作者:Kaito
來源:kaito-kidd.com/2020/07/07/redis-cluster-codis-twemproxy
之前我們提到,為了保證Redis的高可用,主要需要以下幾個方面:
- 資料持久化
- 主從復制
- 自動故障恢復
- 集群化
我們簡單理一下這幾個方案的特點,以及它們之間的聯系,
資料持久化本質上是為了做資料備份,有了資料持久化,當Redis宕機時,我們可以把資料從磁盤上恢復回來,但在資料恢復之前,服務是不可用的,而且資料恢復的時間取決于實體的大小,資料量越大,恢復起來越慢,
而主從復制則是部署多個副本節點,多個副本節點實時復制主節點的資料,當主節點宕機時,我們有完整的副本節點可以使用,另一方面,如果我們業務的讀請求量很大,主節點無法承受所有的讀請求,多個副本節點可以分擔讀請求,實作讀寫分離,這樣可以提高Redis的訪問性能,
但有個問題是,當主節點宕機時,我們雖然有完整的副本節點,但需要手動操作把從節點提升為主節點繼續提供服務,如果每次主節點故障,都需要人工操作,這個程序既耗時耗力,也無法保證及時性,高可用的程度將大打折扣,如何優化呢?
有了資料持久化、主從復制、故障自動恢復這些功能,我們在使用Redis時是不是就可以高枕無憂了?
答案是否定的,如果我們的業務大部分都是讀請求,可以使用讀寫分離提升性能,但如果寫請求量也很大呢?現在是大資料時代,像阿里、騰訊這些大體量的公司,每時每刻都擁有非常大的寫入量,此時如果只有一個主節點是無法承受的,那如何處理呢?
這就需要集群化!簡單來說實作方式就是,多個主從節點構成一個集群,每個節點存盤一部分資料,這樣寫請求也可以分散到多個主節點上,解決寫壓力大的問題,同時,集群化可以在節點容量不足和性能不夠時,動態增加新的節點,對進群進行擴容,提升性能,
從這篇文章開始,我們就開始介紹Redis的集群化方案,當然,集群化也意味著Redis部署架構更復雜,管理和維護起來成本也更高,而且在使用程序中,也會遇到很多問題,這也衍生出了不同的集群化解決方案,它們的側重點各不相同,
集群化方案
要想實作集群化,就必須部署多個主節點,每個主節點還有可能有多個從節點,以這樣的部署結構組成的集群,才能更好地承擔更大的流量請求和存盤更多的資料,
可以承擔更大的流量是集群最基礎的功能,一般集群化方案還包括了上面提到了資料持久化、資料復制、故障自動恢復功能,利用這些技術,來保證集群的高性能和高可用,
另外,優秀的集群化方案還實作了在線水平擴容功能,當節點數量不夠時,可以動態增加新的節點來提升整個集群的性能,而且這個程序是在線完成的,業務無感知,
業界主流的Redis集群化方案主要包括以下幾個:
- 客戶端分片
- Codis
- Twemproxy
- Redis Cluster
它們還可以用是否中心化來劃分,其中客戶端分片、Redis Cluster屬于無中心化的集群方案,Codis、Tweproxy屬于中心化的集群方案,
是否中心化是指客戶端訪問多個Redis節點時,是直接訪問還是通過一個中間層Proxy來進行操作,直接訪問的就屬于無中心化的方案,通過中間層Proxy訪問的就屬于中心化的方案,它們有各自的優劣,下面分別來介紹,
