目錄
- 1 pd.concat()軸連接合并
- 2 pd.merge() 連接資料
- 3 df.join()
- 4 df.append()
1 pd.concat()軸連接合并
pd.concat(objs, axis=0, join='outer',
join_axes=None, ignore_index=False, keys=None, levels=None,
names=None, verify_integrity=False, sort=None, copy=True)
功能說明:
??多個dataframe或者series拼接到一起,指定方向(上下堆疊、左右拼接),指定合并方式(交集、并集),
引數說明:
- objs:連接的物件,多個 DataFrame 或者 Series,例如[df1,df2];
- axis:指定合并的方向,0,縱向合并,對比列標簽;1,橫向合并,對比行標簽;
- join:連接方式,outer,并集(index全部需要);inner,交集(只取index重合的部分);
- join_axes:傳入需要保留的index,如[df1.index]或[df1.columns],在官方檔案中提醒即將被棄用,
- ignore_index:是否保留原表索引,默認保留,為 True 會自動增加自然索引,
- keys:構造層次結構索引,給每個表指定一個一級索引,
- levels:不常用,傳入序列串列,默認值無,用于構建MultiIndex的特定級別(唯一值),
- names:索引的名稱,包括多層索引,標記每條記錄來自于哪個表,
- verify_integrity:
- sort:布林值,默認值無,當" join"為" outer"時,如果有未對齊的軸,則對軸資訊進行排序,不設定sort會有警告資訊,
- 顯式傳遞``sort = True''使警告靜音,進行排序,
- 顯式傳遞``sort = False''以使警告靜音而不進行排序,
- 當"join ='inner'"已經保留了非串聯軸的順序時,這個命令無效,
- copy:bool,默認為True,如果為False,則不要不必要地復制資料,
資料源:
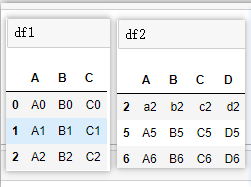
# ①基本連接:縱向合并,取交集
pd.concat([df1, df2])
# ②axis = 1,橫向合并
pd.concat([df1,df2],axis=1)
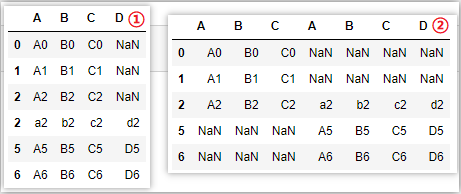
# ③join = 'inner',取交集
pd.concat([df1,df2],join='inner')
pd.concat([df1,df2],join='inner',axis=1)
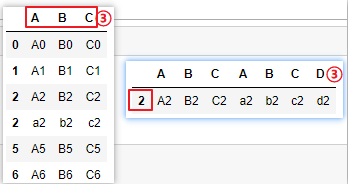
# ④join_axes=[df.index],根據需要保留的index進行合并
pd.concat([df1,df2],join_axes=[df1.columns])
pd.concat([df1,df2],axis=1,join_axes=[df2.index])
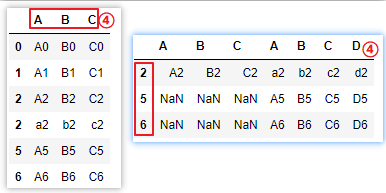
# ⑤ignore_index =True,丟棄原表索引,增加自然索引
pd.concat([df1,df2],ignore_index=True)
pd.concat([df1,df2],ignore_index=True,axis=1)
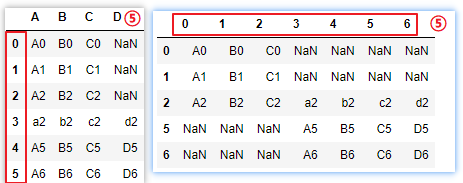
# ⑥keys = ['df1','df2'],names=['來源表','列號'],在最外層添加一層索引,便于區分合并后的資料是哪個原表
pd.concat([df1,df2],keys=['df1','df2'])
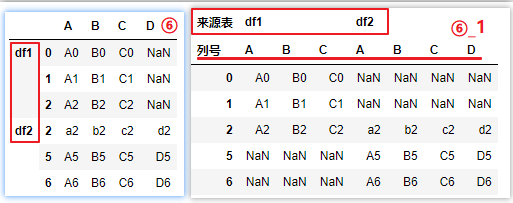
