個人博客歡迎訪問
總結不易,如果對你有幫助,請點贊關注支持一下
微信搜索程式dunk,關注公眾號,獲取博客原始碼、資料結構與演算法筆記、面試筆試題
| 序號 | 內容 |
|---|---|
| 1 | Java基礎面試題 |
| 2 | JVM面試題 |
| 3 | Java并發編程面試 |
| 4 | 計算機網路知識點匯總 |
| 5 | MySQL面試題 |
| 6 | Mybatis原始碼分析 + 面試 |
| 7 | Spring面試題 |
| 8 | SpringMVC面試題 |
| 9 | SpringBoot面試題 |
| 10 | SpringCloud面試題 |
| 11 | Redis面試題 |
| 12 | Elasticsearch面試題 |
| 13 | Docker學習 |
| 14 | 訊息佇列 |
| 15 | 持續更新… |
文章目錄
- 面向物件
- 面向物件和面向程序的區別
- 三大特性
- 封裝
- 繼承
- 多型
- 多載與重寫
- 多載
- 重寫
- 類之間的關系
- 訪問權限控制符
- 語言特性
- Java語言的優點
- Java如何實作平臺無關?
- JDK和JRE的區別
- Java是按值呼叫還是參考呼叫
- 淺拷貝和深拷貝的區別
- 序列化
- 常見的序列化方式
- Java 原生序列化
- Hessian 序列化
- JSON 序列化
- 常問方法和類
- Object 類有哪些方法?
- hashCode與equals的
- hashCode()介紹
- 為什么要有hashCode()
- hashCode()與equals()的相關規定
- 物件的相等與指向他們的參考相等,兩者有什么不同?
- ==和equals?
- 資料型別
- java的基本資料型別
- 包裝類
- int和Integer區別
- Java 為每個原始型別提供了包裝型別:
- Integer a = 127和Integer b = 127相等嗎
- String
- 字串拼接的方式有哪些
- String a = "a" + new String("b")創建了幾個物件?
- StringBuffer和StringBuilder的區別?
- 可變性
- 執行緒安全性
- 性能
- 總結
- switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上?
- final關鍵字
- final、finally、finalize 有什么區別?
- 注解
- 注解的概念
- 什么是注解?什么是元注解?
- 注解處理器
- 定義注解
- 使用注解介面
- 定義注解處理器
- 測驗
- 類
- 內部類
- 靜態內部類
- 成員內部類
- 區域內部類
- 匿名內部類
- 匿名內部類的特點
- 總結
- 內部類的優點
- 應用場景
- 區域內部類和匿名內部類訪問區域變數的時候,為什么變數必須要加上final?
- 抽象類和介面的區別?
- 抽象類和介面怎么選擇?
- 泛型
- 什么是泛型,有什么用?
- 泛型標記和泛型限定
- 泛
- 泛型擦除是什么?
- Java集合容器面試題
- 常用的集合類
- List介面
- 談談ArrayList
- 初始容量
- 擴容
- 如何實作陣列和List之間的轉換
- 談談LinkedList
- ArrayList和LinkedList的區別
- ArrayList和Vector的區別
- 快速失敗(fail-fast)
- 安全失敗(fail-safe)
- 怎么確保一個集合不被修改
- 迭代器
- Iterator
- Iterator 和 ListIterator 有什么區別
- Set介面
- 談談HashSet
- TreeSet同TreeMap
- Map介面
- 談談TreeMap
- Comparable和Comparator介面的區別
- 升序降序記法
- 總結
- HashMap
- Queue
- BlockingQueue
- JavaIO流
- 阻塞(Block)與非阻塞(Non-Block)
- 阻塞IO
- 非阻塞IO
- 同步(Synchronous)與異步(Asynchronous)
- 同步IO
- 異步IO
- 總結
- NIO模型
- NIO(Non-blocking / New I/O)
- NIO的特點
- 核心組件
- Channel(通道)
- Buffer(緩沖區)
- Selector(多路復用器)
- BIO模型
- BIO(傳統IO)
- Java BIO與NIO比較
- AIO概念
- JavaIO流分為哪幾種
- JDK8新特性
- Lambda運算式
- 函式式介面
- 斷定性介面
- 消費型介面
- 供給性介面
- 方法參考
- 介面
- 注解
- 型別推測
- Optional 類
- Stream 類
- 日期
- JavaScript
面向物件
面向物件和面向程序的區別
- 面向程序:具體化的,流程化的,解決一個問題,你需要一步一步分析,一步一步實作
- 優點:性能比面向物件高,因為類呼叫時需要實體化,開銷比較大,比較消耗資源;比如單片機、嵌入式開發、Linux/Unix等一般采用面向程序開發,性能是最重要的因素
- 缺點:沒有面向物件易維護、易復用、易擴展
- 面向物件:模型化的,你只需要抽出一個類,這是一個封閉的盒子,在這里你擁有資料也擁有解決問題的方法,需要什么功能直接使用就可以了,不必去一步一步的實作,至于這個功能是如何實作的
- 優點::易維護、易復用、易擴展,由于面向物件有封裝、繼承、多型性的特性,可以設計出低耦合的系統,使系統更加靈活、更加易于維護
- 缺點:性能比面向程序低
三大特性
抽象:抽象是將一類物件的共同特征總結出來構造類的程序,包括資料抽象和行為抽象兩方面,抽象只關注物件有哪些屬性和行為,并不關注這些行為的細節
封裝
是物件功能內聚的表現形式,在抽象基礎上決定資訊是否公開及公開等級,核心問題是以什么方式暴漏哪些資訊,主要任務是對屬性、資料、敏感行為實作隱藏,對屬性的訪問和修改必須通過公共介面實作,封裝使物件關系變得簡單,降低了代碼耦合度,方便維護
迪米特原則就是對封裝的要求,即 A 模塊使用 B 模塊的某介面行為,對 B 模塊中除此行為外的其他資訊知道得應盡可能少,不直接對 public 屬性進行讀取和修改而使用 getter/setter 方法是因為假設想在修改屬性時進行權限控制、日志記錄等操作,在直接訪問屬性的情況下無法實作,如果將 public 的屬性和行為修改為 private 一般依賴模塊都會報錯,因此不知道使用哪種權限時應優先使用 private
繼承
用來擴展一個類,子類可繼承父類的部分屬性和行為使模塊具有服用性,繼承是“is-a”的關系,可使用里氏替換原則判斷是夠滿足“is-a”的關系,即任何父類出現的地方子類都可以出現,,如果父類參考直接使用子類參考來代替且可以正確編譯并執行,輸出結果符合子類場景預期,那么說明兩個類符合里氏替換原則
多型
以封裝和繼承為基礎,根據運行時物件實際型別使同以行為具有不同表現形式,多型指在編譯層面無法確定最終呼叫的方法體,在運行期由JVM動態系結,適合合適的重寫方法,由于多載屬于靜態系結,本質上多載結果是完全不同的方法,因此多型一般專指重寫
多載與重寫
多載
多載指方法名稱相同,但引數型別個數不同,是行為水平方向不同實作,對編譯器來說,方法名稱和引數串列組成了一個唯一鍵,稱為方法簽名,JVM 通過方法簽名決定呼叫哪種多載方法,不管繼承關系如何復雜,多載在編譯時可以根據規則知道呼叫哪種目標方法,因此屬于靜態系結
JVM 在多載方法中選擇合適方法的順序:① 精確匹配,② 基本資料型別自動轉換成更大表示范圍,③ 自動拆箱與裝箱,④ 子類向上轉型,⑤ 可變引數
重寫
重寫指子類實作介面或繼承父類時,保持方法簽名完全相同,實作不同方法體,是行為垂直方向不同實作
元空間有一個方法表保存方法資訊,如果子類重寫了父類的方法,則方法表中的方法參考會指向子類實作,父類參考執行子類方法時無法呼叫子類存在而父類不存在的方法,
重寫方法訪問權限不能變小,回傳型別和拋出的例外型別不能變大,必須加 @Override
類之間的關系
| 類關系 | 描述 | 權力強側 | 舉例 |
|---|---|---|---|
| 繼承 | 父子類之間的關系:is-a | 父類 | 小狗繼承于動物 |
| 實作 | 介面和實作類之間的關系:can-do | 介面 | 小狗實作了狗叫介面 |
| 組合 | 比聚合更強的關系:contains-a | 整體 | 頭是身體的一部分 |
| 聚合 | 暫時組裝的關系:has-a | 組裝方 | 小狗和繩子是暫時的聚合關系 |
| 依賴 | 一個類用到另一個:depends-a | 被依賴方 | 人養小狗,人依賴于小狗 |
| 關聯 | 平等的使用關系:links-a | 平等 | 人使用卡消費,卡可以提取人的資訊 |
訪問權限控制符
| 訪問權限控制符 | 本類 | 包內 | 包外子類 | 任何地方 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| 無 | √ | √ | × | × |
| private | √ | × | × | × |
語言特性
Java語言的優點
- 平臺無關性,擺脫硬體束縛,一次撰寫,匯出運行
- 相對安全的記憶體管理和訪問機制,避免大部分記憶體泄漏和指標越界
- 熱點代碼檢測和運行時編譯及優化,使程式隨時間運行增長獲得更高的性能
- 完善的應用程式介面,支持第三方類別庫
Java如何實作平臺無關?
