程式總會各種錯誤
有的錯誤是程式撰寫有問題造成的,這種錯誤我們通常稱之為bug,bug是必須修復的;有的錯誤是用戶輸入造成的,這種錯誤可以通過檢查用戶輸入來做相應的處理,
還有一類錯誤是完全無法在程式運行程序中預測的,比如寫入檔案的時候,磁盤滿了,寫不進去了,或者從網路抓取資料,網路突然斷掉了,這類錯誤也稱為例外,在程式中通常是必須處理的,否則,程式會因為各種問題終止并退出,
Python內置了一套例外處理機制,此外也需要跟蹤程式的執行,查看變數的值是否正確,這個程序稱為除錯,Python的pdb可以讓我們以單步方式執行代碼,
最后,撰寫測驗也很重要,有了良好的測驗,就可以在程式修改后反復運行,確保程式輸出符合我們撰寫的測驗,
在程式運行的程序中,如果發生了錯誤,可以事先約定回傳一個錯誤代碼,這樣,就可以知道是否有錯,以及出錯的原因,在作業系統提供的呼叫中,回傳錯誤碼非常常見,
用錯誤碼來表示是否出錯十分不便,高級語言通常都內置了一套try...except...finally...的錯誤處理機制
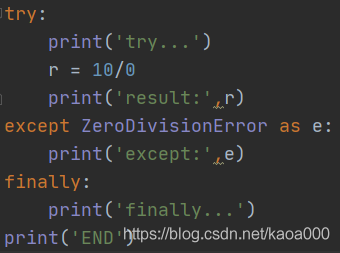
當認為某些代碼可能會出錯時,就可以用try來運行這段代碼,如果執行出錯,則后續代碼不會繼續執行,而是直接跳轉至錯誤處理代碼,即except陳述句塊,執行完except后,如果有finally陳述句塊,則執行finally陳述句塊,至此,執行完畢,上述運行結果:
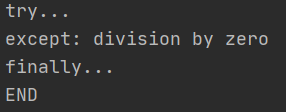
當錯誤發生時,后續陳述句print('result:', r)不會被執行,except由于捕獲到ZeroDivisionError,因此被執行,最后,finally陳述句被執行,
如果沒有錯誤發生,except陳述句塊不會被執行,但是finally如果有,則一定會被執行(可以沒有finally陳述句),
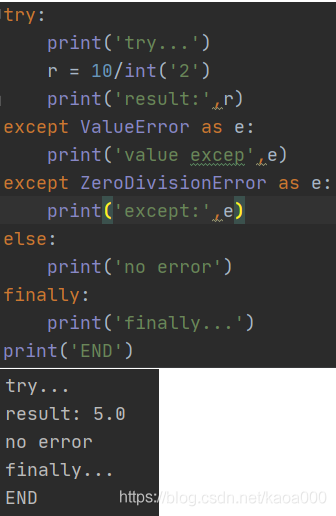
錯誤有很多種類,如果發生了不同型別的錯誤,應該由不同的except陳述句塊處理,可以有多個except來捕獲不同型別的錯誤:

如果沒有錯誤發生,可以在except陳述句塊后面加一個else,當沒有錯誤發生時,會自動執行else陳述句:
Python的錯誤也是class,所有的錯誤型別都繼承自BaseException,所以在使用except時需要注意的是,它不但捕獲該型別的錯誤,還把其子類也“一網打盡”,比如:
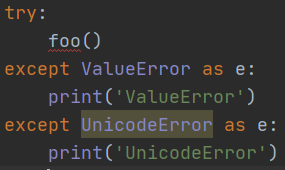
