前言
爬一波大眾點評上美食板塊的資料,順便再把爬到的資料做一波可視化分析

開發工具
Python版本:3.6.4
相關模塊:
scrapy模塊;
requests模塊;
fontTools模塊;
pyecharts模塊;
以及一些python自帶的模塊,
環境搭建
安裝python并添加到環境變數,pip安裝需要的相關模塊即可,
資料爬取
首先,我們新建一個名為大眾點評的scrapy專案:
scrapy startproject dazhongdianping
效果如下:

然后去大眾點評踩個點吧,這里以杭州為例:
http://www.dianping.com/hangzhou/ch10
顯然,我們想爬取的資料如下圖紅框所示:
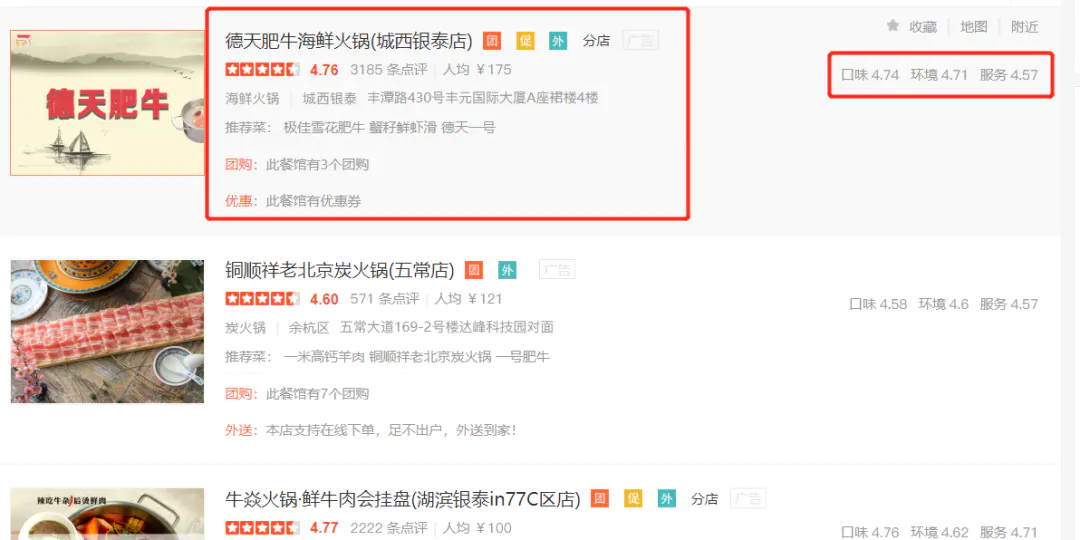
在items.py里定義一下這些資料型別:
'''定義要爬取的資料'''
class DazhongdianpingItem(scrapy.Item):
# 店名
shopname = scrapy.Field()
# 點評數量
num_comments = scrapy.Field()
# 人均價格
avg_price = scrapy.Field()
# 美食型別
food_type = scrapy.Field()
# 所在商區
business_district_name = scrapy.Field()
# 具體位置
location = scrapy.Field()
# 口味評分
taste_score = scrapy.Field()
# 環境評分
environment_score = scrapy.Field()
# 服務評分
serve_score = scrapy.Field()
然后利用正則運算式來提取網頁中我們想要的資料(字體反爬我就不講了,知乎隨便搜一下,就好多相關的文章T_T,只要下載對應的字體檔案,然后找到對應的映射關系就ok啦):
# 提取我們想要的資料
all_infos = re.findall(r'<li >(.*?)<div >', response.text, re.S|re.M)
for info in all_infos:
item = DazhongdianpingItem()
# --店名
item['shopname'] = re.findall(r'<h4>(.*?)<\/h4>', info, re.S|re.M)[0]
# --點評數量
try:
num_comments = re.findall(r'LXAnalytics\(\'moduleClick\', \'shopreview\'\).*?>(.*?)<\/b>', info, re.S|re.M)[0]
num_comments = ''.join(re.findall(r'>(.*?)<', num_comments, re.S|re.M))
for k, v in shopnum_crack_dict.items():
num_comments = num_comments.replace(k, str(v))
item['num_comments'] = num_comments
except:
item['num_comments'] = 'null'
# --人均價格
try:
avg_price = re.findall(r'<b>¥(.*?)<\/b>', info, re.S|re.M)[0]
avg_price = ''.join(re.findall(r'>(.*?)<', avg_price, re.S|re.M))
for k, v in shopnum_crack_dict.items():
avg_price = avg_price.replace(k, str(v))
item['avg_price'] = avg_price
except:
item['avg_price'] = 'null'
# --美食型別
food_type = re.findall(r'<a.*?data-click-name="shop_tag_cate_click".*?>(.*?)<\/span>', info, re.S|re.M)[0]
food_type = ''.join(re.findall(r'>(.*?)<', food_type, re.S|re.M))
for k, v in tagname_crack_dict.items():
food_type = food_type.replace(k, str(v))
item['food_type'] = food_type