JVM:java編譯器可生成與計算機體系結構無關的位元組碼指令,位元組碼指令不僅可以輕易的在任何機器上解釋執行,還可以動態地轉換為本地機器代碼,轉換是由JVM實作的,JVM是平臺相關的,屏蔽了不同作業系統的差異
語言規范:基本資料型別有明確的規定,例如int永遠為32位,而C/C++中可能是16位、32位,也可能是編譯器開發商指定的其他大小,Java中數值型別有固定的位元組數,二進制格式存盤和傳輸,字串采用標準的Unicode格式存盤
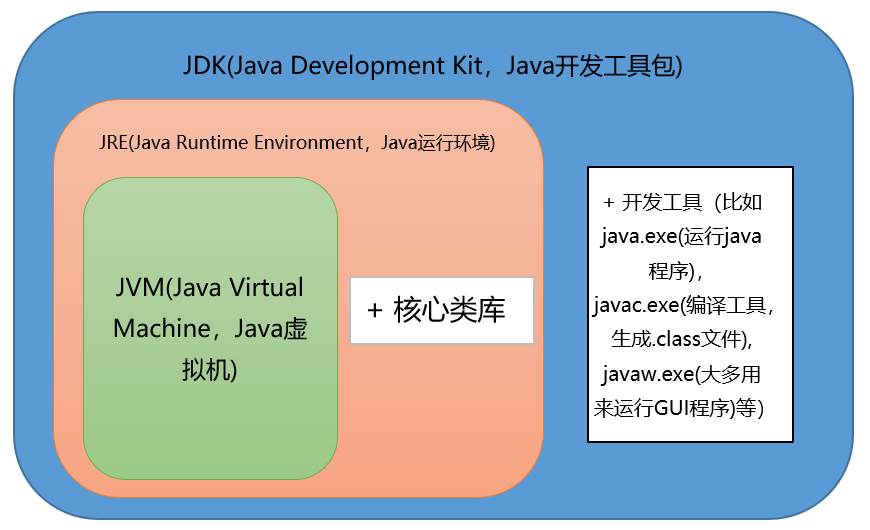
JDK和JRE的區別
JDK:Java Development Kit,開發工具包,提供了編譯運行Java程式的各種工具,包括編譯器(javac.exe)、JRE以及打包工具(jar.exe),是Java的核心
JRE:Java Runtime Environment,運行時環境,運行Java程式所必須的環境,包括JVM、核心類別庫、核心配置工具
Java是按值呼叫還是參考呼叫
- 按值傳遞:是指接受呼叫者提供的值
- 按參考呼叫:是指方法接受呼叫者提供的變數地址
Java總是按值呼叫,方法得到的所有引數的副本,傳遞物件時實際上方法接受的是物件參考的副本,方法不能修改基本資料型別的引數,如果傳遞了一個int值,改變值不會影響實參,因為改變的是值的一個副本
可以改變物件引數的狀態,但不能讓物件引數參考一個新的物件,如果傳遞了一個int陣列,改變陣列的內容會影響實參,而改變這個引數的參考并不會讓實參參考新的陣列物件
淺拷貝和深拷貝的區別
- 淺拷貝:只復制當前物件的基本資料型別即參考變數,沒有復制參考變數指向的實際物件,修改克隆物件可能影響原物件,不安全
- 深拷貝:完全拷貝基本資料型別和應用資料型別,安全
序列化
Java 物件 JVM 退出時會全部銷毀,如果需要將物件及狀態持久化,就要通過序列化實作,將記憶體中的物件保存在二進制流中,需要時再將二進制流反序列化為物件,物件序列化保存的是物件的狀態,因此屬于類屬性的靜態變數不會被序列化
常見的序列化方式
Java 原生序列化
實作 Serializabale 標記介面,Java 序列化保留了物件類的元資料(如類、成員變數、繼承類資訊)以及物件資料,兼容性最好,但不支持跨語言,性能一般,序列化和反序列化必須保持序列化 ID 的一致,一般使用 private static final long serialVersionUID 定義序列化 ID,如果不設定編譯器會根據類的內部實作自動生成該值,如果是兼容升級不應該修改序列化 ID,防止出錯,如果是不兼容升級則需要修改
Hessian 序列化
Hessian 序列化是一種支持動態型別、跨語言、基于物件傳輸的網路協議,Java 物件序列化的二進制流可以被其它語言反序列化,Hessian 協議的特性:① 自描述序列化型別,不依賴外部描述檔案,用一個位元組表示常用基礎型別,極大縮短二進制流,② 語言無關,支持腳本語言,③ 協議簡單,比 Java 原生序列化高效,Hessian 會把復雜物件所有屬性存盤在一個 Map 中序列化,當父類和子類存在同名成員變數時會先序列化子類再序列化父類,因此子類值會被父類覆寫
JSON 序列化
JSON 序列化就是將資料物件轉換為 JSON 字串,在序列化程序中拋棄了型別資訊,所以反序列化時只有提供型別資訊才能準確進行,相比前兩種方式可讀性更好,方便除錯
序列化通常會使用網路傳輸物件,而物件中往往有敏感資料,容易遭受攻擊,Jackson 和 fastjson 等都出現過反序列化漏洞,因此不需要進行序列化的敏感屬性傳輸時應加上 transient 關鍵字,transient 的作用就是把變數生命周期僅限于記憶體而不會寫到磁盤里持久化,變數會被設為對應資料型別的零值
常問方法和類
Object 類有哪些方法?
**equals:**檢測物件是否相等,默認使用 == 比較物件參考,可以重寫 equals 方法自定義比較規則,equals 方法規范:自反性、對稱性、傳遞性、一致性、對于任何非空參考 x,x.equals(null) 回傳 false
**hashCode:**散列碼是由物件匯出的一個整型值,沒有規律,每個物件都有默認散列碼,值由物件存盤地址得出,字串散列碼由內容匯出,值可能相同,為了在集合中正確使用,一般需要同時重寫 equals 和 hashCode,要求 equals 相同 hashCode 必須相同,hashCode 相同 equals 未必相同,因此 hashCode 是物件相等的必要不充分條件
toString:列印物件時默認的方法,如果沒有重寫列印的是表示物件值的一個字串
*clone:clone 方法宣告為 protected,類只能通過該方法克隆它自己的物件,如果希望其他類也能呼叫該方法必須定義該方法為 public,如果一個物件的類沒有實作 Cloneable 介面,該物件呼叫 clone 方拋出一個 CloneNotSupport 例外,默認的 clone 方法是淺拷貝,一般重寫 clone 方法需要實作 Cloneable 介面并指定訪問修飾符為 public
**finalize:**確定一個物件死亡至少要經過兩次標記,如果物件在可達性分析后發現沒有與 GC Roots 連接的參考鏈會被第一次標記,隨后進行一次篩選,條件是物件是否有必要執行 finalize 方法,假如物件沒有重寫該方法或方法已被虛擬機呼叫,都視為沒有必要執行,如果有必要執行,物件會被放置在 F-Queue 佇列,由一條低調度優先級的 Finalizer 執行緒去執行,虛擬機會觸發該方法但不保證會結束,這是為了防止某個物件的 finalize 方法執行緩慢或發生死回圈,只要物件在 finalize 方法中重新與參考鏈上的物件建立關聯就會在第二次標記時被移出回收集合,由于運行代價高昂且無法保證呼叫順序,在 JDK 9 被標記為過時方法,并不適合釋放資源
**getClass:**回傳包含物件資訊的類物件,
**wait / notify / notifyAll:**阻塞或喚醒持有該物件鎖的執行緒
hashCode與equals的
HashSet如何檢查重復,兩個物件的hashCode()相同,則equals()也一定為true
hashCode()介紹
hashCode()的作用是獲取哈希嗎,也稱為散列碼;它實際上是回傳一個int整數,這個哈希碼的作用是確定該物件在哈希表中的索引位置,hashCode()定義在JDK的Object類中,這就意味著Java中任何類都包含hashCode()函式
散串列存盤的是鍵值對(key-value),它的特點是:能根據“鍵”快速的檢索出對應的“值”,這其中就利用到了散列碼!(可以快速找到所需要的物件)
為什么要有hashCode()
我們以“HashSet 如何檢查重復”為例子來說明為什么要有 hashCode:
當你把物件加入HashSet時,HashSet會先計算物件的hashCode值來判斷物件加入的位置,同時也會與其他已經加入的物件的 hashCode值作比較,如果沒有相符的hashCode,HashSet會假設物件沒有重復出現,但是如果發現有相同 hashCode值的物件,這時會呼叫 equals()方法來檢查 hashCode相等的物件是否真的相同,如果兩者相同,HashSet 就不會讓其加入操作成功,如果不同的話,就會重新散列到其他位置
hashCode()與equals()的相關規定
如果兩個物件相等,則hashcode一定相等
兩個物件相等,對兩個物件分別呼叫equals回傳都是true
兩個物件有相同的hashcode值,但是他們不一定相等
因此,equals()方法被覆寫,則hashCode()值也必須被覆寫
hashCode()默認行為是對堆上的物件產生獨特的值,如果沒有重寫hashCode(),則該class兩個物件,無論如何都不會相等(即使這兩個物件指向相同的資料)
物件的相等與指向他們的參考相等,兩者有什么不同?