第二個except永遠也捕獲不到UnicodeError,因為UnicodeError是ValueError的子類,如果有,也被第一個except給捕獲了,這是多型的效果,
使用try...except捕獲錯誤還有一個巨大的好處,就是可以跨越多層呼叫,比如函式main()呼叫bar(),bar()呼叫foo(),結果foo()出錯了,這時,只要main()捕獲到了,就可以處理,不需要在每個可能出錯的地方去捕獲錯誤,只要在合適的層次去捕獲錯誤就可以了,
呼叫堆疊
如果錯誤沒有被捕獲,它就會一直往上拋,最后被Python解釋器捕獲,列印一個錯誤資訊,然后程式退出,出錯的時候,一定要分析錯誤的呼叫堆疊資訊,才能定位錯誤的位置,
記錄錯誤
如果不捕獲錯誤,自然可以讓Python解釋器來列印出錯誤堆疊,但程式也被結束了,既然我們能捕獲錯誤,就可以把錯誤堆疊列印出來,然后分析錯誤原因,同時,讓程式繼續執行下去,
拋出錯誤
因為錯誤是class,捕獲一個錯誤就是捕獲到該class的一個實體,因此,錯誤并不是憑空產生的,而是有意創建并拋出的,Python的內置函式會拋出很多型別的錯誤,我們自己撰寫的函式也可以拋出錯誤,
如果要拋出錯誤,首先根據需要,可以定義一個錯誤的class,選擇好繼承關系,然后,用raise陳述句拋出一個錯誤的實體:
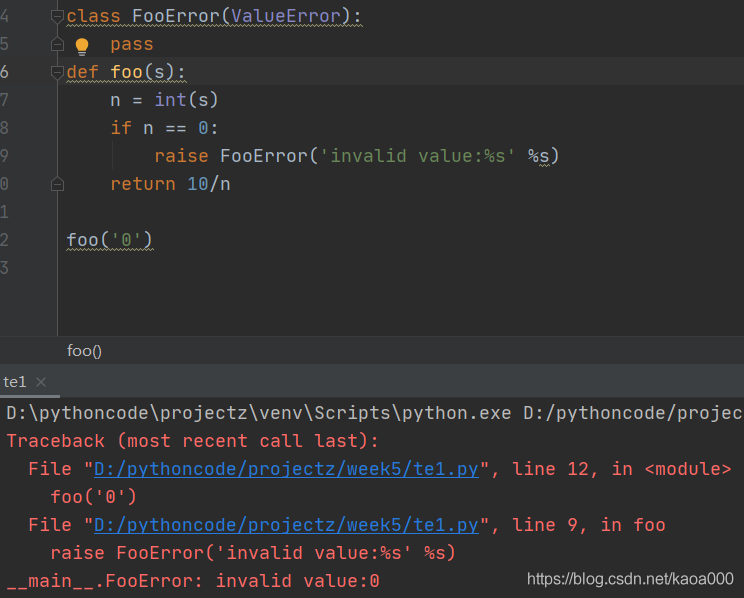
只有在必要的時候才定義我們自己的錯誤型別,如果可以選擇Python已有的內置的錯誤型別(比如ValueError,TypeError),盡量使用Python內置的錯誤型別,
最后,我們來看另一種錯誤處理的方式:
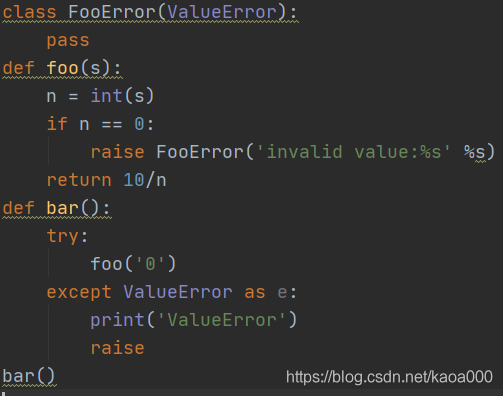
在bar()函式中,已經捕獲了錯誤,又把錯誤通過raise陳述句拋出去了,這種錯誤處理方式相當常見,捕獲錯誤目的只是記錄一下,便于后續追蹤,但是,由于當前函式不知道應該怎么處理該錯誤,所以,最恰當的方式是繼續往上拋,讓頂層呼叫者去處理,好比一個員工處理不了一個問題時,就把問題拋給他的老板,如果他的老板也處理不了,就一直往上拋,最侄訓拋給CEO去處理,
raise陳述句如果不帶引數,就會把當前錯誤原樣拋出,此外,在except中raise一個Error,還可以把一種型別的錯誤轉化成另一種型別:
try:
10 / 0
except ZeroDivisionError:
raise ValueError('input error!')
