一、業務背景
在系統業務開發的程序中,都會面臨這樣一個問題:面對業務的快速擴展,很多版本在當時沒有時間去全域考慮,導致很多業務資料存盤和管理并不規范,例如常見的問題:
- 地址采取輸入的方式,而非三級聯動;
- 沒有統一管理資料字典獲取介面;
- 資料存盤的位置和結構設計不合理;
- 不同服務的資料庫之間存在同步通道;
而分析業務通常都是要面對全域資料,如果出現大量的上述情況,就會導致資料在使用的時候難度非常大,隨之也會帶來很多問題:資料分散不規范,導致回應性能差,穩定性低,同時提高管理成本,
當隨著業務發展,資料的沉淀越來越多,使用的難度就會陡增,會導致在資料分析之前,需要大量時間去清洗資料,
二、資料清洗概述
1、基本方案
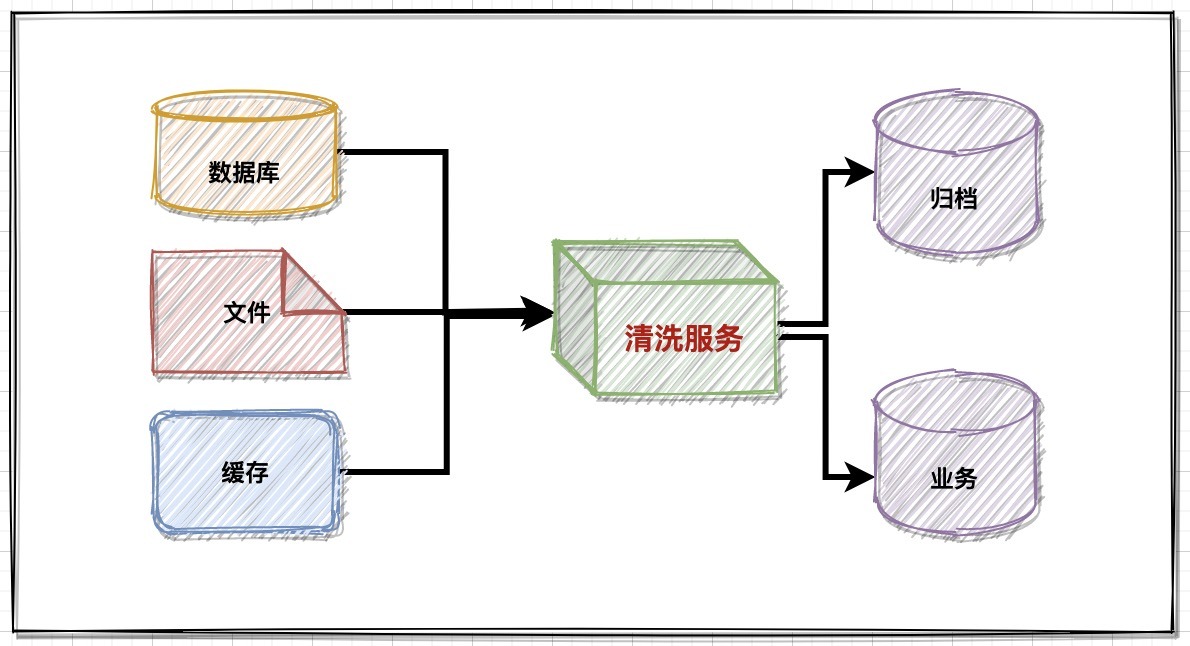
核心思想:
- 讀-洗-寫入業務庫持續服務;
- 讀-洗-寫入檔案資料資產庫;
業務資料清洗本質上理解起來并不難,即讀取待清洗的資料源,經過清洗服務規范化處理后,再把資料放到指定的資料源,但是實際操作起來絕對叫人眼花撩到,
2、容器遷移
資料存盤的方式本身就是多種選擇,清洗資料要面對的第一個問題就是:資料容器的遷移;
- 讀資料源:檔案、快取、資料庫等;
- 臨時容器:清洗程序存盤節點資料;
- 寫資料源:清洗后資料注入的容器;
所以清洗資料的第一步就是明確整個流程下要適配多少資料源,做好服務的基礎功能設計與架構,這是支撐清洗服務的基礎;
3、結構化管理
讀取的清洗資料可能并不是基于庫表管理的結構化資料,或者在資料處理程序中在中間臨時容器存盤時,為了方便下次操作取到資料,都需要對資料做簡單的結構管理;
例如:通常讀取檔案的服務性能是很差,當資料讀取之后在清洗的程序中,一旦流程中斷,可能需要對資料重新讀取,此時如果再次讀取檔案是不合理的,檔案中資料一旦讀取出來,應該轉換成簡單的結構存盤在臨時容器中,方便再次獲取,避免重溫處理檔案的IO流;
