文章目錄
- 1.什么是面向物件?
- 2.JDK JRE JVM
- 3.==和equals比較
- 4.為什么區域內部類和匿名內部類只能訪問區域final變數?
- 5.String、StringBuffer、StringBuilder
- 6.多載和重寫的區別
- 7.介面和抽象類的區別
- 8.hashCode與equals
- 9.List 和 Set的區別
- 10.ArrayList和LinkedList區別
- 11.HashMap和HashTable有什么區別?其底層實作是什么?
- 12.ConcurrentHashMap原理,jdk7和jdk8版本的區別
前言
本專題系列文章僅用于個人學習總結,從零開始逐步到常見服務框架,覺得基礎的大佬可以提前離開,本專欄作業之余抽空更新面試題…
java基礎
1.什么是面向物件?
??面向物件是更注重事情有哪些參與者(物件)、及各自需要做什么,(面向程序更注重事情的每一個步驟及順序) 其四大特征如下:
- 封裝: 封裝的意義,在于明確標識出允許外部使用的所有成員函式和資料項(內部細節對外部呼叫透明,外部呼叫無需修改或者關心內部實作)
- 繼承: 繼承基類(父類)的方法,并做出自己的改變和/或擴展(子類共性的方法或者屬性直接使用父類的,而不需要自己再定義,只需擴展自己個性化的)
- 多型: 基于物件所屬類的不同,外部對同一個方法的呼叫,實際執行的邏輯不同,(繼承和介面可以實作多型)
- 抽象: 抽取關鍵相關特性(屬性和方法)構成物件,用程式的方法邏輯和資料結構 屬性模擬現實的世界物件,(所有的物件都是通過類來描繪的,但是反過來,并不是所有的類都是用來描繪物件的,如果一個類中沒有包含足夠的資訊來描繪一個具體的物件,這樣的類就是抽象類,)
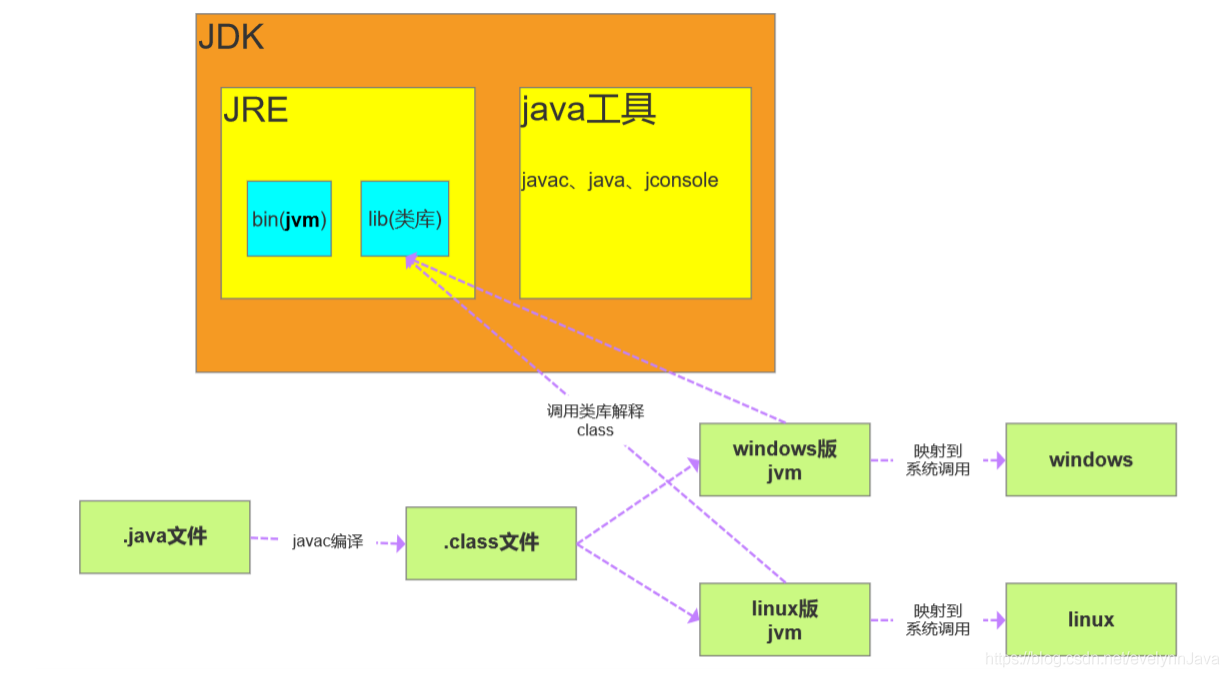
2.JDK JRE JVM
- JDK: Java Develpment Kit java 開發工具(程式員所需的各開發工具,包含 JRE JVM等)
- JRE: Java Runtime Environment java運行時環境(運行java程式)
- JVM: java Virtual Machine java 虛擬機(編譯,解釋.class檔案,作業系統才能夠執行)
3.==和equals比較
== : 對比的是堆疊中的值,基本資料型別是變數值,參考型別是堆中記憶體物件的地址
equals: Object中默認也是采用==比較(通常開發者要自己重寫,改為比較屬性內容)
ps: 初學者可能沒注意到這點,平時使用String比的也是內容,根本沒有去重寫它呀,實際上String類中,已經幫我們重寫了equals方法,