除錯
剛開始撰寫的程式總會有各種各樣的bug需要修正,有的bug很簡單,看看錯誤資訊就知道,有的bug很復雜,我們需要知道出錯時,哪些變數的值是正確的,哪些變數的值是錯誤的,因此,需要一整套除錯程式的手段來修復bug,
第一種方法簡單直接粗暴有效,就是用print()把可能有問題的變數列印出來看看,用print()最大的壞處是將來還得刪掉它,
第二種方法,斷言
凡是用print()來輔助查看的地方,都可以用斷言(assert)來替代:
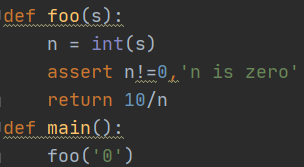
assert的意思是,表達式n != 0應該是True,否則,根據程式運行的邏輯,后面的代碼肯定會出錯,
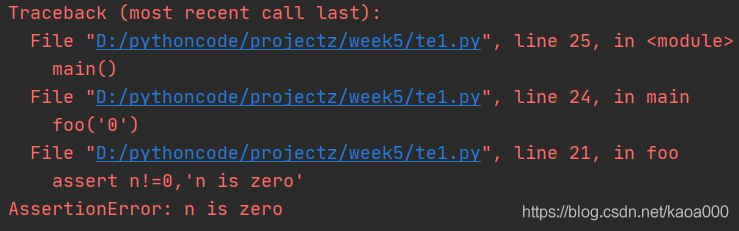
如果斷言失敗,assert陳述句本身就會拋出AssertionError:
運行main()
程式中如果到處充斥著assert,和print()相比也好不到哪去,不過,啟動Python解釋器時可以用-O引數來關閉assert:
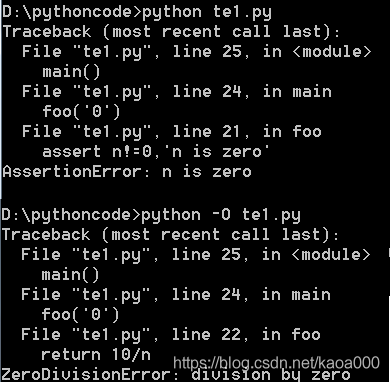
注意:斷言的開關“-O”是英文大寫字母O,不是數字0,關閉后,可以把所有的assert陳述句當成pass來看,
logging
把print()替換為logging是第3種方式,和assert比,logging不會拋出錯誤,而且可以輸出到檔案:
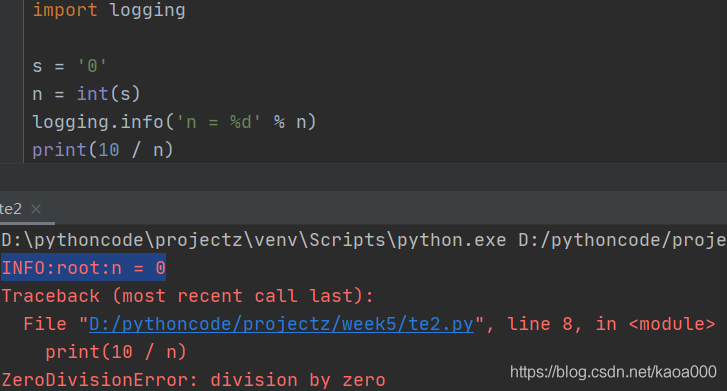
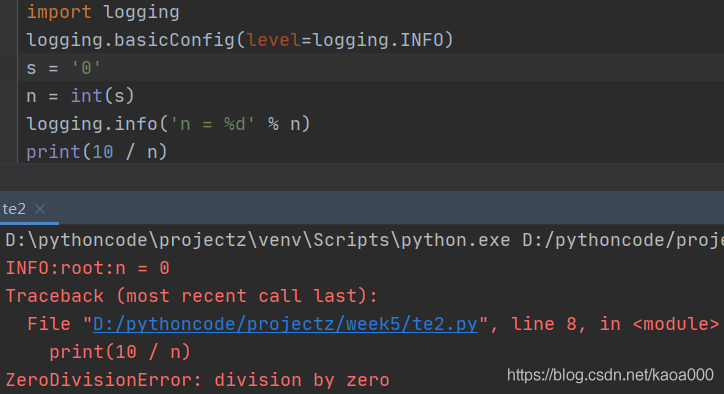
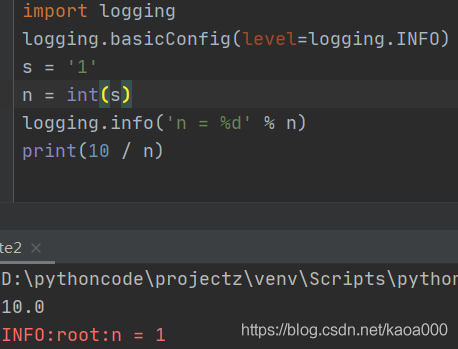
這就是logging的好處,它允許你指定記錄資訊的級別,有debug,info,warning,error等幾個級別.
