??大家好,我是陳哈哈,北漂五年,認識我的朋友們知道,我是非科班出身,半路出家,大學也很差!這種背景來北漂,你都不知道你會經歷什么🙃🙃,
??不敢茍同,相信大家和我一樣,都有一個大廠夢,作為一名資深Java選手,深知面試重要性,接下來我準備用100天時間,基于Java崗面試中的高頻面試題,以每日3題的形式,帶你過一遍熱門面試題及恰如其分的解答,當然,我不會太深入,因為我怕記不住!!
??因此,不足的地方希望各位在評論區補充疑惑、見解以及面試中遇到的奇葩問法,希望這100天能夠讓我們有質的飛越,一起沖進大廠!!,讓我們一起學(juan)起來!!!

車票
- 面試題1:你對資料庫優化有哪些了解呀?
- 正經回答:
- 深入追問:
- 追問1:那你對SQL優化方面有哪些技巧呢?
- 追問2:嗯,那你說一下為什么不建議用SELECT * 呢?
- 面試題2:你對分庫分表是怎么看的呀?
- 正經回答:
- 深入追問:
- 追問1:毫無意義,我真的不想問他MySQL問題了🙃🙃
- 面試題3:MySQL洗掉資料的方式都有哪些?
- 正經回答:
- 深入追問:
- 追問1:說一下 delete、truncate、drop的區別吧
- 每日小結
??本欄目Java開發崗高頻面試題主要出自以下各技術堆疊:Java基礎知識、集合容器、并發編程、JVM、Spring全家桶、MyBatis等ORMapping框架、MySQL資料庫、Redis快取、RabbitMQ訊息佇列、Linux操作技巧等,
??終于到了期待已久的MySQL系列,太舒服了,還是個陽光明媚的周五~~~COOL!
??寫在前面,群里同學常提:資料庫這方面,面試一般怎么問呢?
??我們雖不是大公司,但面試過很多朋友,我們一般從sql優化起頭,基于回答內容,深入原理,然后往索引、事務上找,曾經實際優化的事兒,底子好的,一般兩個點以后就不在問啦~
??至于為啥不再問,是因為問太多毫無意義!!,看完本文你就會有所體會,
面試題1:你對資料庫優化有哪些了解呀?
正經回答:
??在高并發環境下,資料庫是最敏感的地方,nginx負載均衡、Server集群、MQ訊息佇列、Redis快取集群、資料庫主從集群所作的一切都是為了減輕資料庫訪問壓力,但是!前提是要有健壯的資料庫和底層代碼,這樣才能使前期準備不再是花架子,
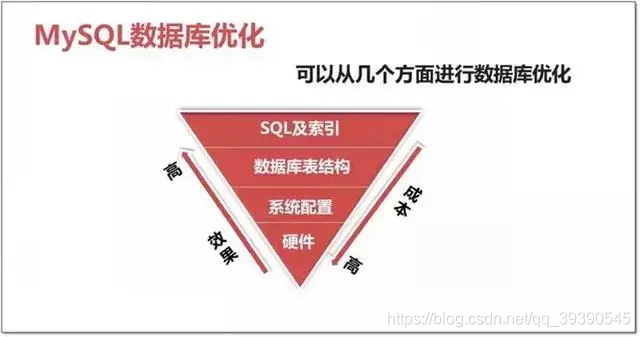
性價比如上圖,我們針對資料庫的優化優先級大致如下:
- 高:從SQL優化、索引優化入手,優化慢SQL、利用好索引,是重中之重;
- 中:SQL優化之后,是對資料表結構設計、橫縱分表分庫,對資料量級的處理;
- 低:通過修改資料庫系統配置,最大化里用服務器記憶體等資源;
- 低:通過以上方式還不行,那就是服務器資源瓶頸了,加機器,
優化成本:硬體 > 系統配置 > 資料庫表結構 > SQL及索引,
優化效果:硬體 < 系統配置 < 資料庫表結構 < SQL及索引,
深入追問:
追問1:那你對SQL優化方面有哪些技巧呢?
