Java生鮮電商平臺-電商搜索引擎架構設計與大資料平臺架構實踐(小程式/APP)
說明:Java生鮮電商平臺-電商搜索引擎架構設計與大資料平臺架構實踐,本文主要是講解電商搜索引擎的設計以及大資料平臺架構實戰
電商搜索引擎,是幫助顧客快速找到需要購買的商品的工具,衡量一個電商搜索引擎是 否成功的標準是,顧客在一連串的搜索行為當中,是否越來越接近自己的真實需求,顧客越 快進入商品頁面去瀏覽商品,越表明搜索引擎推薦的搜索結果越精確,電商搜索引擎,是傳 統搜索引擎的一個垂直領域,為了更好地學習搜索引擎的相關知識,我們首先要看一個完整 的搜索引擎的技術架構,
一個完整的搜索引擎技術框架,如圖 所示,搜索引擎的技術架構,分成 3 個部分
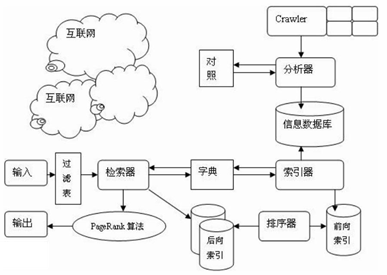
資訊采集、建立索引庫、提供檢索服務,下面我們分別來探討這 3 部分內容,
資訊采集, 在互聯網中發現、搜集資訊和資料,通常, 這個步驟是通過爬蟲
(Crawler/Spider)抓取網頁來實作的,每個獨立的搜索引擎都有自己的網頁抓取程式爬蟲,爬蟲 Spider 順著網頁中的超鏈接,從這個網站爬到另一個網站,通過超鏈接分析連續訪問抓取更多網頁,被抓取的網頁被稱之為網頁快照,由于互聯網中超鏈接的應用很普遍,理論上,從一定范圍的網頁出發,就能搜集到絕大多數的網頁,
建立索引庫,對收集到的資訊進行提取和組織建立索引庫,搜索引擎抓到網頁后,還要 做大量的預處理作業,才能提供檢索服務,其中,最重要的就是提取關鍵詞,建立索引庫和 索引,根據應用場景的不同,其他可能的處理還包括去除重復網頁、分詞(中文)、判斷網 頁型別、分析超鏈接、計算網頁的重要度/豐富度等,
提供檢索服務,由檢索器根據用戶輸入的查詢關鍵字,提供檢索服務,接受到關鍵詞后, 系統在索引庫中快速檢出檔案,進行檔案與查詢的相關度評價,對將要輸出的結果進行排序, 并將查詢結果回傳給用戶,通常,為了用戶便于判斷,除了網頁標題和 URL 外,還會提供一段來自網頁的摘要及其他資訊,
其實搜索已經是一項非常成熟的技術,這里不打算展開討論了,只介紹幾個在搜索技術 架構上比較重要的技術點:分布式索引、分布式搜索,
分布式索引,就是通過很多普通配置的硬體,同時進行索引建立的作業,最后進行索引 的合并操作,這樣處理的好處在于,具備可擴展性,當資料增加的時候,無須增加單臺機器的存盤設備,而是通過水平擴展,增加配置普通的機器來解決,建立分布式索引,可采用
Hadoop 這類分布式系統進行構建,Hadoop 實作了一個分布式檔案系統(Hadoop Distributed File System),簡稱 HDFS,HDFS 有高容錯性的特點,并且設計用來部署在低廉的硬體上; 同時它提供高傳輸率來訪問應用程式的資料,適合那些有著超大資料集的應用程式,HDFS 的上一層是 MapReduce 引擎,用于大規模資料集的并行運算,概念 Map(映射)和 Reduce(規約),和它們的主要思想,都是從函式式編程語言里借來的,還有從矢量編程語言里借來的特性,基于這些分布式特性,搜索索引建立可以非常容易地通過它來進行擴展,利用
Hadoop 的平臺和 MapReduce 的機制,來實作建立分布式搜索索引,是非常好的實踐,
分布式搜索,是將原來的單個索引檔案劃分成 n 個切片(shards),搜索時,并行的搜索這 n 個切片,每個切片回傳當前 shard 的 topK 命中結果;然后將 n 個切片的區域 topK 進行歸并排序,得到全域的 topK 排序結果,分布式搜索的好處在于:更好的可擴展性,在用戶訪問次數和索引大小兩個維度都具有水平擴展能力;更高的穩定性,容許部分失敗,呼叫成功率顯著提高;更靈活的全量更新策略,可針對不同型別的資料;更靈活的排序演算法,可 以針對不同類目,做定制化的排序;更好的可維護性和通用性,支持不同型別的搜索,