pdb
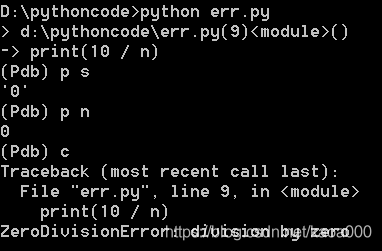
第4種方式是啟動Python的除錯器pdb,讓程式以單步方式運行,可以隨時查看運行狀態,我們先準備好程式:
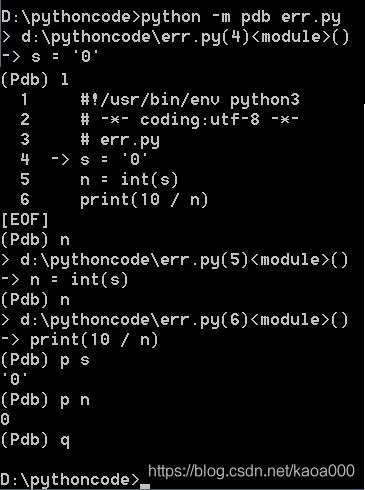
以引數-m pdb啟動后,pdb定位到下一步要執行的代碼-> s = '0',輸入命令l(小寫字母l——list的第一個字母)來查看代碼;輸入命令n可以單步執行代碼;任何時候都可以輸入命令p 變數名來查看變數;輸入命令q結束除錯,退出程式,
通過pdb在命令列除錯的方法理論上是萬能的,但實在是太麻煩了,如果有一千行代碼,要運行到第999行得敲多少命令啊,還好,有另一種除錯方法,
pdb.set_trace()
這個方法也是用pdb,但是不需要單步執行,只需要import pdb,然后,在可能出錯的地方放一個pdb.set_trace(),就可以設定一個斷點:
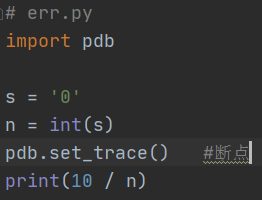
運行代碼,程式會自動在pdb.set_trace()暫停并進入pdb除錯環境,可以用命令p查看變數,或者用命令c繼續運行:
IDE
如果要比較爽地設定斷點、單步執行,就需要一個支持除錯功能的IDE,目前比較好的Python IDE有:
Visual Studio Code:需要安裝Python插件;PyCharm
單元測驗,與“測驗驅動開發”(TDD:Test-Driven Development)相對應
單元測驗是用來對一個模塊、一個函式或者一個類來進行正確性檢驗的測驗作業,
如果單元測驗通過,說明我們測驗的這個函式能夠正常作業,如果單元測驗不通過,要么函式有bug,要么測驗條件輸入不正確,總之,需要修復使單元測驗能夠通過,以測驗為驅動的開發模式最大的好處就是確保一個程式模塊的行為符合我們設計的測驗用例,在將來修改的時候,可以極大程度地保證該模塊行為仍然是正確的,
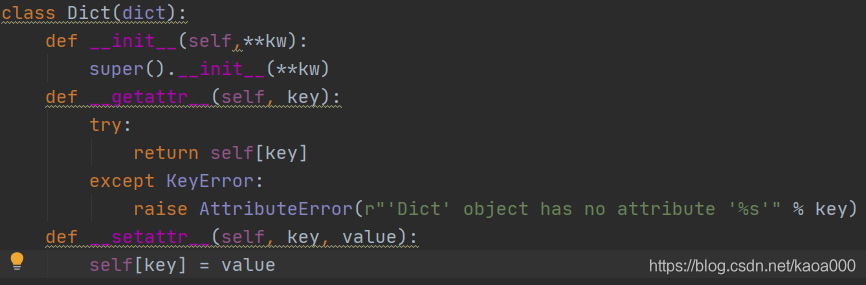
對上面的類進行單元測驗
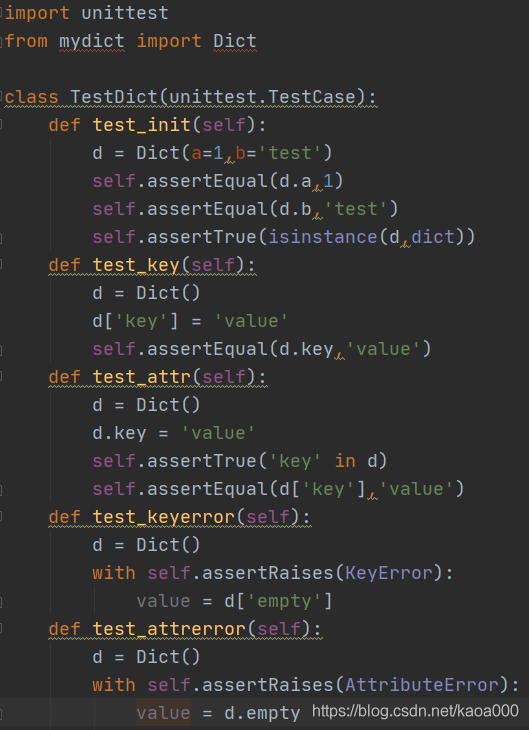
撰寫單元測驗,需要引入Python自帶的unittest模塊,寫單元測驗時,需要撰寫一個測驗類,從unittest.TestCase繼承,
