終于算是閑下來點時間了,也不能算閑,該交的報告什么的算完事了,其他要交的東西現在還不急,然后考研的東西現在也不想看,再加上中午沒睡好,下午也不想學習新的東西了,就抽出點時間把前段時間做的一個小專案來記錄分享一下吧,
寫的比較倉促,有錯誤請指出,共同學習!
目錄
- 一、專案簡介
- 1.想要干什么?
- 2.整個思路介紹
- 二、具體實作
- 1.影像預處理
- 2.資料集準備
- 3.建立神經網路并進行訓練
- 4.輸入圖片進行識別
- 三、專案總結
一、專案簡介
1.想要干什么?
這個專案就是給你一張有車牌的圖片,如下圖,你怎么把這張個車牌上的車牌號給識別出來呢?

從我前段時間的學習也可以看到,這個地方的識別我肯定想用到前面學習到的機器學習的方法,前面學習到的和識別有關的也就是那個Mnist手寫數字識別了,那我接下來的思路就是怎么將這個問題轉化成字符識別的問題了,
2.整個思路介紹
好的,現在我們知道這個問題想要干什么了,而且有了最終的目標,那么現在就是將這個問題進行分解,然后逐個擊破!那么要分解成哪些小問題呢?
我是這樣劃分的:
- 影像預處理
- 準備資料集
- 建立神經網路并進行訓練
- 輸入圖片進行識別
看到這你可能想問了,我怎么知道要這樣劃分~~,也不講講思路啥的,寫的真差勁,不看了,,,別著急別著急,靜下心來聽我娓娓道來(這個詞是這樣用的吧?算了不管了),聽我講就完事了,給我往下看!不準走,否則吃大虧了呀,okok言歸正傳,我來一個一個講,
二、具體實作
1.影像預處理
ok,首先我們想要識別這張車牌上的字符,那么首先我們得把車牌先給剪切下來吧,那么這里就和機器學習和神經網路沒什么關系了,這里是影像處理的知識,什么邊緣提取、灰度變換、二值化、剪切等等,沒學過影像處理也沒有關系,因為python里面的cv2包里已經幫我們把這些函式打包好了,只需要呼叫就好了,總之,最后我們要將這張圖片變成神經網路能夠識別的一張一張的字符圖片,











大概就是這個樣子吧,就是把車牌上字符分割就對了,代碼我后面會貼的,其實我也是參考了很多博客,找了很多代碼然后一點點除錯才能差不多做到這個效果,因為這里不是側重學習影像處理的,所以只是做了簡單學習并沒有深入要求特別高,
這里每一個函式的作用我就不細講了,按著順序看,遇到不知道的函式就去查,知道每個函式是干什么的就行了,多除錯除錯,看會出現什么不同的效果,
不要嫌麻煩,多除錯,多看結果,這一塊剛開始接觸的時候可能會有那么一點點麻煩,,,堅持住!
import numpy as np
import cv2
from PIL import Image
import matplotlib.pyplot as plt # plt 用于顯示圖片
import matplotlib.image as mpimg # mpimg 用于讀取圖片
# 1、讀取車牌圖片函式:將要處理的車牌讀入并做相應的影像處理(邊緣檢測、膨脹處理)
# 輸入引數:照片原影像路徑
# 回傳值:原影像、膨脹處理后的影像
def read_image(image_path):
# 讀取車牌圖片
image = mpimg.imread(image_path, 1) # 讀取和代碼處于同一目錄下的 chepai.png
# 將BGR格式轉換成灰度圖片
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 高斯平滑
gaussian = cv2.GaussianBlur(gray, (3, 3), 0, 0, cv2.BORDER_DEFAULT)
# 中值化處理
median = cv2.medianBlur(gaussian, 5)
# 邊緣檢測
sobel = cv2.Sobel(median, cv2.CV_8U, 1, 0, ksize=3)
# 二值化
ret, binary = cv2.threshold(sobel, 170, 255, cv2.THRESH_BINARY)
# 對二值化的影像進行腐蝕,膨脹,開運算,閉運算的形態學組合變換
# 膨脹和腐蝕操作的核函式
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 1))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (8, 6))
# 膨脹一次,讓輪廓突出
dilation = cv2.dilate(binary, element2, iterations=1)
# 腐蝕一次,去掉細節
erosion = cv2.erode(dilation, element1, iterations=1)
# 再次膨脹,讓輪廓明顯一些
dilation2 = cv2.dilate(erosion, element2, iterations=3)
# 將原始圖片和膨脹后的圖片回傳
return image, dilation2
# 2、查找車牌區域函式
# 輸入引數:膨脹處理的圖片、原始圖片
# 回傳值:車牌的坐標
def findPlateNumberRegion(img, origin_img):
region = []
# 查找輪廓
contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 篩選面積小的
for i in range(len(contours)):
cnt = contours[i]
# 計算該輪廓的面積
area = cv2.contourArea(cnt)
# 面積小的都篩選掉
if area < 2000:
continue
# 輪廓近似,作用很小
epsilon = 0.001 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
# 找到最小的矩形,該矩形可能有方向
# 回傳值為:矩形中心點坐標,矩形長和寬,旋轉角度
rect = cv2.minAreaRect(cnt)
print("rect is: ")
print(rect)
# box是四個點的坐標
box = cv2.boxPoints(rect)
box = np.int0(box)
# 計算高和寬
height = abs(box[0][1] - box[2][1])
width = abs(box[0][0] - box[2][0])
# 篩選矩形:車牌正常情況下長高比在2.7-5之間
ratio =float(width) / float(height)
if (ratio > 5 or ratio < 2):
continue
# 將可能的車牌坐標加入到邊緣串列
region.append(box)
# 根據邊緣坐標畫出矩形區域
for box in region:
# 繪制輪廓
cv2.drawContours(origin_img, [box], 0, (0, 255, 0), 1)
# 回傳
return region
# 3、二值化影像函式
def binaryzation(img):
# 變微灰度圖
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 大津法二值化
retval, dst = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
return dst
# 4、剪切車牌區域的函式
# 輸入引數:車牌的坐標、原影像
def clip_image(reg, img):
if len(reg) > 1:
print("識別出多個車牌,出現錯誤!")