# ⑥_1
pd.concat([df1,df2],keys=['df1','df2'],axis=1,names=['來源表','列號'])
2 pd.merge() 連接資料
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False,
suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
功能說明:
??具有全功能、高性能的記憶體連接操作,與 SQL 的方式很類似,只能用于兩個表的拼接,通過引數名稱也能看出連接方向是左右拼接,一個左表一個右表,而且引數中沒有指定拼接軸的引數axis,不能用于表的上下拼接,
引數說明:
- left/right:參與合并的左側/右側DataFrame;
- how:連接方式:inner、outer、left、right,默認為inner;
- on:用于連接單個列名或組合列名['key1', 'key2'],必須同時存在左右兩個DataFrame中,未顯示指定且其他連接鍵也未指定,默認以左右兩個表的共同列(組合列)作為連接鍵,建議顯示指定;
- left_on/right_on:指定左右側DataFrame的連接鍵;
- left_index/right_index:將左側/右側DataFrame的行索引作為連接鍵;
- sort:根據連接鍵對合并后的資料進行排序,禁用處理大資料獲得更好的性能;
- suffixes:字串元組,追加到重復列名的末尾,默認為('_x', '_y');
- copy:
- validate:檢查重復鍵
- indicator:連接指示
①單個鍵鏈接:
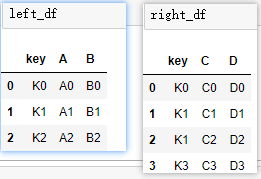
# ①最簡單連接:默認內連接,未指定連接鍵,取公共列作為連接鍵
pd.merge(left_df,right_df)
# 等價,建議顯示指定
pd.merge(left_df,right_df,on='key')
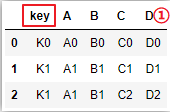
②多個鍵鏈接:
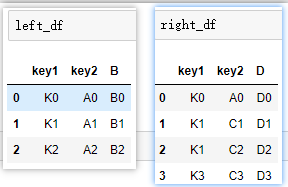
# 不顯示指定連接鍵,默認會以['key1','key2']作為鏈接鍵
pd.merge(left_df,right_df)
# 等價于(所以建議顯示指定)
pd.merge(left_df,right_df,on=['key1','key2'])
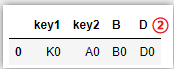
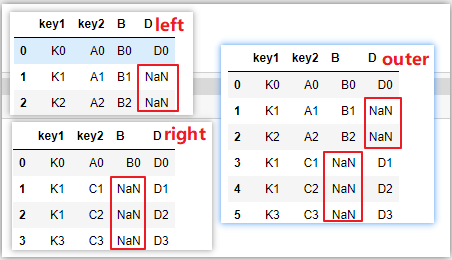
# how='left',以左表為基表,右表無匹配為NaN
pd.merge(left_df,right_df,how='left',on=['key1','key2'])
# how='right',以右表為基表,左表無匹配為NaN
pd.merge(left_df,right_df,how='right',on=['key1','key2'])
# how=‘outer’,外連接,取交集
# 等價于左連接和右連接的并集(疊加)
pd.merge(left_df,right_df,how='outer',on=['key1','key2'])
③欄位不相同指定連接鍵:
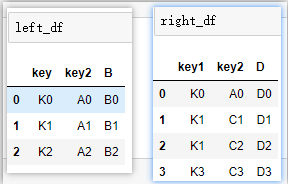
# left_on,right_on指定鏈接鍵,重復列會被標記區分
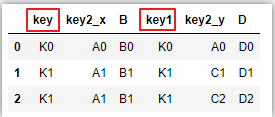
pd.merge(left_df,right_df,left_on='key',right_on='key1')
3 df.join()
4 df.append()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/285587.html
標籤:Python