文章目錄
- 一、前言
- 二、k-means聚類
- 三、影像分類
一、前言
本文使用的是 kaggle 貓狗大戰的資料集:https://www.kaggle.com/c/dogs-vs-cats/data
訓練集中有 25000 張影像,測驗集中有 12500 張影像,作為簡單示例,我們用不了那么多影像,隨便抽取一小部分貓狗影像到一個檔案夾里即可,

通過使用更大、更復雜的模型,可以獲得更高的準確率,預訓練模型是一個很好的選擇,我們可以直接使用預訓練模型來完成分類任務,因為預訓練模型通常已經在大型的資料集上進行過訓練,通常用于完成大型的影像分類任務,
tf.keras.applications中有一些預定義好的經典卷積神經網路結構(Application應用),如下所示:
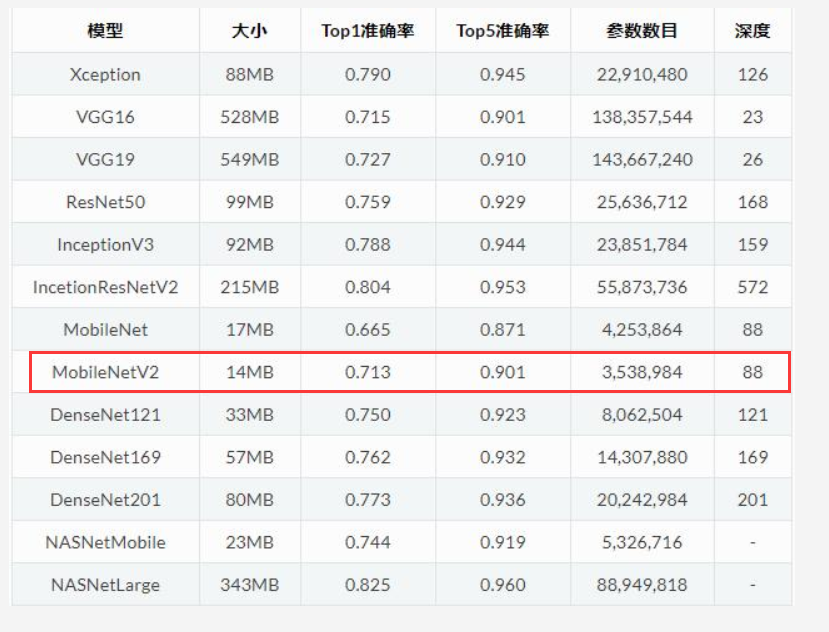
我們可以直接呼叫這些經典的卷積神經網路結構(甚至載入預訓練的引數),而無需手動來構建網路結構,
例如,本文將要用到的模型是由谷歌開發的 MobileNetV2 網路結構,該模型已經在 ImageNet 資料集上進行過預訓練,共含有 1.4M 張影像,而且學習了常見的 1000 種物體的基本特征,因此,該模型具有強大的特征提取能力,
model = tf.keras.applications.MobileNetV2()
當執行以上代碼時,TensorFlow會自動從網路上下載 MobileNetV2 網路結構,運行代碼后需要等待一會會兒~~,MobileNetV2模型的速度很快,而且耗費資源也不是很多,
二、k-means聚類
k-means聚類演算法以 k 為引數,把 n 個物件分成 k 個簇,使簇內具有較高的相似度,而簇間的相似度較低,其處理程序如下:
- 隨機選擇 k 個點作為初始的聚類中心
- 對于剩下的點,根據其與聚類中心的距離,將其歸入最近的簇,
- 對每個簇,計算所有點的均值作為新的聚類中心,
- 重復步驟2、3直到聚類中心不再發生改變
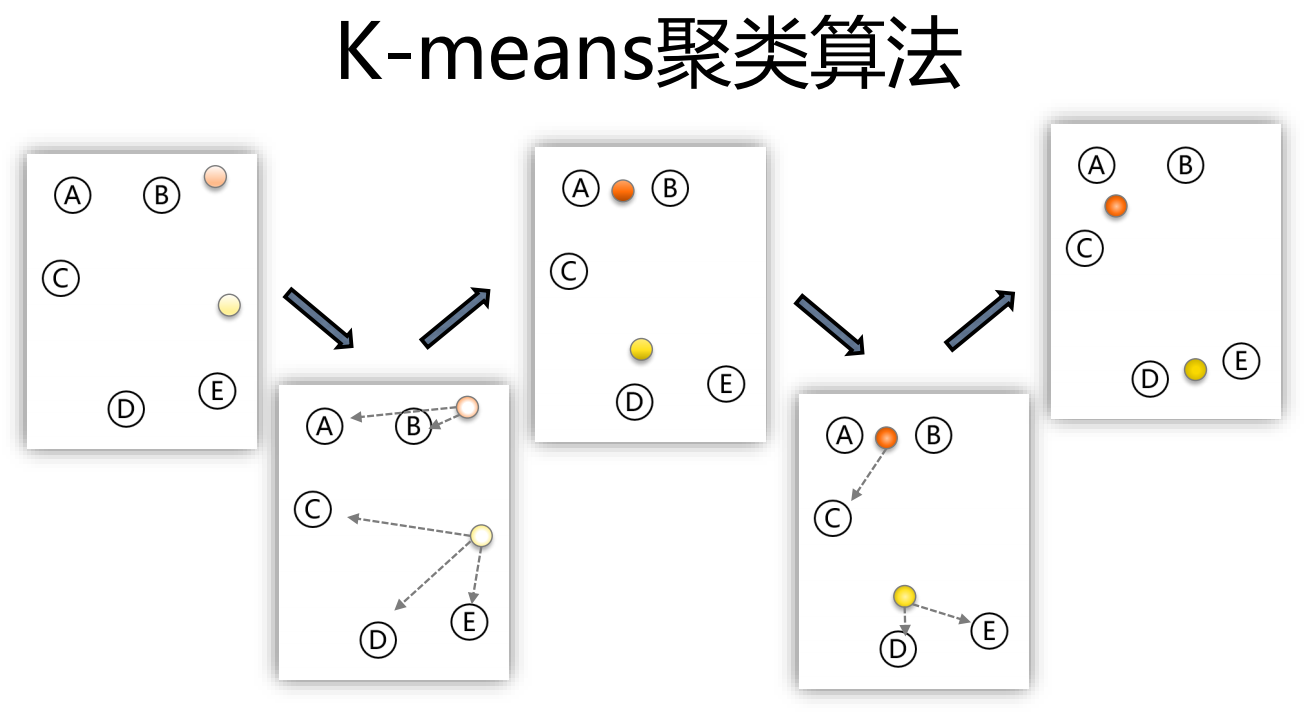
k-means的演算法原理比較非常簡潔、易于理解,但是這里面有個問題需要解決:
如何確定 k 值?
- 在 k-means 演算法實作程序中,首先面臨的問題就是如何確定好 K 值,因為在實際應用中,我們也不知道這些資料到底會有多少個類別,或者分為多少個類別會比較好,所以在選擇 K 值的時候會比較困難,只能根據經驗預設一個數值,
