python處理excel實作自動化辦公
介紹
實作的是把某個檔案夾下的所有檔案名提取出來,放入一個串列,在與excel中的某列進行對比,如果一致的話,對另一列進行操作,比如我們在統計人員活動情況的時候,對參加的人需要進行記錄,
截圖
- 代統計名單
比如下面這個目錄是參與活動的人員名單,每個檔案夾為每個人參與活動的相關資料,有些目錄是很多人一起參與一個活動,這個時候我要把檔案遍歷,把名字輸入到一個串列中,
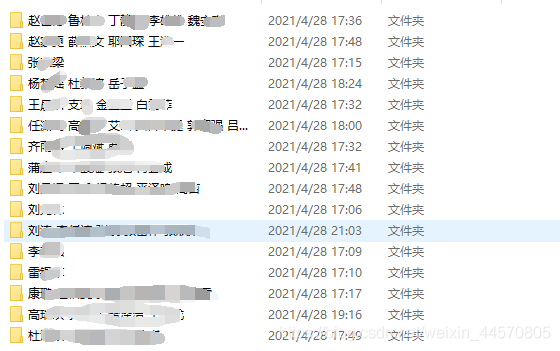
相關代碼如下:
# 保存指定目錄下檔案名到串列
def Save_name(dirPath):
filePath = dirPath
names = os.listdir(filePath)
return names
# 處理檔案名
def progress_name(name):
result = []
for str in name:
str_list = str.split()
for i in str_list:
result.append(i)
return result
- 代處理的excel如下:
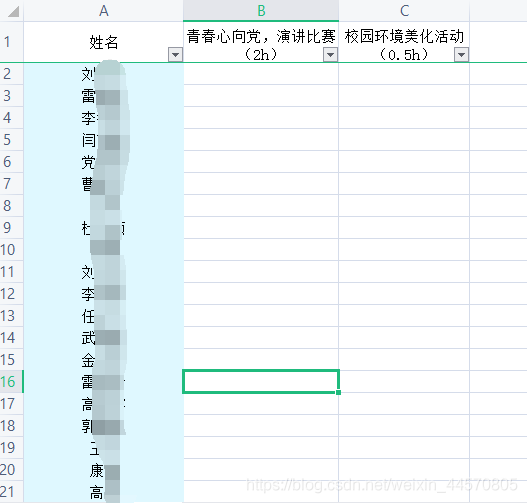
處理excel我用到的是pandas庫,相關代碼如下:
# 處理excel表
def progress_excel(name, filepath, col):
data1 = pd.DataFrame(pd.read_excel(filepath)) # 這個會直接默認讀取到這個Excel的第一個表單
data = data1.head(70) # 默認讀取前5行的資料
num = data.index
for i in name:
for j in num:
if data['姓名'].loc[j] == i:
data[col].loc[j] = 0.5
print(data)
DataFrame(data).to_excel('活動記錄.xlsx', sheet_name='Sheet1', index=False, header=True)
代碼運行后如下:
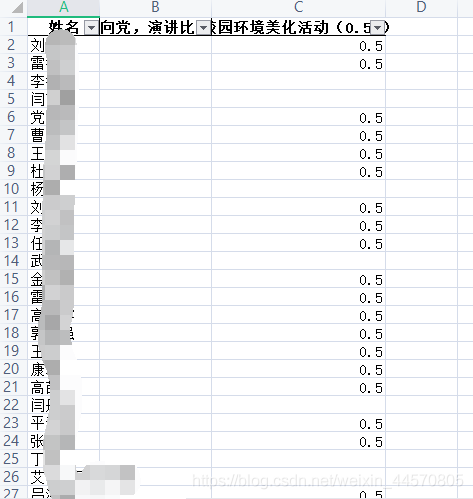
可以看到,成功處理了我需要他處理的列,并進行時長的統計
完整代碼
import os
import pandas as pd
from pandas import DataFrame
# 保存指定目錄下檔案名到串列
def Save_name(dirPath):
filePath = dirPath
names = os.listdir(filePath)
return names
# 處理檔案名
def progress_name(name):
result = []
for str in name:
str_list = str.split()
for i in str_list:
result.append(i)
return result
# 處理excel表
def progress_excel(name, filepath, col):
data1 = pd.DataFrame(pd.read_excel(filepath)) # 這個會直接默認讀取到這個Excel的第一個表單
data = data1.head(70) # 默認讀取前5行的資料
num = data.index
for i in name:
for j in num:
if data['姓名'].loc[j] == i:
data[col].loc[j] = 0.5
print(data)
DataFrame(data).to_excel('活動記錄.xlsx', sheet_name='Sheet1', index=False, header=True)
if __name__ == '__main__':
path = 'F:\\黨支部\\環境美化活動' # 要提取檔案夾名的路徑
names = Save_name(path)
filenames = progress_name(names)
# print(filenames)
# print(len(filenames))
excelname = 'F:\\黨支部\\活動記錄.xlsx' # 要處理的表
col = '校園環境美化活動(0.5h)' # 要處理的列
progress_excel(filenames, excelname, col)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/281642.html
標籤:python