文章目錄
- 一、前言
- 二、RNN是什么
- 三、準備作業
- 1.設定GPU
- 2.加載資料
- 四、資料預處理
- 1.歸一化
- 2.設定測驗集訓練集
- 五、構建模型
- 六、激活模型
- 七、訓練模型
- 八、結果可視化
- 1.繪制loss圖
- 2.預測
- 3.評估
一、前言
今天是第9天,我們將開始RNN系列,完成股票開盤價格的預測,最后的R2可達到0.72,CNN系列后續我也會穿插更新
我的環境:
- 語言環境:Python3.6.5
- 編譯器:jupyter notebook
- 深度學習環境:TensorFlow2.4.1
往期精彩內容:
- 深度學習100例-卷積神經網路(CNN)實作mnist手寫數字識別 | 第1天
- 深度學習100例-卷積神經網路(CNN)服裝影像分類 | 第3天
- 深度學習100例-卷積神經網路(CNN)花朵識別 | 第4天
- 深度學習100例-卷積神經網路(CNN)天氣識別 | 第5天
- 深度學習100例-卷積神經網路(VGG-16)識別海賊王草帽一伙 | 第6天
- 深度學習100例 -卷積神經網路(ResNet-50)鳥類識別 | 第8天
來自專欄:【深度學習100例】
轉載請通過左側聯系方式(電腦端可看)聯系我,備注:CSDN轉載
二、RNN是什么
傳統神經網路的結構比較簡單:輸入層 – 隱藏層 – 輸出層
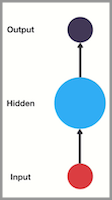
RNN 跟傳統神經網路最大的區別在于每次都會將前一次的輸出結果,帶到下一次的隱藏層中,一起訓練,如下圖所示:
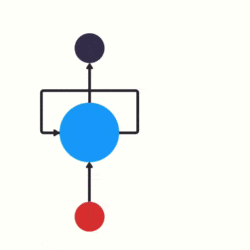
這里用一個具體的案例來看看 RNN 是如何作業的:
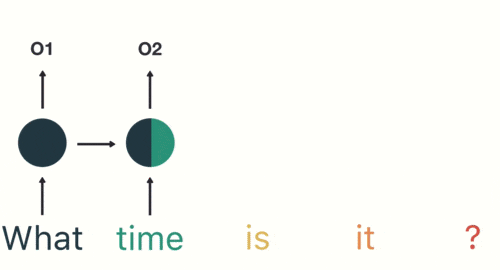
用戶說了一句“what time is it?”,我們的神經網路會先將這句話分為五個基本單元(四個單詞+一個問號)

然后,按照順序將五個基本單元輸入RNN網路,先將 “what”作為RNN的輸入,得到輸出01
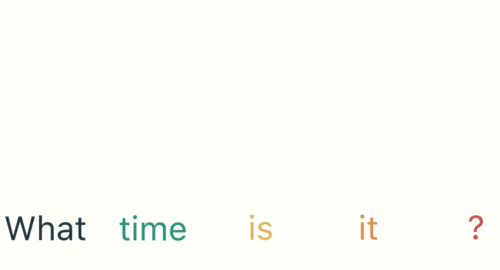
隨后,按照順序將“time”輸入到RNN網路,得到輸出02,
這個程序我們可以看到,輸入 “time” 的時候,前面“what” 的輸出也會對02的輸出產生了影響(隱藏層中有一半是黑色的),
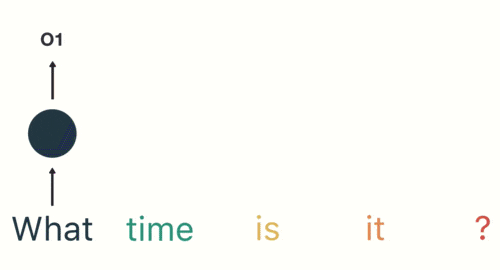
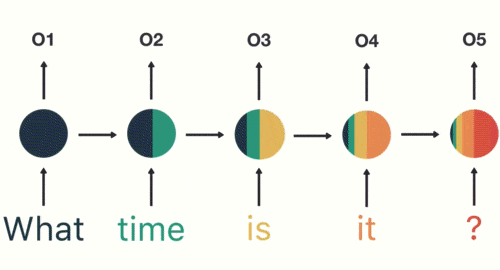
以此類推,我們可以看到,前面所有的輸入產生的結果都對后續的輸出產生了影響(可以看到圓形中包含了前面所有的顏色)
當神經網路判斷意圖的時候,只需要最后一層的輸出05,如下圖所示:
三、準備作業
1.設定GPU
如果使用的是CPU可以注釋掉這部分的代碼,
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #設定GPU顯存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
2.加載資料
import os,math
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
data = pd.read_csv('./datasets/SH600519.csv') # 讀取股票檔案
data
| Unnamed: 0 | date | open | close | high | low | volume | code | |
|---|---|---|---|---|---|---|---|---|
| 0 | 74 | 2010-04-26 | 88.702 | 87.381 | 89.072 | 87.362 | 107036.13 | 600519 |
| 1 | 75 | 2010-04-27 | 87.355 | 84.841 | 87.355 | 84.681 | 58234.48 | 600519 |
| 2 | 76 | 2010-04-28 | 84.235 | 84.318 | 85.128 | 83.597 | 26287.43 | 600519 |
| 3 | 77 | 2010-04-29 | 84.592 | 85.671 | 86.315 | 84.592 | 34501.20 | 600519 |
| 4 | 78 | 2010-04-30 | 83.871 | 82.340 | 83.871 | 81.523 | 85566.70 | 600519 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2421 | 2495 | 2020-04-20 | 1221.000 | 1227.300 | 1231.500 | 1216.800 | 24239.00 | 600519 |
| 2422 | 2496 | 2020-04-21 | 1221.020 | 1200.000 | 1223.990 | 1193.000 | 29224.00 | 600519 |
| 2423 | 2497 | 2020-04-22 | 1206.000 | 1244.500 | 1249.500 | 1202.220 | 44035.00 | 600519 |