常見資料結構管理的幾個業務場景:
- 資料容器更換,需要重組結構;
- 臟資料結構洗掉或者多欄位合并;
- 檔案資料(Json、Xml等)轉結構;
注意:這里的結構管理可能不是單純的庫表結構,也可能是基于庫表存盤的JSON結構或者其他,主要為了方便清洗流程的使用,以至最終資料的寫入,
4、標準化內容
標準化內容則是資料清洗服務中的一些基本準則,或者一些業務中的規范,這塊完全根據需求來確定,也涉及到清洗資料的一些基本方法;
于業務本身的需求而言,可能常見幾個清洗策略如下:
-
基于字典統一管理:例如常見的地址輸入,如果值
浦東新區XX路XX區,這樣要清洗為上海市-浦東新區-XX路XX區,省市區這種地域肯定是要基于字典方式管理的表,事實上在系統中很多欄位屬性都是要基于字典去管理值的邊界和規范,這樣處理之后有利于資料的使用、搜索、分析等; -
資料分析檔案化:例如在某個業務模塊需要用戶實名認證,如果認證成功,基于手機號+身份證所讀取到的用戶資訊則是變動極小,特別是基于身份證號分解出來的相關資料,這些資料則可以作為用戶檔案資料,做資料資產化管理;
-
業務資料結構重組:通常分析都會基于全域資料來處理,這就涉及到資料分分合合的管理,這樣可能需要對部分資料結構做搬運,或者不同業務場景下的資料結構做合并,這樣整體分析,更容易捕獲有價值的資訊資料;
然對于資料清洗本身來說,也是有一些基本策略:
- 資料基礎結構的增、刪、合并等;
- 資料型別的轉變,或者長度處理;
- 資料分析中數值轉換、缺失資料彌補或丟棄;
- 資料值本身的規范化處理,修復等;
- 統一字串、日期、時間戳等格式;
在資料清洗的策略中并沒有一個標準化的規范,這完全取決資料清洗后的業務需求,例如資料質量差,嚴重缺失的話可能直接丟棄,也可能基于多種策略做彌補,這完全取決于結果資料的應用場景,