簡單說對于SQL優化,就三點:
- 最大化利用索引;
- 盡可能避免全表掃描;
- 減少無效資料的查詢;
首先要清楚SELECT陳述句 - 執行順序:
FROM
<表名> # 選取表,將多個表資料通過笛卡爾積變成一個表,
ON
<篩選條件> # 對笛卡爾積的虛表進行篩選
JOIN<join, left join, right join…>
<join表> # 指定join,用于添加資料到on之后的虛表中,例如left join會將左表的剩余資料添加到虛表中
WHERE
<where條件> # 對上述虛表進行篩選
GROUP BY
<分組條件> # 分組
<SUM()等聚合函式> # 用于having子句進行判斷,在書寫上這類聚合函式是寫在having判斷里面的
HAVING
<分組篩選> # 對分組后的結果進行聚合篩選
SELECT
<回傳資料串列> # 回傳的單列必須在group by子句中,聚合函式除外
DISTINCT
#資料除重
ORDER BY
<排序條件> # 排序
LIMIT
<行數限制>
SQL優化策略:
宣告:以下SQL優化策略適用于資料量較大的場景下,如果資料量較小,沒必要以此為準,以免畫蛇添足,
一、避免不走索引的場景
- 盡量避免在欄位開頭模糊查詢,會導致資料庫引擎放棄索引進行全表掃描,如下:
SELECT * FROM t WHERE username LIKE '%陳%'
??優化方式:盡量在欄位后面使用模糊查詢,如下:(原因涉及B+Tree索引最左前綴原則,可以參考《MySQL最左匹配原則,道兒上兄弟都得知道的原則》)
SELECT * FROM t WHERE username LIKE '陳%'
如果需求是要在前面使用模糊查詢,
- 使用MySQL內置函式INSTR(str,substr) 來匹配,作用類似于java中的indexOf(),查詢字串出現的角標位置,可參閱《MySQL模糊查詢用法大全(正則、通配符、內置函式等)》
- 使用FullText全文索引,用match against 檢索
- 資料量較大的情況,建議參考ElasticSearch、solr,億級資料量檢索速度秒級
- 當表資料量較少(幾千條兒那種),別整花里胡哨的,直接用like ‘%xx%’,
- 盡量避免使用 or,會導致資料庫引擎放棄索引進行全表掃描,如下:
SELECT * FROM t WHERE id = 1 OR id = 3
優化方式:可以用union代替or,如下:
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3
- 盡量避免進行null值的判斷,會導致資料庫引擎放棄索引進行全表掃描,如下:
SELECT * FROM t WHERE score IS NULL
優化方式:可以給欄位添加默認值0,對0值進行判斷,如下:
SELECT * FROM t WHERE score = 0
??這里說明了欄位設為not null的重要性,詳細請參考之前博文《領導含淚叮囑我:MySQL 建表欄位記得用 not null,不然就收拾包袱滾蛋》
- 盡量避免在where條件中等號的左側進行運算式、函式操作,會導致資料庫引擎放棄索引進行全表掃描,
可以將運算式、函式操作移動到等號右側,如下:
-- 全表掃描
SELECT * FROM T WHERE score/10 = 9
-- 走索引
SELECT * FROM T WHERE score = 10*9
- 當資料量大時,避免使用where 1=1的條件,通常為了方便拼裝查詢條件,我們會默認使用該條件,資料庫引擎會放棄索引進行全表掃描,如下:
SELECT username, age, sex FROM T WHERE 1=1
優化方式:用代碼拼裝sql時進行判斷,沒 where 條件就去掉 where,有where條件就加 and,
- 查詢條件不要用 <> 或者 !=
??使用索引列作為條件進行查詢時,需要避免使用<>或者!=等判斷條件,如確實業務需要,使用到不等于符號,需要在重新評估索引建立,避免在此欄位上建立索引,改由查詢條件中其他索引欄位代替,
- where條件僅包含復合索引非前置列