客戶端分片
客戶端分片主要是說,我們只需要部署多個Redis節點,具體如何使用這些節點,主要作業在客戶端,
客戶端通過固定的Hash演算法,針對不同的key計算對應的Hash值,然后對不同的Redis節點進行讀寫,
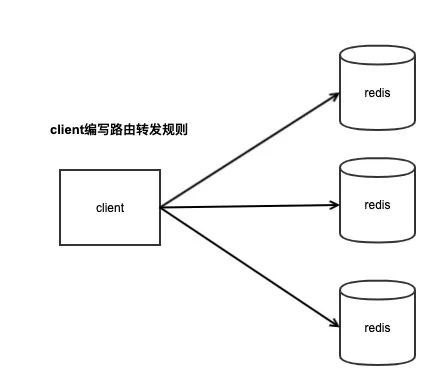 客戶端分片集群模式
客戶端分片集群模式
客戶端分片需要業務開發人員事先評估業務的請求量和資料量,然后讓DBA部署足夠的節點交給開發人員使用即可,
這個方案的優點是部署非常方便,業務需要多少個節點DBA直接部署交付即可,剩下的事情就需要業務開發人員根據節點數量來撰寫key的請求路由邏輯,制定一個規則,一般采用固定的Hash演算法,把不同的key寫入到不同的節點上,然后再根據這個規則進行資料讀取,
可見,它的缺點是業務開發人員使用Redis的成本較高,需要撰寫路由規則的代碼來使用多個節點,而且如果事先對業務的資料量評估不準確,后期的擴容和遷移成本非常高,因為節點數量發生變更后,Hash演算法對應的節點也就不再是之前的節點了,
所以后來又衍生出了一致性哈希演算法,就是為了解決當節點數量變更時,盡量減少資料的遷移和性能問題,
這種客戶端分片的方案一般用于業務資料量比較穩定,后期不會有大幅度增長的業務場景下使用,只需要前期評估好業務資料量即可,
Codis
隨著業務和技術的發展,人們越發覺得,當我需要使用Redis時,我們不想關心集群后面有多少個節點,我們希望我們使用的Redis是一個大集群,當我們的業務量增加時,這個大集群可以增加新的節點來解決容量不夠用和性能問題,
這種方式就是服務端分片方案,客戶端不需要關心集群后面有多少個Redis節點,只需要像使用一個Redis的方式去操作這個集群,這種方案將大大降低開發人員的使用成本,開發人員可以只需要關注業務邏輯即可,不需要關心Redis的資源問題,
多個節點組成的集群,如何讓開發人員像操作一個Redis時那樣來使用呢?這就涉及到多個節點是如何組織起來提供服務的,一般我們會在客戶端和服務端中間增加一個代理層,客戶端只需要操作這個代理層,代理層實作了具體的請求轉發規則,然后轉發請求到后面的多個節點上,因此這種方式也叫做中心化方式的集群方案,Codis就是以這種方式實作的集群化方案,

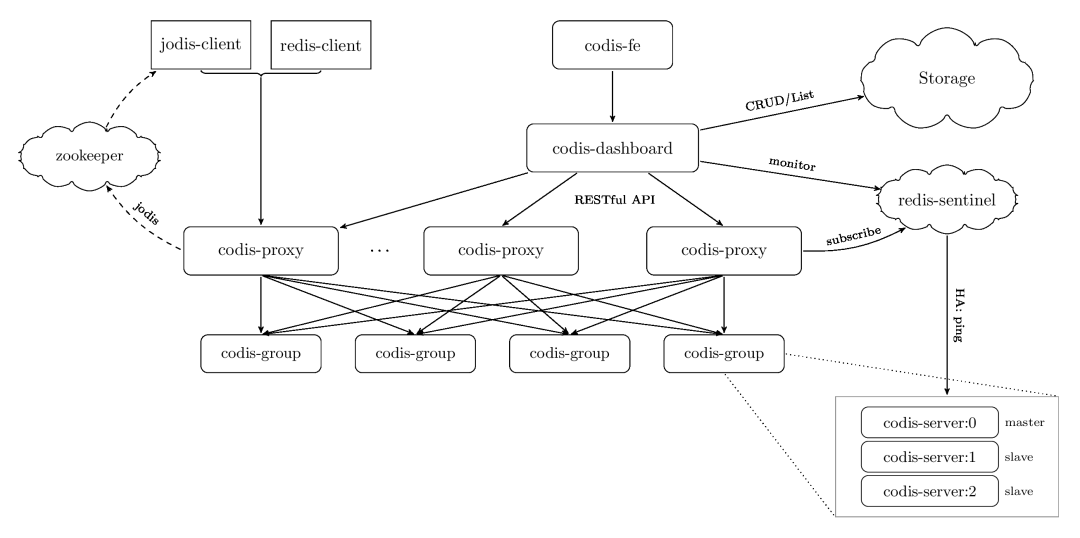
Codis是由國人前豌豆莢大神開發的,采用中心化方式的集群方案,因為需要代理層Proxy來進行所有請求的轉發,所以對Proxy的性能要求很高,Codis采用Go語言開發,兼容了開發效率和性能,
Codis包含了多個組件:
- codis-proxy:主要負責對請求的讀寫進行轉發
- codis-dashbaord:統一的控制中心,整合了資料轉發規則、故障自動恢復、資料在線遷移、節點擴容縮容、自動化運維API等功能
- codis-group:基于Redis 3.2.8版本二次開發的Redis Server,增加了異步資料遷移功能
