 優勢
- 劣勢
- 總結
k-means
概述
k-means 通常被稱為勞埃德演算法, 是聚類演算法中最經典也是最容易理解的模型. 簡單的來說聚類就是把相似的東西分到一組.

基本概念
k 值:
- 要得到簇的個數
質心:
- 均值, 即向量各維度取平均即可
距離的度量:
- 歐幾里得距離和余弦相似度
優化目標:
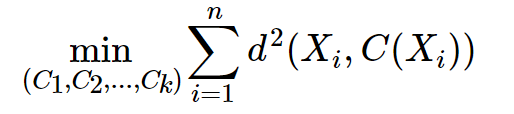
代碼:
class sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
"""
:param n_clusters:要形成的聚類數以及生成的質心數
:param init:初始化方法,默認為'k-means ++',以智能方式選擇k-均值聚類的初始聚類中心,以加速收斂;random,從初始質心資料中隨機選擇k個觀察值(行
:param n_init:int,默認值:10使用不同質心種子運行k-means演算法的時間,最終結果將是n_init連續運行在慣性方面的最佳輸出,
:param n_jobs:int用于計算的作業數量,這可以通過并行計算每個運行的n_init,如果-1使用所有CPU,如果給出1,則不使用任何并行計算代碼,這對除錯很有用,對于-1以下的n_jobs,使用(n_cpus + 1 + n_jobs),因此,對于n_jobs = -2,所有CPU都使用一個,
:param random_state:亂數種子,默認為全域numpy亂數生成器
"""
基本方法
fit(X,y=None)
使用 X 作為訓練資料擬合模型. 如:
kmeans.fit(X)
predict(X)
預測新的資料所在的類別. 如:
kmeans.predict([[0, 0], [4, 4]])
array([0, 1], dtype=int32)
clustercenters
獲取集群中心的點坐標. 如:
kmeans.cluster_centers_
array([[ 1., 2.],
[ 4., 2.]])
labels_
獲取每個點的類別. 如:
kmeans.labels_
作業流程
演算法的執行程序分為 4 個階段:
- 隨機設 k 個特征空間內的點作為初始的聚類中心
- 對于根據每個資料的特征向量, 從 k 個聚類中心中尋找最近的一個, 并把該暑假標記為這個聚類的中心
- 在所有的資料都被標記過聚類中心之后, 根據這些資料分配的類簇, 通過取分配每個先前質心的所有樣本的平均值來創建新的質心重, 新對 k 個聚類中心做計算
- 計算舊和新質心之間的差異. 如果所有的資料點從屬的聚類中心與上一次的分配的類簇沒有變化, 那么迭代就可以停止, 否則回到步驟 2 繼續回圈
優勢 vs 劣勢
優勢
- 演算法原理簡單, 可解釋性好
- 收斂速度快
- 調參的時候只需要改變 k 一個引數
劣勢
- k 值難以確定
- 復雜度與樣本呈線性關系
- 很難發現任意形狀的簇
DBSCAN 演算法
概述
DBSCAN 演算法 (Density-Based Spatial Clustering of Applications with Noise) 是一種基于密度空間聚類演算法.

基本概念
核心物件:
- 若某個點的密度達到演算法設定的閾值則其為核心點
- 即 r 鄰域內的點的數量不小于 minPts
鄰域的距離閾值:
- 設定的半徑 r
直接密度可達:
- 若某點 p 在點 q 的 r 鄰域內, 且 q 是核心點則 p-q 直接密度可達
密度可達:
- 若有一個點的序列 q0, q1, … qk, 對任意 qi-qi-1 是直接密度可達的, 則從 q0 到 qk 密度可達, 這實際上是直接密度可達的 “傳播”
密度相連:
- 若從某核心點 p 出發, 點 q 和點 k 都是密度可達的. 則稱點 q 和點 k 是密度相連的
邊界點:
- 屬于某一個類的非核心點, 不能發展下線了
噪聲點:
- 不屬于任何一個類簇的點, 從任何一個核心出發都是密度不可達的
圖解
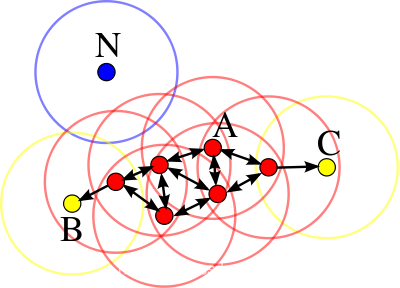
- A: 核心物件
- B, C: 邊界點
- N: 離群點
作業流程
- 引數 D: 輸入資料集
- 引數 e: 指定半徑
- MinPts: 密度閾值
優勢 vs 劣勢
優勢
- 不需要指定簇個數
- 可以發現任意形狀的簇
- 擅長找到離群點 (檢測任務)
- 只需兩個引數
劣勢
- 高維資料不是特別適用 (可以做降維)
- 引數對結果的影響非常大
- Sklearn 中效率并不是很高 (資料削減策略)
總結
DBSCAN 的總體效果比 k-means 好很多, 當我們需要用到聚類演算法的時候推薦使用 DBSCAN, 特別在資料不規則的情況下.

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/280703.html
標籤:python