
前言
今天我們就用scrapy爬一波知網的中國專利資料并做簡單的資料可視化分析唄,讓我們愉快地開始吧~
PS:本專案僅供學習交流,實踐本專案時煩請設定合理的下載延遲與爬取的專利資料量,避免給知網服務器帶來不必要的壓力,
開發工具
Python版本:3.6.4
相關模塊:
scrapy模塊;
fake_useragent模塊;
pyecharts模塊;
wordcloud模塊;
jieba模塊;
以及一些Python自帶的模塊,
環境搭建
安裝Python并添加到環境變數,pip安裝需要的相關模塊即可,
資料爬取
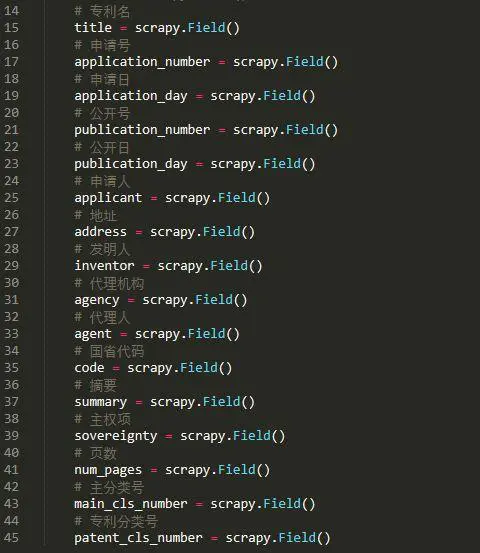
我們需要爬取的資料例如下圖所示:

即包括以下這些內容:
爬取思路:
我們可以很容易地發現每個專利的詳情頁url都是類似這樣的:
http://dbpub.cnki.net/grid2008/dbpub/Detail.aspx?DBName=SCPD年份&FileName=專利公開號&QueryID=4&CurRec=1
因此,只要改變專利公開號即可獲得對應專利的詳情頁url(經測驗,即使年份對不上也沒關系),從而獲得對應專利的資訊,具體而言代碼實作如下:
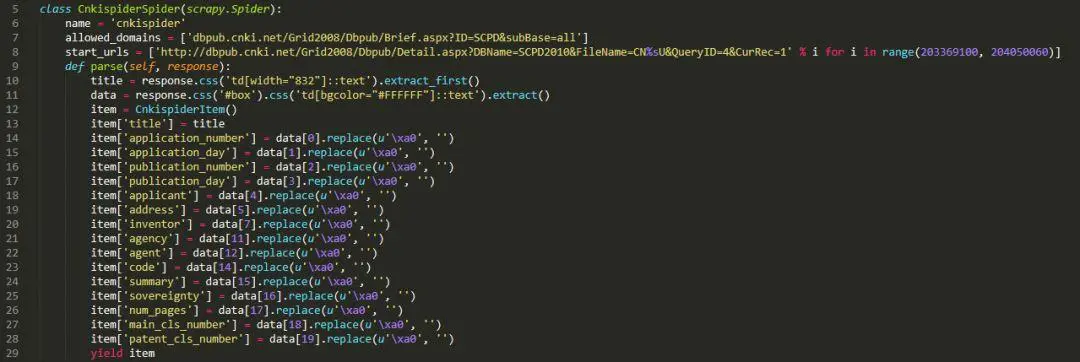
All done~完整源代碼詳見個人簡介相關檔案,
PS:代碼運行方式為運行main.py檔案,
資料可視化
為避免給知網服務器帶來不必要的壓力,這里我們只爬了2014年的一部分知網中國專利資料(就跑了一個多小時吧),對這些資料進行可視化分析的結果如下,
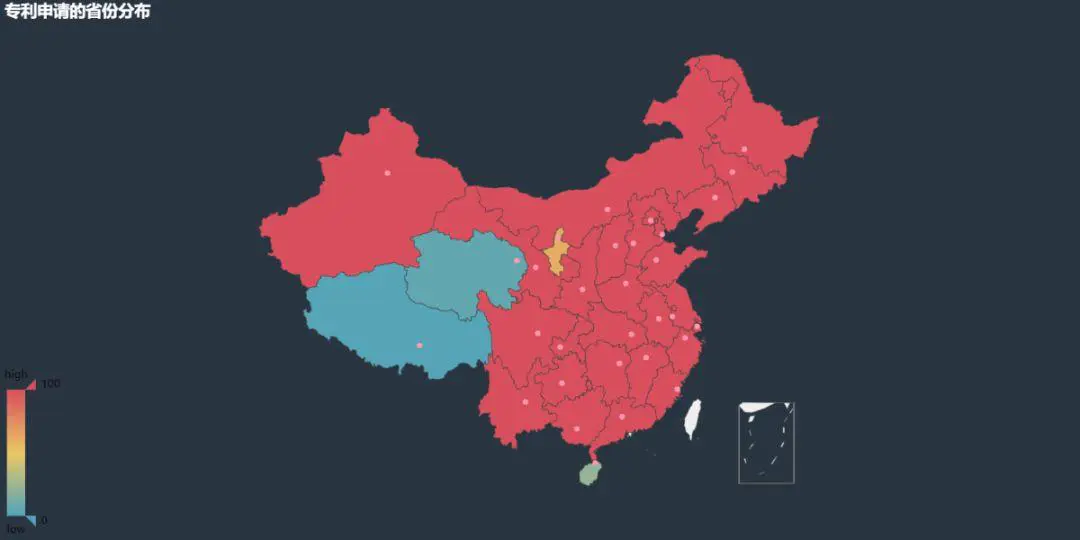
我們先來看看申請專利的省份分布唄:
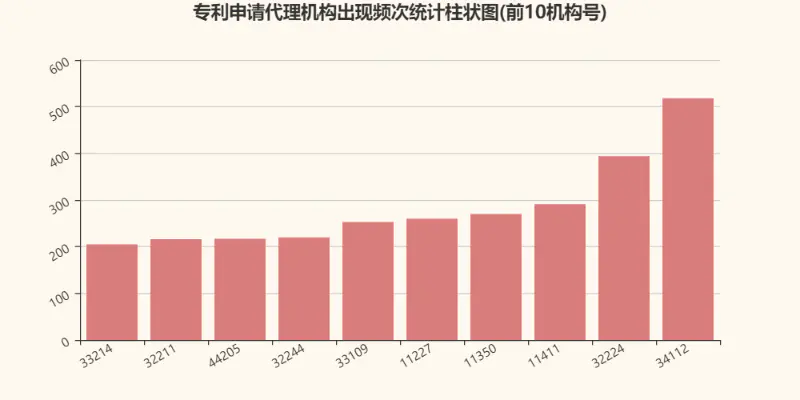
然后再來統計一下專利代理機構?
最后再來看看所有專利摘要做成的詞云唄:

還有所有專利標題做成的詞云唄:

文章到這里就結束了,感謝你的觀看,關注我每天分享Python系列爬蟲,下篇文章分享Python爬蟲知乎表情包,
為了感謝讀者們,我想把我最近收藏的一些編程干貨分享給大家,回饋每一個讀者,希望能幫到你們,
干貨主要有:
① 2000多本Python電子書(主流和經典的書籍應該都有了)
② Python標準庫資料(最全中文版)
③ 專案原始碼(四五十個有趣且經典的練手專案及原始碼)
④ Python基礎入門、爬蟲、web開發、大資料分析方面的視頻(適合小白學習)
⑤ Python學習路線圖(告別不入流的學習)
All done~完整源代碼+干貨詳見個人簡介或者私信獲取相關檔案,,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/288063.html
標籤:其他
上一篇:python實戰技巧之兩個串列實體中,如何讓里面的數字一一對應地相加【對于兩個串列是等長的情況】
下一篇:Java集合