return
# 找出包含整個車牌的最大矩形
for box in reg:
ys = [box[0, 1], box[1, 1], box[2, 1], box[3, 1]]
xs = [box[0, 0], box[1, 0], box[2, 0], box[3, 0]]
ys_sorted_index = np.argsort(ys)
xs_sorted_index = np.argsort(xs)
x1 = box[xs_sorted_index[0], 0]
x2 = box[xs_sorted_index[3], 0]
print(x1)
print(x2)
y1 = box[ys_sorted_index[0], 1]
y2 = box[ys_sorted_index[3], 1]
print(y1)
print(y2)
# 剪裁車牌號
crop = img[y1:y2, x1:x2, :]
# cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 呼叫二值化函式
binary_crop = binaryzation(crop)
# 保存切割后和二值化后的影像
cv2.imwrite('card_img.png', crop)
cv2.imwrite('binary_card_img.png', binary_crop)
# 顯示原始影像、切割車牌、二值化后的車牌
cv2.imshow('img', img) #####顯示圖片#######
cv2.imshow('card_img', crop)
cv2.imshow('binary_card_img', binary_crop)
cv2.waitKey(0)
return binary_crop
# 第一步:
# 呼叫上面3個函式將車牌從原影像上切割下來
origin_img, dila = read_image('2.png')
region = findPlateNumberRegion(dila, origin_img)
image = clip_image(region, origin_img)
# 第二步:
# 進一步剪裁(上下剪裁和左右剪裁,使影像更加規整)
# ······
# 1、讀取影像,并把影像轉換為灰度圖像并顯示
img = cv2.imread("jingAchepai.png") # 讀取圖片
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 轉換了灰度化
cv2.imshow('gray', img_gray) # 顯示圖片
cv2.waitKey(0)
# 2、將灰度影像二值化,設定閾值是100(轉化成白底黑字)
img_thre = img_gray
cv2.threshold(img_gray, 100, 255, cv2.THRESH_BINARY_INV, img_thre)
cv2.imshow('threshold', img_thre)
cv2.waitKey(0)
# 3、保存黑白圖片
# cv2.imwrite('thre_res.png', img_thre)
# 第三步:
# 對處理好的更加規則的車牌圖片進行字符剪裁
# 定義,都可根據應用進行調整
binary_threshold = 100
segmentation_spacing = 0.9 # 普通車牌值0.95,新能源車牌改為0.9即可
# 4、分割字符函式
def jiancai(img_thre):
white = [] # 記錄每一列的白色像素總和
black = [] # ..........黑色.......
height = img_thre.shape[0]
width = img_thre.shape[1]
white_max = 0
black_max = 0
# 計算每一列的黑白色像素總和
for i in range(width):
s = 0 # 這一列白色總數
t = 0 # 這一列黑色總數
for j in range(height):
if img_thre[j][i] == 255:
s += 1
if img_thre[j][i] == 0:
t += 1
white_max = max(white_max, s)
black_max = max(black_max, t)
white.append(s)
black.append(t)
arg = False # False表示白底黑字;True表示黑底白字
if black_max > white_max:
arg = True
# 分割影像
def find_end(start_):
end_ = start_ + 1
for m in range(start_ + 1, width - 1):
if (black[m] if arg else white[m]) > (
segmentation_spacing * black_max if arg else segmentation_spacing * white_max): # 0.95這個引數請多調整,對應下面的0.05
end_ = m
break
return end_
m = 1
n = 1
start = 1
end = 2
while n < width - 2:
n += 1
if (white[n] if arg else black[n]) > (
(1 - segmentation_spacing) * white_max if arg else (1 - segmentation_spacing) * black_max):
# 上面這些判斷用來辨別是白底黑字還是黑底白字
# 0.05這個引數請多調整,對應上面的0.95
start = n
end = find_end(start)
n = end
if end - start > 5:
cj = img_thre[1:height, start:end]
cv2.imshow('caijian', cj)
cv2.waitKey(0)
# 轉換圖片的大小為20*20
reshape_cj = cv2.resize(cj, (20, 20))
# cv2.imshow('caijian', reshape_cj)
cv2.imwrite('new_caijianImg/{0}.png'.format(m), reshape_cj)
m = m+1
# cv2.waitKey(0)
# 呼叫剪裁字符函式
jiancai(img_thre)
2.資料集準備
在原來識別Mnist手寫數字識別的時候,我們有給打包好的資料集,包括圖片和標簽,但是那個資料集不適合我們這個專案,先不說手寫體和車牌上的字符樣式不同,我們車牌上還有字母和漢字呀,所以這個時候我們就必須自己準備資料集,那么首先第一步去下載資料集圖片,就像下面這樣的,包括10個數字、24個字母(因為0和O、1和I很像)、31個漢字,每張圖片都是2020像素的,和mnist手寫數字大小不一樣,那個大小是2828像素的,
資料集下載鏈接:https://download.csdn.net/download/Mu_yongheng/18243520
這里面我上傳了原始的字符圖片,還有我已經處理好的帶有標簽的資料檔案,可以直接拿過來用于訓練模型!