# --所在商區
business_district_name = re.findall(r'<a.*?data-click-name="shop_tag_region_click".*?>(.*?)<\/span>', info, re.S|re.M)[0]
business_district_name = ''.join(re.findall(r'>(.*?)<', business_district_name, re.S|re.M))
for k, v in tagname_crack_dict.items():
business_district_name = business_district_name.replace(k, str(v))
item['business_district_name'] = business_district_name
# --具體位置
location = re.findall(r'<span >(.*?)<\/span>', info, re.S|re.M)[0]
location = ''.join(re.findall(r'>(.*?)<', location, re.S|re.M))
for k, v in address_crack_dict.items():
location = location.replace(k, str(v))
item['location'] = location
# --口味評分
try:
taste_score = re.findall(r'口味<b>(.*?)<\/b>', info, re.S|re.M)[0]
taste_score = ''.join(re.findall(r'>(.*?)<', taste_score, re.S|re.M))
for k, v in shopnum_crack_dict.items():
taste_score = taste_score.replace(k, str(v))
item['taste_score'] = taste_score
except:
item['taste_score'] = 'null'
# --環境評分
try:
environment_score = re.findall(r'環境<b>(.*?)<\/b>', info, re.S|re.M)[0]
environment_score = ''.join(re.findall(r'>(.*?)<', environment_score, re.S|re.M))
for k, v in shopnum_crack_dict.items():
environment_score = environment_score.replace(k, str(v))
item['environment_score'] = environment_score
except:
item['environment_score'] = 'null'
# --服務評分
try:
serve_score = re.findall(r'服務<b>(.*?)<\/b>', info, re.S|re.M)[0]
serve_score = ''.join(re.findall(r'>(.*?)<', serve_score, re.S|re.M))
for k, v in shopnum_crack_dict.items():
serve_score = serve_score.replace(k, str(v))
item['serve_score'] = serve_score
except:
item['serve_score'] = 'null'
# --yield
yield item
最后在終端運行如下命令就可以爬取我們想要的資料啦:
scrapy crawl dazhongdianping -o infos.json -t json
文章到這里就結束了,感謝你的觀看,關注我每天分享Python爬蟲實戰系列,下篇文章分享中國地震臺網爬蟲,
為了感謝讀者們,我想把我最近收藏的一些編程干貨分享給大家,回饋每一個讀者,希望能幫到你們,
干貨主要有:
① 2000多本Python電子書(主流和經典的書籍應該都有了)
② Python標準庫資料(最全中文版)
③ 專案原始碼(四五十個有趣且經典的練手專案及原始碼)
④ Python基礎入門、爬蟲、web開發、大資料分析方面的視頻(適合小白學習)
⑤ Python學習路線圖(告別不入流的學習)
All done~完整源代碼+干貨詳見個人簡介或者私信獲取相關檔案,,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/288125.html
標籤:Python