目錄結構:
1、專案介紹
2、網路設計
3、資料采集
4、APP開發
5、APP下載
6、效果展示
1、專案介紹:
該專案主要在于探索是否能在通用的安卓手機上實作一個輔助駕駛功能的APP,
功能與性能:
-
能夠檢測行人、自行車、電瓶車、汽車、卡車、公交車等常規交通參與者,
-
在行人等數量較多的情況下,可以發出提醒,
-
在前車距離過小的情況下,可以發出提醒,
-
能夠檢測出車道線(下一版本增加)
-
在偏離車道線的時候能夠發出提醒(下一版本增加)
-
能在手機上較為實時的運行(>=10fps)
2、網路設計
要實作車輛,行人等的檢測,需要一個常規的目標檢測網路(不考慮物體方向,否則手機性能不夠),實作車道線檢測需要一個車道線檢測網路,如果使用串行方式,勢必會增加延時,導致手機端無法流暢運行,因此這里考慮將兩個網路合并,共享backbone以及neck部分,目標檢測頭和車道線檢測頭相互獨立,如下圖所示:
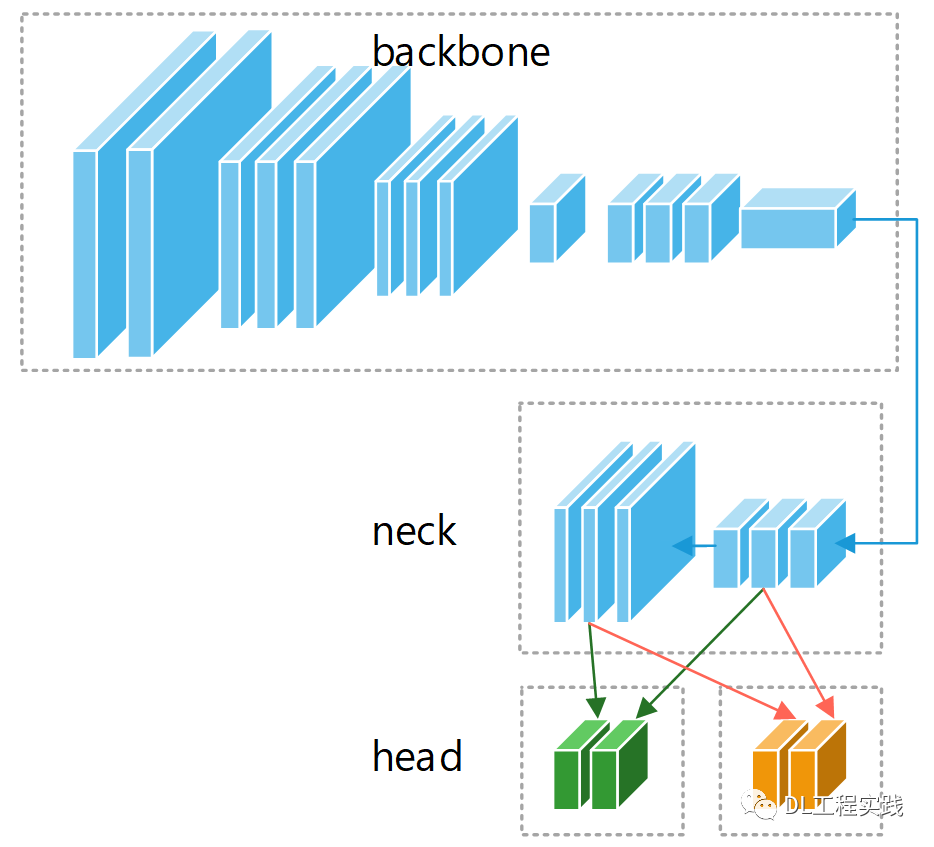
目標檢測網路:
輕量級的目標網路實際上有很多,例如mobilenetSSD,yolo-lite,yolo-fastest,nanodet,yolov5s等,綜合算力與精度,yolov5s是一個不錯的選擇,總的來說,yolov5在yolov3的基礎上,增加了一些降低計算量的模塊,例如FOCUS模塊,CSP模塊等,降低了yolo的計算量,另一方面,使用了PAN,SPP等,增加了網路的精度,本次的目標檢測就選擇yolov5s,
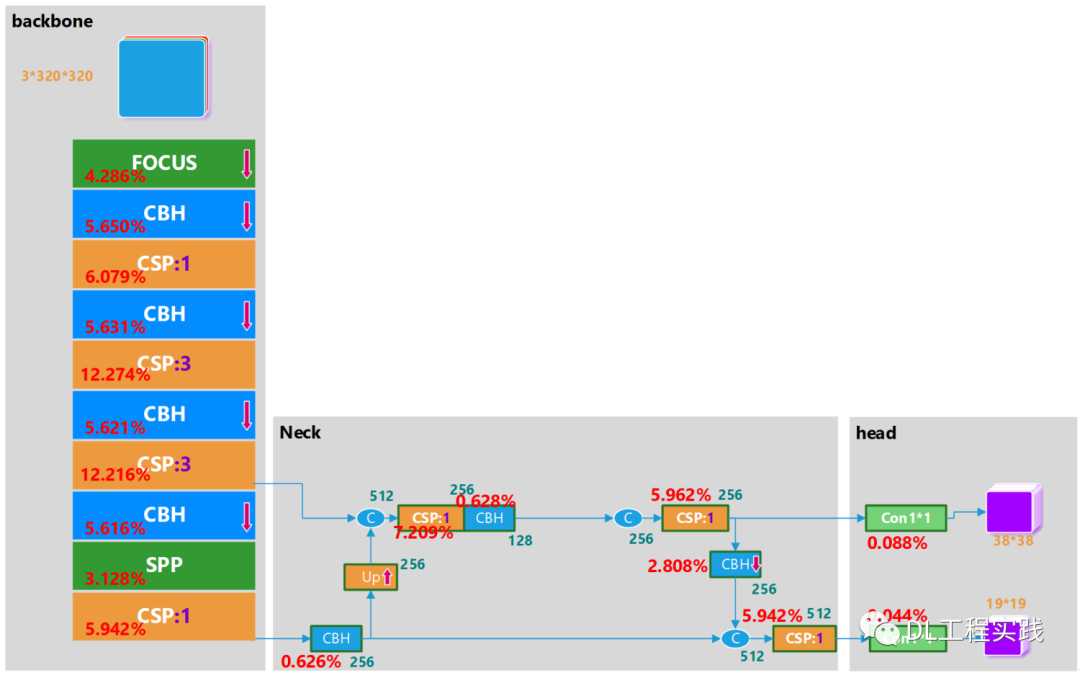
雖然yolov5s已經是一個相對輕量級的通用目標檢測框架,但是對于手機這樣的設備來說,想要實作實時的檢測,依然具有極大的挑戰,使用官方的yolov5s模型在手機上運行,檢測一張圖片的時間大約在800ms-1.5s之間,遠遠達不到實時,因此需要對yolov5s做一個精簡,如下圖所示為yolov5s的網路結構圖(輸入640*640),
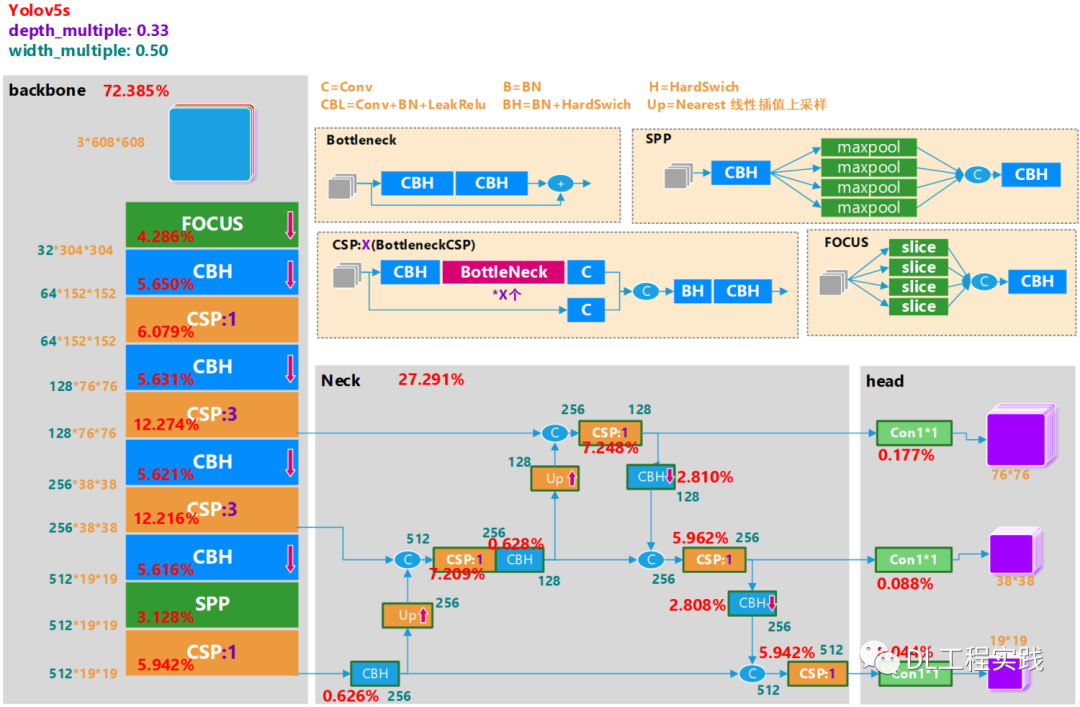