從上面的照片我們可以看到,我們處理后的圖片和訓練的資料還有些不同,還需要就行剪切上面邊緣和添加左右邊緣的進一步的影像處理操作,代碼如下所示:
# 第四步:
# 對剪裁好的單個字符影像進一步處理:減去多余的邊緣部分
# 函式:對多余邊緣進行剪裁的函式(這里主要想要去除上下邊緣)
def corp_margin(img):
img2 = img.sum(axis=2)
(row, col) = img2.shape
row_top = 0
raw_down = 0
col_top = 0
col_down = 0
for r in range(0, row):
if img2.sum(axis=1)[r] < 700 * col:
row_top = r
break
for r in range(row - 1, 0, -1):
if img2.sum(axis=1)[r] < 700 * col:
raw_down = r
break
for c in range(0, col):
if img2.sum(axis=0)[c] < 700 * row:
col_top = c
break
for c in range(col - 1, 0, -1):
if img2.sum(axis=0)[c] < 700 * row:
col_down = c
break
new_img = img[row_top:raw_down + 1, col_top:col_down + 1, 0:3]
return new_img
def diaoyong_corp_margin(img_path, save_path):
img = cv2.imread(img_path)
img_crop_margin = corp_margin(img)
#cv2.imshow('img', img_crop_margin)
cv2.imwrite(save_path, img_crop_margin)
#cv2.waitKey(0)
diaoyong_corp_margin('new_caijianImg/1.png', 'new_caijianImg/new_1.png')
diaoyong_corp_margin('new_caijianImg/2.png', 'new_caijianImg/new_2.png')
diaoyong_corp_margin('new_caijianImg/3.png', 'new_caijianImg/new_3.png')
diaoyong_corp_margin('new_caijianImg/4.png', 'new_caijianImg/new_4.png')
diaoyong_corp_margin('new_caijianImg/5.png', 'new_caijianImg/new_5.png')
diaoyong_corp_margin('new_caijianImg/6.png', 'new_caijianImg/new_6.png')
diaoyong_corp_margin('new_caijianImg/7.png', 'new_caijianImg/new_7.png')
# 給圖片添加邊框的函式(添加左右邊框,因為訓練集的資料左右是有邊框的)
def image_border(src, dst, loc='a', width=3, color=(0, 0, 0)):
'''
src: (str) 需要加邊框的圖片路徑
dst: (str) 加邊框的圖片保存路徑
loc: (str) 邊框添加的位置, 默認是'a'(
四周: 'a' or 'all'
上: 't' or 'top'
右: 'r' or 'rigth'
下: 'b' or 'bottom'
左: 'l' or 'left'
)
width: (int) 邊框寬度 (默認是3)
color: (int or 3-tuple) 邊框顏色 (默認是0, 表示黑色; 也可以設定為三元組表示RGB顏色)
'''
# 讀取圖片
# size = img.shape
# print(size)
# w = size[0]
# print(w)
# h = size[1]
# print(h)
img_ori = Image.open(src)
w = img_ori.size[0]
h = img_ori.size[1]
# 添加邊框
if loc in ['a', 'all']:
w += 2*width
h += 2*width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (width, width))
elif loc in ['t', 'top']:
h += width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (0, width, w, h))
elif loc in ['r', 'right']:
w += width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (0, 0, w-width, h))
elif loc in ['b', 'bottom']:
h += width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (0, 0, w, h-width))
elif loc in ['l', 'left']:
w += width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (width, 0, w, h))
elif loc in ['lr', 'left_and_right']:
w += 2*width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (width, 0))
elif loc in ['tb', 'top_and_bottom']:
h += 2*width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (0, width))
else:
pass
# 保存圖片
img_new.save(dst)
# 得到最終的圖片
image_border('new_caijianImg/new_1.png', 'new_caijianImg/new_1_1.png', 'lr', 5, color=(255, 255, 255))
image_border('new_caijianImg/new_2.png', 'new_caijianImg/new_2_2.png', 'lr', 5, color=(255, 255, 255))
image_border('new_caijianImg/new_3.png', 'new_caijianImg/new_3_3.png', 'lr', 5, color=(255, 255, 255))
image_border('new_caijianImg/new_4.png', 'new_caijianImg/new_4_4.png', 'lr', 5, color=(255, 255, 255))
image_border('new_caijianImg/new_5.png', 'new_caijianImg/new_5_5.png', 'lr', 5, color=(255, 255, 255))
image_border('new_caijianImg/new_6.png', 'new_caijianImg/new_6_6.png', 'lr', 5, color=(255, 255, 255))
image_border('new_caijianImg/new_7.png', 'new_caijianImg/new_7_7.png', 'lr', 5, color=(255, 255, 255))
現在我們圖片處理都已經準備好了,那么現在就是準備資料集,雖然我已經將轉化好的資料集上傳了,但是我還是想講一下如何讀入這些圖片并轉換為和Mnist資料集類似的資料集,
# 生成65*65的二維矩陣(對角線為1,其余全為0),作為獨熱編碼標簽資料
labels = np.diag([1]*65)
# 存盤所有讀取的圖片資料
array_of_img = []
# 讀取相應檔案夾中的所有圖片,并將圖片轉化為灰度圖(減少通道數),連同標簽一起存入串列中
def read_directory(directory_name, m):
# n 用來統計這個檔案中共有多少張圖片,最后回傳出去
n = 0
for filename in os.listdir(r"./"+directory_name):
# 列印正在讀取第幾張圖片
n = n + 1
print("第" + str(n) + "張圖片:" + filename)
# 將讀取的圖片存盤在img中
img = cv2.imread(directory_name + "/" + filename)
# 減少通道數(變為灰度圖)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 改變圖片的形狀(由 20*20 變為 1*400)
reshape_gray_img = gray_img.reshape(1, 400)
# 將numpy轉化為串列,使用append
reshape_gray_img = reshape_gray_img.tolist()
# 添加標簽值(根據所提供的數字m)
# 最終得到(1, 465)的串列
for i in range(len(labels[m])):
reshape_gray_img[0].append(labels[m][i])
# 將照片像素值和標簽都添加到串列中
array_of_img.append(reshape_gray_img[0])
# if n == 1:
# break
return n
# 統計所有檔案中圖片的總數
all_image = 0
# 讀取0-9數字檔案夾
print("**************************************讀取數字為 0 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/0', 0)
all_image = all_image + shu
print("**************************************讀取數字為 1 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/1', 1)
all_image = all_image + shu
print("**************************************讀取數字為 2 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/2', 2)
all_image = all_image + shu
print("**************************************讀取數字為 3 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/3', 3)
all_image = all_image + shu
print("**************************************讀取數字為 4 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/4', 4)
