用python制作一款爬蟲軟體,爬取公眾號文章資訊,爬蟲之路,永無止境!!!
今天拿手機看公眾號里面的文章,不小心退出來,進去之后還得一頁一頁的翻,好麻煩,突發奇想,把資訊爬下來,想看哪個看哪個,,嘿嘿,來自程式員的快樂,
爬蟲操作演示
電腦卡,各位別見怪,,,
開發工具
python
pycharm
selenium
tkinter
xlwt
開發思路
首先start_url="https://mp.weixin.qq.com/"
掃碼注冊一下微信公眾平臺,有的話直接忽略,掃碼登錄即可,(注冊個人訂閱號就行)
利用selenium自動操作掃碼登錄獲得cookie值,之后回應要用cookie
要先下載webdriver插件
插件你下載對應谷歌瀏覽器的版本,下載之后會獲得chromedriver.exe,然后把這個chromedriver.exe放在python解釋器的python.exe檔案的同級目錄下就可以了
登錄進去界面為:
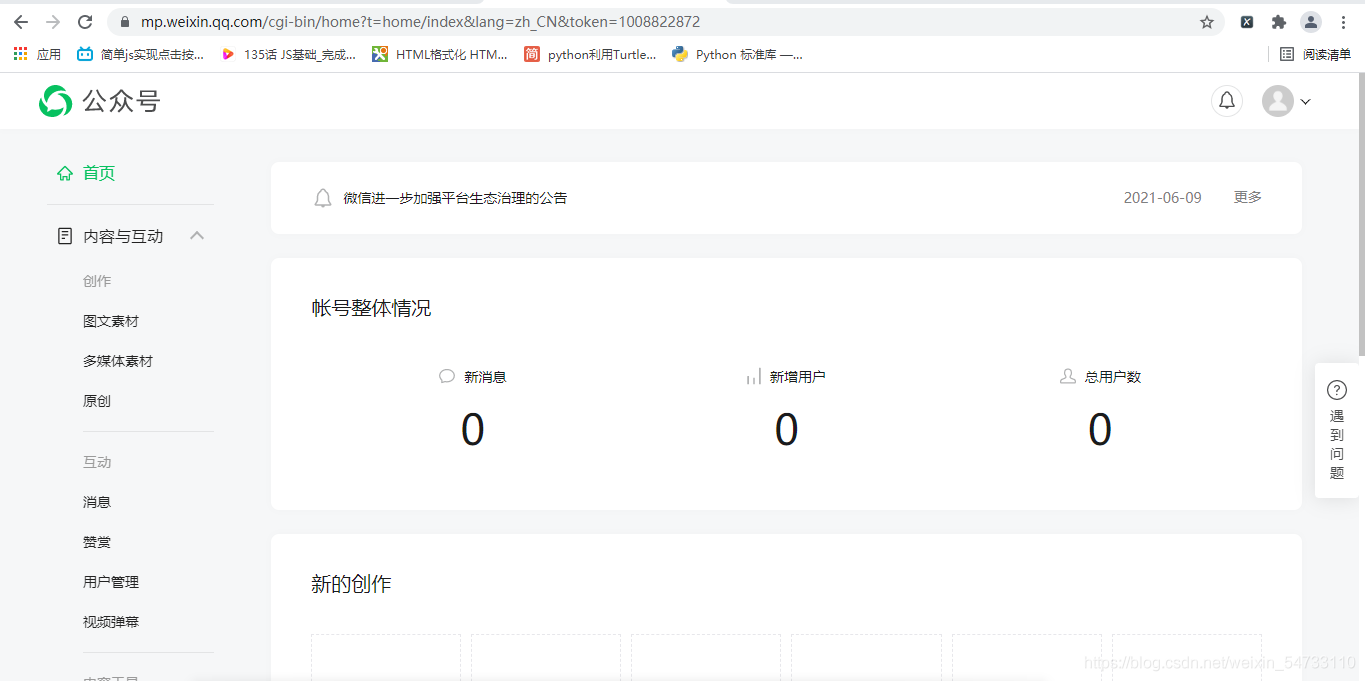
回應拿回網頁原始碼,拿回token值,token值是有時效性的

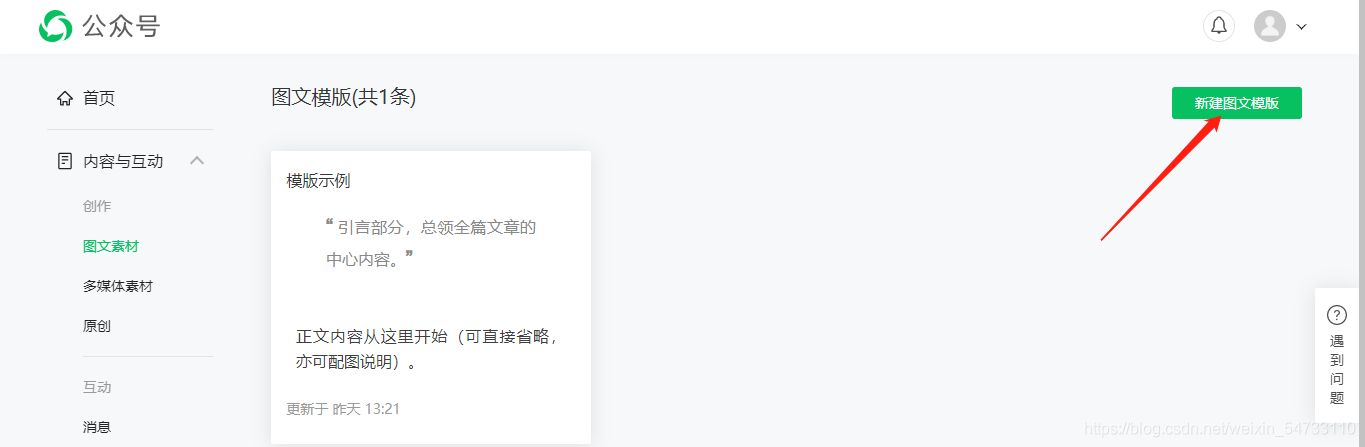
操作點開要搜索公眾號的位置
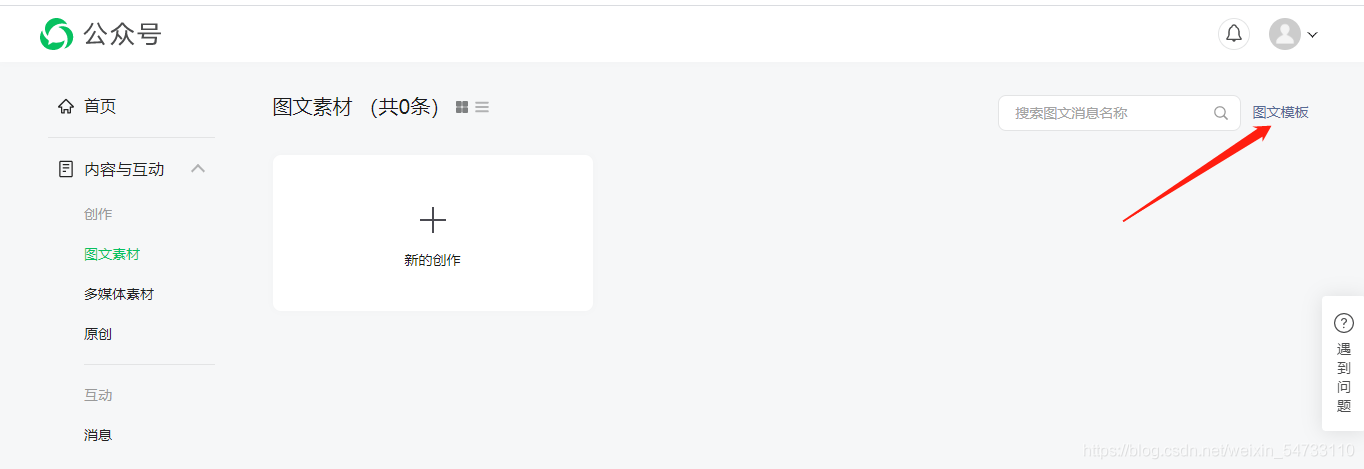
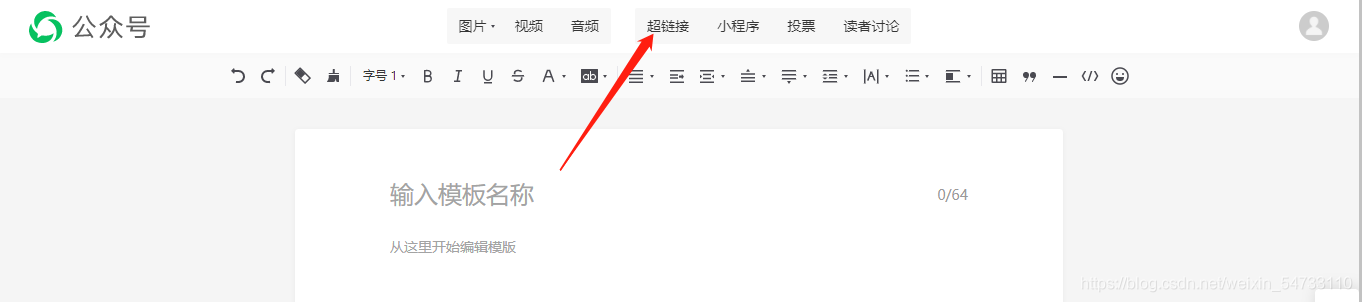
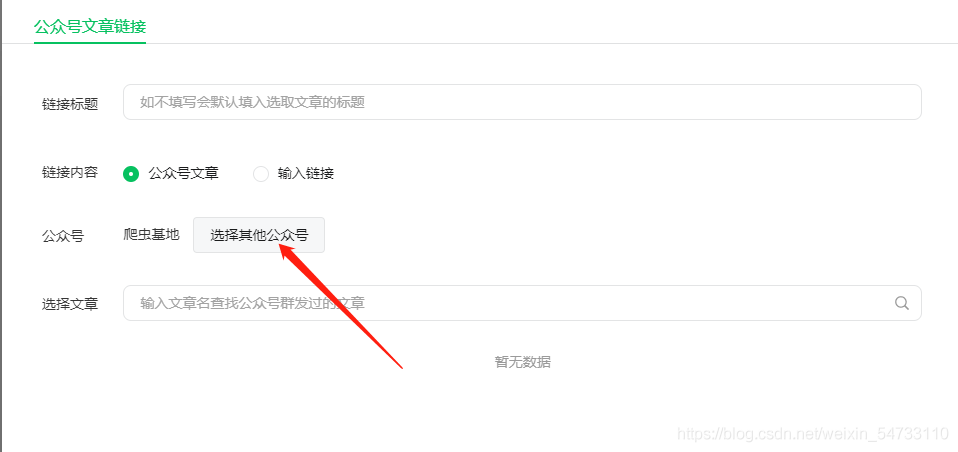
搜索想要爬取的公眾號名字
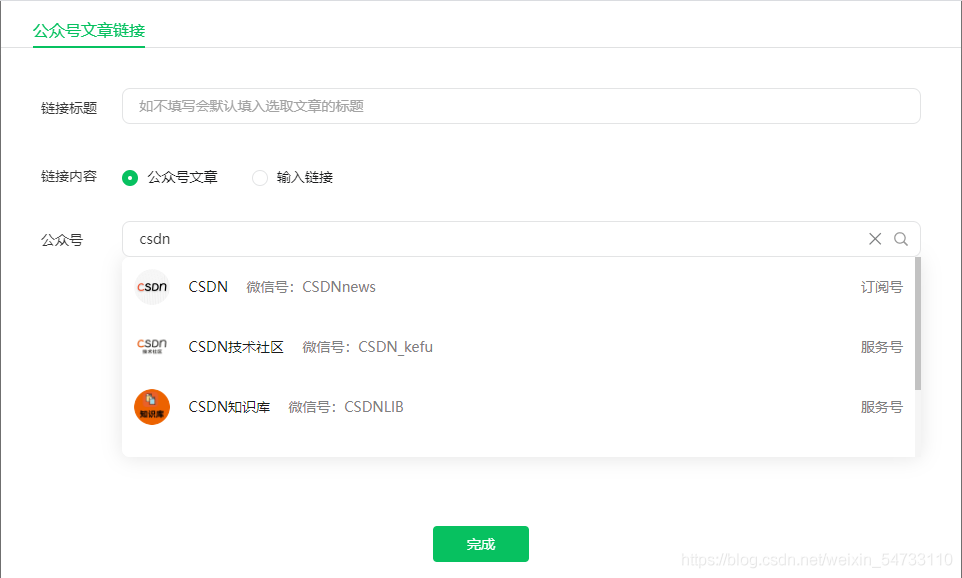
右擊打開檢查,拿回fakeid值,確定公眾號,具有唯一性
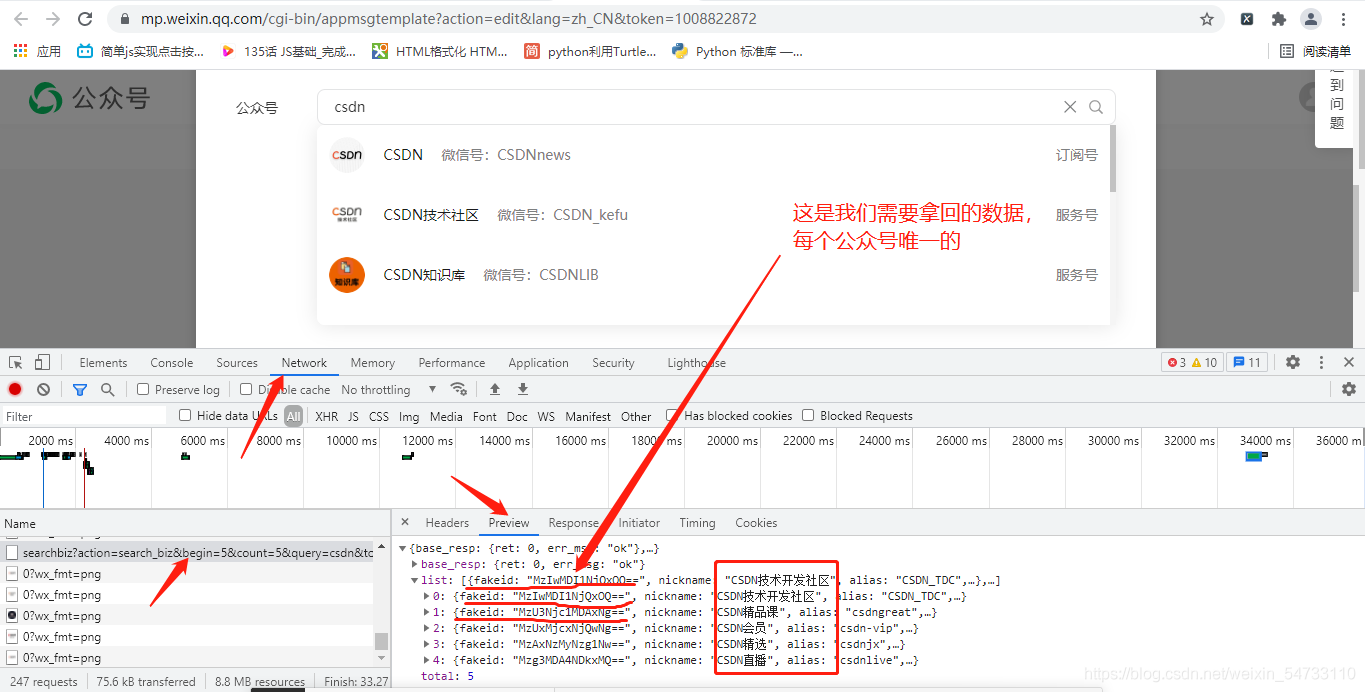
本文以CSDN為例,爬取公眾號的文章
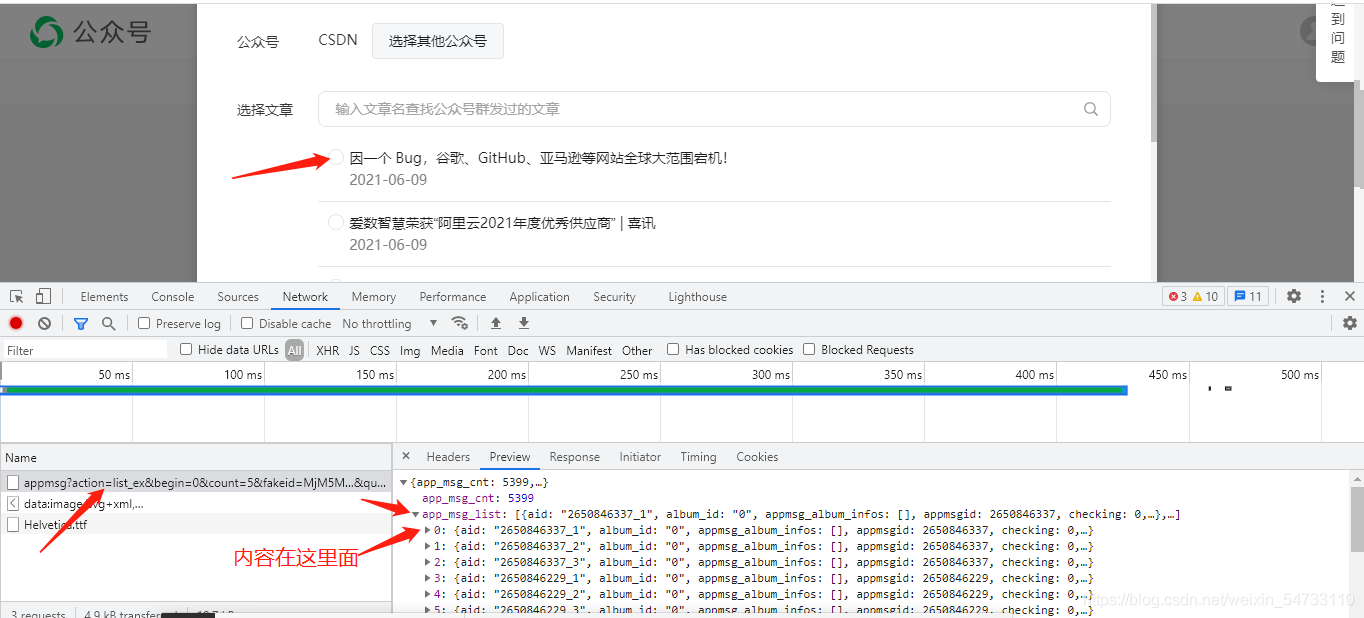
翻頁