三、服務架構
1、基礎設計
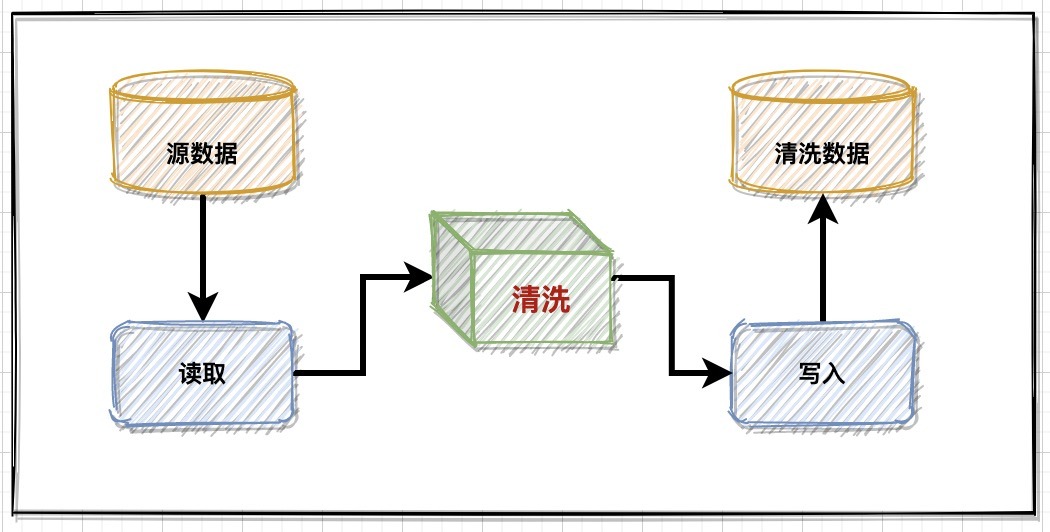
通常在資料清洗的服務中,會圍繞資料的讀-洗-寫基本鏈路來做架構,各個場景本身并沒有過于復雜的邏輯:
資料源讀取
資料源讀取兩面對兩個關鍵問題之一:適配,不同的存盤方式,要開發不同的讀取機制;
- 資料庫:MySQL、Oracle等;
- 檔案型:XML、CSV、Excel等;
- 中間件:Redis、ES索引等;
另一個關鍵問題就是資料讀取規則:涉及讀取速度,大小,先后等;
- 如果資料檔案過大可能要做切割;
- 資料間如果存在時序性,要分先后讀取;
- 根據清洗服務處理能力,測評讀取大小;
2、服務間互動
事實上服務間如何互動,如何管理資料在整個清洗鏈路上的流動規則,需要根據不同服務角色的吞吐量去考量,基本互動邏輯為兩個:直調、異步;
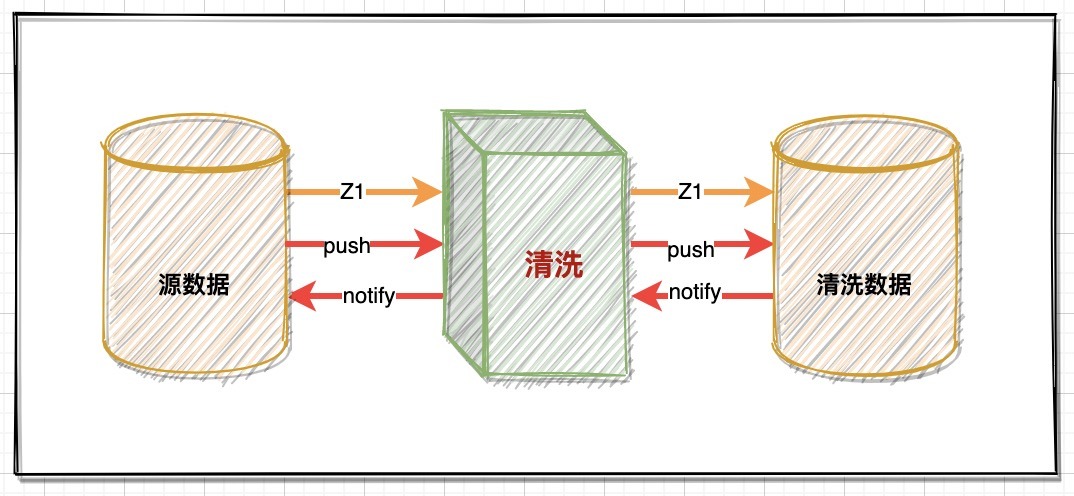
-
直調:如果各服務節點處理能力相同,采用直調方式即可,這種方式流程比較簡單,并且可以第一時間捕獲例外,做相應的補償處理,但實際上清洗服務要處理的規則非常多,自然要耗時很多;
-
異步:每個服務間做解耦,通過異步的方式推動各個節點服務執行,例如資料讀取之后,異步呼叫清洗服務,當資料清洗完成后,在異步呼叫資料寫入服務,同時通知資料讀服務再次讀取資料,這樣各個服務的資源有釋放的空隙,降低服務壓力,為了提高效率可以在不同服務做一些預處理,這樣的流程設計雖然更合理,但是復雜度偏高,
資料的清洗是一個細致且耗費精力的活,要根據不同需求,對服務做持續優化和通用功能的沉淀,
3、流程化管理
對資料清洗鏈路做一個流程管理十分有必要,通常要從兩個方面考慮:節點狀態、節點資料;
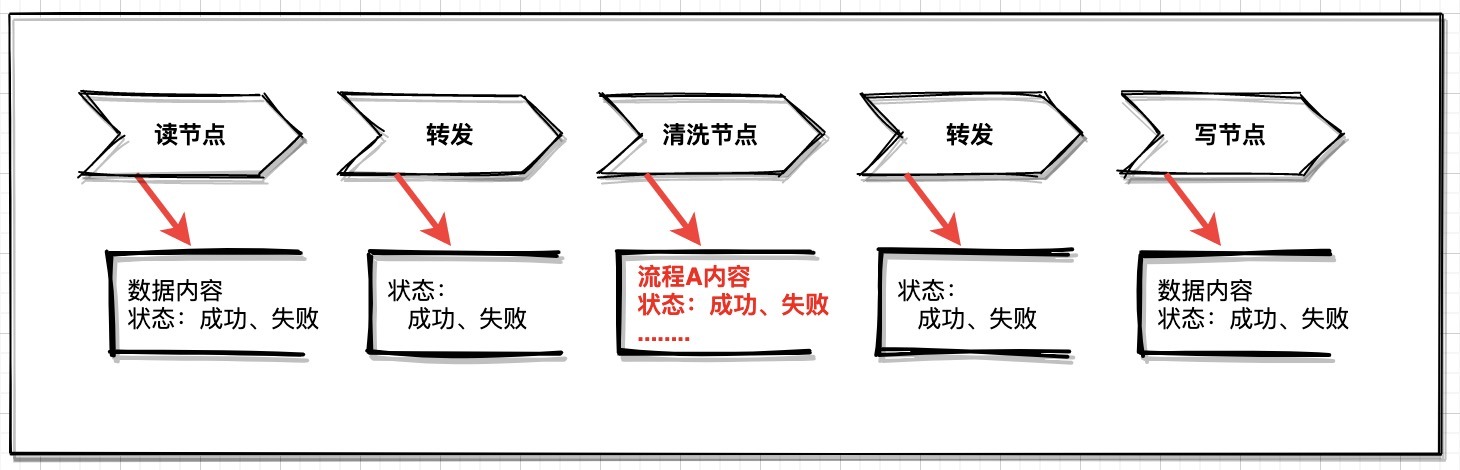