all_image = all_image + shu
print("**************************************讀取數字為 5 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/5', 5)
all_image = all_image + shu
print("**************************************讀取數字為 6 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/6', 6)
all_image = all_image + shu
print("**************************************讀取數字為 7 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/7', 7)
all_image = all_image + shu
print("**************************************讀取數字為 8 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/8', 8)
all_image = all_image + shu
print("**************************************讀取數字為 9 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/9', 9)
all_image = all_image + shu
# 讀取A-Z字母檔案夾
print("**************************************讀取字母為 A 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/A', 10)
all_image = all_image + shu
print("**************************************讀取字母為 B 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/B', 11)
all_image = all_image + shu
print("**************************************讀取字母為 C 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/C', 12)
all_image = all_image + shu
print("**************************************讀取字母為 D 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/D', 13)
all_image = all_image + shu
print("**************************************讀取字母為 E 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/E', 14)
all_image = all_image + shu
print("**************************************讀取字母為 F 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/F', 15)
all_image = all_image + shu
print("**************************************讀取字母為 G 的檔案中的圖片*****************************************")
shu = read_directory('chepaishujuji/G', 16)
all_image = all_image + shu
### 后面和前面的都一樣,只需要改變檔案夾的名稱和標簽就行了,最終一共呼叫函式65次
# 列印出所有讀取結果
print("共有" + str(all_image) + "張圖片")
print(len(array_of_img))
print(len(array_of_img[0]))
# 將讀取的所有資料保存為一個.csv檔案
test = pd.DataFrame(data=array_of_img)
test.to_csv('H:/test3.csv')
# 列印出形狀
array_of_img = np.array(array_of_img)
print(array_of_img.shape)
print(array_of_img)
這里代碼我就不貼完了,反正就是重復呼叫函式,將65個檔案夾中的圖片和其所對應的獨熱編碼標簽讀取并且存到一個csv檔案當中,不熟悉這種編碼的可以再去學習一下Mnist手寫數字識別,這里的資料集準備完全是模仿那一個的,
當我們把把這些圖片和對應的標簽全部讀進去并存成csv檔案以后,將檔案的第一行和第一列刪掉(行和列的序號,沒有用的資料),最終得到的資料應該是一個49063 * 465 的二維矩陣,49063代表我們總共讀取了49063張圖片,465中的前400行是每張照片的像素值(20*20),后65行是獨熱編碼,
其實最后得到的檔案就是這樣的:
鏈接放這里,這里面只包含讀取好的檔案:https://download.csdn.net/download/Mu_yongheng/18266097
不想下載全部圖片的可以直接下載這個,
3.建立神經網路并進行訓練
好了,現在我們的資料集也準備好了,接下來就是怎么用這個資料集來訓練我們的模型,這里的模型還是用的前面mnist手寫數字識別的模型,不同的就是每一層的神經元個數需要調整,
另外一個比較重要就是劃分訓練集、驗證集和測驗集,首先需要將處理好的csv檔案讀取進來放到一個串列里面,方便我們后面的處理,我是這樣劃分的:將前46000張照片作為訓練集,接著的1000張作為驗證機,最后剩下的2063張作為測驗集,
還有要注意打亂我們的資料集,因為我們的資料剛開始都是順序存盤的,按照0, 1,2這樣的順序存盤的,所以需要打亂,并且每一輪訓練都需要打亂資料,防止我們的模型產生“肌肉記憶”,所以為了方便操作,我就定義了一個函式shuffle_data(data): 這個函式的作用是打亂資料并產生訓練集、驗證機、測驗集資料即標簽,
注意多調整每一層神經元個數以及學習率的大小,我這個模型經過最終的訓練可以達到接近99%的正確率!
具體代碼如下:
import tensorflow as tf
import numpy as np
import csv
import random
import os # 用于保存模型
# 讀取csv檔案,將圖片所有資料存入array陣列
array = []
with open('H:/test3.csv', 'r') as csvFile:
reader = csv.reader(csvFile)
arr = []
for line in reader:
for i in range(len(line)):
arr.append(int(line[i]))
array.append(arr)
arr = []
print(len(array))
print(len(array[0]))
# 定義打亂資料函式,并從整體資料中生成訓練集、驗證集和測驗集
def shuffle_data(data):
random.shuffle(data)
# 提取訓練集(46000個)
trains = data[0:46000]
train_images = []
train_labels = []
for train in trains:
image = train[0:400]
train_images.append(image)
label = train[400:465]
train_labels.append(label)
train_images = np.array(train_images)
train_labels = np.array(train_labels)
# 驗證集(1000個)
validations = data[46000:47000]
validation_images = []
validation_labels = []
for validation in validations:
image = validation[0:400]
validation_images.append(image)
label = validation[400:465]
validation_labels.append(label)
validation_images = np.array(validation_images)
validation_labels = np.array(validation_labels)
# 測驗集(2063個)
tests = data[47000:49063]
test_images = []
test_labels = []
for test in tests:
image = test[0:400]
test_images.append(image)
label = test[400:465]
test_labels.append(label)
test_images = np.array(test_images)
test_labels = np.array(test_labels)
return train_images, train_labels, validation_images, validation_labels, test_images, test_labels
# 呼叫shuffle_data函式,生成一批訓練集、驗證集和測驗集
train_images, train_labels, validation_images, validation_labels, test_images, test_labels = shuffle_data(array)
# 定義全連接層函式
def fcn_layer(inputs, # 輸入資料
input_dim, # 輸入神經元數量
output_dim, # 輸出神經元數量
activation=None): # 激活函式
w = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
b = tf.Variable(tf.zeros([output_dim]))
xwb = tf.matmul(inputs, w) + b
if activation is None:
outputs = xwb
else:
outputs = activation(xwb)
return outputs
# 保存模型
# 模型的存盤粒度
save_step = 5
# 創建模型保存的檔案的目錄
ckpt_dir = "./xunlian_dir/"
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
# 構建輸入層
# 定義標簽資料占位符
x = tf.placeholder(tf.float32, [None, 400], name="X")