打開headers,拿回第一頁的requests url
https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=MjM5MjAwODM4MA==&type=9&query=&token=1008822872&lang=zh_CN&f=json&ajax=1
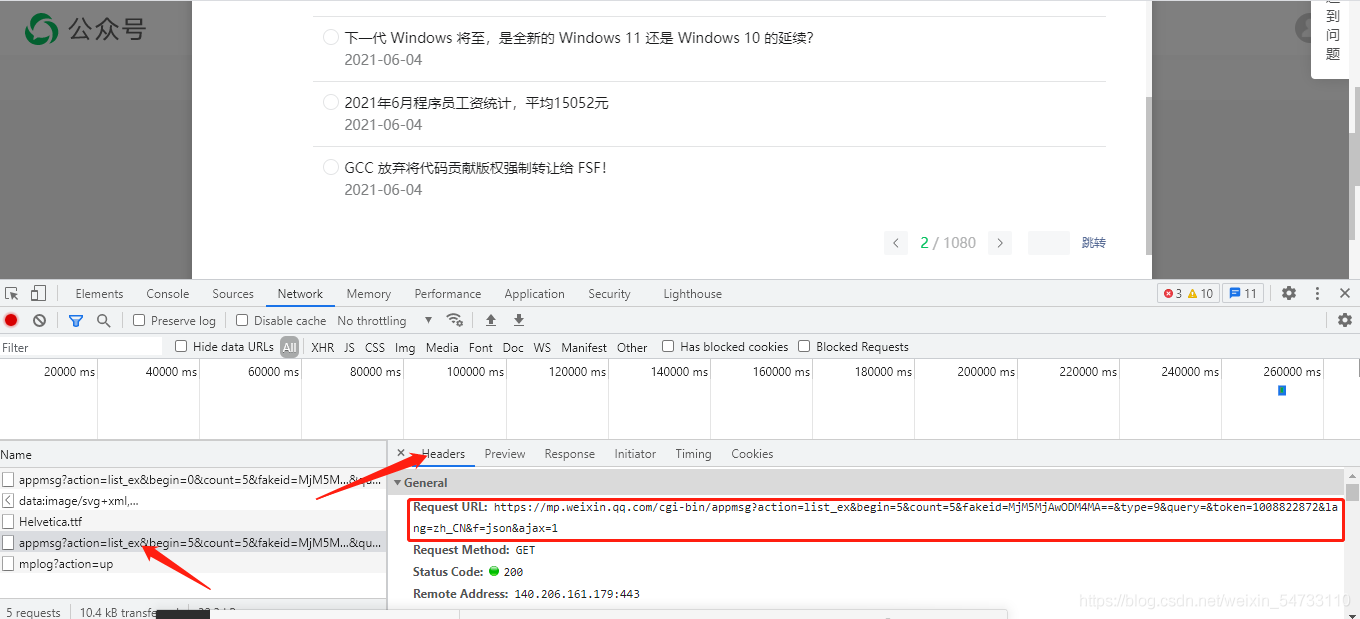
拿回第二頁的地址
https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=5&count=5&fakeid=MjM5MjAwODM4MA==&type=9&query=&token=1008822872&lang=zh_CN&f=json&ajax=1
對比可以發現begin引數以5的速度增長
直接原始碼展示
# !/usr/bin/nev python
# -*-coding:utf8-*-
import tkinter as tk
from selenium import webdriver
import time, re, jsonpath, xlwt
from requests_html import HTMLSession
session = HTMLSession()
class GZHSpider(object):
def __init__(self):
"""定義可視化視窗,并設定視窗和主題大小布局"""
self.window = tk.Tk()
self.window.title('公眾號資訊采集')
self.window.geometry('800x600')
"""創建label_user按鈕,與說明書"""
self.label_user = tk.Label(self.window, text='需要爬取的公眾號:', font=('Arial', 12), width=30, height=2)
self.label_user.pack()
