日志在系統中起到非常重要的debug作用,出core后debug離不開日志的幫助。但是一般的日志又比較慢,對于速度有極致追求的系統,開發人員不得不洗掉或關閉部分甚至全部日志運行系統,但這樣又會導致出bug時難以定位。為了更好的解決這一問題。斯坦福大學的大神們開發了一款延遲極低的開源日志工具Nanolog。
Nanolog在低延遲和高吞吐兩方面做了幾點精妙的改進。非常值得對低延遲技術有興趣的朋友進行深入學習。
01丨Nanolog有多快
C++日志系統有很多開源的專案,如log4clpus、glog、spdlog、boostlog、log4j等。相對這些常見的Log庫,Nanalog快一到兩個數量級。
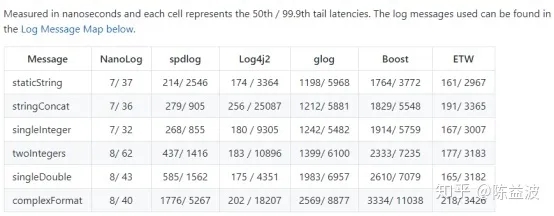
如上圖所示,Nanolog的呼叫開銷中位數為個位數納秒。其他幾款知名開源log的呼叫則需要耗時幾百甚至上千納秒。Nanolog的中位數和99.9分位的延遲要比其他的小一到兩個數量級。
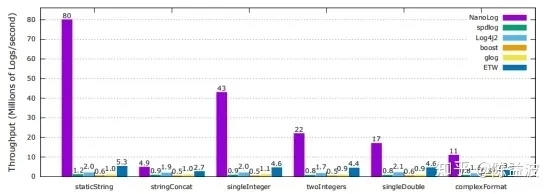
上圖為不同日志庫列印吞吐率對比,紫色的為Nanolog,比其它日志系統每秒吞吐量高幾倍到幾十倍。

上圖為本人跑的Benchmark測驗結果,每秒可輸出143,494,928條日志,平均7ns輸出一條,寫log延遲平均僅2ns每條。另外,本人也測驗了輸出字串加整形加浮點這樣一條日志,發現延遲僅為5ns每條。
02丨Nanolog快的原因
首先為了降低寫延遲,Nanolog用到的第一個編程技術就是無鎖編程。這里說的無鎖編程是真的完全沒有鎖。而非有的文章中寫的將基于CAS鎖的編程稱為無鎖編程。在低延遲的世界里,CAS鎖也是鎖。無鎖編程使得任何寫執行緒都能在較確定性的時間內非常快的完成呼叫,不會因為不同執行緒競爭資源而卡住不確定的時間。
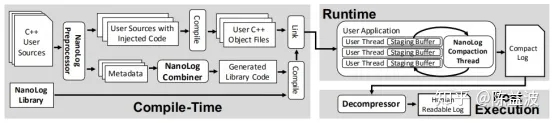
通過基于C++11標準中引入的 __thread 關鍵字,Nanolog為每一個執行緒創建了一個獨立的無鎖環形佇列。記憶體屏蔽是多執行緒能同步的基礎,基于記憶體屏蔽可以實作無鎖佇列,單生產者單消費者可以用一個無鎖佇列來實作無鎖編程,這個是無鎖編程的一個基礎,再通過多個無鎖佇列就可以做到多生產者單消費者的無鎖編程。這也是低延遲編程必用的技能。
降低延遲的第二個關鍵點便是盡量減少cache miss。低延遲系統要應對的頭號敵人就是cache miss,低延遲系統要盡量避免cache miss。為了減少佇列生產者和消費者多執行緒造成佇列頭尾指標判斷時的cache miss。生產者端會快取消費者執行緒在環形佇列中的尾的位置。只有當空間不足時才重新讀取一次隊尾位置。這樣就不會每次寫入都可能發生cache miss,而是只有寫滿一次環形佇列時,才會發生一次cache miss。撰寫多執行緒低延遲系統時要合理規劃結構體的記憶體布局,按執行緒對變數的讀寫情況規劃變數定義順序,盡可能按執行緒訪問順序定義結構體順序,同一執行緒的放一起,不同執行緒間會改變的變數中間加一個cache line長度的空間進行分開,避免因false sharing導致cache miss。比如該專案中的環形佇列中作者便放了兩條cache line長度的定義進行隔離(參考RuntimeLogger.h中的charcacheLineSpacer[2*Util::BYTES_PER_CACHE_LINE])。這里為什么不是一倍而是兩倍長度,本人也有點費解,有誰了解的希望能指點一二。