y = tf.placeholder(tf.float32, [None, 65], name="Y")
# 構建隱藏層
H1_NN = 4096 # 第1隱藏層神經元數量
H2_NN = 2048 # 第2隱藏層神經元數量
H3_NN = 1024 # 第3隱藏層神經元數量
# 輸入層 - 第1隱藏層引數和偏置項(構建第1隱藏層)
h1 = fcn_layer(inputs=x, input_dim=400, output_dim=H1_NN, activation=tf.nn.relu)
# 第1隱藏層 - 第2隱藏層引數和偏執項(構建第2隱藏層)
h2 = fcn_layer(inputs=h1, input_dim=H1_NN, output_dim=H2_NN, activation=tf.nn.relu)
# 第2隱藏層 - 第3隱藏層引數和偏置項(構建第3隱藏層)
h3 = fcn_layer(inputs=h2, input_dim=H2_NN, output_dim=H3_NN, activation=tf.nn.relu)
# 第3隱藏層 - 輸出層引數和偏置項(構建輸出層)
forward = fcn_layer(inputs=h3, input_dim=H3_NN, output_dim=65, activation=None)
pred = tf.nn.softmax(forward)
# 定義訓練引數
train_epochs = 40 # 訓練的輪數
batch_size = 100 # 單次訓練樣本數
# total_batch = int(len(trains)/batch_size)
total_batch = 470
display_step = 1 # 顯示粒度
learning_rate = 0.0001 # 學習率(不斷調整)
# 定義損失函式
# loss_function = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), reduction_indices=1))
loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=forward, labels=y)) # 結合Softmax的交叉熵損失函式定義方法
# 定義優化器
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss_function)
# 定義準確率
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# 準確率,將布林值轉化為浮點數,并計算平均值
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 宣告完所有變數,呼叫tf.train.saver
saver = tf.train.Saver()
# 模型訓練
# 記錄訓練開始的時間
from time import time
startTime = time()
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# 開始訓練
for epoch in range(train_epochs):
# 關鍵一步:每訓練完成一輪,呼叫函式shuffle_data打亂并生成一批新的訓練集、驗證集和測驗集
train_images, train_labels, validation_images, validation_labels, test_images, test_labels = shuffle_data(array)
for batch in range(total_batch):
# 把所有資料按照批次傳入網路進行訓練
xs = train_images[batch * batch_size:(batch + 1) * batch_size]
ys = train_labels[batch * batch_size:(batch + 1) * batch_size]
sess.run(optimizer, feed_dict={x: xs, y: ys}) # 執行批次訓練
# total_batch 個批次訓練完后,使用驗證資料計算準確率
loss, acc = sess.run([loss_function, accuracy], feed_dict={x: validation_images, y: validation_labels})
# 列印訓練程序中的詳細資訊
if (epoch + 1) % display_step == 0:
print("訓練輪次:", epoch + 1, "損失值:", format(loss), "準確率:", format(acc))
# 按照模型保存粒度對模型進行保存
if (epoch+1) % save_step == 0:
saver.save(sess, os.path.join(ckpt_dir, 'mnist_h256_model_{:06d}.ckpt'.format(epoch+1))) # 存盤模型
print('mnist_h256_model_{:06d}.ckpt saved'.format(epoch+1))
saver.save(sess, os.path.join(ckpt_dir, 'mnist_h256_model.ckpt'))
print("Model saved!")
# 顯示運行總時間
duration = time() - startTime
print("本次訓練所花的總時間為:", duration)
# 應用模型
prediction_result = sess.run(tf.argmax(pred, 1), feed_dict={x: test_images})
print(prediction_result[0:10])
4.輸入圖片進行識別
現在圖片也處理好了,模型也訓練好了,萬事俱備只欠東風!接下來就是輸入圖片并進行識別了,
我將最終代碼全部放到一個檔案中了,如下,
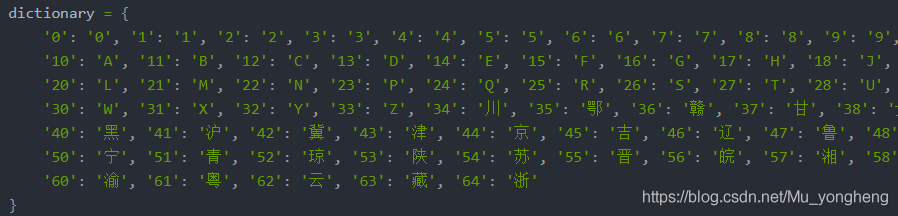
還需要注意的一點就是標簽與實際字符值的轉換,就是后面定義的這個字典,
具體為什么我就不多說了,懂得都懂!不懂也沒關系,歡迎大家提問,
附最終識別效果圖:

最終代碼實作:
from PIL import Image
import matplotlib.image as mpimg # mpimg 用于讀取圖片
import tensorflow as tf
import cv2
import csv
import random
import numpy as np
# 1、讀取車牌圖片函式:將要處理的車牌讀入并做相應的影像處理(邊緣檢測、膨脹處理)
# 輸入引數:照片原影像路徑
# 回傳值:原影像、膨脹處理后的影像
def read_image(image_path):
# 讀取車牌圖片
image = mpimg.imread(image_path, 1) # 讀取和代碼處于同一目錄下的 chepai.png
# 將BGR格式轉換成灰度圖片
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 高斯平滑
gaussian = cv2.GaussianBlur(gray, (3, 3), 0, 0, cv2.BORDER_DEFAULT)
# 中值化處理
median = cv2.medianBlur(gaussian, 5)
# 邊緣檢測
sobel = cv2.Sobel(median, cv2.CV_8U, 1, 0, ksize=3)
# 二值化
ret, binary = cv2.threshold(sobel, 170, 255, cv2.THRESH_BINARY)
# 對二值化的影像進行腐蝕,膨脹,開運算,閉運算的形態學組合變換
# 膨脹和腐蝕操作的核函式
element1 = cv2.getStructuringElement(cv2.MORPH_RECT, (9, 1))
element2 = cv2.getStructuringElement(cv2.MORPH_RECT, (8, 6))
# 膨脹一次,讓輪廓突出
dilation = cv2.dilate(binary, element2, iterations=1)
# 腐蝕一次,去掉細節
erosion = cv2.erode(dilation, element1, iterations=1)
# 再次膨脹,讓輪廓明顯一些
dilation2 = cv2.dilate(erosion, element2, iterations=3)
# 將原始圖片和膨脹后的圖片回傳
return image, dilation2
# 2、查找車牌區域函式
# 輸入引數:膨脹處理的圖片、原始圖片
# 回傳值:車牌的坐標
def findPlateNumberRegion(img, origin_img):
region = []
# 查找輪廓
contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 篩選面積小的
for i in range(len(contours)):
cnt = contours[i]
# 計算該輪廓的面積
area = cv2.contourArea(cnt)
# 面積小的都篩選掉
if area < 2000:
continue
# 輪廓近似,作用很小
epsilon = 0.001 * cv2.arcLength(cnt, True)
approx = cv2.approxPolyDP(cnt, epsilon, True)
# 找到最小的矩形,該矩形可能有方向
# 回傳值為:矩形中心點坐標,矩形長和寬,旋轉角度
rect = cv2.minAreaRect(cnt)
print("rect is: ")
print(rect)
# box是四個點的坐標
box = cv2.boxPoints(rect)
box = np.int0(box)
# 計算高和寬
height = abs(box[0][1] - box[2][1])
width = abs(box[0][0] - box[2][0])
# 篩選矩形:車牌正常情況下長高比在2.7-5之間
ratio =float(width) / float(height)
if (ratio > 5 or ratio < 2):
continue
# 將可能的車牌坐標加入到邊緣串列
region.append(box)
# 根據邊緣坐標畫出矩形區域
for box in region:
# 繪制輪廓
cv2.drawContours(origin_img, [box], 0, (0, 255, 0), 1)
# 回傳
return region
# 3、二值化影像函式
def binaryzation(img):
# 變微灰度圖
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 大津法二值化
retval, dst = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU)
return dst
# 4、剪切車牌區域的函式
# 輸入引數:車牌的坐標、原影像
def clip_image(reg, img):
if len(reg) > 1:
print("識別出多個車牌,出現錯誤!")
