重要提醒:網路爬取盜亦有道,本教程僅做技術交流,不做任何商業用途,請大家遵守網路商業環境
#編程新人第一次寫文章,技術不成熟之處望各位大神輕噴,指出來我也可以更快進步,謝謝大家了!!!提前謝謝大家的一鍵三連
#這是爬取后的結果,可自定義爬取頁數,我這里只爬取了2頁(手機熱點開著爬取,爬多了流量著不住啊!!!o(╥﹏╥)o)
先看看爬取結果吧~

1、技術路線
requests:網頁請求
BeautifulSoup:決議html網頁
re:正則運算式,提取html網頁資訊
os:保存檔案
import re
import requests
import os
from bs4 import BeautifulSoup
2、獲取網頁資訊
常規操作,獲取網頁資訊的固定格式,回傳的字串格式的網頁內容,其中headers引數可模擬人為的操作,‘欺騙’網站不被發現
def getHtml(url): #固定格式,獲取html內容
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
} #模擬用戶操作
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('網路狀態錯誤')
3、網頁爬取分析
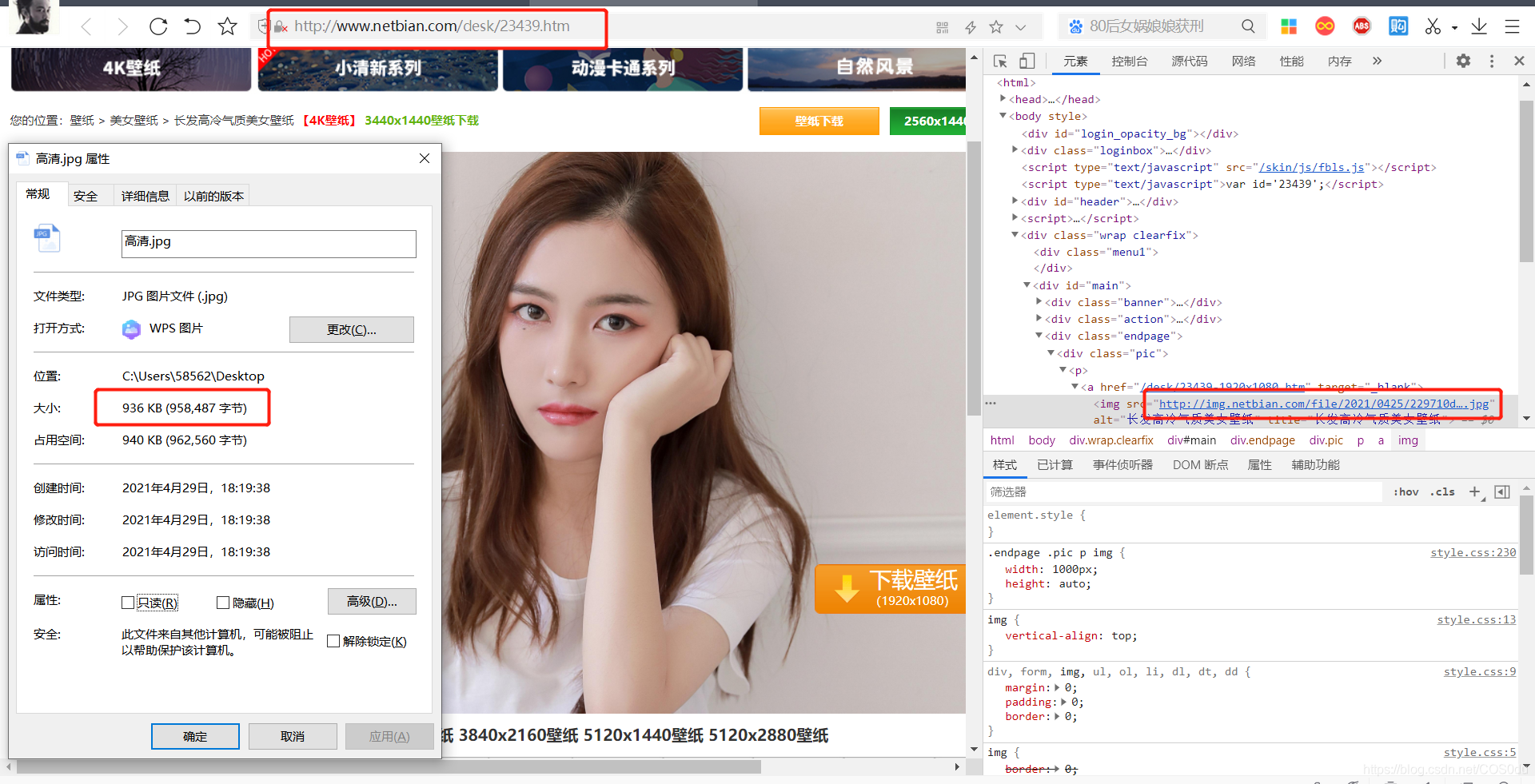
右鍵單擊圖片區域,選擇 ‘審查元素’ ,可以查看當前網頁圖片詳情鏈接,我就滿心歡喜的復制鏈接打開保存,看看效果,結果一張圖片只有60幾kb,這就是縮略圖啊,不清晰,果斷舍棄,,,


沒有辦法,只有點擊找到詳情頁鏈接,再進行單獨爬取,
空白右鍵,‘查看頁面源代碼’,把剛剛復制的縮略圖鏈接復制查找快速定位,分析所有圖片詳情頁鏈接存在div標簽,并且class=‘list’ 唯一,因此可以使用BeautifulSoup提取此標簽,并且發現圖片詳情頁鏈接在herf=后面(同時我們注意到有部分無效鏈接也在div標簽中,觀察它們異同,發現無效鏈接存在’https’字樣,因此可在代碼中依據此排出無效鏈接,對應第4條中的函式代碼),只需提取出來再在前面加上網頁首頁鏈接即可打開,并且右鍵圖片,‘審查元素’,復制鏈接下載的圖片接近1M,表示是高清圖片了,到這一步我們只需呼叫下載保存函式即可保存圖片

4、網頁詳情頁鏈接獲取
根據第3條分析的情況,首要目標是將每頁的每個圖片的詳情頁鏈接給爬取下來,為后續的高清圖片爬取做準備,這里直接定義函式def getUrlList(url):
def getUrlList(url): # 獲取圖片鏈接
url_list = [] #存盤每張圖片的url,用于后續內容爬取