- codis-fe:管理多個集群的UI界面
可見Codis的組件還是挺多的,它的功能非常全,除了請求轉發功能之外,還實作了在線資料遷移、節點擴容縮容、故障自動恢復等功能,
Codis的Proxy就是負責請求轉發的組件,它內部維護了請求轉發的具體規則,Codis把整個集群劃分為1024個槽位,在處理讀寫請求時,采用crc32Hash演算法計算key的Hash值,然后再根據Hash值對1024個槽位取模,最終找到具體的Redis節點,
Codis最大的特點就是可以在線擴容,在擴容期間不影響客戶端的訪問,也就是不需要停機,這對業務使用方是極大的便利,當集群性能不夠時,就可以動態增加節點來提升集群的性能,
為了實作在線擴容,保證資料在遷移程序中還有可靠的性能,Codis針對Redis進行了修改,增加了針對異步遷移資料相關命令,它基于Redis 3.2.8進行開發,上層配合Dashboard和Proxy組件,完成對業務無損的資料遷移和擴容功能,
因此,要想使用Codis,必須使用它內置的Redis,這也就意味著Codis中的Redis是否能跟上官方最新版的功能特性,可能無法得到保障,這取決于Codis的維護方,目前Codis已經不再維護,所以使用Codis時只能使用3.2.8版的Redis,這是一個痛點,
另外,由于集群化都需要部署多個節點,因此操作集群并不能完全像操作單個Redis一樣實作所有功能,主要是對于操作多個節點可能產生問題的命令進行了禁用或限制,具體可參考Codis不支持的命令串列,
但這不影響它是一個優秀的集群化方案,由于我司使用Redis集群方案較早,那時Redis Cluster還不夠成熟,所以我司使用的Redis集群方案就是Codis,
目前我的作業主要是圍繞Codis展開的,我們公司對Codis進行了定制開發,還對Redis進行了一些改造,讓Codis支持了跨多個資料中心的資料同步,
Twemproxy
Twemproxy是由Twitter開源的集群化方案,它既可以做Redis Proxy,還可以做Memcached Proxy,
它的功能比較單一,只實作了請求路由轉發,沒有像Codis那么全面有在線擴容的功能,它解決的重點就是把客戶端分片的邏輯統一放到了Proxy層而已,其他功能沒有做任何處理,
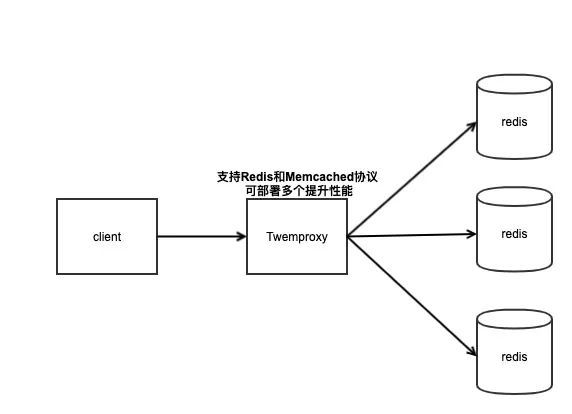
Tweproxy推出的時間最久,在早期沒有好的服務端分片集群方案時,應用范圍很廣,而且性能也極其穩定,
但它的痛點就是無法在線擴容、縮容,這就導致運維非常不方便,而且也沒有友好的運維UI可以使用,Codis就是因為在這種背景下才衍生出來的,
Redis Cluster
采用中間加一層Proxy的中心化模式時,這就對Proxy的要求很高,因為它一旦出現故障,那么操作這個Proxy的所有客戶端都無法處理,要想實作Proxy的高可用,還需要另外的機制來實作,例如Keepalive,
而且增加一層Proxy進行轉發,必然會有一定的性能損耗,那么除了客戶端分片和上面提到的中心化的方案之外,還有比較好的解決方案么?
