文章目錄
- 1. 簡介
- 2. 開始行動
- 2.1 步驟
- 2.2 實作代碼
- 2.3 成果
- 2.4 成果分析
- 2.5 優化
- 2.6 代碼優化
- 2.7 成果
1. 簡介
使用的技術堆疊 : python3, re, BeautifulSoup
目標網站: https://www.umei.net/p/gaoqing/cn/
免責宣告:僅用于學習,請勿商用!!!!
2. 開始行動
2.1 步驟
- 獲取
html - 資料清洗(獲取圖片標簽)
- 獲取圖片標簽里面的
src - 發起請求并保存圖片
2.2 實作代碼
import requests
import re
from bs4 import BeautifulSoup
url = 'https://www.umei.net/p/gaoqing/cn/'
r = requests.get(url)
# with open('./meinv.html','wb+') as f:
# f.write(r.content)
if(r.status_code == 200 ):
imgs = []
soup = BeautifulSoup(r.content, 'html5lib')
img_list = soup.select('.TypeBigPics img ')
for i in img_list:
# print(i)
res = re.search('src="(.*?)"', str(i) , re.M | re.I)
imgs.append( str (res.group(1)) )
for i,k in enumerate (imgs):
# print(i,type(k))
ans = requests.get(k)
if (ans.status_code == 200):
with open(str (i) +'.jpg', 'wb+') as f:
f.write(ans.content)
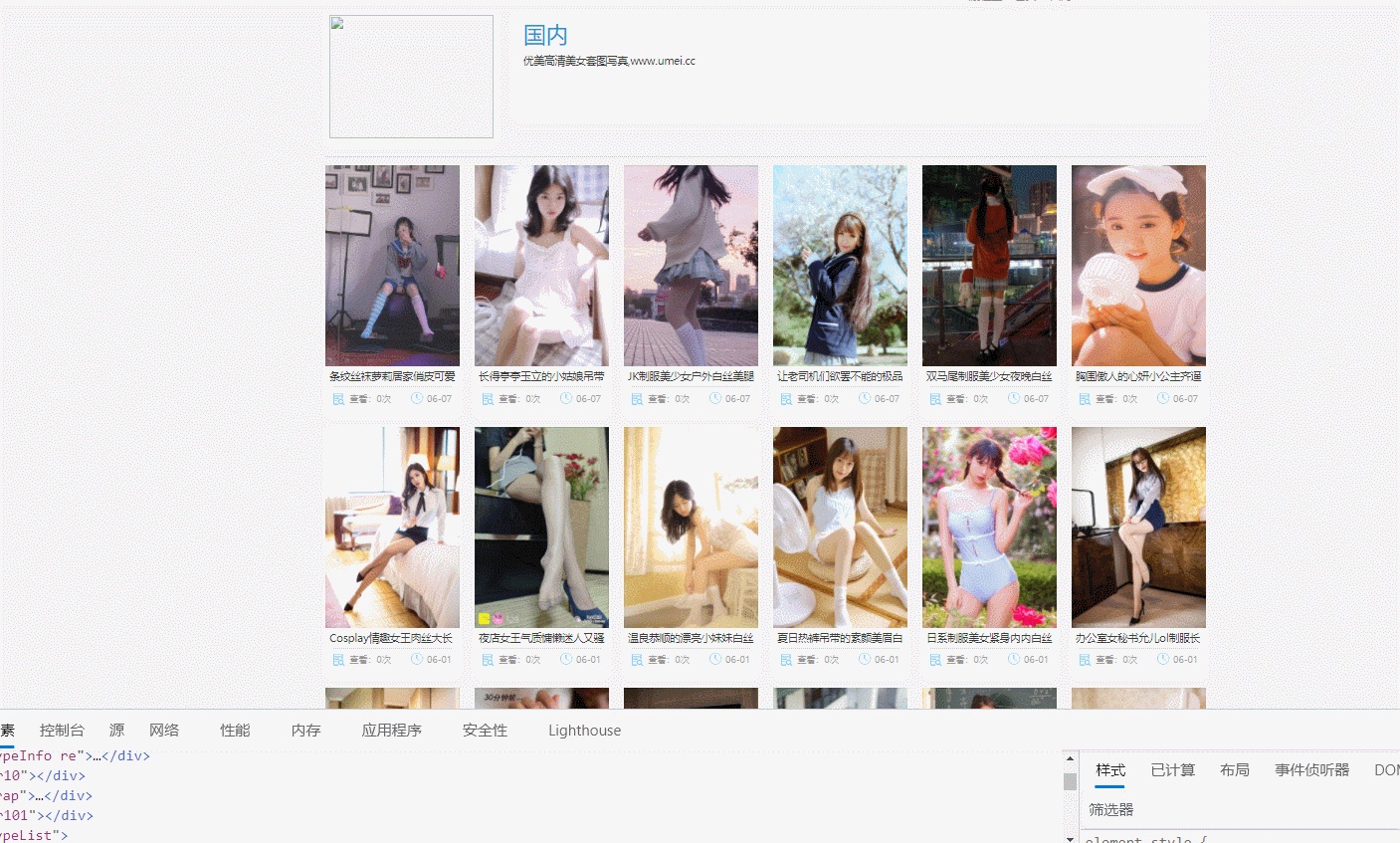
2.3 成果

2.4 成果分析
- 雖然成功拿到了圖片,但是圖片的清晰度不夠,可進一步優化
2.5 優化
- 優化分析
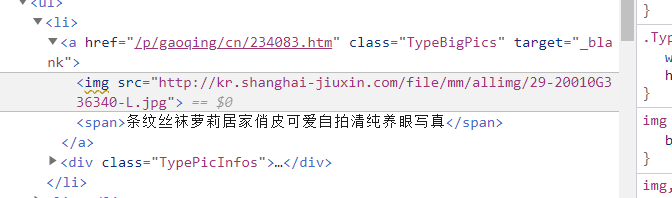
通過分析可知:我們可以通過點擊圖片外面的
a標簽獲取到圖片大圖
2.6 代碼優化
import requests