??如下:復合(聯合)索引包含key_part1,key_part2,key_part3三列,但SQL陳述句沒有包含索引前置列"key_part1",按照MySQL聯合索引的最左匹配原則,不會走聯合索引,,
select col1 from table where key_part2=1 and key_part3=2
了解其原理的同學可以參考《MySQL最左匹配原則,道兒上兄弟都得知道的原則》
- 隱式型別轉換造成不使用索引
??如下SQL陳述句由于索引對列型別為varchar,但給定的值為數值,涉及隱式型別轉換,造成不能正確走索引,
select col1 from table where col_varchar=123;
了解其原理的同學可以參考《令人炸毛兒的MySQL隱式轉換 - 無形之刃,最為致命》
- order by 條件要與where中條件一致,否則order by不會利用索引進行排序
-- 不走age索引
SELECT * FROM t order by age;
-- 走age索引
SELECT * FROM t where age > 0 order by age;
對于上面的陳述句,資料庫的處理順序是:
- 第一步:根據where條件和統計資訊生成執行計劃,得到資料,
- 第二步:將得到的資料排序,當執行處理資料(order by)時,資料庫會先查看第一步的執行計劃,看order by 的欄位是否在執行計劃中利用了索引,如果是,則可以利用索引順序而直接取得已經排好序的資料,如果不是,則重新進行排序操作,
- 第三步:回傳排序后的資料,
??當order by 中的欄位出現在where條件中時,才會利用索引而不再二次排序,更準確的說,order by 中的欄位在執行計劃中利用了索引時,不用排序操作,
??這個結論不僅對order by有效,對其他需要排序的操作也有效,比如group by 、union 、distinct等,

二、SELECT陳述句的一些其他優化
避免出現select *
??首先,select * 操作在任何型別資料庫中都不是一個好的SQL撰寫習慣,
??使用select * 取出全部列,會讓優化器無法完成索引覆寫掃描這類優化,會影響優化器對執行計劃的選擇,也會增加網路帶寬消耗,更會帶來額外的I/O,記憶體和CPU消耗,
??建議提出業務實際需要的列數,將指定列名以取代select *,
具體詳情見《為什么大家都說SELECT * 效率低》
避免出現不確定結果的函式
??特定針對主從復制這類業務場景,由于原理上從庫復制的是主庫執行的陳述句,使用如now()、rand()、sysdate()、current_user()等不確定結果的函式很容易導致主庫與從庫相應的資料不一致,另外不確定值的函式,產生的SQL陳述句無法利用query cache,
多表關聯查詢時,小表在前,大表在后
??在MySQL中,執行 from 后的表關聯查詢是從左往右執行的(Oracle相反),第一張表會涉及到全表掃描,所以將小表放在前面,先掃小表,掃描快效率較高,在掃描后面的大表,或許只掃描大表的前100行就符合回傳條件并return了,
??例如:表1有50條資料,表2有30億條資料;如果全表掃描表2,你品,那就先去吃個飯再說吧是吧,

使用表的別名
??當在SQL陳述句中連接多個表時,請使用表的別名并把別名前綴于每個列名上,這樣就可以減少決議的時間并減少哪些友列名歧義引起的語法錯誤,
用where字句替換HAVING字句
??避免使用HAVING字句,因為HAVING只會在檢索出所有記錄之后才對結果集進行過濾,而where則是在聚合前刷選記錄,如果能通過where字句限制記錄的數目,那就能減少這方面的開銷,HAVING中的條件一般用于聚合函式的過濾,除此之外,應該將條件寫在where字句中,
- where和having的區別:where后面不能使用組函式
調整Where字句中的連接順序
??MySQL采用從左往右,自上而下的順序決議where子句,根據這個原理,應將過濾資料多的條件往前放,最快速度縮小結果集,對了,聽說5.7版的語法決議器已經實作了where后條件的自動調節作業,查詢條件很多的場景,建議不要做這種嘗試,
追問2:嗯,那你說一下為什么不建議用SELECT * 呢?
??在阿里代碼規范中的《阿里java開發手冊(泰山版)》(提取碼:hb6i)MySQL 部分描述宣告:
4 - 1.