Redis官方推出的Redis Cluster另辟蹊徑,它沒有采用中心化模式的Proxy方案,而是把請求轉發邏輯一部分放在客戶端,一部分放在了服務端,它們之間互相配合完成請求的處理,
Redis Cluster是在Redis 3.0推出的,早起的Redis Cluster由于沒有經過嚴格的測驗和生產驗證,所以并沒有廣泛推廣開來,也正是在這樣的背景下,業界衍生了出了上面所說的中心化集群方案:Codis和Tweproxy,
但隨著Redis的版本迭代,Redis官方的Cluster也越來越穩定,更多人開始采用官方的集群化方案,也正是因為它是官方推出的,所以它的持續維護性可以得到保障,這就比那些第三方的開源方案更有優勢,
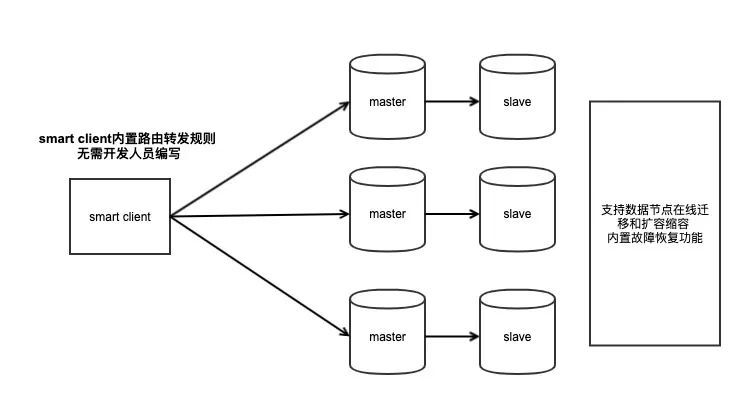
Redis Cluster沒有了中間的Proxy代理層,那么是如何進行請求的轉發呢?
Redis把請求轉發的邏輯放在了Smart Client中,要想使用Redis Cluster,必須升級Client SDK,這個SDK中內置了請求轉發的邏輯,所以業務開發人員同樣不需要自己撰寫轉發規則,Redis Cluster采用16384個槽位進行路由規則的轉發,
 Redis
Redis
沒有了Proxy層進行轉發,客戶端可以直接操作對應的Redis節點,這樣就少了Proxy層轉發的性能損耗,
Redis Cluster也提供了在線資料遷移、節點擴容縮容等功能,內部還內置了哨兵完成故障自動恢復功能,可見它是一個集成所有功能于一體的Cluster,因此它在部署時非常簡單,不需要部署過多的組件,對于運維極其友好,
Redis Cluster在節點資料遷移、擴容縮容時,對于客戶端的請求處理也做了相應的處理,當客戶端訪問的資料正好在遷移程序中時,服務端與客戶端制定了一些協議,來告知客戶端去正確的節點上訪問,幫助客戶端訂正自己的路由規則,
雖然Redis Cluster提供了在線資料遷移的功能,但它的遷移性能并不高,遷移程序中遇到大key時還有可能長時間阻塞遷移的兩個節點,這個功能相較于Codis來說,Codis資料遷移性能更好,
現在越來越多的公司開始采用Redis Cluster,有能力的公司還在它的基礎上進行了二次開發和定制,來解決Redis Cluster存在的一些問題,我們期待Redis Cluster未來有更好的發展,
總結
比較完了這些集群化方案,下面我們來總結一下,
| # | 客戶端分片 | Codis | Tweproxy | Redis Cluster |
|---|---|---|---|---|
| 集群模式 | 無中心化 | 中心化 | 中心化 | 無中心化 |
| 使用方式 | 客戶端撰寫路由規則代碼,直連Redis | 通過Proxy訪問 | 通過Proxy訪問 | 使用Smart Client直連Redis,Smart Client內置路由規則 |
| 性能 | 高 | 有性能損耗 | 有性能損耗 | 高 |
| 支持的資料庫數量 | 多個 | 多個 | 多個 | 一個 |
| Pipeline | 支持 | 支持 | 支持 | 僅支持單個節點Pipeline,不支持跨節點 |
| 需升級客戶端SDK? | 否 | 否 | 否 | 是 |
| 支持在線水平擴容? | 不支持 | 支持 | 不支持 | 支持 |
| Redis版本 | 支持最新版 | 僅支持3.2.8,升級困難 | 支持最新版 | 支持最新版 |
| 可維護性 | 運維簡單,開發人員使用成本高 | 組件較多,部署復雜 | 只有Proxy組件,部署簡單 | 運維簡單,官方持續維護 |
| 故障自動恢復 | 需部署哨兵 | 需部署哨兵 | 需部署哨兵 | 內置哨兵邏輯,無需額外部署 |
業界主流的集群化方案就是以上這些,并對它們的特點和區別做了簡單的介紹,我們在開發程序中選擇自己合適的集群方案即可,但最好是理解它們的實作原理,在使用程序中遇到問題才可以更從容地去解決,
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2021最新版)
2.終于靠開源專案弄到 IntelliJ IDEA 激活碼了,真香!
3.阿里 Mock 工具正式開源,干掉市面上所有 Mock 工具!
4.Spring Cloud 2020.0.0 正式發布,全新顛覆性版本!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/287288.html
標籤:其他