清洗節點:這是重點記錄的節點,如果清洗規則過多,分批處理的話,對于每個關鍵流程處理成功后的資料和狀態做記錄尤其重要;
讀寫節點:根據資料源型別選擇性存盤,例如檔案型別;
轉發節點:記錄轉發狀態,常見成功或者失敗狀態;
對于關鍵節點結果記錄,可以在清洗鏈路失敗的時候快速執行重試機制,哪個節點出現例外,可以快速構建重新執行的資料,例如讀取檔案A的資料,但是清洗程序失敗,那么可以基于讀節點的資料記錄快速重試;
如果資料量過大,可以對處理成功的資料進行周期性洗掉,或者直接在資料寫成功之后直接通知洗掉,降低維護清洗鏈路本身對資源的過度占用,
4、工具化沉淀
在資料清洗的鏈路中,可以對一些工具型代碼做持續沉淀和擴展:
- 資料源適配,常用庫和檔案型別;
- 檔案切割,對大檔案的處理;
- 非結構化資料轉結構化表資料;
- 資料型別轉換和校驗機制;
- 并發模式設計,多執行緒處理;
- 清洗規則策略配置,字典資料管理;
資料清洗的業務和規則很難一概而論,但是對清洗服務的架構設計,和鏈路中工具的封裝沉淀是很有必要的,從而可以集中時間和精力處理業務本身,這樣面對不同的業務場景,可以更加的快速和高效,
5、鏈路測驗
資料清洗的鏈路是比較長的,所以對鏈路的測驗很有必要,基本上從兩個極端情況測驗即可:
- 缺失:非必要資料之外全部缺失;
- 完整:所有資料屬性的值全存在;
這兩個場景為了驗證清洗鏈路的可用性和準確性,降低例外發生的可能性,

閱讀標簽
【Java基礎】【設計模式】【結構與演算法】【Linux系統】【資料庫】
【分布式架構】【微服務】【大資料組件】【SpringBoot進階】【Spring&Boot基礎】
【資料分析】【技術導圖】【 職場】
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/285557.html
標籤:Java