我爸對籃球真可是相當鐘愛,基本是每個賽季必追,我就不同了,自從高中畢業后,就再也沒怎么看籃球了,于是,我就有感而發,是否可以爬取現役球員的一些資訊,看看我還有幾個認識的,

1. 頁面分析
我爬取的頁面是騰訊體育,鏈接如下:
https://nba.stats.qq.com/player/list.htm

觀察上圖:左邊展示的分別是NBA的30支球隊,右邊就是每只球隊對應球員的詳細資訊,
此時思路就很清晰了,我們每點擊一支球員,右側就會出現該球隊的球員資訊,
整個爬蟲思路簡化如下:
- ① 獲取每支球員頁面的url;
- ② 利用Python代碼獲取每個網頁中的資料;
- ③ 將獲取到的資料,整理后存盤至不同的資料庫;
那么,現在要做的就是找到每支球員頁面的url,去發現它們的關聯,
我們每點擊一支球隊,復制它的url,下面我復制了三支球隊的頁面url,如下所示:
# 76人
https://nba.stats.qq.com/player/list.htm#teamId=20
# 火箭
https://nba.stats.qq.com/player/list.htm#teamId=10
# 熱火
https://nba.stats.qq.com/player/list.htm#teamId=14
觀察上述url,可以發現:url基本一模一樣,除了引數teamId對應的數字不一樣,完全可以猜測出,這就是每支球隊對應的編號,30支球隊30個編號,
只要是涉及到“騰訊”二字,基本都是動態網頁,我之前碰到過好多次,基礎方法根本獲取不到資料,不信可以查看網頁原始碼試試:點擊滑鼠右鍵——>點擊查看網頁源代碼,
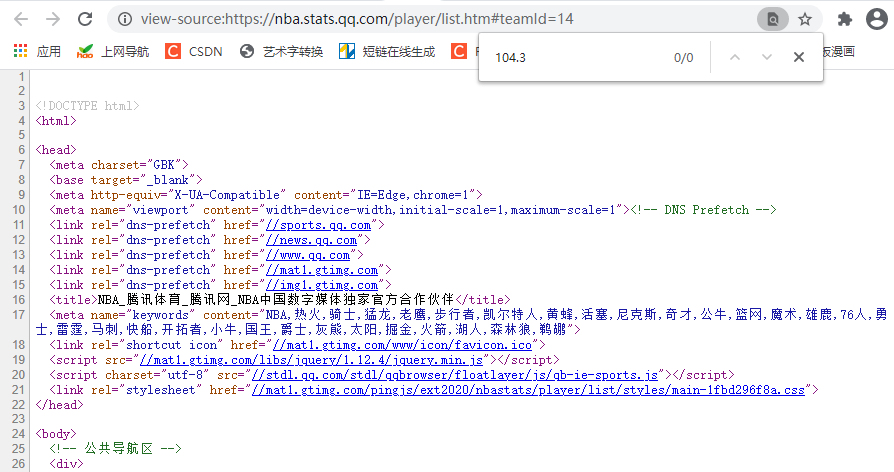
接著,將網頁中的某個資料(你要獲取的)復制,然后再源代碼頁面中,點擊crtl + f,調出“搜索框”,將復制的資料粘貼進去,如果和上圖一樣,出現0條記錄,則基本可以判斷該網頁屬于動態網頁,直接獲取原始碼,一定找不到你要的資料,
因此如果你想要獲取頁面中的資料,使用selenuim自動化爬蟲,是其中一種辦法,
2. 資料爬取
關于selenium的的使用配置,我在一篇文章中詳細講述過,貼上這個鏈接供大家參考:
《https://mp.weixin.qq.com/s/PUPmpbiCJqRW8Swr1Mo2UQ》
我喜歡用xpath,對于本文資料的獲取,我都將使用它,關于xpath的使用,那就是另一篇文章了,這里就不詳細講述,

說了這么多,咋們直接上代碼吧!【代碼中會有注釋】
from selenium import webdriver
# 創建瀏覽器物件,該操作會自動幫我們打開Google瀏覽器視窗
browser = webdriver.Chrome()
# 呼叫瀏覽器物件,向服務器發送請求,該操作會打開Google瀏覽器,并跳轉到“百度”首頁
browser.get("https://nba.stats.qq.com/player/list.htm#teamId=20")
# 最大化視窗
browser.maximize_window()
# 獲取球員中文名
chinese_names = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[2]/a')
chinese_names_list = [i.text for i in chinese_names]
# 獲取球員英文名
english_names = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[3]/a')
english_names_list = [i.get_attribute('title') for i in english_names] # 獲取屬性