以test開頭的方法就是測驗方法,不以test開頭的方法不被認為是測驗方法,測驗的時候不會被執行,
對每一類測驗都需要撰寫一個test_xxx()方法,由于unittest.TestCase提供了很多內置的條件判斷,只需要呼叫這些方法就可以斷言輸出是否是我們所期望的,最常用的斷言就是assertEqual():
self.assertEqual(abs(-1), 1) # 斷言函式回傳的結果與1相等
另一種重要的斷言就是期待拋出指定型別的Error,比如通過d['empty']訪問不存在的key時,斷言會拋出KeyError:
with self.assertRaises(KeyError):
value = d['empty']
而通過d.empty訪問不存在的key時,我們期待拋出AttributeError:
with self.assertRaises(AttributeError):
value = d.empty
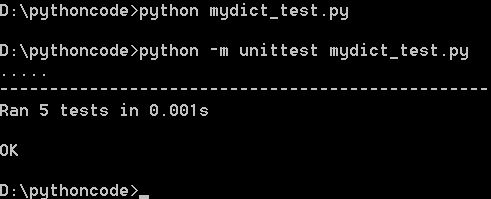
運行單元測驗
一旦撰寫好單元測驗,我們就可以運行單元測驗,最簡單的運行方式是在mydict_test.py的最后加上兩行代碼:
if __name__ == '__main__':
unittest.main()
這樣就可以把mydict_test.py當做正常的python腳本運行:
$ python mydict_test.py
另一種方法是在命令列通過引數-m unittest直接運行單元測驗:
$ python -m unittest mydict_test
這是推薦的做法,因為這樣可以一次批量運行很多單元測驗,并且,有很多工具可以自動來運行這些單元測驗,
setUp與tearDown
可以在單元測驗中撰寫兩個特殊的setUp()和tearDown()方法,這兩個方法會分別在每呼叫一個測驗方法的前后分別被執行,
setUp()和tearDown()方法有什么用呢?設想你的測驗需要啟動一個資料庫,這時,就可以在setUp()方法中連接資料庫,在tearDown()方法中關閉資料庫,這樣,不必在每個測驗方法中重復相同的代碼:
class TestDict(unittest.TestCase):
def setUp(self):
print('setUp...')
def tearDown(self):
print('tearDown...')