demo = getHtml(url)
soup = BeautifulSoup(demo,'html.parser')
sp = soup.find_all('div', class_="list") #class='list'在全文唯一,因此作為錨,獲取唯一的div標簽;注意,這里的網頁源代碼是class,但是python為了和class(類)做區分,在最后面添加了_
nls = re.findall(r'a href="(.*?)"', str(sp)) #用正則運算式提取鏈接
for i in nls:
if 'https' in i: #因所有無效鏈接中均含有'https'字串,因此直接剔除無效鏈接(對應第3條的分析)
continue
url_list.append('http://www.netbian.com' + i) #在獲取的鏈接中添加前綴,形成完整的有效鏈接
return url_list
5、依據圖片鏈接保存圖片
同理,在第4條中獲取了每個圖片的詳情頁鏈接后,打開,右鍵圖片’審查元素’,復制鏈接即可快速定位,然后保存圖片
def fillPic(url,page):
pic_url = getUrlList(url) #呼叫函式,獲取當前頁的所有圖片詳情頁鏈接
path = './美女' # 保存路徑
for p in range(len(pic_url)):
pic = getHtml(pic_url[p])
soup = BeautifulSoup(pic, 'html.parser')
psoup = soup.find('div', class_="pic") #class_="pic"作為錨,獲取唯一div標簽;注意,這里的網頁源代碼是class,但是python為了和class(類)做區分,在最后面添加了_
picUrl = re.findall(r'src="(.*?)"', str(psoup))[0] #利用正則運算式獲取詳情圖片鏈接,因為這里回傳的是串列形式,所以取第一個元素(只有一個元素,就不用遍歷的方式了)
pic = requests.get(picUrl).content #打開圖片鏈接,并以二進制形式回傳(圖片,聲音,視頻等要以二進制形式打開)
image_name ='美女' + '第{}頁'.format(page) + str(p+1) + '.jpg' #給圖片預定名字
image_path = path + '/' + image_name #定義圖片保存的地址
with open(image_path, 'wb') as f: #保存圖片
f.write(pic)
print(image_name, '下載完畢!!!')