- 比較常用的一個方法:肘部法,就是去回圈嘗試 K 值,計算在不同的 K 值情況下,所有資料的損失,即用每一個資料點到中心點的距離之和計算平均距離,可以想到,當 K=1 的時候,這個距離和肯定是最大的;當 K=m 的時候,每個點也是自己的中心點,這個時候全域的距離和是0,平均距離也是0,當然我們不可能設定成K=m,
- 而在逐漸加大 K 的程序中,會有一個點,使這個平均距離發生急劇的變化,如果把這個距離與 K 的關系畫出來,就可以看到一個拐點,也就是我們說的手肘,
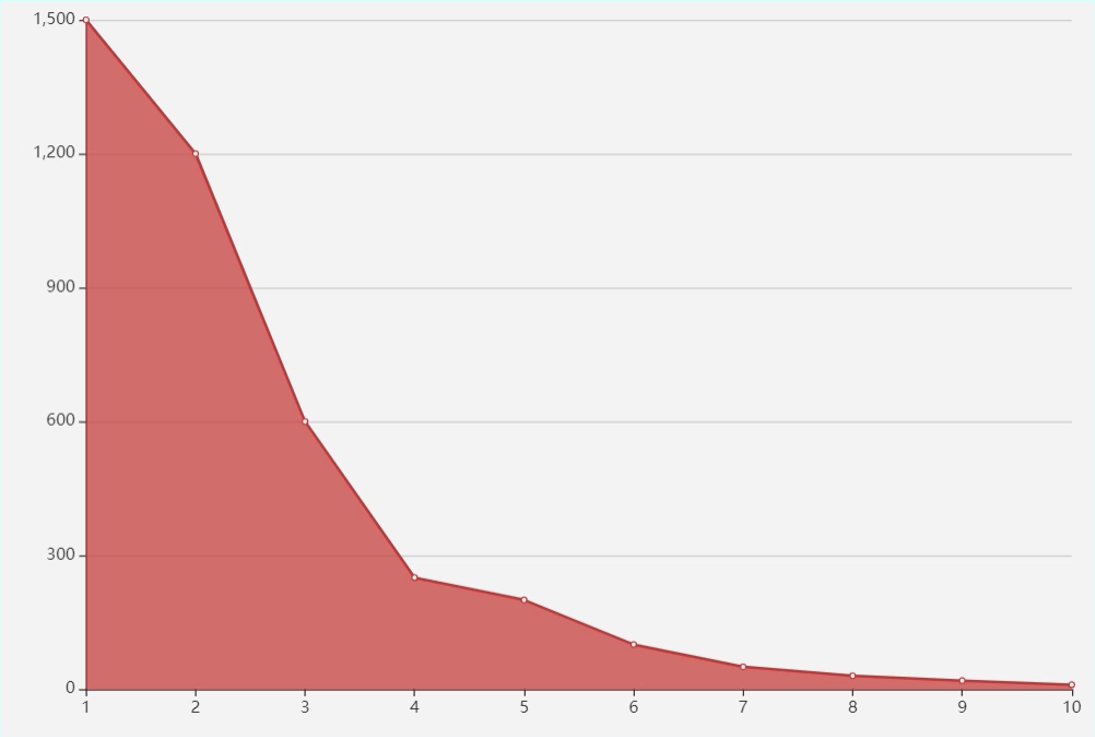
要確定 K 值確實是一項比較費時費力的事情,但是也是 K-Means 聚類演算法中必須要做好的作業,
三、影像分類
現在進入正題,實作我們的貓狗影像分類,
匯入需要的依賴庫
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import cv2 as cv
import os, shutil
from pathlib import Path
獲取 animals 檔案夾下所有 jpg 貓狗影像
# 獲得該檔案夾下所有jpg圖片路徑
p = Path(r"C:\Users\Administrator\DeepLearning\animals")
files = list(p.glob("**/*.jpg"))
opencv讀取影像,并將影像大小 resize 為(224,224),以匹配模型輸入層的大小以進行特征提取,影像陣列轉換為 float32 型別并reshape,然后做歸一化,
# opencv讀取影像 并resize為(224,224)
images = [cv.resize(cv.imread(str(file)), (224, 224)) for file in files]
paths = [file for file in files]
# 影像陣列轉換為float32型別并reshape 然后做歸一化
images = np.array(np.float32(images).reshape(len(images), -1) / 255)
加載預訓練模型 MobileNetV2 來實作影像分類