下面先簡單介紹一下網路結構,主要由backbne+neck+head組成,如圖中的三個灰色模塊,關于網路中使用的各個模塊,其細節如圖中的米黃色模塊所示 ,其中CBH為yolov5中的基礎模塊,包含一個卷積,一個BN層以及一個Swish的激活層,FOCUS是一種快速降采樣的方式,在傳統的 CNN網路 中,一般使用兩個大卷積7*7或者5*5進行快速的降低輸入影像的解析度,但是大卷積核就意味著大計算量,FOCUS首先將輸入圖片進行切片,然后在cat在一起,用一個卷積融合資訊,極大的降低了網路前期的計算量,再來看網路的Neck部分,很明顯的是增加了另外一個分支,原來的FPN將小解析度的特征圖上采樣之后融合進行各個level的預測,現在的PAN增加了從大解析度下采樣到小解析度的路徑,進一步融合了各個level之間的資訊,使得每個level能夠很好的保留空間資訊與語意資訊,
Yolov5s計算量
接下來分析一下yolov5s的計算量,如圖中的紅色字體已經標注了各個模塊的計算量占比,可以看到backbone大約占據了72%的計算量,而neck占據了27%的計算量,總的計算量大約為7.59G的計算量,這個計算量相對于手機來說還是非常巨大的,一般要想在手機上比較流暢的運行,計算量最好能降低到<1G的范圍,由于目前的計算量實在巨大,可以考慮降低輸入圖片的解析度,我們知道CNN關于輸入圖片解析度的計算復雜度可以表達為:O(H*W),其中H為輸入圖片的高度,W為輸入圖片的寬度,因此降低影像解析度可以得到一個平方倍的計算復雜度降低,這個收益還是比較大的,例如將影像的輸入解析度降低到原來的一半,計算復雜度就變成了O(1/2H*1/2W) = 1/4O(H*W),也就是 說將解析度降低一半,計算量減小為原來的1/4,通常輕量級分類網路的,考慮到我們輔助駕駛只需要判斷車輛附近的物件,不需要對遠處的小目標進行識別,那么選擇320*320的解析度作為輸入,這樣計算量就 大約變成了1/4*7.59G = 1.89G,
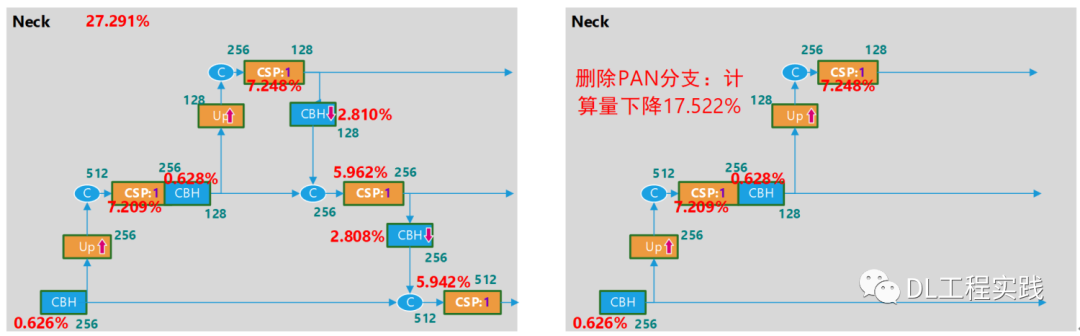
Yolov5s裁剪
繼續觀察網路結構,由于neck使用PAN,增加了一路資料通路,使得neck部分的計算量增加了一倍,那么可以考慮將PAN修改為FPN來降低計算量,如下圖所示:
還有一種方式就是減少輸出的level,Yolov5s默認輸出3個level的特征圖分別對應stride=8,16,32,由于輸入解析度已經被我們降低,且為了實作實時運行目標,我們也可以考慮將stride=8的level洗掉,這樣也能降低比較多的計算量,如下圖所示:
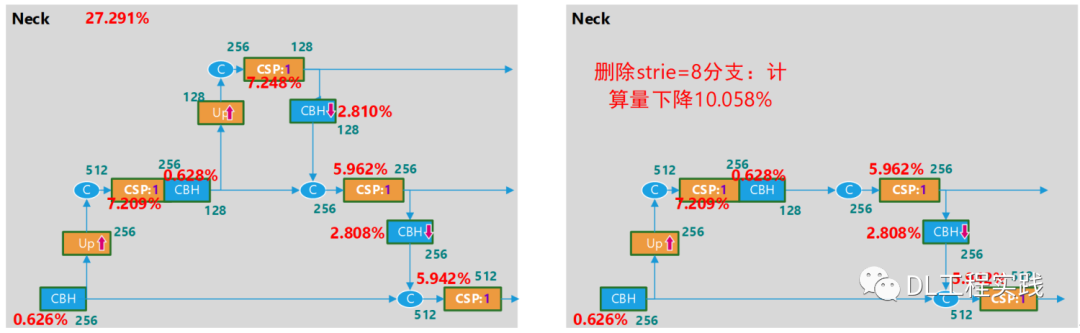
對過對比兩種方案,洗掉PAN通路降低的計算量相對多一些,但是結合訓練的最終精度(MAP),洗掉PAN通路的方式精度下降的比較明顯,而洗掉stride=8的方案,可以取得一個比較好的平衡,因此最終的精簡版本的網路結構為:
車道線檢測網路:
輕量級的車道線檢測網路并不是很多,因為大部分車道線檢測是基于分割任務來做的,大家都知道,分割任務的一個特點是需要保持一個較高的解析度,因此對于計算量,記憶體都是一個不小的挑戰,這里參考一篇比較創新的車道線檢測演算法:《Ultra Fast Structure-aware Deep Lane Detection》,效果一般,并且官方網路只支持4車道線檢測,但是特點就是快,論文的動機就是為了解決傳統基于分割方法檢測車道線的延時大的問題,下面來解讀一下這篇論文(論文地址:https://arxiv.org/abs/2004.11757)
核心方法
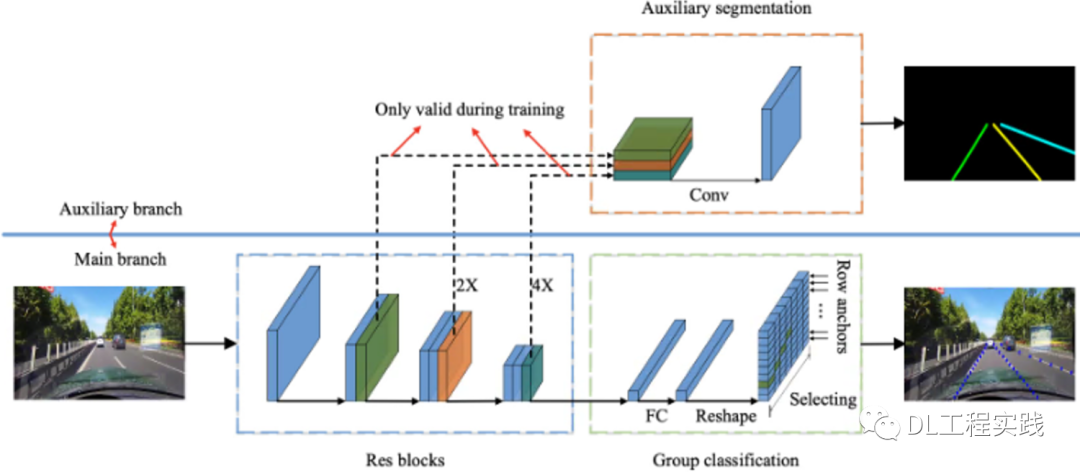
將車道線檢測定義為尋找車道線在影像中某些行的位置的集合,即基于行方向上的位置選擇與分類(row-based classification),這句話是整片論文的核心,如下圖所示,
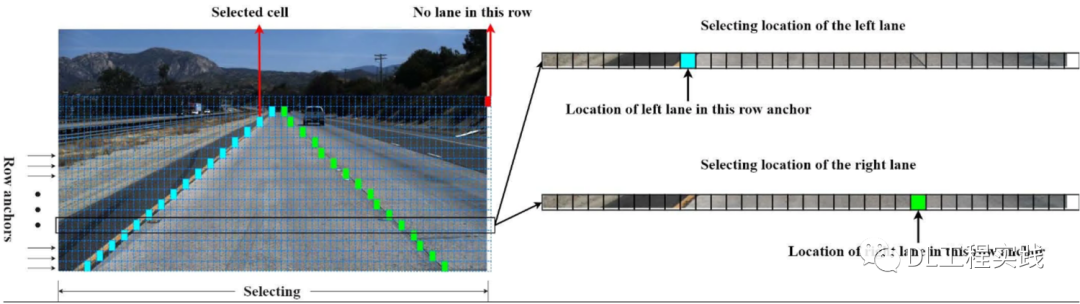
基于分割任務的車道線檢測中,分類物件是每個像素點,對一個像素點進行C+1個類別的分類(C為車道線的預設數目,+1表示背景類別,由于使用CE損失,所以需要增加一個背景類,如果不用CE損失,+1可以不需要),而該方案是對一行進行分類,分類的類別數為w+1(w表示圖片在寬度上被分割的數目,即grid_cell的數量,+1表示該行上面無車道線),表示的是行上面的哪個位置有車道,因此,兩種方案的分類含義不同,分割任務的分類是:H*W*(C+1), 該論文的分類是:C*h*(w+1),由于該論文的這種分類方式,可以很方便的做一些先驗約束,例如相領行之間的平滑與剛性等,而基于原始分割任務的卻很難做這方面的約束,
如何解決速度慢