"""創建label_user關聯輸入"""
self.entry_user = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_user.pack(after=self.label_user)
"""創建label_passwd按鈕,與說明書"""
self.label_passwd = tk.Label(self.window, text="爬取多少頁:(小于100)", font=('Arial', 12), width=30, height=2)
self.label_passwd.pack()
"""創建label_passwd關聯輸入"""
self.entry_passwd = tk.Entry(self.window, show=None, font=('Arial', 14))
self.entry_passwd.pack(after=self.label_passwd)
"""創建Text富文本框,用于按鈕操作結果的展示"""
self.text1 = tk.Text(self.window, font=('Arial', 12), width=85, height=22)
self.text1.pack()
"""定義按鈕1,系結觸發事件方法"""
self.button_1 = tk.Button(self.window, text='爬取', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
"""定義按鈕2,系結觸發事件方法"""
self.button_2 = tk.Button(self.window, text='清除', font=('Arial', 12), width=10, height=1,
command=self.parse_hit_click_2)
self.button_2.pack(anchor="e")
def parse_hit_click_1(self):
"""定義觸發事件1,呼叫main函式"""
user_name = self.entry_user.get()
pass_wd = int(self.entry_passwd.get())
self.main(user_name, pass_wd)
def main(self, user_name, pass_wd):
# 網頁登錄
driver_path = r'D:\python\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
# 網頁最大化
driver.maximize_window()
# 拿微信掃描登錄
time.sleep(20)
# 獲得登錄的cookies
cookies_list = driver.get_cookies()
# 轉化成能用的cookie格式
cookie = [item["name"] + "=" + item["value"] for item in cookies_list]
cookie_str = '; '.join(item for item in cookie)
# 請求頭
headers_1 = {
'cookie': cookie_str,
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36'
}
# 起始地址
start_url = 'https://mp.weixin.qq.com/'
response = session.get(start_url, headers=headers_1).content.decode()
# 拿到token值,token值是有時效性的
token = re.findall(r'token=(\d+)', response)[0]
# 搜索出所有跟輸入的公眾號有關的
next_url = f'https://mp.weixin.qq.com/cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={user_name}&token=' \