# 加載預先訓練的模型MobileNetV2來實作影像分類
model = tf.keras.applications.MobileNetV2(include_top=False,
weights="imagenet", input_shape=(224, 224, 3))
predictions = model.predict(images.reshape(-1, 224, 224, 3))
pred_images = predictions.reshape(images.shape[0], -1)
k-means聚類演算法
k = 2 # 2個類別
# K-Means聚類
kmodel = KMeans(n_clusters=k, n_jobs=-1, random_state=888)
kmodel.fit(pred_images)
kpredictions = kmodel.predict(pred_images)
print(kpredictions) # 預測的類別
# 0:dog 1:cat
將分類后的影像保存到不同檔案夾下
for i in ["cat", "dog"]:
os.mkdir(r"C:\Users\Administrator\DeepLearning\picture_" + str(i))
# 復制檔案,保留元資料 shutil.copy2('來源檔案', '目標地址')
for i in range(len(paths)):
if kpredictions[i] == 0:
shutil.copy2(paths[i], r"C:\Users\Administrator\DeepLearning\picture_dog")
else:
shutil.copy2(paths[i], r"C:\Users\Administrator\DeepLearning\picture_cat")
結果如下:
貓狗影像分類
推薦閱讀:
https://keras-cn.readthedocs.io/en/latest/other/application/
https://www.freesion.com/article/6932673943/
https://mp.weixin.qq.com/s/64fgbm4QESz-irwY0uUYOA
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/281269.html
標籤:python