| 2424 | 2498 | 2020-04-23 | 1250.000 | 1252.260 | 1265.680 | 1247.770 | 26899.00 | 600519 |
| 2425 | 2499 | 2020-04-24 | 1248.000 | 1250.560 | 1259.890 | 1235.180 | 19122.00 | 600519 |
2426 rows × 8 columns
"""
前(2426-300=2126)天的開盤價作為訓練集,表格從0開始計數,2:3 是提取[2:3)列,前閉后開,故提取出C列開盤價
后300天的開盤價作為測驗集
"""
training_set = data.iloc[0:2426 - 300, 2:3].values
test_set = data.iloc[2426 - 300:, 2:3].values
四、資料預處理
1.歸一化
sc = MinMaxScaler(feature_range=(0, 1))
training_set = sc.fit_transform(training_set)
test_set = sc.transform(test_set)
2.設定測驗集訓練集
x_train = []
y_train = []
x_test = []
y_test = []
"""
使用前60天的開盤價作為輸入特征x_train
第61天的開盤價作為輸入標簽y_train
for回圈共構建2426-300-60=2066組訓練資料,
共構建300-60=260組測驗資料
"""
for i in range(60, len(training_set)):
x_train.append(training_set[i - 60:i, 0])
y_train.append(training_set[i, 0])
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 對訓練集進行打亂
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
"""
將訓練資料調整為陣列(array)
調整后的形狀:
x_train:(2066, 60, 1)
y_train:(2066,)
x_test :(240, 60, 1)
y_test :(240,)
"""
x_train, y_train = np.array(x_train), np.array(y_train) # x_train形狀為:(2066, 60, 1)
x_test, y_test = np.array(x_test), np.array(y_test)
"""
輸入要求:[送入樣本數, 回圈核時間展開步數, 每個時間步輸入特征個數]
"""
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
五、構建模型
model = tf.keras.Sequential([
SimpleRNN(80, return_sequences=True), #布林值,是回傳輸出序列中的最后一個輸出,還是全部序列,
Dropout(0.2), #防止過擬合
SimpleRNN(80),
Dropout(0.2),
Dense(1)
])
六、激活模型
# 該應用只觀測loss數值,不觀測準確率,所以刪去metrics選項,一會在每個epoch迭代顯示時只顯示loss值
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 損失函式用均方誤差
七、訓練模型
history = model.fit(x_train, y_train,
batch_size=64,
epochs=20,
validation_data=(x_test, y_test),
validation_freq=1) #測驗的epoch間隔數
model.summary()
Epoch 1/20
33/33 [==============================] - 6s 123ms/step - loss: 0.1809 - val_loss: 0.0310
Epoch 2/20
33/33 [==============================] - 3s 105ms/step - loss: 0.0257 - val_loss: 0.0721
Epoch 3/20
33/33 [==============================] - 3s 85ms/step - loss: 0.0165 - val_loss: 0.0059
Epoch 4/20
33/33 [==============================] - 3s 85ms/step - loss: 0.0097 - val_loss: 0.0111
Epoch 5/20
33/33 [==============================] - 3s 90ms/step - loss: 0.0099 - val_loss: 0.0139
Epoch 6/20
33/33 [==============================] - 3s 105ms/step - loss: 0.0067 - val_loss: 0.0167
...................