由于我們的方案是行向選擇,假設我們在h個行上做選擇,我們只需要處理h個行上的分類問題,只不過每行上的分類問題是W維的,因此這樣就把原來HxW個分類問題簡化為了只需要h個分類問題,而且由于在哪些行上進行定位是可以人為設定的,因此h的大小可以按需設定,但一般h都是遠小于影像高度H的,(作者在博客中是這么說的,但是我認為雖然該方案的分類問題變少了,但是每個分類的維度變大了由原來的C+1變成了w+1, 即原來是H*W個分類問題,每個分類的維度是C+1, 現在是C*h個分類問題,每個分類的維度是w+1, 所以最終的分類總維度是從 H*W*(C+1) 變成了 C*h*(w+1),所以變快的主要原因是h<<H且w<<W,而不是分類數目的減少,)
如何解決感受野小
區域感受野小導致的復雜車道線檢測困難問題,由于我們的方法不是分割的全卷積形式,是一般的基于全連接層的分類,它所使用的特征是全域特征,這樣就直接解決了感受野的問題,對于我們的方法,在檢測某一行的車道線位置時,感受野就是全圖大小,因此也不需要復雜的資訊傳遞機制就可以實作很好的效果,(這也帶來了引數量大的問題,因為h和w不像分類網路下降的那么多,所以對于最后的全連接層來說,引數量將會很大)
先驗約束
平滑性約束:
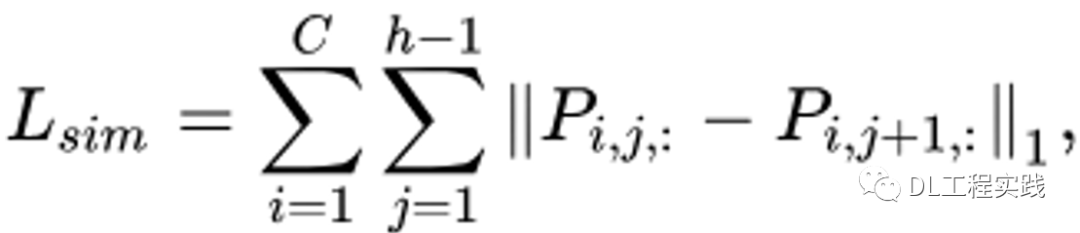
剛性約束:
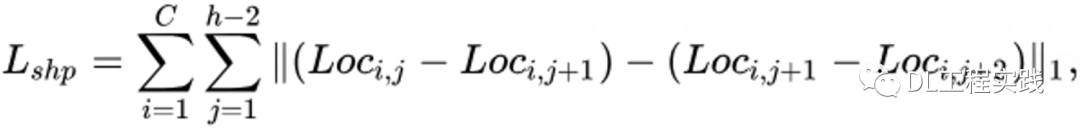
整體網路結構
整體網路結構如下圖所示(分割模塊作為訓練負責模塊,推理的時候不需要)
3、資料采集
通常來說,深度學習依賴大量的訓練資料,好在對于交通場景,已經有比較多的開源資料集存在,例如kitti,bdd100k,apploscape,cityscapes,tuSimple Lane,Culane等,由于手頭上只有mocrosoft的coco資料集,且coco資料集中包含了常規的行人,非機動車(自行車),機動車(car,bus,trunk),信號燈等,于是筆者準備先使用coco資料集進行訓練,
COCO資料集篩選
由于原生的coco資料集有80類別,對于我們的輔助駕駛來說很多都是沒有意義的,因此需要從里面選出帶有交通類別的資料,這里筆者寫了一個python腳本來進行自動化的篩選作業,
from pycocotools.coco import COCOimport numpy as npimport skimage.io as ioimport matplotlib.pyplot as pltimport osfrom PIL import Imagefrom PIL import ImageDrawimport csvimport