【強制】在表查詢中,一律不要使用 * 作為查詢的欄位串列,需要哪些欄位必須明確寫出,
- 增加查詢分析器決議成本,
- 增減欄位容易與 resultMap 配置不一致,
- 無用欄位增加網路 消耗,尤其是 text 型別的欄位,
1. 不需要的列會增加資料傳輸時間和網路開銷
??用“SELECT * ”資料庫需要決議更多的物件、欄位、權限、屬性等相關內容,在 SQL 陳述句復雜,硬決議較多的情況下,會對資料庫造成沉重的負擔,
??增大網路開銷;* 有時會誤帶上如log、IconMD5之類的無用且大文本欄位,資料傳輸size會幾何增漲,如果DB和應用程式不在同一臺機器,這種開銷非常明顯,
??即使 mysql 服務器和客戶端是在同一臺機器上,使用的協議還是 tcp,通信也是需要額外的時間,
2. 對于無用的大欄位,如 varchar、blob、text,會增加 io 操作
??準確來說,長度超過 728 位元組的時候,會先把超出的資料序列化到另外一個地方,因此讀取這條記錄會增加一次 io 操作,(MySQL InnoDB)
3. 失去MySQL優化器“覆寫索引”策略優化的可能性
??SELECT * 杜絕了覆寫索引的可能性,而基于MySQL優化器的“覆寫索引”策略又是速度極快,效率極高,業界極為推薦的查詢優化方式,

課間休息,《垂釣者1》 坐標:北京 元大都遺址,😂
面試題2:你對分庫分表是怎么看的呀?
正經回答:
- 分庫:由單個資料庫實體拆分成多個資料庫實體,將資料分布到多個資料庫實體中,
- 分表:由單張表拆分成多張表,將資料劃分到多張表內,
??要知道,對于大型互聯網專案,資料量級可能不是我們能想到的,每日新增資料量過千萬是常有的事兒,想靠單臺MySQL服務器是不現實的,你項羽在牛B,也頂不住四個隊友掛機啊!!項羽:???

??隨著業務資料量和網站QPS日益增高,對資料庫壓力也越來越大,單機版資料庫很快會到達存盤和并發瓶頸,就需要做資料庫性能方面的優化,分庫分表采取的是分而治之的策略,分庫目的是減輕單臺MySQL實體存盤壓力及可擴展性,而分表是解決單張表資料過大以后查詢的瓶頸問題,坦白說,這些問題也是所有關系型資料庫的“硬傷”,
常用策略包括:
垂直分表、水平分表、垂直分庫、水平分庫,
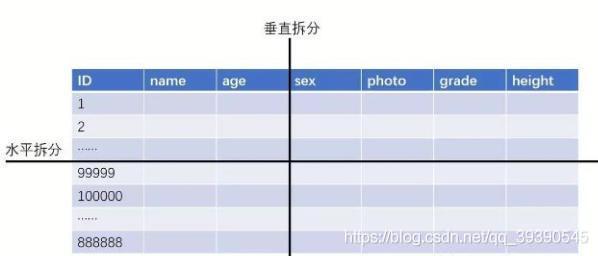
1、垂直分表
??垂直分表,或者叫豎著切表,是不是感受到該策略是以欄位為依據的!主要按照欄位的活躍性、欄位長度,將表中欄位拆分到不同的表(主表和擴展表)中,
特點:
- 每個表的結構都不一樣;
- 每個表的資料也不一樣,
- 有一個關聯欄位,一般是主鍵或外鍵,用于關聯
兄弟表資料; - 所有兄弟表的并集是該表的全量資料;
場景:
有幾個欄位屬于熱點欄位,更新頻率很高,要把這些欄位單獨切到一張表里,不然innodb行鎖很惡心的,鎖死你呀~~如用戶表里的余額欄位?不,我的余額就很穩定,一直是0,,有大欄位,如text,存盤壓力很大,畢竟innodb資料和索引是同一個檔案;同時,我又喜歡用SELECT *,你懂得,這磁盤IO消耗的,跟玩兒似的,誰都扛不住的,有明顯的業務區分,或表結構設計時欄位冗余;有些小伙伴看到第一點時,就發現陳哈哈是個菜雞,用戶表怎么會有余額欄位?明顯有問題啊!趕緊先到評論區噴陳哈哈一波~~然后笑嘻嘻的發現原來是個小尾巴,真不要臉是吧,,是的,因此不同業務我們要把具體欄位拆開,這樣才有利于業務后續擴展哦,