第三點,當討論的是納秒級別的延遲時,任何慢速的函式呼叫都要盡可能避免。通過系統介面去取時間就會顯得偏慢,Nanolog采用的是記錄系統的tsc暫存器的數值來記錄時間。再將這個數值在日志處理執行緒中還原成日歷時間。這一方法使得日志寫執行緒的時間獲取延遲降低為讀暫存器級別。同樣也是低延遲交易系統中必用的技巧。低延遲系統應當盡可能的避免使用慢速介面呼叫。比如gettimeofday對低延遲系統來說就是慢速呼叫,在核心執行緒中要避免使用。
把變數轉成字串這樣的格式化轉換是一個很耗時的操作,Nanolog把格式化操作放到副執行緒里執行。如果要想實作系統低延遲,就盡可能的避免在核心執行緒中出現格式化處理,比如把數值轉成字串,能避免的一律避免。統統放到輔助執行緒中處理。
第四點值得學習的是,在某些耗時最大的環節可以通過對資訊進行壓縮再解壓來提升速度。對于日志系統來說,寫檔案就是一個瓶頸。但是考慮到大多時候日志不需要實時去看。可以先寫入壓縮格式的日志檔案來降低寫入量。在要查看日志時再解壓成人眼可讀的格式即可。同時有大量靜態字串日志資訊是重復不變的,沒有必要每次呼叫都寫入相同的靜態字串,只需要記錄一次或者預編譯時記錄。Nanolog提供了兩種版本,預編譯版本便是在預編譯時就進行了處理。運行時不會重復寫入靜態字串,只寫入變數資訊,如整形,浮點型字串變數。并且在寫入日志時進行了壓縮操作只寫入壓縮后的二進制資訊以提高IO吞吐率。在日志完成后,通過后續解壓縮來還原成人眼可讀的文本檔案。這一思路也是很值得學習的,比如網路傳輸時,要把異地交易所的信號進行跨網路傳輸。考慮到CPU處理速度通常遠遠快于專線的網路傳輸速度。可以先將資料先做壓縮,收到后解壓再使用。
03丨Nanolog 原始碼以及論文
Nanolog基于C++17標準開發,源代碼地址如下: https://github.com/PlatformLab/NanoLog
注意,github上有一個基于C++11標準開發的同名開源專案,不要搞錯了,那個C++11的專案測驗過延遲比這個正真對應的結果慢大約100倍。
論文于2018 USENIX年度技識訓議,下載地址:
https://www.usenix.org/conference/atc18/presentation/yang-stephen
04丨改進
最后提供一個無壓縮版本的代碼供參考。Nanolog壓縮的特性使得對于要tail -f 實時看日志變得不是那么方便。考慮到某些場景只追求呼叫的低延遲,不追求高吞吐。每次查看log還需要解壓的話使用起來就不夠方便了。對于這一點,我們可以修改代碼,把輔助執行緒中的壓縮存盤這步改為直接輸出人眼可讀的結果。這樣的修改不會增加呼叫的延遲,只是會降低吞吐率。對于不關注吞吐率只關注低延遲的應用可以參考朱大牛修改的直接輸出版本,github鏈接:zwzw1/NanoLog
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/282429.html
標籤:C++ 語言
上一篇:C++ 發展如何了?
下一篇:麻煩幫我看看這個程式的問題