在進入具體的kafka應用設計之前我們先把kafka集群環境配置介紹一下,多節點kafka-cluster的安裝、配置非常簡單,所以應該不用太多篇幅就可以完成一個完整可用的kafka-cluster環境了:
1、安裝Kafka之前需要安裝zookeeper,無論zookeeper或者kafka,安裝步驟都很簡單,直接按照官方的安裝指引一步步進行就行了,我們把注意力還是放在它們的具體配置上吧,
2、kafka的配置集中在server.properties檔案里的幾個設定上:
1)broker.id=2
本kafka實體在多節點集群中的唯一編號為2
2)listeners=PLAINTEXT://130.90.27.123:9092,130.90.27.233:9092
kafka實體監聽埠
3)log.dirs=/usr/local/var/lib/kafka-logs
kafka日志檔案路徑
4)zookeeper.connect=130.90.27.123:2181,130.90.27.233:2181
zookeeper集群節點埠清單,kafka是自然集群模式的,只要組態檔中zookeeper.connect指向同一個zookeeper集群,代表所有kafka節點都屬于同一個kafka集群
3、zookeeper主要的功能是對kafka集群成員的控制管理,為了實作系統的安全和高可用性,zookeeper是一個仲裁模式的集群體系,為了實作多數裁定,zookeeper集群的節點數目必須是單數的,3-5個節點比較正常,
zookeeper組態檔zookeeper.properties里設定舉例如下:
假如server.1,server.2,server.3分別為同一個zookeeper-cluster里的節點
server.1
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=0
initLimit=5
syncLimit=2
tickTime=2000
# list of servers
server.1=0.0.0.0:2888:3888
server.2=<Ip of second server>:2888:3888
server.3=<ip of third server>:2888:3888
server.2
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=0
initLimit=5
syncLimit=2
tickTime=2000
# list of servers
server.1=<ip of first server>:3888
server.2=0.0.0.0:2888:3888
server.3=<ip of third server>:2888:3888
server.3
dataDir=/var/lib/zookeeper
clientPort=2181
maxClientCnxns=0
initLimit=5
syncLimit=2
tickTime=2000
# list of servers
server.1=<ip of first server>:3888
server.2=<ip of second server>:3888
server.3=0.0.0.0:2888:3888
kafka適合在大型集成應用系統中使用,一個分布式應用系統可能包括了多個底層集群系統,包括資料庫、搜索引擎、分布式訊息佇列、資料流集群等等,如何通過有效部署實作這些集群系統的集成也是一個值得考慮的問題,講到系統集成,首先想到的是http協議,http可以說是一種異類系統集成協議,是一種行業標準,拿一個大型應用軟體操作做例子,前端一般負責兩塊功能:
1、連接后臺業務邏輯系統進行業務互動,一般來講后臺業務決策是基于處理過的資料支持的
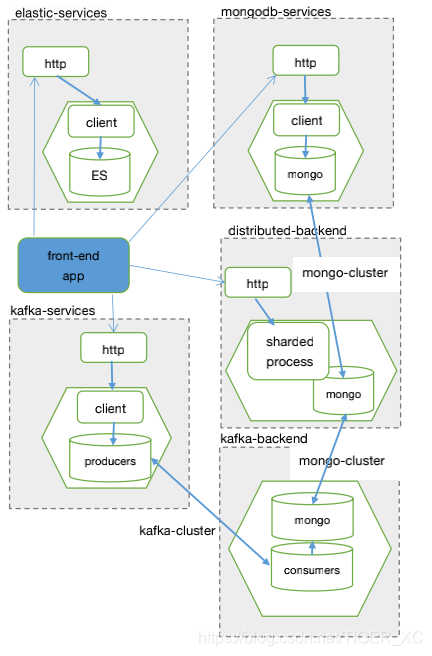
2、輸入商品及交易資料,這實際上是一個資料采集、過濾、加工處理的全程序,舉例:錄入一條交易資料、寫入資料庫、寫入搜索引擎索引、更新庫存數等等 ... 整個程序涉及到上面提到的幾個集群系統,如下圖:
??
![]() ??
??
從上面這個圖示可以看到:前端應用(app)主要是通過http分別與幾個集群系統對接的,也就是說app需要逐個通過http呼叫各系統api來實作特定的資料錄入,圖示中的系統如下:
1、elastic-services: 搜索引擎服務平臺
2、mongodb-services: 資料庫服務平臺
3、mongo-cluster: 資料庫集群節點連接
4、kafka-services: 訊息發布平臺
5、kafka-backend: 訊息消費及資料處理平臺
6、kafka-cluster: 訊息佇列集群節點連接
7、distributed-backend: 應用系統業務互動平臺
http方式系統集成的特點是目標系統之間耦合非常松散,實作了自由系統部署,最明顯的是各系統的客戶端可以分別部署,互不相關,假如上面這個app是個第三方軟體,比如是一個與其它企業資料交換的前端系統,那么這種http方式就非常適用,任何第三方系統,只要遵照協定的方式和資料格式就可以成為系統的一個集成部分,
但是,從大型系統資料安全的角度考慮:對企業內部系統來說,http集成方式存在諸多短板和風險,從下面幾個方面考慮:
1、負載均衡:http接入節點必須提供所有用戶的服務請求,超載會造成資料遺失
2、資料安全:任何一個集群系統http接入節點出現故障都會造成整體資料的不完整
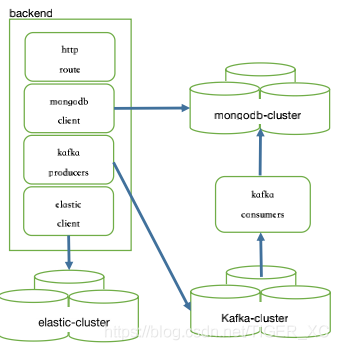
從資料錄入來說,整個流程的完結在成功的寫入資料庫,也就是說:一旦資料存入資料庫就代表該資料已經成功完成了所有相關處理,包括:寫入搜索索引、完成資料處理如庫存數更新等等,如果按http方式逐個呼叫api服務的話,任何環節出現問題都會造成資料的不完整,所以,更穩妥的做法應該是寫入資料庫和其它相關資料處理環節都在同一個節點完成,也就是說在一個包含資料庫客戶端的節點上應該部署所有相關集群系統的客戶端,這樣,只要節點運行正常,能寫入資料庫,就能保證完成相關資料處理的所有環節,從這個思路出發,可以得出下面的集群系統部署圖示:
?
![]() ??
??
按圖所示,整個資料錄入流程只需要呼叫一個http服務,資料保存到資料處理等所有環節都包含在同一項服務里(在backend自動實作),如此實作相關資料處理環節與資料庫寫入同步:能寫入資料庫代表節點運行正常,也就是說其它環節也同樣能順利完成,反之如節點系統發生例外,寫入資料庫及其它相關環節都同時無法完成,可以保證整體資料的完整性,
![]() ??
??
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/287536.html
標籤:Scala