物件的相等 比的是記憶體中存放的內容是否相等而 參考相等 比較的是他們指向的記憶體地址是否相等
==和equals?
- ==:它的作用是判斷兩個物件的地址是不是相等的,即,判斷兩個物件是不是同一個物件(基本的資料型別**比較的是值,參考資料型別**比較的是記憶體地址)
- equals():它的作用也是判斷兩個物件是否相等,但它一般有兩種使用情況
- 類沒有覆寫equals()方法,則通過equals()比較該類的兩個物件時,等價通過**==**比較這兩個物件
- 類覆寫了**equals()方法,一般,我們都覆寫equals()**放方法來判斷兩個物件內容是否相等,若他們的內容相等,則回傳true
注意:String中的equals方法是被重寫過的,因為Object的equals方法比較的物件的記憶體地址,而String的equals方法比較的是物件的值
當創建String型別的物件時,虛擬機會在常量池中查找有么有已經存在的值和要創建的值相同的物件,如果有就把它賦值給當前參考,如果沒有就在常量池中創建一個String物件
資料型別
java的基本資料型別
| 資料型別 | 記憶體大小 | 默認值 | 取值范圍 |
|---|---|---|---|
| byte | 1B | (byte)0 | -128 ~ 127 |
| short | 2B | (short)0 | -215 ~ 215-1 |
| int | 4B | 0 | -231 ~ 231-1 |
| long | 8B | 0L | -263 ~ 263-1 |
| float | 4B | 0.0F | ±3.4E+38(有效位數 6~7 位) |
| double | 8B | 0.0D | ±1.7E+308(有效位數 15 位) |
| char | 英文1B,中文UTF-8占3B,GBK占2B | ‘\u0000’ | ‘\u0000’ ~ ‘\uFFFF’ |
| boolean | 單個變數4B/陣列1B | false | true、false |
JVM沒有boolean賦值的專用位元組碼指令,
boolean f = false就是使用 ICONST_0 即常數 0 賦值,單個 boolean 變數用 int 代替,boolean 陣列會編碼成 byte 陣列
包裝類
每個基本資料型別都對應一個包裝類,除了int和char對應Integer和Character外,其余基本資料型別的包裝類都是首字母大寫
-
自動裝箱:將基本型別用它們對應的參考型別包裝起來
-
自動拆箱:將包裝型別轉換為基本資料型別
int和Integer區別
Java是一個近乎純潔的面向物件的編程語言,但是為了編程方便還是引入了基本資料型別,但是為了能夠將這些基本資料型別當做物件操作,Java為每一個基本資料型別都引入了對應的包裝型別(wrapper class)),int 的包裝類就是 Integer,從 Java 5 開始引入了自動裝箱/拆箱機制,使得二者可以相互轉換
Java 為每個原始型別提供了包裝型別:
原始型別: boolean,char,byte,short,int,long,float,double
包裝型別:Boolean,Character,Byte,Short,Integer,Long,Float,Double
Integer a = 127和Integer b = 127相等嗎
對于物件參考型別:==比較的是物件的記憶體地址,
對于基本資料型別:==比較的是值
如果整型字面量的值在**-128到127之間**,那么自動裝箱時不會new新的Integer物件,而是直接參考常量池中的Integer物件,超過范圍 a1==b1的結果是false
public static void main(String[] args) {
Integer a = new Integer(3);
Integer b = 3; // 將3自動裝箱成Integer型別
int c = 3;
System.out.println(a == b); // false 兩個參考沒有參考同一物件
System.out.println(a == c); // true a自動拆箱成int型別再和c比較
System.out.println(b == c); // true
Integer a1 = 128;
Integer b1 = 128;
System.out.println(a1 == b1); // false
Integer a2 = 127;
Integer b2 = 127;
System.out.println(a2 == b2); // true
}
String
字串拼接的方式有哪些
- 直接用
+,底層用 StringBuilder 實作,只適用小數量,如果在回圈中使用+拼接,相當于不斷創建新的 StringBuilder 物件再轉換成 String 物件,效率極差 - 使用 String 的 concat 方法,該方法中使用
Arrays.copyOf創建一個新的字符陣列 buf 并將當前字串 value 陣列的值拷貝到 buf 中,buf 長度 = 當前字串長度 + 拼接字串長度,之后呼叫getChars方法使用System.arraycopy將拼接字串的值也拷貝到 buf 陣列,最后用 buf 作為構造引數 new 一個新的 String 物件回傳,效率稍高于直接使用+ - 使用 StringBuilder 或 StringBuffer,兩者的
append方法都繼承自 AbstractStringBuilder,該方法首先使用Arrays.copyOf確定新的字符陣列容量,再呼叫getChars方法使用System.arraycopy將新的值追加到陣列中,StringBuilder 是 JDK5 引入的,效率高但執行緒不安全,StringBuffer 使用 synchronized 保證執行緒安全
String a = “a” + new String(“b”)創建了幾個物件?
常量和常量拼接仍是常量,結果在常量池,只要有變數參與拼接結果就是變數,存在堆
使用字面量時只創建一個常量池中的常量,使用 new 時如果常量池中沒有該值就會在常量池中新創建,再在堆中創建一個物件參考常量池中常量,因此 String a = "a" + new String("b") 會創建四個物件,常量池中的 a 和 b,堆中的 b 和堆中的 ab
StringBuffer和StringBuilder的區別?
可變性
-
String類中使用字符陣列保存字符,
private final char value[],所以String物件是不可變的, -
StringBuilder與StringBuffer都繼承自
AbstractStringBuilder類,在AbstractStringBuilder中也是使用字符陣列保存字串
執行緒安全性
- String中的物件是不可變的,也就可以理解常量,執行緒安全,
AbstractStringBuilder是StringBuilder與StringBuffer的公共父類,StringBuffer對方法加了同步鎖或者對呼叫的方法加了同步鎖,所以是執行緒安全的,StringBuilder并沒有對方法進行加同步鎖,所以是非執行緒安全的
性能
- 每次對String型別進行改變的時候,都會生成一個新的String物件,然后將指向新的String物件,
- StringBuffer每次都會對StringBuffer進行操作,而不是生成新的物件并改變物件的參考,相同情況下使用StringBuilder相比使用StringBuffer僅能獲得10%~15% 左右的性能提升,但卻要冒多執行緒不安全的風險
總結
- 如果操作少量的資料使用String
- 單執行緒操作大量資料使用StringBuilder
- 多執行緒操作大量資料使用StringBuffer
switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上?
