神經網路之手寫數字
文章目錄
- 神經網路之手寫數字
- 00. 寫在之前
- 01. 代碼框架
- 02. 開始做一些準備作業
- 03. 框架的開始
- 04. 訓練模型構建
- 05. 手寫數字的識別
- 06. 想看原始碼的同學戳這里
- 07. 思考
首先鼓掌,又是一個有識訓的五一小假期,想前年五一出門旅游,去年五一疫情在家寫了爬蟲【就是我博客里的那個口袋妖怪】,這個五一就寫了一個神經網路,
代碼參考學習于 python神經網路編程這本書,實話實說,這本書看了好幾次,之前打算寫來著,但不知道為什么總是不敢輕易嘗試,今天把五一的任務的任務都完成了,早上就想給自己找點事兒干,于是就又把這本書翻出來了,打算正兒八經的寫一次,但是沒想到比我想象的簡單那么多,咳咳,,,為啥我感覺越寫越像寫朋友圈???
不廢話了,開始正文吧!
00. 寫在之前
首先是寫在之前的一些建議:
首先是關于這本書,我真的認為他是將神經網路里非常棒的一本書,但你也需要注意,如果你真的想自己動手去實作,那么你一定需要有一定的python基礎,并且還需要有一些python資料科學處理能力
然后希望大家在看這邊博客的時候對于神經網路已經有一些了解了,知道什么是輸入層,什么是輸出層,并且明白他們的一些理論,在這篇博客中我們僅僅是展開一下代碼;
然后介紹一下本篇博客的環境等:
語言:Python3.8.5
環境:jupyter
庫檔案: numpy | matplotlib | scipy
01. 代碼框架
我們即將設計一個神經網路物件,它可以幫我們去做資料的訓練,以及資料的預測,所以我們將具有以下的三個方法:
- 首先我們需要初始化這個函式,我們希望這個神經網路僅有三層,因為再多也不過是在隱藏層去做文章,所以先做一個簡單的,那么我們需要知道我們輸入層、隱藏層和輸出層的節點個數;
- 訓練函式,我們需要去做訓練,得到我們需要的權重,
- 通過我們已有的權重,將給定的輸入去做輸出,
02. 開始做一些準備作業
現在我們需要準備一下:
- 將我們需要的庫匯入
import numpy as np
import scipy.special as spe
import matplotlib.pyplot as plt
- 構建一個類
class neuralnetwork:
# 我們需要去初始化一個神經網路
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
pass
def train(self, inputs_list, targets_list):
pass
def query(self, inputs_list):
pass
- 我們的主函式
input_nodes = 784 # 輸入層的節點數
hidden_nodes = 88 # 隱藏層的節點數
output_nodes = 10 # 輸出層的節點數
learn_rate = 0.05 # 學習率
n = neuralnetwork(input_nodes, hidden_nodes, output_nodes, learn_rate)
- 匯入檔案
data_file = open("E:\sklearn_data\神經網路數字識別\mnist_train.csv", 'r')
data_list = data_file.readlines()
data_file.close()
file2 = open("E:\sklearn_data\神經網路數字識別\mnist_test.csv")
answer_data = file2.readlines()
file2.close()
這里需要介紹以下這個資料集,訓練集在這里,測驗集在這里
03. 框架的開始
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
self.inodes = inputnodes # 輸入層節點設定
self.hnodes = hiddennodes # 影藏層節點設定
self.onodes = outputnodes # 輸出層節點設定
self.lr = learningrate # 學習率設定,這里可以改進的
self.wih = (np.random.normal(0.0, pow(self.hnodes, -0.5),(self.hnodes, self.inodes))) # 這里是輸入層與隱藏層之間的連接
self.who = (np.random.normal(0.0, pow(self.onodes, -0.5),(self.onodes, self.hnodes))) # 這里是隱藏層與輸出層之間的連接
self.activation_function = lambda x: spe.expit(x) # 回傳sigmoid函式
Δ w j , k = α ? E k ? sigmoid ( O k ) ? ( 1 ? sigmoid ? ( O k ) ) ? O j ? \Delta w_{j, k}=\alpha * E_{k} * \text { sigmoid }\left(O_{k}\right) *\left(1-\operatorname{sigmoid}\left(O_{k}\right)\right) \cdot O_{j}^{\top} Δwj,k?=α?Ek?? sigmoid (Ok?)?(1?sigmoid(Ok?))?Oj??