shutil?def create_coco_maps(ann_handle):coco_name_maps = {}coco_id_maps = {}cat_ids = ann_handle.getCatIds()cat_infos = ann_handle.loadCats(cat_ids)for cat_info in cat_infos:cat_name = cat_info['name']cat_id = cat_info['id']?if cat_name not in coco_name_maps.keys():coco_name_maps[cat_name] = cat_idif cat_id not in coco_id_maps.keys():coco_id_maps[cat_id] = cat_name?return coco_name_maps, coco_id_maps?def get_need_cls_ids(need_cls_names, coco_name_maps):need_cls_ids = []for cls_name in coco_name_maps.keys():if cls_name in need_cls_names:need_cls_ids.append(coco_name_maps[cls_name])return need_cls_ids?def get_new_label_id(name, need_cls_names):for i,need_name in enumerate(need_cls_names):if name == need_name:return ireturn None?if __name__ == '__main__':# create coco ann handleneed_cls_names = ['person','bicycle','car','motorcycle','bus','truck','traffic light']dst_img_dir = '/dataset/coco_traffic_yolov5/images/val/'dst_label_dir = '/dataset/coco_traffic_yolov5/labels/val/'min_side = 0.04464 # while 224*224, min side is 10. 0.04464=10/224?dataDir='/dataset/COCO/'dataType='val2017'annFile = '{}/annotations/instances_{}.json'.format(dataDir,dataType)ann_handle=COCO(annFile)?# create coco maps for id and namecoco_name_maps, coco_id_maps = create_coco_maps(ann_handle)?# get need_cls_idsneed_cls_ids = get_need_cls_ids(need_cls_names, coco_name_maps)?# get all imgidsimg_ids = ann_handle.getImgIds() # get all imgidsfor i,img_id in enumerate(img_ids):print('process img: %d/%d'%(i, len(img_ids)))new_info = ''img_info = ann_handle.loadImgs(img_id)[0]img_name = img_info['file_name']img_height = img_info['height']img_width = img_info['width']?boj_infos = []ann_ids = ann_handle.getAnnIds(imgIds=img_id,iscrowd=None)for ann_id in ann_ids:anns = ann_handle.loadAnns(ann_id)[0]obj_cls = anns['category_id']obj_name = coco_id_maps[obj_cls]obj_box = anns['bbox']?if obj_name in need_cls_names:new_label = get_new_label_id(obj_name, need_cls_names)x1 = obj_box[0]y1 = obj_box[1]w = obj_box[2]h = obj_box[3]?