下面我們來看一個例子:
/**
* @author wook
* @date 2021/4/23 21:35
*/
public class WookTest {
private Integer id;
private String name;
public WookTest(Integer id,String name){
this.id = id;
this.name = name;
}
public static void main(String[] args) {
WookTest wook = new WookTest(1, "wook");
WookTest wook2 = new WookTest(1, "wook");
System.out.println(wook.equals(wook2));
}
}
根據開頭的概念,所有類都繼承Object,而Object的equals采用==比較記憶體地址,所以此處結果為:false ,那如果想讓結果回傳 :true 呢?
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
WookTest wookTest = (WookTest) o;
return Objects.equals(id, wookTest.id) &&
Objects.equals(name, wookTest.name);
}
只需要在WookTest中重寫equals即可(快捷鍵 ctrl + insert,選擇equals…),
ps: 細心的同學肯定發現了,equals和hashCode一般是成對出現的,equals搞明白了,那hashCode是干什么的呢?別著急,后面的文章會講到,(著急請翻到第8點=,=)
4.為什么區域內部類和匿名內部類只能訪問區域final變數?
首先回顧下 final修飾基本型別資料和參考型別資料 的情況:
- 如果是基本資料型別的變數,則其數值一旦在初始化之后便不能更改;
- 如果是參考型別的變數,則在對其初始化之后便不能再讓其指向另一個物件,但是參考的值是可變的,
public static void main() {
final int[] iArr = {1, 2, 3, 4};
iArr[2] = -3;//合法
iArr = null;//非法,對iArr不能重新賦值(不能重新指向)
final Person p = new Person(25);
p.setAge(24);//合法
p = null;//非法
}
回到正題 為什么區域內部類和匿名內部類只能訪問區域final變數?