可以再次運行測驗看看每個測驗方法呼叫前后是否會列印出setUp...和tearDown...,

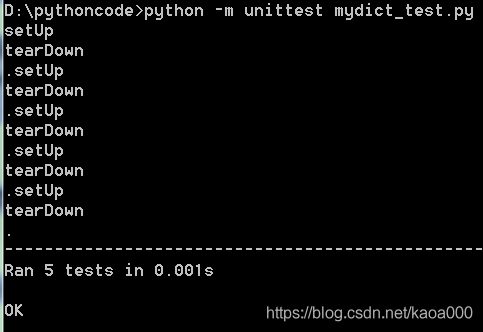
檔案測驗
把示例代碼在Python的互動式環境下輸入并執行,結果與檔案中的示例代碼顯示的一致,
撰寫注釋時,如果寫上這樣的注釋:
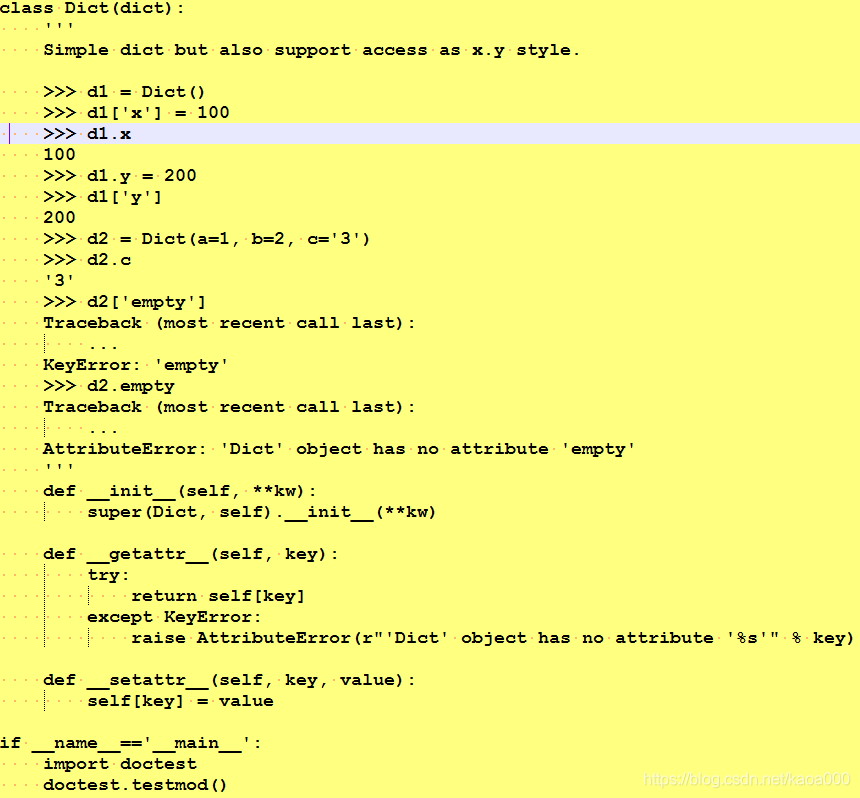
Python內置的“檔案測驗”(doctest)模塊可以直接提取注釋中的代碼并執行測驗,

什么輸出也沒有,這說明我們撰寫的doctest運行都是正確的,如果程式有問題,比如把__getattr__()方法注釋掉,再運行就會報錯:
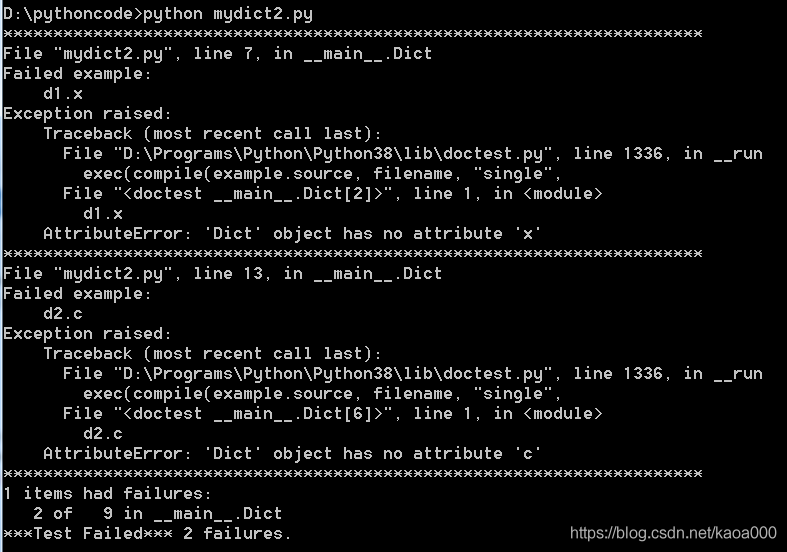
注意到最后3行代碼,當模塊正常匯入時,doctest不會被執行,只有在命令列直接運行時,才執行doctest,所以,不必擔心doctest會在非測驗環境下執行,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/286956.html
標籤:python