return
# 找出包含整個車牌的最大矩形
for box in reg:
ys = [box[0, 1], box[1, 1], box[2, 1], box[3, 1]]
xs = [box[0, 0], box[1, 0], box[2, 0], box[3, 0]]
ys_sorted_index = np.argsort(ys)
xs_sorted_index = np.argsort(xs)
x1 = box[xs_sorted_index[0], 0]
x2 = box[xs_sorted_index[3], 0]
# print(x1)
# print(x2)
y1 = box[ys_sorted_index[0], 1]
y2 = box[ys_sorted_index[3], 1]
# print(y1)
# print(y2)
# 剪裁車牌號
crop = img[y1:y2, x1:x2, :]
# cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 呼叫二值化函式
binary_crop = binaryzation(crop)
# 保存切割后和二值化后的影像
cv2.imwrite('card_img.png', crop)
cv2.imwrite('binary_card_img.png', binary_crop)
# 顯示原始影像、切割車牌、二值化后的車牌
cv2.imshow('img', img) #####顯示圖片#######
cv2.imshow('card_img', crop)
cv2.imshow('binary_card_img', binary_crop)
cv2.waitKey(0)
# 第一步:
# 呼叫上面3個函式將車牌從原影像上切割下來
origin_img, dila = read_image('2.png')
region = findPlateNumberRegion(dila, origin_img)
clip_image(region, origin_img)
# 第二步:
# 進一步剪裁(上下剪裁和左右剪裁,使影像更加規整)
# ······
# 1、讀取影像,并把影像轉換為灰度影像并顯示
img = cv2.imread("jingAchepai.png") # 讀取圖片
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 轉換了灰度化
cv2.imshow('gray', img_gray) # 顯示圖片
cv2.waitKey(0)
# 2、將灰度影像二值化,設定閾值是100(轉化成白底黑字)
img_thre = img_gray
cv2.threshold(img_gray, 100, 255, cv2.THRESH_BINARY_INV, img_thre)
cv2.imshow('threshold', img_thre)
cv2.waitKey(0)
# 3、保存黑白圖片
# cv2.imwrite('thre_res.png', img_thre)
# 第三步:
# 對處理好的更加規則的車牌圖片進行字符剪裁
# 定義,都可根據應用進行調整
binary_threshold = 100
segmentation_spacing = 0.9 # 普通車牌值0.95,新能源車牌改為0.9即可
# 4、分割字符函式
def jiancai(img_thre):
white = [] # 記錄每一列的白色像素總和
black = [] # ..........黑色.......
height = img_thre.shape[0]
width = img_thre.shape[1]
white_max = 0
black_max = 0
# 計算每一列的黑白色像素總和
for i in range(width):
s = 0 # 這一列白色總數
t = 0 # 這一列黑色總數
for j in range(height):
if img_thre[j][i] == 255:
s += 1
if img_thre[j][i] == 0:
t += 1
white_max = max(white_max, s)
black_max = max(black_max, t)
white.append(s)
black.append(t)
arg = False # False表示白底黑字;True表示黑底白字
if black_max > white_max:
arg = True
# 分割影像
def find_end(start_):
end_ = start_ + 1
for m in range(start_ + 1, width - 1):
if (black[m] if arg else white[m]) > (
segmentation_spacing * black_max if arg else segmentation_spacing * white_max): # 0.95這個引數請多調整,對應下面的0.05
end_ = m
break
return end_
m = 1
n = 1
start = 1
end = 2
while n < width - 2:
n += 1
if (white[n] if arg else black[n]) > (
(1 - segmentation_spacing) * white_max if arg else (1 - segmentation_spacing) * black_max):
# 上面這些判斷用來辨別是白底黑字還是黑底白字
# 0.05這個引數請多調整,對應上面的0.95
start = n
end = find_end(start)
n = end
if end - start > 5:
cj = img_thre[1:height, start:end]
cv2.imshow('caijian', cj)
cv2.waitKey(0)
# 轉換圖片的大小為20*20
# reshape_cj = cv2.resize(cj, (20, 20))
# cv2.imshow('caijian', reshape_cj)
cv2.imwrite('new_caijianImg/{0}.png'.format(m), cj)
m = m+1
# cv2.waitKey(0)
# 呼叫剪裁字符函式
jiancai(img_thre)
# 第四步:
# 對剪裁好的單個字符影像進一步處理:減去多余的邊緣部分
# 函式:對多余邊緣進行剪裁的函式(這里主要想要去除上下邊緣)
def corp_margin(img):
img2 = img.sum(axis=2)
(row, col) = img2.shape
row_top = 0
raw_down = 0
col_top = 0
col_down = 0
for r in range(0, row):
if img2.sum(axis=1)[r] < 700 * col:
row_top = r
break
for r in range(row - 1, 0, -1):
if img2.sum(axis=1)[r] < 700 * col:
raw_down = r
break
for c in range(0, col):
if img2.sum(axis=0)[c] < 700 * row:
col_top = c
break
for c in range(col - 1, 0, -1):
if img2.sum(axis=0)[c] < 700 * row:
col_down = c
break
new_img = img[row_top:raw_down + 1, col_top:col_down + 1, 0:3]
return new_img
def diaoyong_corp_margin(img_path, save_path):