在Java5以前,switch(expr)中,expr只能是byte、short、char、int,從java5開始,java中引入了列舉型別,expr也可以是enum型別,從Java7開始,expr還可以是字串(String),但是long不支持
final關鍵字
- 修飾變數
凡是對成員變數或者區域變數(在方法中的或者代碼塊中的變數稱為本地變數)宣告為final的都叫做final變數,final變數經常和static關鍵字一起使用,作為常量
final修飾的基本資料的變數時,必須賦予初始值且不能變修飾參考變數時,該參考變數不能在指向其他物件
當final修飾基本資料型別變數時不賦予初始值以及參考變數指向其他物件時就會報錯
當final修飾基本資料型別變數被改變時,就會報錯
- 修飾方法
final也可以宣告方法,方法上面加上final關鍵字,代表這個方法不可以被子類方法重寫,如果你認為一個方法的功能足夠完整了,子類不需要改變的話,你也可以宣告此方法為final,final方法比非final方法要快,因為在編譯的時候已經靜態系結了,不需要在運行時在進行系結
- 修飾類
使用final修飾的類叫做final類,final類通常功能是完整的,他們不能被繼承,Java中有許多類是final的,如String,Integer以及其他包裝類
final、finally、finalize 有什么區別?
final可以修飾類、變數、方法,修飾類表示該類不能被繼承、修飾方法表示該方法不能被重寫、修飾變數表示該變數是一個常量不能被重新賦值,
finally一般作用在try-catch代碼塊中,在處理例外的時候,通常我們將一定要執行的代碼方法finally代碼塊中,表示不管是否出現例外,該代碼塊都會執行,一般用來存放一些關閉資源的代碼,
finalize是一個方法,屬于Object類的一個方法,而Object類是所有類的父類,Java 中允許使用 finalize()方法在垃圾收集器將物件從記憶體中清除出去之前做必要的清理作業,
注解
注解的概念
注解(Annotation)是Java提供的設定程式中元素的關聯資訊和元資料(MetaData)的方法,他是一個介面,程式可以通過反射獲取指定程式中元素的注解物件,然后通過該注解物件獲取注解中的元資料資訊
什么是注解?什么是元注解?
- 注解:是一種標識,使類或借口附加額外的資訊,幫助編譯器和JVM完成一些特定的功能,例如
@Override標識一個方法是重寫方法, - 元注解:元注解是自定義注解的注解:
@Target:約束作用位置,值是ElementType列舉常量,包括 METHOD 方法、VARIABLE 變數、TYPE 類/介面、PARAMETER 方法引數、CONSTRUCTORS 構造方法和 LOACL_VARIABLE 區域變數等@Retention:約束生命周期- SOURCE:在源檔案中有效,即源檔案中被保留
- CLASS:在Class檔案中有效,即在Class檔案中保留
- RUNTIME:在運行時有效,即在運行時保留
@Documented:表明這個注解應該被javadoc工具記錄,因此可以為javadoc類的工具檔案化@Inherited:是一個標記注解,表明某個被標注的型別是被繼承的,如果有一個使用了@Inherited修飾的Annotation被用于一個Class,則這個注解將被用于該Class類
注解處理器
注解用于描述元資料的資訊,使用的重點在于對注解處理器的定義,JavaSE5擴展了反射機制的API,以幫助程式員快速構造自定義注解處理器,對注解的使用一般包含定義及使用注解介面,我們一般通過封裝統一的注解工具來使用注解
定義注解
/**
* @author :zsy
* @date :Created 2021/6/12 14:48
* @description:
*/
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface FruitProvider {
//供應商編號
public int id() default -1;
//供應商名稱
public String name() default "";
//供應商地址
public String address() default "";
}
使用注解介面
定義一個Apple類,并通過注解方式定義了一個屬性
/**
* @author :zsy
* @date :Created 2021/6/12 14:51
* @description:蘋果
*/
@Setter
@Getter
public class Apple {
@FruitProvider(id = 1, name = "陜西商洛", address = "陜西省西安市")
private String appleProvider;
}
定義注解處理器
通過反射資訊獲取注解資料
/**
* @author :zsy
* @date :Created 2021/6/12 14:53
* @description:注解處理器
*/
public class FruitInfoUtil {
public static void getFruitInfo(Class<?> clazz) {
System.out.println("供應商資訊");
Field[] declaredFields = clazz.getDeclaredFields();
for (Field declaredField : declaredFields) {
FruitProvider annotation = declaredField.getAnnotation(FruitProvider.class);
System.out.println("供應商編號:" + annotation.id());
System.out.println("供應商姓名:" + annotation.name());
System.out.println("供應商地址:" + annotation.address());
System.out.println(annotation);
}
}
}
測驗
/**
* @author :zsy
* @date :Created 2021/6/12 14:54
* @description:
*/
public class Test {
public static void main(String[] args) {
FruitInfoUtil.getFruitInfo(Apple.class);
}
}
供應商資訊
供應商編號:1
供應商姓名:陜西商洛
供應商地址:陜西省西安市
@注解.FruitProvider(name=陜西商洛, address=陜西省西安市, id=1)
類
內部類
定義在類內部的類被稱為內部類,內部類根據不同的定義方式,可以分為靜態內部類、成員內部類、區域內部類和匿名內部類
靜態內部類
定義在類內部的靜態類,就是靜態內部類
靜態內部類可以訪問外部類的靜態變數和方法;在靜態內部類中可以定義靜態變數、靜態方法、構造反函式等;靜態內部類通過外部類.靜態內部類的方式呼叫
靜態內部類可以訪問外部類所有的靜態變數,而不可訪問外部類的非靜態變數;靜態內部類的創建方式,new 外部類.靜態內部類(),如下
/**
* @author :zsy
* @date :Created 2021/6/12 15:07
* @description: 靜態內部類
*/
public class OuterClass {
private static String className = "StaticInnerClass";
public static class StaticInnerClass {
public void getClassName() {
System.out.println("className:" + className);
}
}
//呼叫靜態內部類
public static void main(String[] args) {
StaticInnerClass staticInnerClass = new StaticInnerClass();
staticInnerClass.getClassName();
}
}
Java集合類中HashMap在內部維護了一個靜態內部類Node陣列用于存放元素,Node元素對使用者是透明的,像這種和外部類關系密切且不依賴外部類實體得嘞,可以使用靜態內部類
成員內部類
定義在類內部,成員位置上的非靜態類,就是成員內部類,
成員內部內部類不能定義靜態方法和變數(final修飾除外),因為成員內部類是非靜態的,而在Java的非靜態代碼塊中不能定義靜態方法和靜態變數
成員內部類可以訪問外部類所有的變數和方法,包括靜態和非靜態,私有和公有,成員內部類依賴于外部類的實體,它的創建方式外部類實體.new 內部類()
/**
* @author :zsy
* @date :Created 2021/6/12 15:16
* @description:成員內部類
*/
public class OutClass {
private static int a = 12;
private int b = 2;
public class MemberInnerClass {
public void print() {
System.out.println(a);
System.out.println(b);
}
}
public static void main(String[] args) {
OutClass outClass = new OutClass();
MemberInnerClass memberInnerClass = outClass.new MemberInnerClass();
memberInnerClass.print();
}
}
區域內部類
定義在方法中的內部類,就是區域內部類
當一個類只需要在某個方法中使用特定的類時,可以通過區域內部類來優雅的實作
區域內部類的創建方式,在對應方法內,new 內部類()
/**
* @author :zsy
* @date :Created 2021/6/12 15:26
* @description:區域內部類
*/
public class OutClass {
private static int a;
private int b;
public void printClassTest(final int c) {
final int d = 1;
class PastClass {
public void print() {
System.out.println(c);
}
}
PastClass pastClass = new PastClass();
pastClass.print();
}
public static void main(String[] args) {
OutClass outClass = new OutClass();
outClass.printClassTest(10);
}
}
匿名內部類
匿名內部類就是沒有名字的內部類,日常開發中使用的比較多,
匿名內部了通過繼承一個父類或者實作一個介面的方式直接定義并使用的類,匿名內部類沒有class關鍵字,這是應為匿名內部類直接使用new生成一個物件參考
/**
* @author :zsy
* @date :Created 2021/6/12 15:38
* @description:匿名內部類
*/
public class Worker {
public void work() {
// lamda ((Service) () -> System.out.println("工人正在作業....")).doSome();
new Service() {
@Override
public void doSome() {
System.out.println("工人正在作業....");
}
}.doSome();
}
public static void main(String[] args) {
Worker worker = new Worker();
worker.work();
}
}
interface Service {
void doSome();
}
匿名內部類的特點
- 匿名內部類必須繼承一個抽象類或者實作一個介面
- 匿名內部類不能定義任何靜態成員和靜態方法
- 當所在的方法的形參需要被匿名內部類使用時,必須宣告為 final
- 匿名內部類不能是抽象的,它必須要實作繼承的類或者實作的介面的所有抽象方法
總結
內部類的優點
- 一個內部類物件可以訪問創建它的外部物件的內容,包括私有資料
- 內部類不為同一個包的其他類所見,具有很好的封裝性
- 內部類有效實作了多重繼承,優化了java單繼承的缺陷
- 匿名內部類可以很方便的定義回呼
應用場景
- 一些多演算法場合
- 解決一些非面向物件的陳述句塊
- 適當使用內部類,使得代碼更加靈活和富有擴展性
- 當某個類除了它的外部類,不再被其他的類使用時
區域內部類和匿名內部類訪問區域變數的時候,為什么變數必須要加上final?