#x_c_norm = (x1) / img_width#y_c_norm = (y1) / img_heightx_c_norm = (x1 + w / 2.0) / img_widthy_c_norm = (y1 + h / 2.0) / img_height?w_norm = w / img_widthh_norm = h / img_height?if w_norm > min_side and h_norm > min_side:boj_infos.append('%d %.4f %.4f %.4f %.4f\n'%(new_label, x_c_norm, y_c_norm, w_norm, h_norm))?if len(boj_infos) > 0:print(' this img has need cls')shutil.copy(dataDir + '/' + dataType + '/' + img_name, dst_img_dir + '/' + img_name)with open(dst_label_dir + '/' + img_name.replace('.jpg', '.txt'), 'w') as f:f.writelines(boj_infos)else:print(' this img has no need cls')
4、APP開發
模型轉換
由于訓練程序使用的是pytorch框架,而pytorch框架是無法直接在手機上運行的,因此需要將pytorch模型轉換為手機上支持的模型,這其實就是深度學習模型部署的問題,可以選擇的開源專案非常多,例如mnn,ncnn,tnn等,這里我選擇使用ncnn,因為ncnn開源的早,使用的人多,網路支持,硬體支持都還不錯,關鍵是很多問題都能搜索到別人的經驗,可以少走很多彎路,但是遺憾的是ncnn并不支持直接將pytorch模型匯入,需要先轉換成onnx格式,然后再將onnx格式匯入到ncnn中,另外注意一點,將pytroch的模型到onnx之后有許多膠水op,這在ncnn中是不支持的,需要使用另外一個開源工具:onnx-simplifier對onnx模型進行剪裁,然后再匯入到ncnn中,因此整個程序還有些許繁瑣,為了簡單,我撰寫了從"pytorch模型->onnx模型->onnx模型精簡->ncnn模型"的轉換腳本,方便大家一鍵轉換,減少中間程序出錯,我把主要流程的代碼貼出來,