img = cv2.imread(img_path)
img_crop_margin = corp_margin(img)
# cv2.imshow('img', img_crop_margin)
cv2.imwrite(save_path, img_crop_margin)
# cv2.waitKey(0)
diaoyong_corp_margin('new_caijianImg/1.png', 'new_caijianImg/new_1.png')
diaoyong_corp_margin('new_caijianImg/2.png', 'new_caijianImg/new_2.png')
diaoyong_corp_margin('new_caijianImg/3.png', 'new_caijianImg/new_3.png')
diaoyong_corp_margin('new_caijianImg/4.png', 'new_caijianImg/new_4.png')
diaoyong_corp_margin('new_caijianImg/5.png', 'new_caijianImg/new_5.png')
diaoyong_corp_margin('new_caijianImg/6.png', 'new_caijianImg/new_6.png')
diaoyong_corp_margin('new_caijianImg/7.png', 'new_caijianImg/new_7.png')
# 給圖片添加邊框的函式(添加左右邊框,因為訓練集的資料左右是有邊框的)
def image_border(src, dst, loc='a', width=3, color=(0, 0, 0)):
'''
src: (str) 需要加邊框的圖片路徑
dst: (str) 加邊框的圖片保存路徑
loc: (str) 邊框添加的位置, 默認是'a'(
四周: 'a' or 'all'
上: 't' or 'top'
右: 'r' or 'rigth'
下: 'b' or 'bottom'
左: 'l' or 'left'
)
width: (int) 邊框寬度 (默認是3)
color: (int or 3-tuple) 邊框顏色 (默認是0, 表示黑色; 也可以設定為三元組表示RGB顏色)
'''
# 讀取圖片
img_ori = Image.open(src)
w = img_ori.size[0]
h = img_ori.size[1]
# 添加邊框
if loc in ['a', 'all']:
w += 2*width
h += 2*width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (width, width))
elif loc in ['t', 'top']:
h += width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (0, width, w, h))
elif loc in ['r', 'right']:
w += width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (0, 0, w-width, h))
elif loc in ['b', 'bottom']:
h += width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (0, 0, w, h-width))
elif loc in ['l', 'left']:
w += width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (width, 0, w, h))
elif loc in ['lr', 'left_and_right']:
w += 2*width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (width, 0))
elif loc in ['tb', 'top_and_bottom']:
h += 2*width
img_new = Image.new('RGB', (w, h), color)
img_new.paste(img_ori, (0, width))
else:
pass
# 保存圖片
img_new.save(dst)
# 得到最終的圖片
image_border('new_caijianImg/new_1.png', 'new_caijianImg/new_1_1.png', 'lr', 15, color=(255, 255, 255))
image_border('new_caijianImg/new_2.png', 'new_caijianImg/new_2_2.png', 'lr', 15, color=(255, 255, 255))
image_border('new_caijianImg/new_3.png', 'new_caijianImg/new_3_3.png', 'lr', 15, color=(255, 255, 255))
image_border('new_caijianImg/new_4.png', 'new_caijianImg/new_4_4.png', 'lr', 15, color=(255, 255, 255))
image_border('new_caijianImg/new_5.png', 'new_caijianImg/new_5_5.png', 'lr', 15, color=(255, 255, 255))
image_border('new_caijianImg/new_6.png', 'new_caijianImg/new_6_6.png', 'lr', 15, color=(255, 255, 255))
image_border('new_caijianImg/new_7.png', 'new_caijianImg/new_7_7.png', 'lr', 15, color=(255, 255, 255))
# 轉化圖片為指定大小
def produceImage(file_in, width, height, file_out):
image = Image.open(file_in)
resized_image = image.resize((width, height), Image.ANTIALIAS)
resized_image.save(file_out)
produceImage('new_caijianImg/new_1_1.png', 20, 20, 'new_caijianImg/chepai_1.png')
produceImage('new_caijianImg/new_2_2.png', 20, 20, 'new_caijianImg/chepai_2.png')
produceImage('new_caijianImg/new_3_3.png', 20, 20, 'new_caijianImg/chepai_3.png')
produceImage('new_caijianImg/new_4_4.png', 20, 20, 'new_caijianImg/chepai_4.png')
produceImage('new_caijianImg/new_5_5.png', 20, 20, 'new_caijianImg/chepai_5.png')
produceImage('new_caijianImg/new_6_6.png', 20, 20, 'new_caijianImg/chepai_6.png')
produceImage('new_caijianImg/new_7_7.png', 20, 20, 'new_caijianImg/chepai_7.png')
print('影像處理完畢,開始識別!')