Epoch 16/20
33/33 [==============================] - 3s 95ms/step - loss: 0.0035 - val_loss: 0.0149
Epoch 17/20
33/33 [==============================] - 4s 111ms/step - loss: 0.0028 - val_loss: 0.0111
Epoch 18/20
33/33 [==============================] - 4s 110ms/step - loss: 0.0029 - val_loss: 0.0061
Epoch 19/20
33/33 [==============================] - 3s 104ms/step - loss: 0.0027 - val_loss: 0.0110
Epoch 20/20
33/33 [==============================] - 3s 90ms/step - loss: 0.0028 - val_loss: 0.0037
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) (None, 60, 80) 6560
_________________________________________________________________
dropout (Dropout) (None, 60, 80) 0
_________________________________________________________________
simple_rnn_1 (SimpleRNN) (None, 80) 12880
_________________________________________________________________
dropout_1 (Dropout) (None, 80) 0
_________________________________________________________________
dense (Dense) (None, 1) 81
=================================================================
Total params: 19,521
Trainable params: 19,521
Non-trainable params: 0
_________________________________________________________________
八、結果可視化
1.繪制loss圖
plt.plot(history.history['loss'] , label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss by K同學啊')
plt.legend()
plt.show()
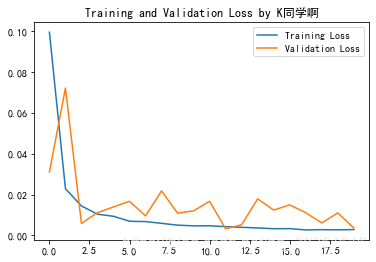
2.預測
predicted_stock_price = model.predict(x_test) # 測驗集輸入模型進行預測
predicted_stock_price = sc.inverse_transform(predicted_stock_price) # 對預測資料還原---從(0,1)反歸一化到原始范圍
real_stock_price = sc.inverse_transform(test_set[60:]) # 對真實資料還原---從(0,1)反歸一化到原始范圍
# 畫出真實資料和預測資料的對比曲線
plt.plot(real_stock_price, color='red', label='Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted Stock Price')
plt.title('Stock Price Prediction by K同學啊')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.show()
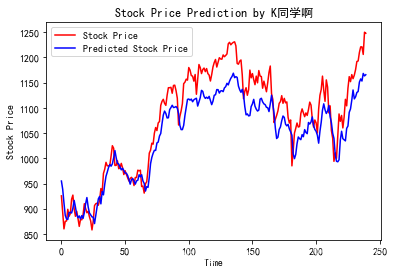
3.評估
"""
MSE :均方誤差 -----> 預測值減真實值求平方后求均值
RMSE :均方根誤差 -----> 對均方誤差開方
MAE :平均絕對誤差-----> 預測值減真實值求絕對值后求均值
R2 :決定系數,可以簡單理解為反映模型擬合優度的重要的統計量
詳細介紹可以參考文章:https://blog.csdn.net/qq_38251616/article/details/107997435
"""
MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)
RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5
MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price)
R2 = metrics.r2_score(predicted_stock_price, real_stock_price)
print('均方誤差: %.5f' % MSE)
print('均方根誤差: %.5f' % RMSE)
print('平均絕對誤差: %.5f' % MAE)
print('R2: %.5f' % R2)
均方誤差: 1833.92534
均方根誤差: 42.82435
平均絕對誤差: 36.23424
R2: 0.72347
往期精彩內容:
- 深度學習100例-卷積神經網路(CNN)實作mnist手寫數字識別 | 第1天
- 深度學習100例-卷積神經網路(CNN)服裝影像分類 | 第3天
- 深度學習100例-卷積神經網路(CNN)花朵識別 | 第4天
- 深度學習100例-卷積神經網路(CNN)天氣識別 | 第5天
- 深度學習100例-卷積神經網路(VGG-16)識別海賊王草帽一伙 | 第6天
- 深度學習100例 -卷積神經網路(ResNet-50)鳥類識別 | 第8天
來自專欄:【深度學習100例】
需要資料的同學可以在評論中留下郵箱,若時間久遠可在文章左側(電腦端可看)或者留言處尋找我的聯系方式,
點個關注,給個贊,加個收藏,送我上熱搜,先謝謝大家啦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/287271.html
標籤:python