# 獲取球員號碼
numbers = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[4]')
numbers_list = [i.text for i in numbers_list]
# 獲取球員位置
locations = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[5]')
locations_list = [i.text for i in locations_list]
# 獲取球員身高
heights = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[6]')
heights_list = [i.text for i in heights_list]
# 獲取球員體重
weights = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[7]')
weights_list = [i.text for i in weights_list]
# 獲取球員年齡
ages = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[8]')
ages_list = [i.text for i in ages_list]
# 獲取球員球齡
qiu_lings = browser.find_elements_by_xpath('//div[@class="players"]//tr[@class="show"]/td[9]')
qiu_lings_list = [i.text for i in qiu_lings_list]
這里只爬取了一支球隊,剩下29支球隊球員資料的爬取任務交給你們,整個代碼部分,基本上大同小異,我寫了一個,你們照葫蘆畫瓢,【就一個回圈,還不簡單呀!】
3. 存盤至txt
將資料保存到txt文本的操作非常簡單,txt幾乎兼容所有平臺,唯一的缺點就是不方便檢索,要是對檢索和資料結構要求不高,追求方便第一的話,請采用txt文本存盤,
注意:txt中寫入的是str字串,
txt檔案寫入資料的規則是這樣的:從頭開始,從左至右一直填充,當填充至最右邊后,會被擠到下一行,因此,如果你想存入的資料規整一點,可以自動填入制表符“\t”和換行符“\n”,
以本文為例,將獲取到的資料,存盤到txt文本中,
for i in zip(chinese_names_list,english_names_list,numbers_list,locations_list,heights_list,weights_list,ages_list,qiu_lings_list):
with open("NBA.txt","a+",encoding="utf-8") as f:
# zip函式,得到的是一個元組,我們需要將它轉換為一個字串
f.write(str(i)[1:-1])
# 自動換行,好寫入第2行資料
f.write("\n")
f.write("\n")
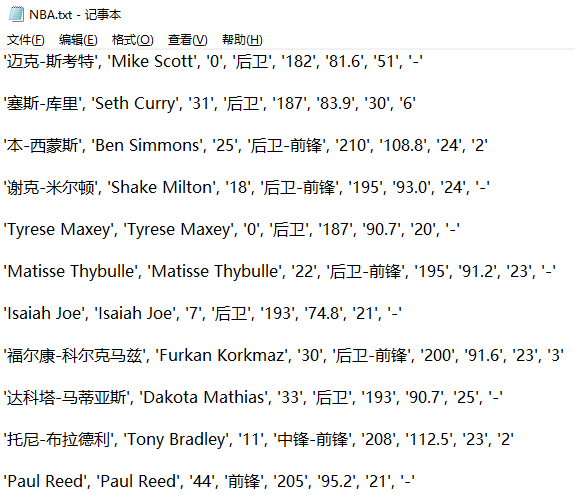
部分截圖如下:
4. 存盤至excel
excel有兩種格式的檔案,一種是csv格式,一種是xlsx格式,將資料保存至excel,當然是使用pandas庫更方便,
import pandas as pd
# 一定要學會組織資料
df = pd.DataFrame({"中文名": chinese_names_list,
"英文名": english_names_list,
"球員號碼": numbers_list,
"位置": locations_list,
"身高": heights_list,
"體重": weights_list,
"年齡": ages_list,
"球齡": qiu_lings_list})