2、水平分表
??水平分表,也叫“橫著切”,,以行資料為依據進行切分,一般按照某列的自容進行切分,
??如手機號表,我們可以通過前兩位或前三位進行切分,如131、132、133 → phone_131、phone_132、phone_133,手機號有11位(100億),量大是很正常的事兒,這年頭誰家老頭老太太每個手機呢是吧,這樣切就把一張大表切成了好幾十張小表,資料量不就下來了,有同學就問了那我怎么知道我這手機號查哪個表呢?一看你就沒認真看前兩行標紅的點,為啥標紅嘞?比如我查13100001111,那我截取前三位,動態拼接到查詢的表名上,就行了,
特點:
- 每個表的結構都一樣;
- 每個表的資料都不一樣,沒有交集;
- 所有表的并集是該表的全量資料;
場景:單表的資料量過大或增長速度很快,已經影響或即將會影響SQL查詢效率,加重了CPU負擔,提前到達瓶頸,記得水平分表越早越好,別問我為什么,,
??你要有興趣試一試,就關注我,讓csdn研發同學給我的粉絲們分個表哈哈,,算了,別做夢了,忘了你是個菜狗了么~

花里胡哨的 - 分庫
??需要你注意的是,傳統的分庫和我們熟悉的集群、主從復制可不是一個事兒;多節點集群是將一個庫復制成N個庫,從而通過讀寫分離實作多個MySQL服務的負載均衡,實際是圍繞一個庫來搞的,這個庫稱為Master主庫,而分庫就不同了,分庫是將這個主庫一分為N,比如一分為二,然后針對這兩個主庫,再配置2N個從庫節點,
3、垂直分庫
??縱向切庫,太經典的切分方式,基于表進行切分,通常是把新的業務模塊或集成公共模塊拆分出去,比如我們最熟悉的單點登錄、鑒權模塊,熟悉的味道,記得有一次我把一些沒用的表切到一個性能很好的服務器中,這服務器我專門用來學習,后來也不知被哪個狗腿子告密了~ 我**你個**,有種站出來,你個**東西😅😅,
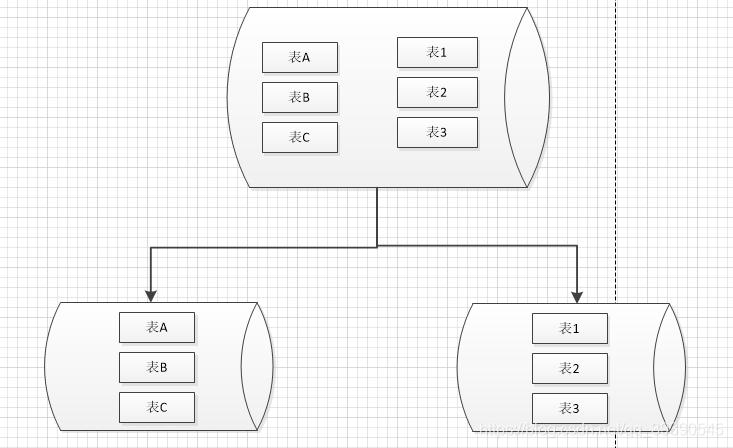
特點:
- 每個庫的表都不一樣;
- 表不一樣,資料就更不一樣了~ 沒有任何交集;
- 每個庫相對獨立,模塊化
場景:可以抽象出單獨的業務模塊時,可以抽象出公共區時(如字典、公共時間、公共配置等),或者想有一臺屬于自己的服務器時?
4、水平分庫
??以行資料為依據,將一個庫中的資料拆分到多個庫中,大型分表體驗一下?坦白說這種策略并不實用,因為會對后臺開發很不友好,有很多坑,不建議采用,理解即可,
特點:
- 每個庫的結構都一樣;
- 每個庫的資料都不一樣,沒有交集;
- 所有庫的并集是全量資料;
場景:系統絕對并發量上來了,CPU記憶體壓力大,分表難以根本上解決量的問題,并且還沒有明顯的業務歸屬來垂直分庫,主庫磁盤接近飽和,
??其實,在實際作業中,我們在選擇分庫分表策略前,想到的應該是從快取、讀寫分離、SQL優化等方面,因為這些能夠更直接、代價更小的解決問題,要記住動表就是動根本,你永遠不知道這張表后面會連帶多少歷史遺留問題,如果是個很大型的專案,遇到些問題你就跟經理提議要分庫分表,小心被呼死~
深入追問:
追問1:毫無意義,我真的不想問他MySQL問題了🙃🙃

課間休息,《垂釣者2》 坐標:北京 亮馬河,😂😂
面試題3:MySQL洗掉資料的方式都有哪些?