import re
from bs4 import BeautifulSoup
url = 'https://www.umei.net/p/gaoqing/cn/'
r = requests.get(url)
# with open('./meinv.html','wb+') as f:
# f.write(r.content)
if(r.status_code == 200 ):
imgs = []
soup = BeautifulSoup(r.content, 'html5lib')
# 獲取img外面的a標簽
aList = soup.select('.TypeBigPics')
for item in aList:
obj = re.search('.*?\/cn\/(.*?)".*', str(item), re.M | re.I )
imgs.append( str( obj.group(1)) )
ans_imgs = []
for i,k in enumerate(imgs):
# print(str(url + k))
ans = requests.get(str(url+k))
if(ans.status_code==200):
soup1 = BeautifulSoup(ans.content, 'html5lib')
imgBody = soup1.select('.ImageBody img')
# print(imgBody)
# 獲取大圖的src
obj = re.search('.*?src="(.*?)"', str(imgBody), re.M | re.I )
ans_imgs.append( obj.group(1))
# print(ans_imgs)
# 保存大圖
for i,k in enumerate(ans_imgs):
b = requests.get(str(k))
if(b.status_code==200):
with open('./'+str(i)+'.jpg','wb+') as f:
f.write(b.content)
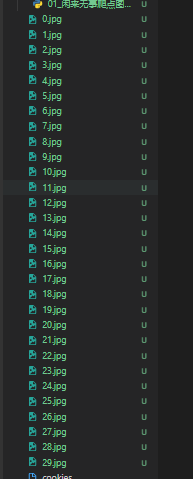
2.7 成果

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286602.html
標籤:python
上一篇:Pycharm基本操作