沒想到奧特曼竟然還真的有這么多種類,
Python 爬蟲 120 例,已完成文章清單
- 10 行代碼集 2000 張美女圖,Python 爬蟲 120 例,再上征途
- 通過 Python 爬蟲,發現 60%女裝大佬游走在 cosplay 領域
- Python 千貓圖,簡單技術滿足你的收集控
本篇博客目標
爬取目標
-
爬取 60+ 奧特曼,目標資料源: http://www.ultramanclub.com/?page_id=1156

使用框架
- requests,re
重點學習的內容
- get 請求;
- requests 請求超時設定,timeout 引數;
- re 模塊正則運算式;
- 資料去重;
- URL 地址拼接,
串列頁分析
經過開發者工具的簡單查閱,得到全部奧特曼卡片所在的 DOM 標簽為 <li class="item"></li>
詳情頁所在的標簽為 <a = href="詳情頁" ……
具體標簽所在元素如下圖所示:
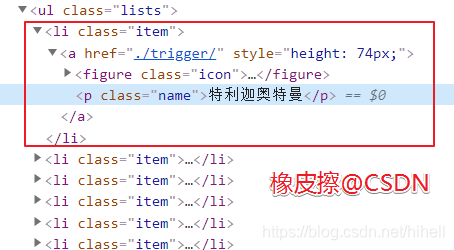
稍后根據實際請求資料,整理一下正則運算式,
詳情頁
點擊任意目標資料,進入詳情頁,詳情頁獲取奧特曼圖片,圖片地址所在位置如下圖所示,

右鍵可獲得圖片的所在標簽,

整理需求如下
- 通過串列頁,爬取全部奧特曼詳情頁的地址;
- 進入詳情頁,爬取詳情頁里面的圖片地址;
- 下載保存圖片;
代碼實作
爬取全部奧特曼詳情頁地址
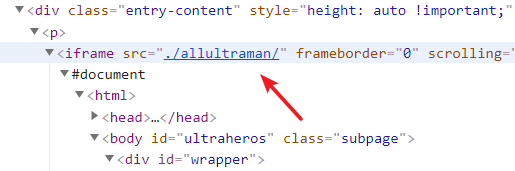
在爬取串列頁的程序中,發現奧特曼頁面使用了 iframe 嵌套,該手段也屬于最簡單的反爬手段,提取真實鏈接即可,故目標資料源切換為 http://www.ultramanclub.com/allultraman/ ,
import requests
import re
import time
# 爬蟲入口
def run():
url = "http://www.ultramanclub.com/allultraman/"
try:
# 網頁訪問速度慢,需要設定 timeout
res = requests.get(url=url, timeout=10)
res.encoding = "gb2312"
html = res.text
get_detail_list(html)
except Exception as e:
print("請求例外", e)
# 獲取全部奧特曼詳情頁
def get_detail_list(html):
start_index = '<ul class="lists">'
start = html.find(start_index)
html = html[start:]
links = re.findall('<li class="item"><a href="(.*)">', html)
print(len(links))
links = list(set(links))
print(len(links))
if __name__ == '__main__':
run()
在代碼撰寫程序中,發現網頁訪問速度慢,故設定 timeout 屬性為 10,防止出現例外,
正則運算式匹配資料時,出現了重復資料,通過 set 集合進行去重,最終在轉換為 list,
接下來對獲取到的 list 進行二次拼接,獲取詳情頁地址,
進行二次拼接得到的詳情頁地址,代碼如下:
# 獲取全部奧特曼詳情頁
def get_detail_list(html):
start_index = '<ul class="lists">'
start = html.find(start_index)
html = html[start:]
links = re.findall('<li class="item"><a href="(.*)">', html)
# links = list(set(links))
links = [f"http://www.ultramanclub.com/allultraman/{i.split('/')[1]}/" for i in set(links)]
print(links)
爬取全部奧特曼大圖
該步驟先獲取網頁標題的方式,然后用該標題,對奧特曼大圖爬取命名,
爬取邏輯非常簡單,只需要回圈上文爬取到詳情頁地址,然后通過正則運算式進行匹配即可,
修改代碼如下所示,關鍵節點查看注釋,
import requests
import re
import time
# 宣告 UA
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36"
}
# 存盤例外路徑,防止出現爬取失敗情況
error_list = []
# 爬蟲入口
def run():
url = "http://www.ultramanclub.com/allultraman/"
try:
# 網頁訪問速度慢,需要設定 timeout
res = requests.get(url=url, headers=headers, timeout=10)
res.encoding = "gb2312"
html = res.text
return get_detail_list(html)
except Exception as e:
print("請求例外", e)
# 獲取全部奧特曼詳情頁
def get_detail_list(html):
start_index = '<ul class="lists">'
start = html.find(start_index)
html = html[start:]
links = re.findall('<li class="item"><a href="(.*)">', html)
# links = list(set(links))
links = [
f"http://www.ultramanclub.com/allultraman/{i.split('/')[1]}/" for i in set(links)]
return links
def get_image(url):
try:
# 網頁訪問速度慢,需要設定 timeout
res = requests.get(url=url, headers=headers, timeout=15)
res.encoding = "gb2312"
html = res.text
print(url)
# 獲取詳情頁標題,作為圖片檔案名
title = re.search('<title>(.*?)\[', html).group(1)
# 獲取圖片短連接地址
image_short = re.search(
'<figure class="image tile">[.\s]*?<img src="(.*?)"', html).group(1)
# 拼接完整圖片地址
img_url = "http://www.ultramanclub.com/allultraman/" + image_short[3:]
# 獲取圖片資料
img_data = requests.get(img_url).content
print(f"正在爬取{title}")
if title is not None and image_short is not None:
with open(f"images/{title}.png", "wb") as f:
f.write(img_data)
except Exception as e:
print("*"*100)
print(url)
print("請求例外", e)
error_list.append(url)
if __name__ == '__main__':
details = run()
for detail in details:
get_image(detail)
while len(error_list) > 0:
print("再次爬取")
detail = error_list.pop()
get_image(detail)
print("奧特曼圖片資料爬取完畢")
運行代碼,看到圖片接連存盤到本地 images 目錄中,

代碼說明:
上述代碼在主函式中,對串列頁抓取到的詳情頁進行了回圈抓取,即如下部分代碼:
for detail in details:
get_image(detail)
由于本網站爬取速度慢,故在 get_image 函式中的 get 請求里面,加入了 timeout=15 的設定,
圖片地址正則匹配與地址拼接,使用的代碼如下:
# 獲取詳情頁標題,作為圖片檔案名
title = re.search('<title>(.*?)\[', html).group(1)
# 獲取圖片短連接地址
image_short = re.search(
'<figure class="image tile">[.\s]*?<img src="(.*?)"', html).group(1)
# 拼接完整圖片地址
img_url = "http://www.ultramanclub.com/allultraman/" + image_short[3:]
哎,這些奧特曼果然長得不一樣,

完整代碼下載地址:https://codechina.csdn.net/hihell/python120
如果你不想運行代碼,只想要圖,購買一份吧:https://download.csdn.net/download/hihell/19543243
抽獎時間(目前累計送出 4 份)
很遺憾,上一篇文章,評論沒有超過 50,所以本篇博客,送 2 份~
只要評論數過 50
隨機抽取一名幸運讀者
獎勵 39.9 元爬蟲 100 例專欄 1 折購買券一份,只需 3.99 元
今天是持續寫作的第 164 / 200 天,可以點贊、評論、收藏啦,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286779.html
標籤:python