因為生命周期不一樣,區域變數直接存盤在堆疊中,當方法執行結束后,非final的區域變數就被銷毀了,而區域內部類對區域變數的參考依然存在,如果區域內部類要呼叫區域變數時就會出錯,加了final,可以確保區域內部類使用的變數與外層的區域變數區分開,解決了這個問題
/**
* @author :zsy
* @date :Created 2021/6/12 15:50
* @description:測驗final
*/
public class OuterClass {
private int age = 12;
class Inner {
private int age = 13;
public void print() {
int age = 14;
System.out.println("區域變數:" + age);
System.out.println("內部類變數:" + this.age);
System.out.println("外部類變數:" + OuterClass.this.age);
}
}
public static void main(String[] args) {
OuterClass outerClass = new OuterClass();
outerClass.new Inner().print();
}
}
抽象類和介面的區別?
介面和抽象類對物體類進行更高層次的抽象,僅定義公共行為和特征
| 語法維度 | 抽象類 | 介面 |
|---|---|---|
| 成員變數 | 無特殊要求 | 默認public static final常量 |
| 構造方法 | 有構造方法,不能實體化 | 沒有構造方法,不能實體化 |
| 方法 | 抽象類可以沒有抽象方法,但有抽象方法的一定是抽象類 | 默認public abstract,JDK8支持默認/靜態方法,JDK9支持私有方法 |
| 繼承 | 單繼承 | 多繼承 |
抽象類和介面怎么選擇?
- 抽象類體現is-a關系,介面體現can-do關系,與介面相比,抽象類是對同類事務相對具體的抽象
- 抽象類是模板設計,包含一組具體特征,例如某汽車,底盤、控制電路等是抽象出來的共同特征,但內飾、顯示屏、座椅材質可以根據不同級別配置存在不同實作
- 介面是契約式設計,是開放的,定義了方法名、引數、回傳值、拋出的例外型別,誰都可以實作它,但必須遵守介面的約定,例如所有車輛都必須實作剎車這種強制規范
- 介面是頂級類,抽象類在介面下面的第二層,對介面進行了組合,然后實作了部分介面,當糾結定義介面和抽象類時,推薦定義為介面,遵循介面隔離原則,按維度劃分成多個介面,再利用抽象類去實作這些,方便后續的擴展和重構
泛型
什么是泛型,有什么用?
泛型的本質是引數化型別,解決不確定物件具體型別的問題,泛型在定義處只具備執行Object方法的能力
泛型的好處:
- 型別安全,放置什么出來就是什么,不存在 ClassCastException
- 提升可讀性,編碼階段就顯示知道泛型集合、泛型方法等處理的物件型別
- 代碼重用,合并了同型別的處理代碼
泛型標記和泛型限定
泛
| 泛型標記 | 說明 |
|---|---|
| E-Element | 在集合中使用,表示集合中存放的元素 |
| T-Type | 表示Java類,包括基本的類和我們定義的類 |
| K-Key | 表示鍵,比如Map的key |
| V-Value | 表示值 |
| N-Number | 表示資料型別 |
| ? | 表示不確定型別 |
泛型限定
- 對泛型上限的限定
<? extends T>:表示該通配符所代表的型別是T型別的子類或者幾口T的子介面 - 對翻新下限限定
<? super T>:表示該通配符所代表的型別是T型別的父類或者父介面
泛型擦除是什么?
泛型用于編譯階段,編譯后位元組碼檔案不包括泛型型別資訊,因為虛擬機沒有泛型型別物件,所以編譯時,型別引數會被編譯器時去掉,這個程序稱為型別擦除
例如:編碼時定義 List<Object> 或 List<String>,在編譯后都會變成 List ,泛型附加的型別資訊對JVM來說是不可見的
型別擦除的程序,首先查找用來替換型別引數的具體類(一般為Object),如果指定了型別引數的上界,則以上界作為替換時的具體類,然后把代碼中的型別引數都替換為具體的型別
例如:<T extends A>會使用A型別替換T
如果有多個限定型別就會替換為第一個限定型別
例如: <T extends A & B> 會使用 A 型別替換 T
Java集合容器面試題
常用的集合類
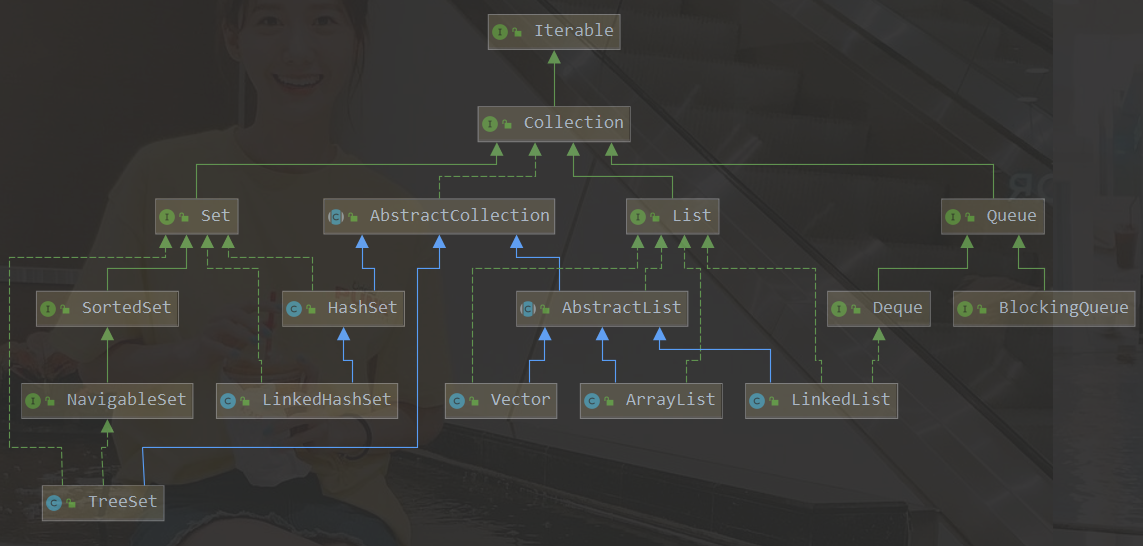
Collection介面的子類包括:Set介面、Queue介面和List介面
- Set介面(無序:元素存入和取出的順序可能不一致)的實作類主要有:HashSet、TreeSet、LinkedHashSet
- Queue介面包含Deque和BlockingQueue
- List介面(有序:元素存入集合的順序和取出順序一致)的實作類:ArrayList、LinkedList、Stack以及Vector
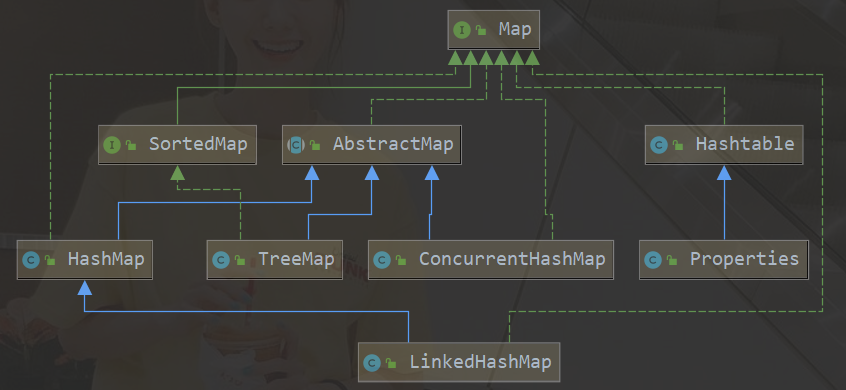
Map介面:鍵值對集合,存盤鍵、值之間的映射,Key無序,唯一;value,不要求有序,允許重復
實作類:HashMap、TreeMap、HashTable、ConcurrentHashMap以及Properties
List介面
談談ArrayList
ArrayList是容量可變的非執行緒安全串列,使用陣列實作,集合擴容時會創建更大的陣列,把原有的陣列復制到新的陣列中,支持對元素的快速隨機訪問,但插入與洗掉的速度很慢,ArrayList實作了RandomAcess標記介面,如果一個類實作了這個介面,證明使用索引遍歷比迭代器更快
ArrayList主要底層實作是Object[]elementData,被transient修飾,重寫了writeObject()方法,序列化時會呼叫 writeObject()寫入流,反序列化時呼叫 readObject()重新賦值到新物件的 elementData
writeObject()
先呼叫 defaultWriteObject() 方法序列化 ArrayList 中的非 transient 元素,然后遍歷 elementData,只序列化已存入的元素,這樣既加快了序列化的速度,又減小了序列化之后的檔案大小
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
size是實際的大小,elementData大小等于size
**modCount **記錄了 ArrayList 結構性變化的次數,繼承自 AbstractList,所有涉及結構變化的方法都會增加該值,expectedModCount 是迭代器初始化時記錄的 modCount 值,每次訪問新元素時都會檢查 modCount 和 expectedModCount 是否相等,不相等就會拋出例外,這種機制叫做 fail-fast,所有集合類都有這種機制
初始容量
初始容量為10
JDK1.7時,相當于餓漢式,第一次創建無參構造器時,就創建一個初始容量為10的陣列
JDK1.8時,相當于懶漢式,只有當整整add時才會分配默認的初始容量
擴容
ArrayList的擴容閾值為1.5
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
擴容程序:
- 假設有一個長度為10的陣列,此時新增加一個元素,發現ArrayList已經滿了,需要擴容