def query(self, inputs_list):
inputs = np.array(inputs_list, ndmin=2).T # 輸入進來的二維影像資料
hidden_inputs = np.dot(self.wih, inputs) # 隱藏層計算,說白了就是線性代數中的矩陣的點積
hidden_outputs = self.activation_function(hidden_inputs) # 將隱藏層的輸出是經過sigmoid函式處理
final_inputs = np.dot(self.who, hidden_outputs) # 原理同hidden_inputs
final_outputs = self.activation_function(final_inputs) # 原理同hidden_outputs
return final_outputs # 最終的輸出結果就是我們預測的資料
這里我們對預測這一部分做一個簡單的解釋:我們之前的定義輸出的節點是10個,對應的是十個數字,
而為什么會通過神經網路能達到這個亞子,我推薦這本書深度學習的數學 這本書的理論講解非常不錯!!!
04. 訓練模型構建
之前的部分相對而言還是比較簡單的,那么接下來就是如何去構建訓練模型了,
def train(self, inputs_list, targets_list):
# 前期和識別程序是一樣的,說白了我們與要先看看現在的預測結果如何,只有根據這次的預期結果才能去修改之前的權重
inputs = np.array(inputs_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
# 接下來將標簽拿遲來
targets = np.array(targets_list, ndmin=2).T
# 得到我們的資料預測的誤差,這個誤差將是向前反饋的基礎
output_errors = targets - final_outputs
# 這部分是根據公式得到的反向傳播引數
hidden_errors = np.dot(self.who.T, output_errors)
# 根據我們的反饋引數去修改兩個權重
self.who += self.lr * np.dot((output_errors * final_outputs * ( 1.0-final_outputs)), np.transpose(hidden_outputs))
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0-hidden_outputs)), np.transpose(inputs))
如此我們的基礎神經網路構建完成了,
05. 手寫數字的識別
接下來神經網路是完成的,那么我們究竟該如何去將資料輸入呢?
csv檔案我們并不陌生【或許陌生?】,他是逗號分割檔案,顧名思義,它是通過逗號分隔的,所以我們可以打開看一下:
眼花繚亂!!
但是細心的我們可以發現他的第一個數字都是0~9,說明是我們的標簽,那么后面的應該就是影像了,通過了解我們知道這個后面的資料是一個28*28的影像,
all_value = data_list[0].split(',') # split分割成串列
image_array = np.asfarray(all_value[1:]).reshape((28,28)) # 將資料reshape成28*28的矩陣
plt.imshow(image_array, cmap='Greys', interpolation='None') # 展示一下
通過這段代碼,我們可以簡單的看一下每個數字是什么:
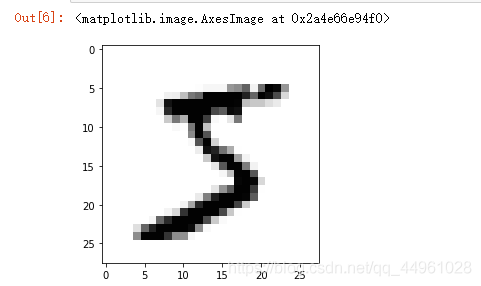
很好,知道這里就足夠了,那么我們接下來就是將這些資料傳入了!
我們在訓練的時候,需要將他們都轉化成數字串列,方便處理
data = [] # 用來保存訓練程序的資料
sum_count = 0 # 統計總識別的正確的個數
for i in range(15): # 訓練的輪數
count = 0 # 單次訓練識別正確的個數
for j in range(len(data_list)): # 對60000張圖片開始訓練, 沒有劃分資料集的程序主要是別人直接給了,我也懶得自己去做了,主要就是展示一下神經網路嘛~
target = np.zeros(10)+0.01 # 生成初始標簽集合,用來和結果對比
line_ = data_list[j].split(',') # 對每一行的資料處理切割
imagearray = np.asfarray(line_) # 將切割完成的資料轉換成數字串列
target[int(imagearray[0])] = 1.0 # 將正確答案挑出來
n.train(imagearray[1:]/255*0.99+0.01, target) # 丟入訓練,丟入的時候注意將資料轉換成0.01~1.0之間的結果
for line in answer_data: # 對10000組測驗集測驗
all_values = line.split(',')
answer = n.query((np.asfarray(all_values[1:])/255*0.99)+0.01)
if answer[int(all_values[0])] > 0.85: # 查看對應位置是否達到自定義的閾值?