# to_excel()函式
df.to_excel("NBA.xlsx",encoding="utf-8",index=None)
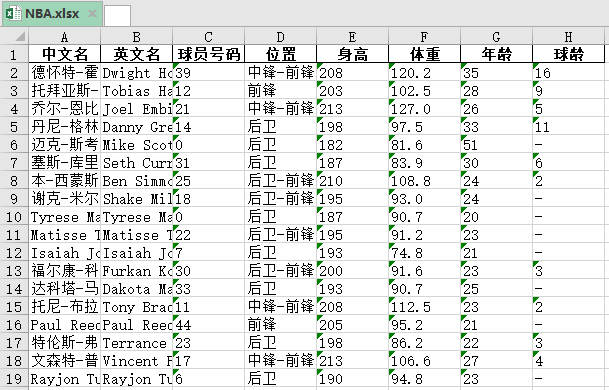
結果如下:
5. 存盤至mysql
MySQL是一個關系型資料庫,資料是采用類excel的二維表來保存資料的,即行、列組成的表,每一行代表一條記錄,每一列代表一個欄位,
關于Python操作MySQL資料庫,我曾經寫了一篇博客,大家可以參考以下:
http://blog.csdn.net/weixin_41261833/article/details/103832017
為了讓大家更明白這個程序,我這里分布為大家講解:
① 創建一個表nba
我們想要往資料庫中插入資料,首先需要建立一張表,這里命名為nba,
import pymysql
# 1. 連接資料庫
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='demo', charset='utf8')
# 2. 創建一個表
# 創建一個游標物件;
cursor = db.cursor()
# 建表陳述句;
sql = """
create table NBA(
chinese_names_list varchar(20),
english_names_list varchar(20),
numbers_list varchar(20),
locations_list varchar(20),
heights_list varchar(20),
weights_list varchar(20),
ages_list varchar(20),
qiu_lings_list varchar(20)
)charset=utf8
"""
# 執行sql陳述句;
cursor.execute(sql)
# 斷開資料庫的連接;
db.close()
② 往表nba中插入資料
import pymysql
# 1. 組織資料
data_list = []
for i in zip(chinese_names_list,english_names_list,numbers_list,locations_list,heights_list,weights_list,ages_list,qiu_lings_list):
data_list.append(i)
# 2. 連接資料庫
db = pymysql.connect(host='localhost',user='root', password='123456',port=3306, db='demo', charset='utf8')
# 創建一個游標物件;
cursor = db.cursor()
# 3. 插入資料
sql = 'insert into nba(chinese_names_list,english_names_list,numbers_list,locations_list,heights_list,weights_list,ages_list,qiu_lings_list) values(%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.executemany(sql,data_list)
db.commit()
print("插入成功")
except:
print("插入失敗")
db.rollback()
db.close()
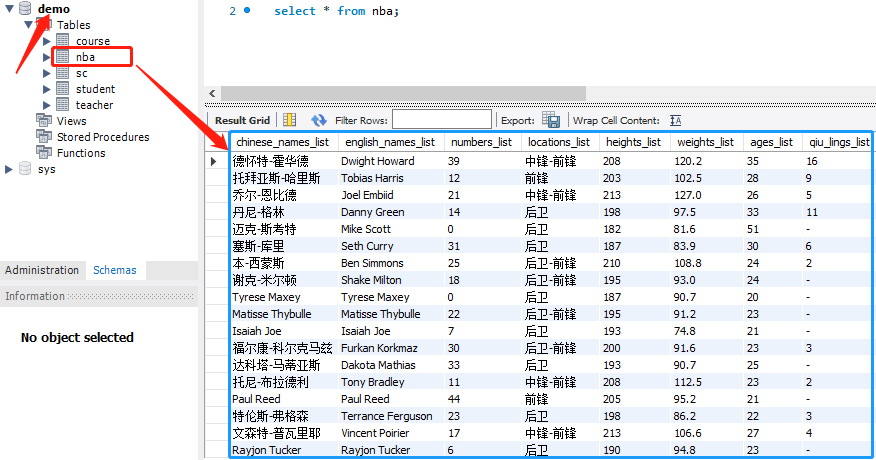
結果如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/281773.html
標籤:python
上一篇:python可視化圖表生成(二)
下一篇:python正則運算式