# ----------------------------------------------------------------------------------------------------------
# ----------------------------------------------------------------------------------------------------------
# ---------------------------------------------- 開始識別 ---------------------------------------------------
# ----------------------------------------------------------------------------------------------------------
# ----------------------------------------------------------------------------------------------------------
# 讀取資料檔案
array = []
with open('H:/test3.csv', 'r') as csvFile:
reader = csv.reader(csvFile)
arr = []
for line in reader:
for i in range(len(line)):
arr.append(int(line[i]))
array.append(arr)
arr = []
print(len(array))
print(len(array[0]))
# 打亂資料
random.shuffle(array)
# 制作測驗集,用來后面評價模型的準確率
tests = array[47000:49063]
test_images = []
test_labels = []
for test in tests:
image = test[0:400]
test_images.append(image)
label = test[400:465]
test_labels.append(label)
test_images = np.array(test_images)
test_labels = np.array(test_labels)
# 定義全連接層函式
def fcn_layer(inputs, # 輸入資料
input_dim, # 輸入神經元數量
output_dim, # 輸出神經元數量
activation=None): # 激活函式
w = tf.Variable(tf.truncated_normal([input_dim, output_dim], stddev=0.1))
b = tf.Variable(tf.zeros([output_dim]))
xwb = tf.matmul(inputs, w) + b
if activation is None:
outputs = xwb
else:
outputs = activation(xwb)
return outputs
# 構建輸入層
# 定義標簽資料占位符
x = tf.placeholder(tf.float32, [None, 400], name="X")
y = tf.placeholder(tf.float32, [None, 65], name="Y")
# 構建隱藏層
H1_NN = 4096 # 第1隱藏層神經元數量
H2_NN = 2048 # 第2隱藏層神經元數量
H3_NN = 1024 # 第3隱藏層神經元數量
# 輸入層 - 第1隱藏層引數和偏置項(構建第1隱藏層)
h1 = fcn_layer(inputs=x, input_dim=400, output_dim=H1_NN, activation=tf.nn.relu)
# 第1隱藏層 - 第2隱藏層引數和偏執項(構建第2隱藏層)
h2 = fcn_layer(inputs=h1, input_dim=H1_NN, output_dim=H2_NN, activation=tf.nn.relu)
# 第2隱藏層 - 第3隱藏層引數和偏置項(構建第3隱藏層)
h3 = fcn_layer(inputs=h2, input_dim=H2_NN, output_dim=H3_NN, activation=tf.nn.relu)
# 第3隱藏層 - 輸出層引數和偏置項(構建輸出層)
forward = fcn_layer(inputs=h3, input_dim=H3_NN, output_dim=65, activation=None)
pred = tf.nn.softmax(forward)
# 定義準確率
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# 準確率,將布林值轉化為浮點數,并計算平均值
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# -------------------------------- 還原模型 ------------------------------------
# 1、必須指定為模型檔案的存放目錄
ckpt_dir = "./xunlian_dir"
# 2、讀取模型
saver = tf.train.Saver() # 創建saver
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
ckpt = tf.train.get_checkpoint_state(ckpt_dir)
if ckpt and ckpt.model_checkpoint_path:
saver.restore(sess, ckpt.model_checkpoint_path) # 從已經保存的模型中讀取引數
print("Restore model from " + ckpt.model_checkpoint_path)
# 利用制作的測驗集來驗證模型的準確率
print("Accuracy: ", accuracy.eval(session=sess, feed_dict={x: test_images, y: test_labels}))
def chuli_image(path):
img = cv2.imread(path)
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# cv2.imshow('img', gray_img)
# cv2.waitKey(0)
# 將白底黑字照片變為黑底白字(和訓練集保持一致)
height = gray_img.shape[0]
width = gray_img.shape[1]
dst = np.zeros((height, width), np.uint8)
for i in range(height):
for j in range(width):
dst[i, j] = 255 - gray_img[i, j]
# cv2.imshow('img', dst)
# cv2.waitKey(0)
# 變形
dst = dst.reshape(1, 400)
return dst
picture = []
d1 = chuli_image('new_caijianImg/chepai_1.png')
picture.append(d1[0])
d2 = chuli_image('new_caijianImg/chepai_2.png')
picture.append(d2[0])
d3 = chuli_image('new_caijianImg/chepai_3.png')
picture.append(d3[0])
d4 = chuli_image('new_caijianImg/chepai_4.png')
picture.append(d4[0])
d5 = chuli_image('new_caijianImg/chepai_5.png')
picture.append(d5[0])
d6 = chuli_image('new_caijianImg/chepai_6.png')
picture.append(d6[0])
d7 = chuli_image('new_caijianImg/chepai_7.png')
picture.append(d7[0])
# 應用模型,并列印出預測的結果
prediction_result = sess.run(tf.argmax(pred, 1), feed_dict={x: picture})
print(prediction_result)
dictionary = {
'0': '0', '1': '1', '2': '2', '3': '3', '4': '4', '5': '5', '6': '6', '7': '7', '8': '8', '9': '9',
'10': 'A', '11': 'B', '12': 'C', '13': 'D', '14': 'E', '15': 'F', '16': 'G', '17': 'H', '18': 'J', '19': 'K',
'20': 'L', '21': 'M', '22': 'N', '23': 'P', '24': 'Q', '25': 'R', '26': 'S', '27': 'T', '28': 'U', '29': 'V',
'30': 'W', '31': 'X', '32': 'Y', '33': 'Z', '34': '川', '35': '鄂', '36': '贛', '37': '甘', '38': '貴', '39': '桂',
'40': '黑', '41': '滬', '42': '冀', '43': '津', '44': '京', '45': '吉', '46': '遼', '47': '魯', '48': '蒙', '49': '閩',
'50': '寧', '51': '青', '52': '瓊', '53': '陜', '54': '蘇', '55': '晉', '56': '皖', '57': '湘', '58': '新', '59': '豫',
'60': '渝', '61': '粵', '62': '云', '63': '藏', '64': '浙'
}
result = ''
str_0 = dictionary[str(prediction_result[0])]
str_1 = dictionary[str(prediction_result[1])]
str_2 = dictionary[str(prediction_result[2])]
str_3 = dictionary[str(prediction_result[3])]
str_4 = dictionary[str(prediction_result[4])]
str_5 = dictionary[str(prediction_result[5])]
str_6 = dictionary[str(prediction_result[6])]
result = str_0 + str_1 + str_2 + str_3 + str_4 + str_5 + str_6
print("識別的車牌號為:" + result)
三、專案總結
因為這個專案主要想要學習的是機器學習識別部分,所以對于影像處理部分可能沒有這么的精確,中間沒處理好的也用到了“人工”剪切處理,反正就是無論你怎么處理,只要能處理成我們神經網路認識的圖片就好了,(當然也可以認真研究研究怎么把影像處理的更好,由于時間有限,我就偷個懶了~~)
認真把這個的小專案搞清楚,對前面的機器學習識別這一部分絕對有更高層次的理解,并且能鍛煉使用python處理資料以及編程的能力,最重要的我覺得是編程思想的提升,盡管可能這只是一個不是很復雜的小專案,不過說實話我在做這個的之一段時間,雖然有點累,但是我覺得我真的學習到了東西,也提升了不少能力,
不管怎樣,保持學習永遠沒有錯,不斷學習,不斷提升,共勉!
Keep Learning! Keep Moving!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/282316.html
標籤:python
上一篇:Python基于Django醫院預約掛號診療系統設計
下一篇:python中的內置函式