f'{token}&lang=zh_CN&f=json&ajax=1'
# 獲取回應
response_1 = session.get(next_url, headers=headers_1).content.decode()
# 拿到fakeid的值,確定公眾號,唯一的
fakeid = re.findall(r'"fakeid":"(.*?)",', response_1)[0]
# 構造公眾號的url地址
next_url_2 = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
headers_2 = {
'cookie': cookie_str,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.77 Safari/537.36',
'referer': f'https://mp.weixin.qq.com/cgi-bin/appmsgtemplate?action=edit&lang=zh_CN&token={token}',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'x-requested-with': 'XMLHttpRequest'
}
# 表的創建
workbook = xlwt.Workbook(encoding='gbk', style_compression=0)
sheet = workbook.add_sheet('test', cell_overwrite_ok=True)
j = 1
# 構造表頭
sheet.write(0, 0, '時間')
sheet.write(0, 1, '標題')
sheet.write(0, 2, '地址')
# 回圈翻頁
for i in range(pass_wd):
data["begin"] = i * 5
time.sleep(3)
# 獲取回應的json資料
response_2 = session.get(next_url_2, params=data, headers=headers_2).json()
# jsonpath 獲取時間,標題,地址
title_list = jsonpath.jsonpath(response_2, '$..title')
url_list = jsonpath.jsonpath(response_2, '$..link')
create_time_list = jsonpath.jsonpath(response_2, '$..create_time')
# 將時間戳轉化為北京時間
list_1 = []
for create_time in create_time_list:
time_local = time.localtime(int(create_time))
time_1 = time.strftime("%Y-%m-%d", time_local)
time_2 = time.strftime("%H:%M:%S", time_local)
time_3 = time_1 + ' ' + time_2
list_1.append(time_3)
# for回圈遍歷
for times, title, url in zip(list_1, title_list, url_list):
# 其中的'0-行, 0-列'指定表中的單元
sheet.write(j, 0, times)
sheet.write(j, 1, title)
sheet.write(j, 2, url)
j = j + 1
# 視窗顯示行程
self.text1.insert("insert", f'*****************第{i+1}頁爬取成功*****************')
time.sleep(2)
self.text1.insert("insert", '\n ')
self.text1.insert("insert", '\n ')
# 最后保存成功
workbook.save(f'{user_name}公眾號資訊.xls')
print(f"*********{user_name}公眾號資訊保存成功*********")
def parse_hit_click_2(self):
"""定義觸發事件2,洗掉文本框中內容"""
self.entry_user.delete(0, "end")
self.entry_passwd.delete(0, "end")
self.text1.delete("1.0", "end")
def center(self):
"""創建視窗居中函式方法"""
ws = self.window.winfo_screenwidth()
hs = self.window.winfo_screenheight()
x = int((ws / 2) - (800 / 2))
y = int((hs / 2) - (600 / 2))
self.window.geometry('{}x{}+{}+{}'.format(800, 600, x, y))
def run_loop(self):
"""禁止修改表單大小規格"""
self.window.resizable(False, False)
"""視窗居中"""
self.center()
"""視窗維持--持久化"""
self.window.mainloop()
if __name__ == '__main__':
g = GZHSpider()
g.run_loop()
代碼寫完打包一下,就可以發給客戶了

本代碼僅供學習!!!
代碼還需完善很多地方,想討論的可以評論留言,趕快收藏拿去試試吧
祝大家學習python順利,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286774.html
標籤:python