/**
* @author wook
* @date 2021/4/23 22:35
*/
public class Test {
//區域final變數a,b
//jdk8在此處做了優化(語法糖),可不寫final,但實際上也是有的,引數a,b在內部類中不能修改
public void test(final int b) {
final int a = 10;
//匿名內部類
new Thread() {
public void run() {
System.out.println(a);
System.out.println(b);
}
}.start();
}
}
class OutClass {
private int age = 12;
public void outPrint(final int x) {
//區域內部類
class InClass {
public void InPrint() {
System.out.println(x);
System.out.println(age);
}
}
new InClass().InPrint();
}
}
ps:程式編譯后的檔案共有4個(內部類生成的class為原類名+$1…2…3)
- Test.class 、 Test$1.class
- ps: 再有匿名內部類則為 Test$2.class)
- OutClass.class 、 OutClass$1InClass.class
- ps: 再有區域內部類則為 OutClass$1其他內部類名
首先需要知道的一點: 內部類和外部類是處于同一個級別的,內部類不會因為定義在方法中就會隨著方法的執行完畢就被銷毀(例如開了執行緒跑匿名內部類),
這里就會產生問題:
- 當外部類的方法結束時,區域變數(a)就會被銷毀了,但是內部類物件可能還存在(只有沒有人再參考它時,才會死亡),這里就出現了一個矛盾:內部類物件訪問了一個不存在的變數,為了解決這個問題,就將區域變數復制了一份作為內部類的成員變數,這樣當區域變數死亡后,內部類仍可以訪問它,實際訪問的是區域變數的"copy",這樣就好像延長了區域變數的生命周期,
- 將區域變數復制為內部類的成員變數時,必須保證這兩個變數是一樣的,也就是如果我們在內部類中修改了成員變數,方法中的區域變數也得跟著改變,怎么解決問題呢?
- 就將區域變數設定為final,對它初始化后,我就不讓你再去修改這個變數,就保證了內部類的成員變數和方法的區域變數的一致性,這實際上也是一種妥協,使得區域變數與內部類內建立的拷貝保持一致,
答:因為內部類復制了一份作為內部類的成員變數,為保證復制的與原先的值一致,只能妥協,使用final修飾,不讓別人修改,
5.String、StringBuffer、StringBuilder
- String是final修飾的,不可變,每次操作都會產生新的String物件
- StringBuffer和StringBuilder都是在原物件上操作
- StringBuffer是執行緒安全的(方法都是synchronized修飾的)
- StringBuilder執行緒不安全的
性能: StringBuilder > StringBuffer > String
場景: 經常需要改變字串內容時使用后面兩個優先使用StringBuilder,多執行緒使用共享變數時使用StringBuffer,
6.多載和重寫的區別
多載: 發生在同一個類中,方法名必須相同,引數型別不同、個數不同、順序不同,方法回傳值和訪問修飾符可以不同,發生在編譯時,
重寫: 發生在父子類中,方法名、引數串列必須相同,回傳值范圍小于等于父類,拋出的例外范圍小于等于父類,訪問修飾符范圍大于等于父類;如果父類方法訪問修飾符為private則子類就不能重寫該方法,
public int add(int a,String b)
//編譯報錯(非多載)
public String add(int a,String b)
7.介面和抽象類的區別
- 抽象類可以存在普通成員函式,而介面中只能存在public abstract 方法,
- 抽象類中的成員變數可以是各種型別的,而介面中的成員變數只能是public static final型別的,
- 抽象類只能繼承一個,介面可以實作多個,
詳細說明:(趕時間知道上面三點即可)
??介面的設計目的,是對類的行為進行約束(更準確的說是一種“有”約束,因為介面不能規定類不可以有什么行為),也就是提供一種機制,可以強制要求不同的類具有相同的行為,它只約束了行為的有無,但不對如何實作行為進行限制,
??抽象類的設計目的,是代碼復用,當不同的類具有某些相同的行為(記為行為集合A),且其中一部分行為的實作方式一致時(A的真子集,記為B),可以讓這些類都派生于一個抽象類,在這個抽象類中實作了B,避免讓所有的子類來實作B,這就達到了代碼復用的目的,而A減B的部分,留給各個子類自己實作,正是因為A-B在這里沒有實作,所以抽象類不允許實體化出來(否則當呼叫到A-B時,無法執行),
ps: 真子集就是一個集合中的元素全部是另一個集合中的元素,
解釋一下抽象類的話:
- ①A類和B類都有action()方法,但實作不同
- ②A類和B類都有fun()方法,且實作相同
- ③可將A類和B類的fun()方法提取到抽象類C,A和B去繼承C
- ④而action則作為C類的抽象方法,由A和B去重寫
使用場景: 當你關注一個事物的本質的時候,用抽象類;當你關注一個操作的時候,用介面,
ps:抽象類的功能要遠超過介面,但是,定義抽象類的代價高,因為高級語言來說(從實際設計上來說也是)每個類只能繼承一個類,在這個類中,你必須繼承或撰寫出其所有子類的所有共性,雖然介面在功能上會榷訓許多,但是它只是針對一個動作的描述,而且你可以在一個類中同時實作多個介面,在設計階段會降低難度,(Java 8 介面default method不討論)