正經回答:
??咱們常用的三種洗掉方式:通過 delete、truncate、drop 關鍵字進行洗掉;這三種都可以用來洗掉資料,但用于的場景不同,
深入追問:
追問1:說一下 delete、truncate、drop的區別吧
一、從執行速度上來說
drop > truncate >> DELETE
二、從原理上講
- DELETE
DELETE from TABLE_NAME where xxx
-
DELETE屬于資料庫DML操作語言,只洗掉資料不洗掉表的結構,會走事務,執行時會觸發trigger;
-
在 InnoDB 中,DELETE其實并不會真的把資料洗掉,mysql 實際上只是給洗掉的資料打了個標記為已洗掉,因此 delete 洗掉表中的資料時,表檔案在磁盤上所占空間不會變小,存盤空間不會被釋放,只是把洗掉的資料行設定為不可見,雖然未釋放磁盤空間,但是下次插入資料的時候,仍然可以重用這部分空間(重用 → 覆寫),
-
DELETE執行時,會先將所洗掉資料快取到rollback segement中,事務commit之后生效;
-
delete from table_name洗掉表的全部資料,對于MyISAM 會立刻釋放磁盤空間,InnoDB 不會釋放磁盤空間;
-
對于delete from table_name where xxx 帶條件的洗掉, 不管是InnoDB還是MyISAM都不會釋放磁盤空間;
-
delete操作以后使用
optimize table table_name會立刻釋放磁盤空間,不管是InnoDB還是MyISAM ,所以要想達到釋放磁盤空間的目的,delete以后執行optimize table 操作, -
delete 操作是一行一行執行洗掉的,并且同時將該行的的洗掉操作日志記錄在redo和undo表空間中以便進行回滾(rollback)和重做操作,生成的大量日志也會占用磁盤空間,
- truncate
Truncate table TABLE_NAME
-
truncate:屬于資料庫DDL定義語言,不走事務,原資料不放到 rollback segment 中,操作不觸發 trigger,
執行后立即生效,無法找回
執行后立即生效,無法找回
執行后立即生效,無法找回 -
truncate table table_name 立刻釋放磁盤空間 ,不管是 InnoDB和MyISAM ,truncate table其實有點類似于drop table 然后creat,只不過這個create table 的程序做了優化,比如表結構檔案之前已經有了等等,所以速度上應該是接近drop table的速度;
-
truncate能夠快速清空一個表,并且重置auto_increment的值,
但對于不同的型別存盤引擎需要注意的地方是:
- 對于MyISAM,truncate會重置auto_increment(自增序列)的值為1,而
delete后表仍然保持auto_increment,- 對于InnoDB,truncate會重置auto_increment的值為1,delete后表仍然保持auto_increment,但是
在做delete整個表之后重啟MySQL的話,則重啟后的auto_increment會被置為1,
??也就是說,InnoDB的表本身是無法持久保存auto_increment,delete表之后auto_increment仍然保存在記憶體,但是重啟后就丟失了,只能從1開始,實質上重啟后的auto_increment會從 SELECT 1+MAX(ai_col) FROM t 開始,
- 小心使用 truncate,尤其沒有備份的時候,如果誤洗掉線上的表,記得及時聯系中國民航,訂票電話:
400-806-9553
- drop
Drop table Tablename
-
drop:屬于資料庫DDL定義語言,同Truncate;
執行后立即生效,無法找回
執行后立即生效,無法找回
執行后立即生效,無法找回 -
drop table table_name 立刻釋放磁盤空間 ,不管是 InnoDB 和 MyISAM; drop 陳述句將洗掉表的結構被依賴的約束(constrain)、觸發器(trigger)、索引(index); 依賴于該表的存盤程序/函式將保留,但是變為 invalid 狀態,
-
小心使用 drop ,要刪表跑路的兄弟,請在訂票成功后在執行操作!訂票電話:400-806-9553
??可以這么理解,一本書,delete是把目錄撕了,truncate是把書的內容撕下來燒了,drop是把書燒了

每日小結
??今天我們復習了面試中常考的MySQL類的三個問題,你做到心中有數了么?對了,如果你的朋友也在準備面試,請將這個系列扔給他,如果他認真對待,肯定會感謝你的!!好了,今天就到這里,學廢了的同學,記得在評論區留言:打卡,,給同學們以激勵,
MySQL系列文章匯總與《MySQL江湖路 | 專欄目錄》
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286274.html
標籤:java