6、main()函式
經過前面的主體框架搭建完畢之后,對整個程式做一個前置化,直接上代碼
在這里第1頁的鏈接是’http://www.netbian.com/meinv/’,第2頁的鏈接是’http://www.netbian.com/meinv/index_2.htm’,并且后續頁面是在第2頁的基礎上僅改變最后的數字,因此在寫代碼的時候要注意區分第1頁和后續頁面的鏈接,分別做處理;同時在main()函式還增加了自定義爬取頁數的功能,詳見代碼

def main():
n = input('請輸入要爬取的頁數:')
url = 'http://www.netbian.com/meinv/' # 資源的首頁,可根據自己的需求查看不同分類,自定義改變目錄,爬取相應資源
if not os.path.exists('./美女'): # 如果不存在,創建檔案目錄
os.mkdir('./美女/')
page = 1
fillPic(url, page) # 爬取第一頁,因為第1頁和后續頁的鏈接的區別,單獨處理第一頁的爬取
if int(n) >= 2: #爬取第2頁之后的資源
ls = list(range(2, 1 + int(n)))
url = 'http://www.netbian.com/meinv/'
for i in ls: #用遍歷的方法對輸入的需求爬取的頁面做分別爬取處理
page = str(i)
url_page = 'http://www.netbian.com/meinv/'
url_page += 'index_' + page + '.htm' #獲取第2頁后的每頁的詳情鏈接
fillPic(url, page) #呼叫fillPic()函式
7、全代碼
最后再呼叫main(),輸入需要爬取的頁數,即可開始爬取,完整代碼如下
import re
import requests
import os
from bs4 import BeautifulSoup
def getHtml(url): #固定格式,獲取html內容
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
} #模擬用戶操作
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('網路狀態錯誤')
def getUrlList(url): # 獲取圖片鏈接
url_list = [] #存盤每張圖片的url,用于后續內容爬取
demo = getHtml(url)
soup = BeautifulSoup(demo,'html.parser')
sp = soup.find_all('div', class_="list") #class='list'在全文唯一,因此作為錨,獲取唯一的div標簽;注意,這里的網頁源代碼是class,但是python為了和class(類)做區分,在最后面添加了_
nls = re.findall(r'a href="(.*?)"', str(sp)) #用正則運算式提取鏈接
for i in nls:
if 'https' in i: #因所有無效鏈接中均含有'https'字串,因此直接剔除無效鏈接(對應第3條的分析)
continue
url_list.append('http://www.netbian.com' + i) #在獲取的鏈接中添加前綴,形成完整的有效鏈接
return url_list
def fillPic(url,page):
pic_url = getUrlList(url) #呼叫函式,獲取當前頁的所有圖片詳情頁鏈接
path = './美女' # 保存路徑
for p in range(len(pic_url)):
pic = getHtml(pic_url[p])
soup = BeautifulSoup(pic, 'html.parser')
psoup = soup.find('div', class_="pic") #class_="pic"作為錨,獲取唯一div標簽;注意,這里的網頁源代碼是class,但是python為了和class(類)做區分,在最后面添加了_
picUrl = re.findall(r'src="(.*?)"', str(psoup))[0] #利用正則運算式獲取詳情圖片鏈接,因為這里回傳的是串列形式,所以取第一個元素(只有一個元素,就不用遍歷的方式了)
pic = requests.get(picUrl).content #打開圖片鏈接,并以二進制形式回傳(圖片,聲音,視頻等要以二進制形式打開)
image_name ='美女' + '第{}頁'.format(page) + str(p+1) + '.jpg' #給圖片預定名字
image_path = path + '/' + image_name #定義圖片保存的地址
with open(image_path, 'wb') as f: #保存圖片
f.write(pic)
print(image_name, '下載完畢!!!')
def main():
n = input('請輸入要爬取的頁數:')
url = 'http://www.netbian.com/meinv/' # 資源的首頁,可根據自己的需求查看不同分類,自定義改變目錄,爬取相應資源
if not os.path.exists('./美女'): # 如果不存在,創建檔案目錄
os.mkdir('./美女/')
page = 1
fillPic(url, page) # 爬取第一頁,因為第1頁和后續頁的鏈接的區別,單獨處理第一頁的爬取
if int(n) >= 2: #爬取第2頁之后的資源
ls = list(range(2, 1 + int(n)))
url = 'http://www.netbian.com/meinv/'
for i in ls: #用遍歷的方法對輸入的需求爬取的頁面做分別爬取處理
page = str(i)
url_page = 'http://www.netbian.com/meinv/'
url_page += 'index_' + page + '.htm' #獲取第2頁后的每頁的詳情鏈接
fillPic(url_page, page) #呼叫fillPic()函式
main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/281647.html
標籤:python