總結:
??抽象類是對類本質的抽象,表達的是 is a 的關系,比如: 寶馬是一輛車 ,抽象類包含并實作子類的通用特性,將子類存在差異化的特性進行抽象,交由子類去實作,
??而介面是對行為的抽象,表達的是 like a 的關系,比如: 鳥像飛行器一樣可以飛,但其本質上 is a Bird ,介面的核心是定義行為,即實作類可以做什么,至于實作類主體是誰、是如何實作的,介面并不關心,
8.hashCode與equals
hashCode介紹:
??hashCode() 的作用是獲取哈希碼,也稱為散列碼;它實際上是回傳一個int整數,這個哈希碼的作用是確定該物件在哈希表中的索引位置,hashCode() 定義在JDK的Object.java中,Java中的任何類都包含有hashCode() 函式,
??散串列存盤的是鍵值對(key-value),它的特點是:能根據“鍵(索引)”快速的檢索出對應的“值”,這其中就利用到了散列碼!(可以快速找到所需要的物件)
ps: hashCode方法的主要作用是為了配合基于散列的集合一起正常運行,這樣的散列集合包括HashSet、HashMap以及HashTable,
以“HashSet如何檢查重復”為例子來說明為什么要有hashCode:
??物件加入HashSet時,HashSet會先計算物件的hashcode值來判斷物件加入的位置,看該位置是否有值,如果沒有、HashSet會認為物件沒有重復出現,但是如果發現有值(hash沖突了),這時會呼叫equals()方法來檢查兩個物件是否真的相同,如果兩者相同,HashSet就不會讓其加入操作成功,如果不同的話,就會重新散列到其他位置,這樣就大大減少了equals的次數(equals性能較差),相應就大大提高了執行速度,
- 如果兩個物件相等,則hashcode一定也是相同的
- 兩個物件相等,對兩個物件分別呼叫equals方法都回傳true
- 兩個物件有相同的hashcode值,它們也不一定是相等的
- equals方法被覆寫過,則hashCode方法也必須被覆寫
- hashCode()的默認行為是對堆上的物件產生獨特值,如果沒有重寫hashCode(),則該class的兩個物件無論如何都不會相等(即使這兩個物件指向相同的資料(內容))
理論明白了,下面通過代碼來說明:
ps:代碼參照海子大佬 https://www.cnblogs.com/dolphin0520/p/3681042.html
import java.util.HashMap;
import java.util.HashSet;
import java.util.Set;
class People{
private String name;
private int age;
public People(String name,int age) {
this.name = name;
this.age = age;
}
public void setAge(int age){
this.age = age;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
return this.name.equals(((People)obj).name) && this.age== ((People)obj).age;
}
}
public class Main {
public static void main(String[] args) {
People p1 = new People("Jack", 12);
System.out.println(p1.hashCode());
HashMap<People, Integer> hashMap = new HashMap<People, Integer>();
hashMap.put(p1, 1);
System.out.println(hashMap.get(new People("Jack", 12)));
}
}
這里我只重寫了equals方法,也就說如果兩個People物件,如果它的姓名和年齡相等,則認為是同一個人,
這段代碼本來的意愿是想這段代碼輸出結果為“1”,但是事實上它輸出的是“null”,為什么呢?原因就在于重寫equals方法的同時忘記重寫hashCode方法,
雖然通過重寫equals方法使得邏輯上姓名和年齡相同的兩個物件被判定為相等的物件(跟String類類似),但是要知道默認情況下,hashCode方法是將物件的存盤地址進行映射,那么上述代碼的輸出結果為“null”就不足為奇了,原因很簡單,p1指向的物件和System.out.println(hashMap.get(new People(“Jack”, 12)));這句中的new People(“Jack”, 12)生成的是兩個物件,它們的存盤地址肯定不同,下面是HashMap的get方法的具體實作:
所以在hashmap進行get操作時,因為得到的hashcdoe值不同(注意,上述代碼也許在某些情況下會得到相同的hashcode值,不過這種概率比較小,因為雖然兩個物件的存盤地址不同也有可能得到相同的hashcode值),所以導致在get方法中for回圈不會執行,直接回傳null,
因此如果想上述代碼輸出結果為“1”,很簡單,只需要重寫hashCode方法,讓equals方法和hashCode方法始終在邏輯上保持一致性,
import java.util.HashMap;
import java.util.HashSet;
import java.util.Set;
class People{
private String name;