- 重新定義一個長度為10 * 1.5的陣列
- 將原陣列的資料原封不動的復制到新的陣列
- 將ArrayList的地址指向新陣列
如何實作陣列和List之間的轉換
陣列轉List:使用Arrays.asList()進行轉換
List轉陣列:使用List自帶的toArray()方法
談談LinkedList
LinkedList的本質是雙向鏈表,AbstractList 外還實作了 Deque 介面,這個介面具有佇列和堆疊的性質,成員變數被 transient 修飾,原理和 ArrayList 類似
LinkedList 包含三個重要的成員:size、first 和 last,size 是雙向鏈表中節點的個數,first 和 last 分別指向首尾節點的參考
LinkedList的優點在于可以將零碎的記憶體空間通過附加參考的方式關聯起來,形成鏈路順序查找的線性結構,記憶體利用率高
ArrayList和LinkedList的區別
-
資料結構實作:ArrayList是動態陣列的資料結構實作,而LinkedList是雙向鏈表的資料結構實作
-
ArrayList的查詢和訪問速度較快,但是新增、洗掉的速度較慢,LinkedList的查找和訪問元素到的速度較慢,但是它的新增,洗掉速度較快
-
ArrayList需要一份連續的記憶體空間,LinkedList不需要連續的記憶體空間(特別地,當創建一個ArrayList集合的時候,連續的記憶體空間必須要大于等于創建的容量)
-
兩者都是執行緒不安全的
綜合來說,在需要頻繁讀取集合中的元素時,更推薦使用 ArrayList,而在插入和洗掉操作較多時,更推薦使用 LinkedList
ArrayList和Vector的區別
| 區別 | ArrayList | Vector |
|---|---|---|
| 執行緒安全 | 非執行緒安全 | 執行緒安全 |
| 性能 | 優 | 差 |
| 擴容 | ArrayList擴容1.5 | Vector擴容2倍 |
Vector類的所有方法都是同步的,可以由兩個執行緒安全地訪問一個Vector物件、但是一個執行緒訪問Vector的話代碼要在同步操作上耗費大量的時間
Arraylist不是同步的,所以在不需要保證執行緒安全時時建議使用Arraylist
快速失敗(fail-fast)
是Java集合的一種錯誤檢測機制,當多個執行緒對集合進行結構上的改變操作時,有可能會產生fail-fast機制
迭代器在遍歷時直接訪問集合中的內容,并且在遍歷程序中使用一個 modCount 變數,集合在被遍歷期間如果內容發生變化,就會改變modCount的值,每當迭代器使用hashNext()/next()遍歷下一個元素之前,都會檢測modCount變數是否為expectedmodCount值,是的話就回傳遍歷;否則拋出例外,終止遍歷
安全失敗(fail-safe)
采用安全失敗機制的集合容器,在比那里時不是直接在集合內容上訪問的,而是先復制原有的集合內容,在拷貝的集合上進行遍歷
原理:由于迭代時是對原集合的拷貝進行遍歷,所以在遍歷程序中對原集合所作的修改并不能被迭代器檢測到,所以不會觸發ConcurrentModificationException
缺點:基于拷貝內容的優點是避免了ConcurrentModificationException,但同樣地,迭代器并不能訪問到修改后的內容,即:迭代器遍歷的是開始遍歷那一刻拿到的集合拷貝,在遍歷期間原集合發生的修改迭代器是不知道的
場景:java.util.concurrent包下的容器都是安全失敗,可以在多執行緒下并發使用,并發修改,
怎么確保一個集合不被修改
可以使用 Collections. unmodifiableCollection(Collection c) 方法來創建一個只讀集合,這樣改變集合的任何操作都會拋出 Java. lang. UnsupportedOperationException 例外
迭代器
Iterator
Iterator介面提供遍歷任何Collection的介面,我們可以從一個 Collection 中使用迭代器方法來獲取迭代器實體,迭代器取代了 Java 集合框架中的 Enumeration,迭代器允許呼叫者在迭代程序中移除元素
迭代器的特點:只能單向遍歷,但是更加安全,因為它可以擔保,在當前遍歷的集合元素被更改的時候,就會拋出ConcurrentModificationException 例外
如何邊遍歷邊洗掉Collection中的元素
Iterator<Integer> it = list.iterator();
while(it.hasNext()){
*// do something*
it.remove();
}
錯誤寫法:list.remove(i)
Iterator 和 ListIterator 有什么區別
Iterator 可以遍歷 Set 和 List 集合,而 ListIterator 只能遍歷 List
Iterator 只能單向遍歷,而 ListIterator 可以雙向遍歷(向前/后遍歷)
ListIterator 實作 Iterator 介面,然后添加了一些額外的功能,比如添加一個元素、替換一個元素、獲取前面或后面元素的索引位置
Set介面
談談HashSet
HashSet是基于HashMap實作的,HashSet的值存放與HashMap的key上,HashMap的value統一為PRESENT,基本上都是直接呼叫底層的HashMap相關方法來完成的
private static final Object PRESENT = new Object();
HashMap先比較hashCode,再比較equals,所以key是不會重復的
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
TreeSet同TreeMap
Map介面
談談TreeMap
TreeMap基于紅黑樹實作,增刪改查的平均和最差時間復雜度均為O(logn),最大的特點是Key有序,Key必須實作Comparable介面或者提供Comparator比較器,所以Key不能為null
HashMap依靠hashCode和equals去重,而TreeMap依靠Comparable或者Comparator,TreeMap 排序時,如果比較器不為空就會優先使用比較器的 compare 方法,否則使用 Key 實作的 Comparable 的 compareTo 方法,兩者都不滿足會拋出例外
紅黑樹的操作,HashMap中會有介紹
Comparable和Comparator介面的區別
Comparable一般都是通過類去實作介面,在類內部去實作comparaTo方法,所以一般人也稱為內部比較器,實作了Comparable介面的類有一個共同特點,就是這些類可以和自己比較,至于具體和另一個實作了Comparable介面的類如何比較,則依賴compareTo方法的實作
public interface Comparable<T> {
public int compareTo(T o);
}
Comparator一般都是寫一個類去實作Comparator介面,讓這個類作為專用的比較器,在需要比較器的地方當做引數傳進去,外比較器, 一個物件實作了Comparable介面,但是開發者認為compareTo方法中的比較方式并不是自己想要的那種比較方式
public interface Comparator<T> {
int compare(T o1, T o2);
}
升序降序記法
這里o1表示位于前面的物件,o2表示后面的物件