count += 1
sum_count += count
string = "訓練進度 %05f\n本輪準確度 %05f\n總準確度 %05f\n\n"%(i/120,count/len(answer_data), sum_count/(len(answer_data)*(i+1)))
data.append([i/120,count/len(answer_data), sum_count/(len(answer_data)*(i+1))]) # 將資料保存方便生成訓練曲線
print(string)
```
接下來我們將結果圖片展示以下吧~
```python
data = np.array(data)
plt.plot(range(len(data)), data[:, 1:])
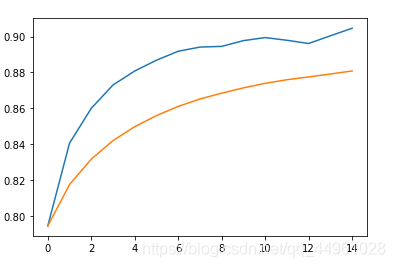
06. 想看原始碼的同學戳這里
把原始碼整理一下貼出來
import numpy as np
import scipy.special as spe
import matplotlib.pyplot as plt
class neuralnetwork:
# 我們需要去初始化一個神經網路
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
self.lr = learningrate
self.wih = (np.random.normal(0.0, pow(self.hnodes, -0.5),(self.hnodes, self.inodes)))
self.who = (np.random.normal(0.0, pow(self.onodes, -0.5),(self.onodes, self.hnodes)))
self.activation_function = lambda x: spe.expit(x) # 回傳sigmoid函式
def train(self, inputs_list, targets_list):
inputs = np.array(inputs_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
targets = np.array(targets_list, ndmin=2).T
output_errors = targets - final_outputs
hidden_errors = np.dot(self.who.T, output_errors)
self.who += self.lr * np.dot((output_errors * final_outputs * ( 1.0-final_outputs)), np.transpose(hidden_outputs))
self.wih += self.lr * np.dot((hidden_errors * hidden_outputs * (1.0-hidden_outputs)), np.transpose(inputs))
def query(self, inputs_list):
inputs = np.array(inputs_list, ndmin=2).T
hidden_inputs = np.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
return final_outputs
input_nodes = 784
hidden_nodes = 88
output_nodes = 10
learn_rate = 0.05
n = neuralnetwork(input_nodes, hidden_nodes, output_nodes, learn_rate)
data_file = open("E:\sklearn_data\神經網路數字識別\mnist_train.csv", 'r')
data_list = data_file.readlines()
data_file.close()
file2 = open("E:\sklearn_data\神經網路數字識別\mnist_test.csv")
answer_data = file2.readlines()
file2.close()
data = []
sum_count = 0
for i in range(15):
count = 0
for j in range(len(data_list)):
target = np.zeros(10)+0.01
line_ = data_list[j].split(',')
imagearray = np.asfarray(line_)
target[int(imagearray[0])] = 1.0
n.train(imagearray[1:]/255*0.99+0.01, target)
for line in answer_data:
all_values = line.split(',')
answer = n.query((np.asfarray(all_values[1:])/255*0.99)+0.01)
if answer[int(all_values[0])] > 0.85:
count += 1
sum_count += count
string = "訓練進度 %05f\n本輪準確度 %05f\n總準確度 %05f\n\n"%(i/120,count/len(answer_data), sum_count/(len(answer_data)*(i+1)))
data.append([i/120,count/len(answer_data), sum_count/(len(answer_data)*(i+1))])
print(string)
data = np.array(data)
plt.plot(range(len(data)), data[:, 1:])
可以說是相對簡單的一個程式,但卻是包含著神經網路最基礎的思想!值得好好康康~
07. 思考
- 如何識別其他手寫字體等?
我的想法:通過影像處理,將像素規定到相近大小【尺度放縮】
- 影像大小運行速度問題
我的想法:如何快速的矩陣運算,通過C語言是否可以加速?相較于darknet這個神經網路僅有三層,運算速度并不是十分理想,當然cuda編程對于GPU加速肯定是最好的選擇之一,
總結一下,真實學海無涯啊!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286308.html
標籤:python