private int age;
public People(String name,int age) {
this.name = name;
this.age = age;
}
public void setAge(int age){
this.age = age;
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
return name.hashCode()*37+age;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
return this.name.equals(((People)obj).name) && this.age== ((People)obj).age;
}
}
public class Main {
public static void main(String[] args) {
People p1 = new People("Jack", 12);
System.out.println(p1.hashCode());
HashMap<People, Integer> hashMap = new HashMap<People, Integer>();
hashMap.put(p1, 1);
System.out.println(hashMap.get(new People("Jack", 12)));
}
}
這樣一來的話,輸出結果就為“1”了,
“設計hashCode()時最重要的因素就是:無論何時,對同一個物件呼叫hashCode()都應該產生同樣的值,如果在講一個物件用put()添加進HashMap時產生一個hashCdoe值,而用get()取出時卻產生了另一個hashCode值,那么就無法獲取該物件了,所以如果你的hashCode方法依賴于物件中易變的資料,用戶就要當心了,因為此資料發生變化時,hashCode()方法就會生成一個不同的散列碼”,
import java.util.HashMap;
import java.util.HashSet;
import java.util.Set;
class People{
private String name;
private int age;
public People(String name,int age) {
this.name = name;
this.age = age;
}
public void setAge(int age){
this.age = age;
}
@Override
public int hashCode() {
// TODO Auto-generated method stub
return name.hashCode()*37+age;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
return this.name.equals(((People)obj).name) && this.age== ((People)obj).age;
}
}
public class Main {
public static void main(String[] args) {
People p1 = new People("Jack", 12);
System.out.println(p1.hashCode());
HashMap<People, Integer> hashMap = new HashMap<People, Integer>();
hashMap.put(p1, 1);
p1.setAge(13);
System.out.println(hashMap.get(p1));
}
}
這段代碼輸出的結果為“null”,想必其中的原因大家應該都清楚了,
因此,在設計hashCode方法和equals方法的時候,如果物件中的資料易變,則最好在equals方法和hashCode方法中不要依賴于該欄位,
9.List 和 Set的區別
- List: 有序,按物件進入的順序保存物件,可重復,允許多個Null元素物件,可以使用Iterator取出所有元素,在逐一遍歷,還可以使用get(int index)獲取指定下標的元素
- Set: 無序,不可重復,最多允許有一個Null元素物件,取元素時只能用Iterator介面取得所有元素,在逐一遍歷各個元素 (沒有get方法)
10.ArrayList和LinkedList區別
ArrayList: 基于動態陣列,連續記憶體存盤,適合下標訪問(隨機訪問)
- 擴容機制:
- 因其基于陣列,而陣列長度固定,超出長度存資料時會新建更大的陣列,然后將老陣列的資料拷貝到新陣列,
- 插入機制:
- 性能差:如果從前,中間插入元素會涉及元素移動,例 [1,3,4…],要在3前面插入元素2,此時會將4的值賦值到后面的索引位,3的值賦值到4的索引位,插入的元素2賦值到3的索引位,從而實作插入,
- 性能好:使用尾插法(不會導致元素移動)并指定初始容量可以極大提升性能、甚至超過linkedList
LinkedList: 基于鏈表,可以存盤在分散的記憶體中,適合做資料插入及洗掉操作,不適合查詢
- 缺點1:極其不建議使用for回圈,因為每次for回圈體內通過get(i)取元素,實際上都需要對list集合重新進行遍歷,性能消耗極大,(建議使用迭代器iterator)
- 缺點2:不要試圖使用indexOf等回傳元素索引,并利用其進行遍歷,使用indexlOf對list進行了遍歷,當結果為空時會遍歷整個串列,
- 缺點3:每插入任意元素,都需要new一個node節點,而arrayList放什么就存什么,
ps:上面列舉了那么多缺點,個人建議使用哪個就不用我說了吧?