回傳-1(或負數),表示不需要交換01和02的位置,o1排在o2前面,asc 回傳1(或正數),表示需要交換01和02的位置,o1排在o2后面,desc
總結
1、如果實作類沒有實作Comparable介面,又想對兩個類進行比較(或者實作類實作了Comparable介面,但是對compareTo方法內的比較演算法不滿意),那么可以實作Comparator介面,自定義一個比較器,寫比較演算法
2、實作Comparable介面的方式比實作Comparator介面的耦合性 要強一些,如果要修改比較演算法,要修改Comparable介面的實作類,而實作Comparator的類是在外部進行比較的,不需要對實作類有任何修 改,從這個角度說,其實有些不太好,尤其在我們將實作類的.class檔案打成一個.jar檔案提供給開發者使用的時候,實際上實作Comparator 介面的方式后面會寫到就是一種典型的策略模式,
HashMap
HashMap、Hashtable、ConcurrentHashMap(1.7、1.8)原始碼分析 + 紅黑樹
Queue
佇列的特點
佇列是一種比較特殊的線性結構,它只允許在表的前端(front)進行洗掉操作,而在表的后端(rear)進行插入操作,進行插入操作的端稱為隊尾,進行洗掉操作的端稱為隊頭,
佇列中最先插入的元素也將最先被洗掉,對應的最后插入的元素將最后被洗掉,因此佇列又稱為“先進先出”(FIFO—first in first out)的線性表,與堆疊(FILO-first in last out)剛好相反
BlockingQueue
四組API
| 方式 | 拋出例外 | 不拋出例外,有回傳值 | 阻塞一直等待 | 超時等待 |
|---|---|---|---|---|
| 添加 | add | offer | put | offer(“c”,2, TimeUnit.SECONDS) |
| 洗掉 | remove | poll | take | poll(2,TimeUnit.SECONDS) |
| 判斷對列首元素 | element | peek | - | - |
IO與NIO
JavaIO流
阻塞(Block)與非阻塞(Non-Block)
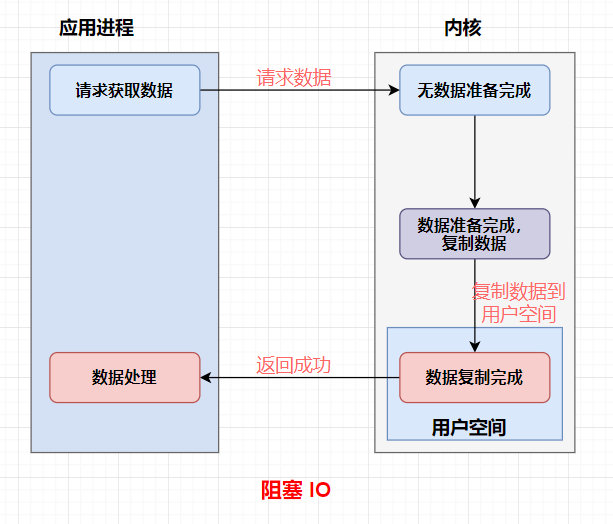
阻塞和非阻塞是行程在訪問資料的時候,資料是否準備就緒的一種處理方式,
當資料沒有準備的時候
阻塞:往往需要等待緩沖區中的資料準備好之后才處理其他的事情,否則一直等待,
非阻塞:當我們的行程訪問我們的資料緩沖區的時候,如果資料沒有準備好,則直接回傳,不會等待,如果資料已經準備好,也直接回傳
阻塞IO
非阻塞IO
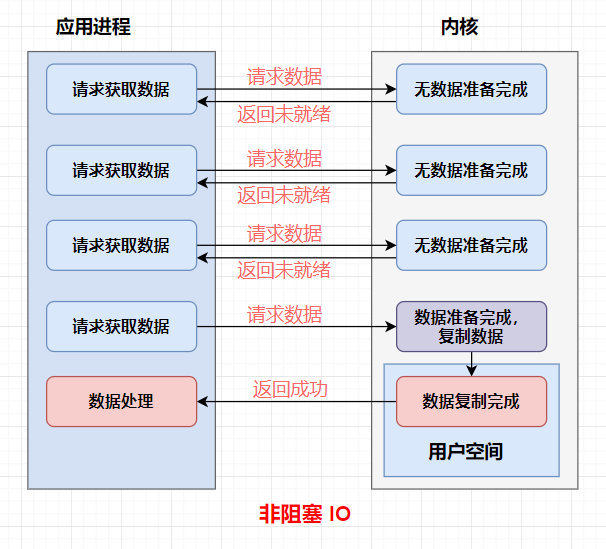
同步(Synchronous)與異步(Asynchronous)
同步和異步都是基于應用程式和作業系統處理IO時間所采用的方式
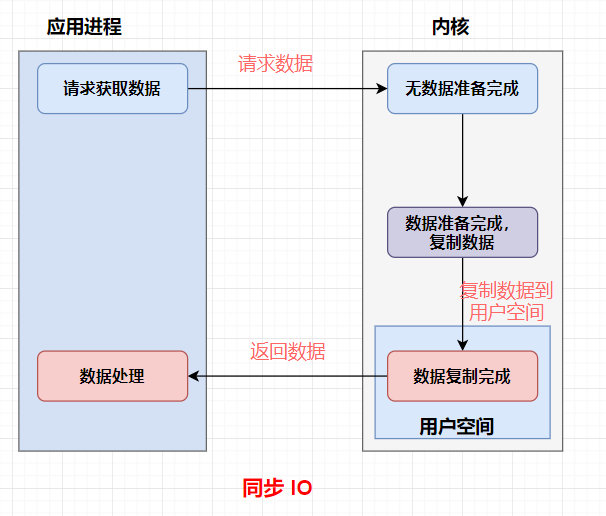
同步:是應用程式要直接參與IO讀寫操作
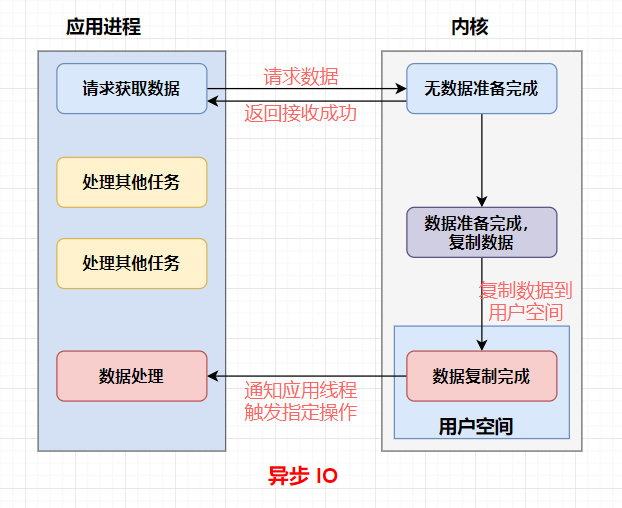
異步:所有的IO讀寫都交給作業系統去處理,應用程式只需要等待通知,
同步方式在處理 IO 事件的時候,必須阻塞在某個方法上面等待我們的 IO 事件完成(阻塞 IO 事件或者通過輪詢 IO事件的方式),對于異步來說,所有的 IO 讀寫都交給了作業系統,這個時候,我們可以去做其他的事情,并不需要去完成真正的 IO 操作,當操作完成 IO 后,會給我們的應用程式一個通知,
舉例
同步阻塞:普通水壺燒水,站在旁邊,主動看水開了沒有
同步非阻塞:去干點別的事,每過一段時間去看看水開了沒有,水沒開就走人
異步阻塞:站在旁邊,不會每過一段時間主動看水開了沒有,如果水開了,水壺自動通知他,
異步非阻塞:去干點別的事,如果水開了,水壺自動通知他,異步非阻塞
所以異步相比于同步帶來的好處就是在我們處理IO資料的時候,異步的方式我們可以把這部分等待所消耗的資源用于處理其他事務,提升我們服務自身的性能
同步IO
異步IO
總結
同步和異步是通信機制,阻塞和非阻塞是呼叫狀態
-
同步IO是用戶執行緒發起IO請求后需要等待或輪詢內核IO操作完成后才能繼續執行
-
異步IO是用戶執行緒發起IO請求后可以繼續執行,當內核IO操作完成后會通知用戶執行緒,或呼叫用戶執行緒注冊的回呼函式
-
阻塞IO是IO操作需要徹底完成后才能回傳用戶空間
-
非阻塞IO是IO操作呼叫后立即回傳一個狀態值,無需等待IO操作徹底完成
NIO模型
NIO(Non-blocking / New I/O)
NIO是一種同步非阻塞的IO模型,于 Java 1.4 中引入,對應 java.nio 包,提供了Channel、Selector、Buffer等抽象,NIO中的N可以理解為Non-blocking,不單純是 New,它支持面向緩沖的,基于通道的 I/O 操作方法,NIO提供了與傳統BIO模型中的Socket和ServerSocket相對應的SocketChannel和ServerSocketChannel兩種不同的套接字通道實作,兩種通道都支持阻塞和非阻塞兩種模式,對于高負載、高并發的(網路)應用,應使用 NIO 的非阻塞模式來開發
NIO的非阻塞模式,是一個執行緒從某通道發送請求讀取資料,但是它僅能得到目前可用的資料,如果目前沒有資料可用,就可以什么都不獲取,而不是保持執行緒阻塞,所以直到資料變得可以讀取之前,該執行緒可以繼續做其他的事情,非阻塞寫也是如此,一個執行緒請求寫入一些資料到某通道,但不需要等待它完全寫入,這個執行緒同時可以去做別的事情, 執行緒通常將非阻塞IO的空閑時間用于在其它通道上執行IO操作,所以一個單獨的執行緒現在可以管理多個輸入和輸出通道
NIO的特點
- 一個執行緒可以處理多個通道,減少執行緒數創建的數量
- 讀寫非阻塞,節約資源,沒有可寫\可讀資料時,不會發生阻塞導致執行緒資源的浪費
核心組件
Channel(通道)
Channel是一個雙向通道,與傳統IO操作只允許單向的讀寫不同的是,NIO的Channel允許在一個通道上進行讀和寫的操作,替換了傳統BIO中的Stream,不能直接訪問資料,要通過Buffer來讀取資料,也可和其他Channel互動
主要實作
FileChannel、SocketChannel、ServerSocketChannel、DatagramChannel
Buffer(緩沖區)
Buffer顧名思義,他是一個緩沖區,實際上是一個容器,一個連續陣列,Channel提供從檔案、網路讀取資料的渠道,但是讀寫的資料都必須經過Buffer
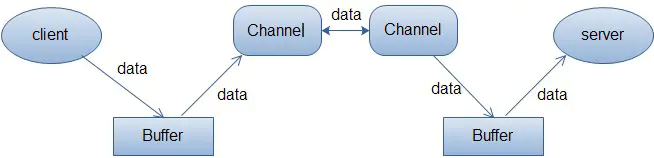
Buffer緩沖區本質是一塊可以寫入資料,然后可以從中讀取資料的記憶體這塊記憶體被包裝成NIO Buffer物件,并提供了一組方法,用來方便的訪問該模塊記憶體,為了理解Buffer的作業原理,需要熟悉它的三個屬性:
- position:下次讀寫資料的位置
- limit:本次讀寫的極限位置
- capacity:最大容量
使用步驟:向 Buffer 寫資料,呼叫 flip 方法轉為讀模式,從 Buffer 中讀資料,呼叫 clear 或 compact 方法清慷訓沖區
flip將寫轉為讀,底層實作原理把 position 置 0,并把 limit 設為當前的 position 值clear將讀轉為寫模式(用于讀完全部資料的情況,把 position 置 0,limit 設為 capacity)compact將讀轉為寫模式(用于存在未讀資料的情況,讓 position 指向未讀資料的下一個)