# 1、pytroch模型匯出到onnx模型torch.onnx.export(net,input,onnx_file,verbose=DETAIL_LOG)?# 2、呼叫onnx-simplifier工具對onnx模型進行精簡cmd = 'python -m onnxsim ' + str(onnx_file) + ' ' + str(onnx_sim_file)ret = os.system(str(cmd))?# 3、呼叫ncnn的onnx2ncnn工具,將onnx模型準換為ncnn模型cmd = onnx2ncnn_path + ' ' + str(new_onnx_file) + ' ' + str(ncnn_param_file) + ' ' + str(ncnn_bin_file)ret = os.system(str(cmd))?# 4、對ncnn模型加密(可選步驟)cmd = ncnn2mem_path + ' ' + str(ncnn_param_file) + ' ' + str(ncnn_bin_file) + ' ' + str(ncnn_id_file) + ' ' + str(ncnn_mem_file)ret = os.system(str(cmd))
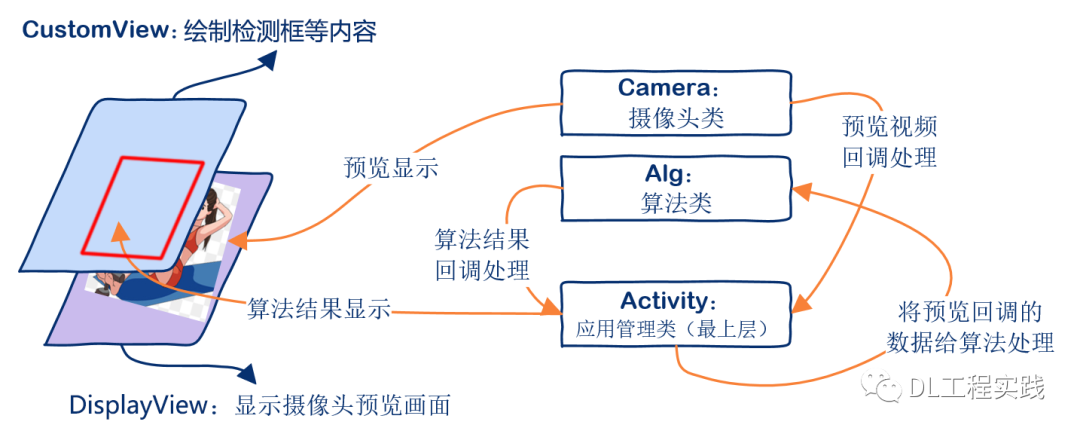
APP結構
當完成了所有的演算法模塊開發之后,APP開發實際上是水到渠成的事情,這里沿用運動技術APP中的框架,如下圖所示:
APP主要原始碼:
參考計數APP開發中的原始碼示例:
Activity類核心原始碼
Camera類核心原始碼
Alg類核心原始碼
5、APP下載
語雀平臺下載:
https://www.yuque.com/lgddx/xmlb/ny150b
百度網盤下載:
鏈接:https://pan.baidu.com/s/13YAPaI_WdaMcjWWY8Syh5w
提取碼:hhjl

6、效果展示
手持手機在馬路口隨拍測驗:
https://www.yuque.com/lgddx/xmlb/wyozh2
>堆堆星微信:15158106211
>官方微信討論群:先加堆堆星,再拉進群
>官方QQ討論群:885194271
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/282424.html
標籤:python