11.HashMap和HashTable有什么區別?其底層實作是什么?
區別 :
①HashMap方法沒有synchronizedHashTable 修飾,執行緒非安全, 執行緒安全;
②HashMap允許key和value為null,而HashTable不允許
底層實作: 陣列+鏈表實作(JDK 1.7)
ps: jdk8開始鏈表高度到8、陣列長度超過64,鏈表轉變為紅黑樹,元素以內部類Node節點存在
- 計算key的hash值,二次hash然后位與陣列長度-1(hash & length -1 ),得到陣列下標(有點類似取模,例如 3%16,3永遠在16范圍內)
- 如果沒有產生hash沖突(下標位置沒有元素),則直接創建Node存入陣列
- 如果產生hash沖突,先進行equal比較,相同則取代該元素,不同,則判斷鏈表高度插入鏈表,鏈表高度達到8,并且陣列長度到64則轉變為紅黑樹,長度低于6則將紅黑樹轉回鏈表
- key為null,存在下標0的位置
擴容: 當HashMap元素>= 擴容閾值,會擴容為原來的兩倍,
例:初始容量16,負載因子固定為0.75; 16 * 0.75 = 12 ,元素過12個就會擴容,
二次Hash: 防止高位都是0,只有低位在參與位與運算,如下代碼結果都為15,,瘋狂hash沖突
System.out.println(Integer.parseInt("0001111", 2) & Integer.parseInt("0001111", 2));
System.out.println(Integer.parseInt("0011111", 2) & Integer.parseInt("0001111", 2));
System.out.println(Integer.parseInt("0111111", 2) & Integer.parseInt("0001111", 2));
System.out.println(Integer.parseInt("1111111", 2) & Integer.parseInt("0001111", 2));
12.ConcurrentHashMap原理,jdk7和jdk8版本的區別
jdk7:
資料結構: ReentrantLock+Segment+HashEntry,一個Segment中包含一個HashEntry陣列,每個HashEntry的索引又是一個鏈表結構(類似hashMap,只是外部多了個 Segment分段的概念)
ps: ReentrantLock是李二狗寫的可重入鎖,在jdk1.8之前,synchronized遠不如它,
元素查詢: 二次hash,第一次Hash定位到Segment,第二次Hash定位到元素所在的鏈表的頭部,
鎖: Segment分段鎖 Segment繼承ReentrantLock,鎖定操作的Segment,其他的Segment不受影響,segment個數相當于可同時并發的數量,可通過建構式指定;陣列擴容不會影響其他的segment,
jdk8:
資料結構: synchronized+CAS+Node+紅黑樹,Node的val和next都用volatile修飾,保證可見性,(查找,替換,賦值操作都使用CAS,性能比syn高,但CAS執行緒競爭激烈的時候會自旋浪費cpu,所以擴容,hash沖突等會使用syn鎖)
鎖: 鎖鏈表的head節點,不影響其他元素的讀寫,鎖粒度更細,效率更高,擴容時,阻塞所有的讀寫操作、并發擴容
ps: 兩個版本讀操作無鎖,Node的val和next使用volatile修飾,讀寫執行緒對該變數互相可見;陣列用volatile修飾,保證擴容時被讀執行緒感知,但不保證原子性,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/280743.html
標籤:java