大資料平臺架構設計
近年來,大家對大資料的關注度和使用頻率越來越高,軟體產品中的各類資料都被記錄 下來,以便更好地研究和分析,在電商企業中,每天系統記錄下來的運營資料,達到幾百
GB 增量的規模,為了保證所有資料能集中存盤并且可隨時訪問,越來越多的企業把離線資料體系從商用的 Exadata 等解決方案,全面轉向開放的 Hadoop 體系當中,以謀求成本與擴展性的平衡,
有一定技術實力的互聯網公司,紛紛搭建自己的大資料平臺,如圖所示是一個典型
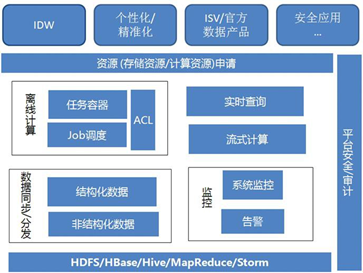
的大資料平臺的技術架構,下面我們一起來學習,從圖 可以看到,大資料平臺是由資料存盤、資料同步分發、監控、離線計算、平臺安全、資源申請等部分構成的
資料存盤,是整個大資料平臺的基礎,包含如:HDFS、HBase、Hive、MapReduce、
Storm 等等,下面,我們對其中的主要框架做些介紹,詳細資料大家可以到搜索引擎中獲取,
HDFS,分布式檔案系統,Hadoop 的核心組成部分,
MapReduce,分布式資料處理,Hadoop 核心之一,
HBase,一個分布式的,列存盤資料庫,使用 HDFS 作為底層存盤,同時支持 MapReduce
的批量式計算和點查詢,
Zookeeper,一個分布式的,高可用的協調服務,提供分布式鎖之類的基本服務,用于構建分布式應用,
Hive,分布式資料倉庫,Hive 管理 HDFS 中存盤的資料,并提供基于 SQL 的查詢語言用以查詢資料,
Hama,建立在 Hadoop 上的分布式并行計算框架,基于 Map/Reduce 和Bulk Synchronous
的實作框架,運行環境需要關聯 Zookeeper、HBase、HDFS 組件,
Mahout,一個基于 MapReduce 的機器學習演算法庫,運行在 Hadoop 集群上,
Cassandra,一種混合的非關系型資料庫,類似于 Google 的 BigTable,
以上就是資料存盤層中,用到的一些開源資料框架,我們繼續看大資料平臺的其他組成 部分,
資料同步分發,這個組件對資料同步和分發做統一管理,可實作異步、分布式的資料同 步和分發,
監控,指的是對大資料平臺的服務和資源,進行監控和預警,包括資料存盤的可用性、 性能、系統負載、資源請求的回應時效等,
離線計算,處理離線計算任務的模塊,包括任務容器、任務調度定時器、例外捕獲等模 塊,確保離線計算任務能夠在資源容許的情況下,按計劃運行,
平臺安全,主要包括對資料訪問權限的管理,把資料劃分成不同的安全等級進行管理, 當訪問某些安全級別高的資料時,會觸發一個審批流程,經過主管審批后才能訪問,
資源申請,指的是對大資料平臺的計算或存盤資源發起一個使用請求,這里會記錄每一 個資料操作訪問,以供日后審計,
結語
復盤與總結.
總結:
做Java生鮮電商平臺的互聯網應用,無論是生鮮小程式還是APP,電商搜索引擎架構設計與大資料平臺架構實踐是非常重要的,本文只是起一個拋磚引玉的作用,
希望用生鮮小程式的搭建電商搜索引擎架構設計與大資料平臺架構實踐實戰經驗告訴大家一些實際的專案經驗,希望對大家有用.
QQ:137071249
共同學習QQ群:793305035
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/285554.html
標籤:Java