通道方向和 Buffer 方向相反,讀資料相當于向 Buffer 寫,寫資料相當于從 Buffer 讀
Selector(多路復用器)
輪詢檢查多個Channel的狀態,判斷注冊事件是否發生,即判斷Channel是否處于可讀或可寫狀態,適用前需要將Channel注冊到Selector中,注冊后會得到一個SelectionKey,通過SelectionKey獲取Channel和Selector的相關資訊
BIO模型
BIO(傳統IO)
- BIO是一個同步并阻塞的IO模式,傳統的
java.io包,它基于流模型實作,提供了我們最熟知的一些 IO 功能,比如File抽象、輸入輸出流等,互動方式是同步、阻塞的方式 - 在讀取輸入流或者寫入輸出流時,在讀、寫動作完成之前,執行緒會一直阻塞在那里,它們之間的呼叫是可靠的線性順序
- 服務器實作模式為一個連接請求對應一個執行緒,服務器需要為每一個客戶端請求創建一個執行緒,如果這個連接不做任何事會造成不必要的執行緒開銷,可以通過執行緒池改善,這種IO稱為偽異步IO,適用連接數目少且服務器資源多的場景
Java BIO與NIO比較
| IO模型 | BIO | NIO |
|---|---|---|
| 通信 | 面向流 | 面向緩沖 |
| 處理 | 阻塞IO | 非阻塞IO |
| 觸發 | 無 | 選擇器 |
AIO概念
AIO是JDK7引入的異步非阻塞IO,服務器實作模式為一個有效的請求對應一個執行緒,客戶端的IO請求都是由作業系統先完成IO操作后,再通知服務器應用來直接使用準備好的資料,適用連接數目多且連接時間長的場景
實作方式包括通過 Future 的 get 方法進行阻塞式呼叫以及實作 CompletionHandler 介面,重寫請求成功的回呼方法 completed 和請求失敗回呼方法 failed
JavaIO流分為哪幾種
- 按照流的流向分,可以分為輸入流和輸出流
- 按照操作單元劃分,可以分為位元組流和字符流
- 按照流的角色劃分為節點流和處理流
字符流一般用于文本檔案,位元組流一般用于影像或者其他檔案
字符流包括了字符輸入流Reader和字符輸出流Writer,位元組流包括位元組輸入流inputStream和位元組輸出流OutputStream,
字符流和位元組流都有對應的緩沖流,位元組流也可以分為字符流,緩沖流帶有一個8KB的緩沖陣列,可以提高流的讀寫效率,
除了緩沖流外還有過濾流FilterReader、字符陣列流CharArrayReader、位元組陣列流ByteArrayInputStream、檔案流FileInputStream

JDK8新特性
Lambda運算式
允許把函式作為引數傳遞到方法,簡化匿名內部類代碼
-
為什么要使用Lambda運算式
- 避免匿名內部類定義過多
- 可以代碼看起來很簡潔
-
函式式介面的定義
- 任何介面,如果只包含唯一一個抽象方法,那么他就是一個函式式介面
public interface Runnable { public abstract void run(); }- 對于函式式介面,我們可以通過Lambda運算式來創建它的介面物件
interface Love { void lambda(int a); } Love love = (int a) -> {...} -
Lambda運算式簡化
- 去掉引數型別
love = (a) -> {...}- 去掉括號
love = a -> {...}- 去掉花括號
love = a -> ...- 多個引數情況
love = (a, b, c) -> ...
函式式介面
輸入T型別回傳R型別
public interface Function<T, R> {
/**
* Applies this function to the given argument.
*
* @param t the function argument
* @return the function result
*/
R apply(T t);
實體
/**
* @author :zsy
* @date :Created 2021/4/21 19:26
* @description:函式式介面
*/
public class Demo1 {
public static void main(String[] args) {
Function<String, String> function = str -> {return str;};
System.out.println(function.apply("zhangsna"));
}
}
斷定性介面
輸入T型別回傳boolean型別
@FunctionalInterface
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
*
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
實體
/**
* @author :zsy
* @date :Created 2021/4/21 19:29
* @description:斷定性介面
*/
public class Demo2 {
public static void main(String[] args) {
Predicate<String> predicate = str -> {return str.isEmpty();};
predicate.test("zhangsan");
}
}
消費型介面
只要輸入型別,沒有回傳型別
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
供給性介面
只有回傳型別,沒有輸入型別
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
實體
/**
* @author :zsy
* @date :Created 2021/4/21 19:37
* @description:消費型介面和供給型介面
*/
public class Demo3 {
public static void main(String[] args) {
Consumer<String> consumer = o -> System.out.println(o);
Supplier<Integer> supplier = () -> 1024;
}
}
方法參考
可以參考已有類或物件的方法和構造方法,進一步簡化 lambda 運算式
介面
介面可以定義 default 修飾的默認方法,降低了介面升級的復雜性,還可以定義靜態方法,
注解
引入重復注解機制,相同注解在同地方可以宣告多次,注解作用范圍也進行了擴展,可作用于區域變數、泛型、方法例外等,
型別推測
加強了型別推測機制,使代碼更加簡潔,
Optional 類
處理空指標例外,提高代碼可讀性,
Stream 類
引入函式式編程風格,提供了很多功能,使代碼更加簡潔,方法包括 forEach 遍歷、count 統計個數、filter 按條件過濾、limit 取前 n 個元素、skip 跳過前 n 個元素、map 映射加工、concat 合并 stream 流等,
日期
增強了日期和時間 API,新的 java.time 包主要包含了處理日期、時間、日期/時間、時區、時刻和時鐘等操作,
JavaScript
提供了一個新的 JavaScript引擎,允許在 JVM上運行特定JavaScript 應用,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/287376.html
標籤:java